Hampir setahun yang lalu, saya memposting solusi saya untuk pagination di SQL Server, yang melibatkan penggunaan CTE untuk menemukan hanya nilai kunci untuk kumpulan baris yang dimaksud, dan kemudian bergabung kembali dari CTE ke tabel sumber untuk mengambil kolom lain hanya untuk "halaman" baris itu. Ini terbukti paling bermanfaat ketika ada indeks sempit yang mendukung pengurutan yang diminta oleh pengguna, atau ketika pengurutan didasarkan pada kunci pengelompokan, tetapi bahkan berkinerja sedikit lebih baik tanpa indeks untuk mendukung pengurutan yang diperlukan.
Sejak itu, saya bertanya-tanya apakah indeks ColumnStore (baik berkerumun dan tidak berkerumun) dapat membantu salah satu skenario ini. TL;DR :Berdasarkan percobaan ini secara terpisah, jawaban atas judul posting ini adalah TIDAK . Jika Anda tidak ingin melihat penyiapan pengujian, kode, rencana eksekusi, atau grafik, silakan lewati ringkasan saya, dengan mengingat bahwa analisis saya didasarkan pada kasus penggunaan yang sangat spesifik.
Penyiapan
Pada VM baru dengan SQL Server 2016 CTP 3.2 (13.0.900.73) terinstal, saya menjalankan pengaturan yang kira-kira sama seperti sebelumnya, hanya kali ini dengan tiga tabel. Pertama, tabel tradisional dengan kunci pengelompokan sempit dan beberapa indeks pendukung:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Selanjutnya, tabel dengan indeks ColumnStore berkerumun:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
Dan akhirnya, tabel dengan indeks ColumnStore non-cluster yang mencakup semua kolom:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Perhatikan bahwa untuk kedua tabel dengan indeks ColumnStore, saya mengabaikan indeks yang akan mendukung pencarian lebih cepat pada jenis "Buku Telepon" (nama belakang, nama depan).
Data Uji
Saya kemudian mengisi tabel pertama dengan 1.000.000 baris acak, berdasarkan skrip yang saya gunakan kembali dari posting sebelumnya:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Kemudian saya menggunakan tabel itu untuk mengisi dua lainnya dengan data yang sama persis, dan membangun kembali semua indeks:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Ukuran total setiap tabel:
| Tabel | Dipesan | Data | Indeks |
|---|---|---|---|
| Pelanggan | 463.200 KB | 154.344 KB | 308.576 KB |
| Customers_CCI | 117.280 KB | 30.288 KB | 86.536 KB |
| Pelanggan_NCCI | 349.480 KB | 154.344 KB | 194.976 KB |
Dan jumlah baris / jumlah halaman dari indeks yang relevan (indeks unik pada email lebih berguna bagi saya untuk mengasuh skrip pembuatan data saya sendiri daripada yang lainnya):
| Tabel | Indeks | Baris | Halaman |
|---|---|---|---|
| Pelanggan | PK_Pelanggan | 1.000.000 | 19.377 |
| Pelanggan | Pelanggan_Buku Telepon | 1.000.000 | 17.209 |
| Pelanggan | Pelanggan_Aktif | 808.012 | 13.977 |
| Customers_CCI | PK_PelangganCCI | 1.000.000 | 2,737 |
| Customers_CCI | Pelanggan_CCI | 1.000.000 | 3,826 |
| Pelanggan_NCCI | PK_PelangganNCCI | 1.000.000 | 19.377 |
| Pelanggan_NCCI | Pelanggan_NCCI | 1.000.000 | 16.971 |
Prosedur
Kemudian, untuk melihat apakah indeks ColumnStore akan masuk dan membuat skenario menjadi lebih baik, saya menjalankan kumpulan kueri yang sama seperti sebelumnya, tetapi sekarang terhadap ketiga tabel. Saya mendapatkan setidaknya sedikit lebih pintar dan membuat dua prosedur tersimpan dengan SQL dinamis untuk menerima sumber tabel dan mengurutkan urutan. (Saya sangat menyadari injeksi SQL; ini bukan yang akan saya lakukan dalam produksi jika string ini berasal dari pengguna akhir, jadi tolong jangan menganggapnya sebagai rekomendasi untuk melakukannya. Saya cukup percaya pada diri saya sendiri lingkungan tertutup yang tidak menjadi perhatian untuk pengujian ini.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Kemudian saya menyiapkan beberapa SQL yang lebih dinamis untuk menghasilkan semua kombinasi panggilan yang perlu saya lakukan untuk memanggil prosedur tersimpan lama dan baru, di ketiga urutan pengurutan yang diinginkan, dan pada nomor halaman yang berbeda (untuk mensimulasikan kebutuhan halaman di dekat awal, tengah, dan akhir urutan pengurutan). Agar saya bisa menyalin PRINT output dan tempel ke SQL Sentry Plan Explorer untuk mendapatkan metrik runtime, saya menjalankan batch ini dua kali, sekali dengan procedures CTE menggunakan P_Old , dan sekali lagi menggunakan P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Ini menghasilkan output seperti ini (36 panggilan sekaligus untuk metode lama (P_Old ), dan 36 panggilan untuk metode baru (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Saya tahu, ini semua sangat merepotkan; kita akan segera ke bagian lucunya, aku janji.
Hasil
Saya mengambil dua set 36 pernyataan itu dan memulai dua sesi baru di Plan Explorer, menjalankan setiap set beberapa kali untuk memastikan kami mendapatkan data dari cache hangat dan mengambil rata-rata (saya bisa membandingkan cache dingin dan hangat juga, tapi saya pikir ada cukup variabel di sini).
Saya dapat memberi tahu Anda langsung beberapa fakta sederhana tanpa menunjukkan grafik atau rencana pendukung kepada Anda:
- Dalam skenario apa pun metode "lama" tidak mengalahkan metode CTE baru Saya mempromosikan di posting saya sebelumnya, apa pun jenis indeks yang ada. Sehingga memudahkan untuk mengabaikan setengah dari hasil, setidaknya dalam hal durasi (yang merupakan metrik yang paling diperhatikan pengguna akhir).
- Tidak ada indeks ColumnStore yang bernasib baik saat paging menjelang akhir hasil – mereka hanya memberikan manfaat di awal, dan hanya dalam beberapa kasus.
- Saat mengurutkan berdasarkan kunci utama (berkelompok atau tidak), keberadaan indeks ColumnStore tidak membantu – sekali lagi, dalam hal durasi.
Dengan ringkasan itu, mari kita lihat beberapa penampang data durasi. Pertama, hasil kueri diurutkan dengan nama depan menurun, lalu email, tanpa harapan menggunakan indeks yang ada untuk penyortiran. Seperti yang Anda lihat di bagan, kinerjanya tidak konsisten – pada nomor halaman yang lebih rendah, ColumnStore yang tidak berkerumun melakukan yang terbaik; pada nomor halaman yang lebih tinggi, indeks tradisional selalu menang:
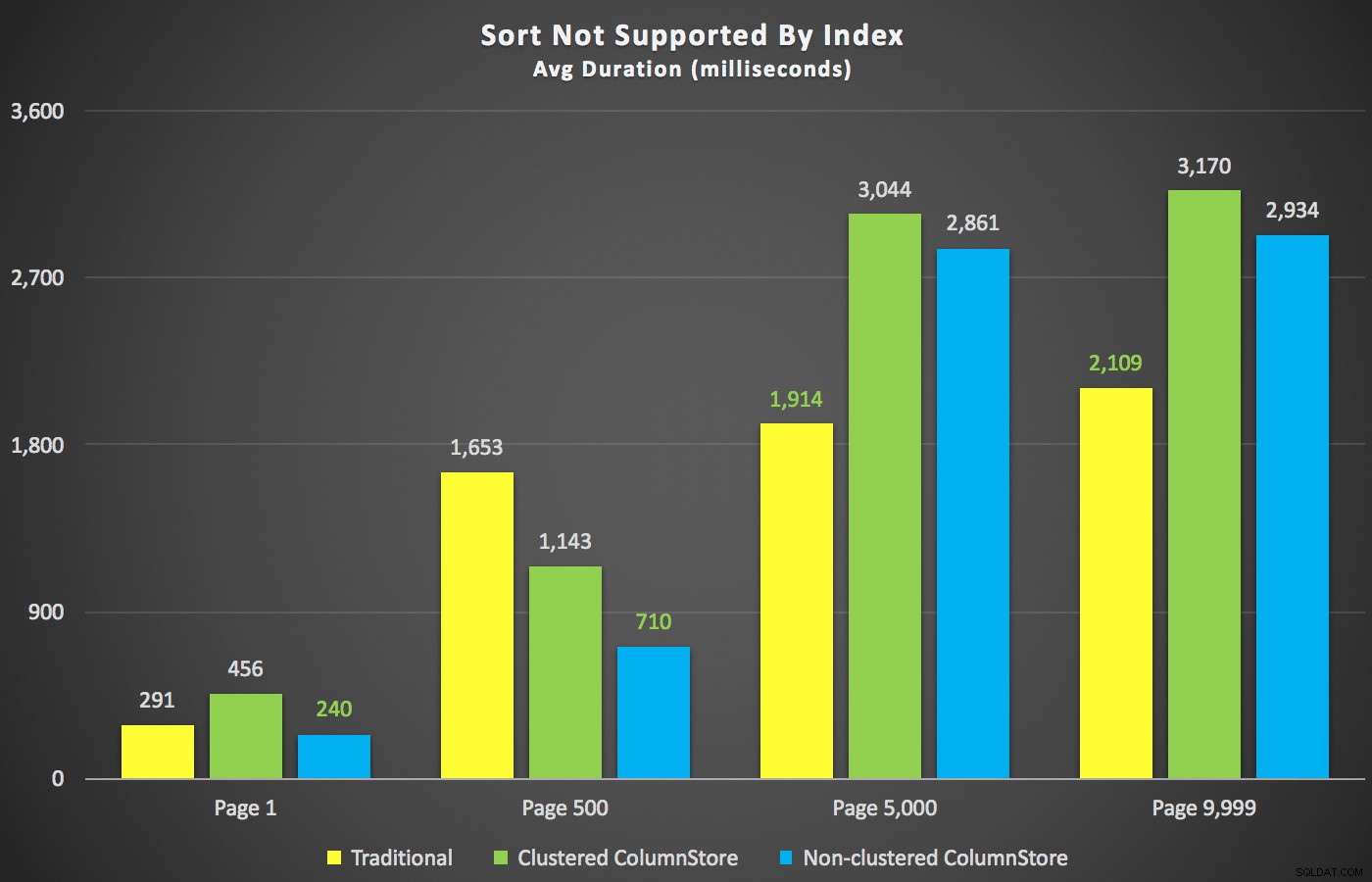 Durasi (milidetik) untuk nomor halaman berbeda dan jenis indeks berbeda
Durasi (milidetik) untuk nomor halaman berbeda dan jenis indeks berbeda
Dan kemudian tiga rencana yang mewakili tiga jenis indeks yang berbeda (dengan skala abu-abu yang ditambahkan oleh Photoshop untuk menyoroti perbedaan utama antara rencana):
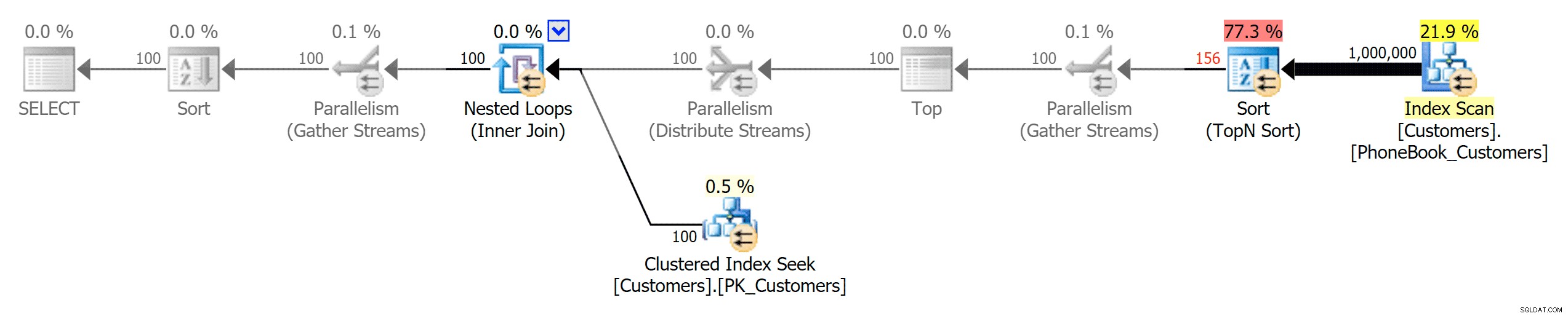 Rencanakan untuk indeks tradisional
Rencanakan untuk indeks tradisional
 Rencanakan indeks ColumnStore berkerumun
Rencanakan indeks ColumnStore berkerumun
 Rencanakan indeks ColumnStore non-clustered
Rencanakan indeks ColumnStore non-clustered
Skenario yang lebih saya minati, bahkan sebelum saya mulai menguji, adalah pendekatan penyortiran buku telepon (nama belakang, nama depan). Dalam hal ini indeks ColumnStore sebenarnya cukup merugikan kinerja hasil:
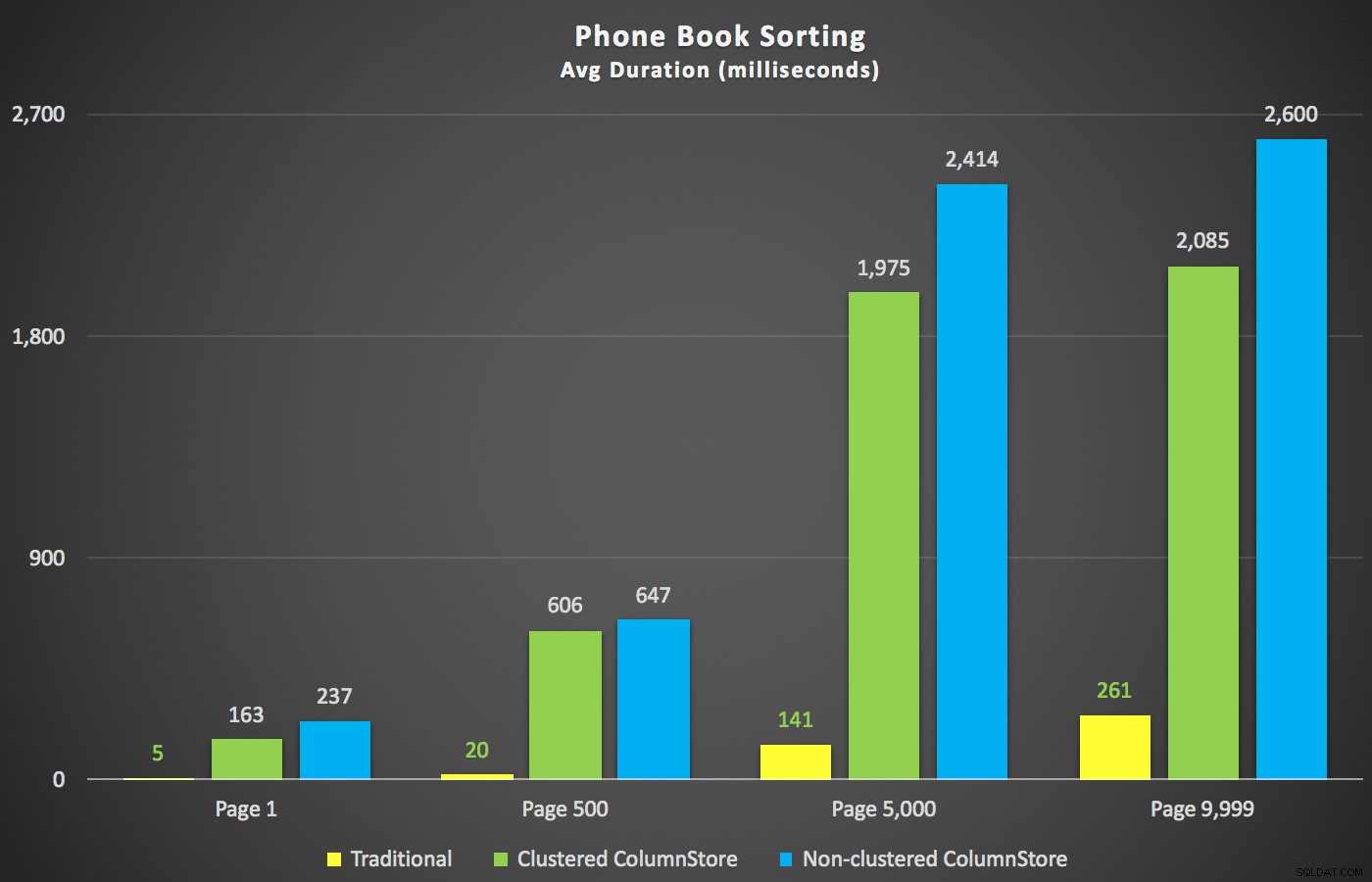
Paket ColumnStore di sini mendekati gambar cermin ke dua paket ColumnStore yang ditunjukkan di atas untuk jenis yang tidak didukung. Alasannya sama dalam kedua kasus:pemindaian atau pengurutan yang mahal karena kurangnya indeks yang mendukung pengurutan.
Jadi selanjutnya, saya membuat indeks "Buku Telepon" yang mendukung pada tabel dengan indeks ColumnStore juga, untuk melihat apakah saya dapat membujuk rencana yang berbeda dan/atau waktu eksekusi yang lebih cepat dalam skenario mana pun. Saya membuat dua indeks ini, lalu membangunnya kembali:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Berikut adalah durasi baru:
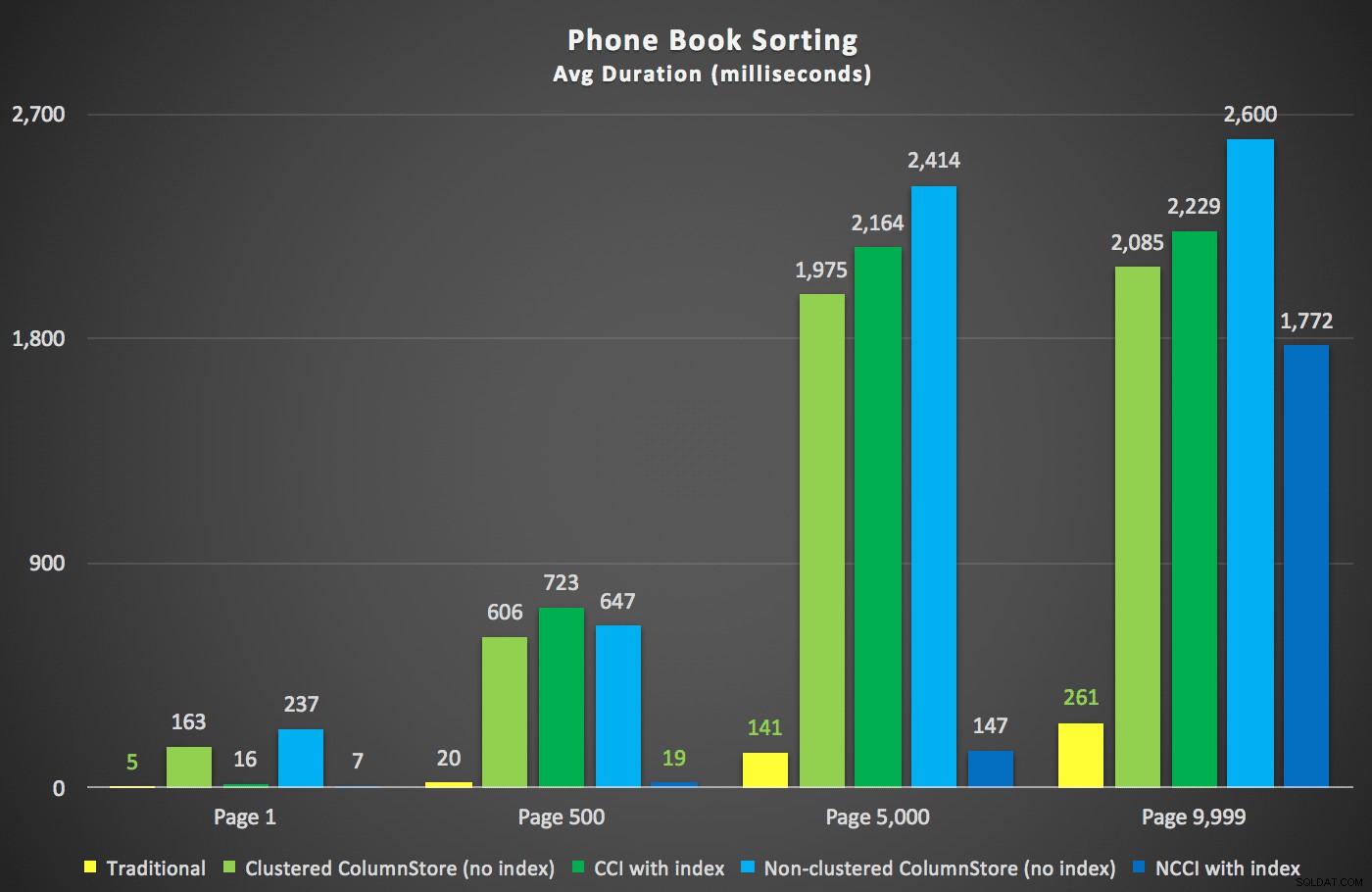
Yang paling menarik di sini adalah bahwa sekarang kueri paging terhadap tabel dengan indeks ColumnStore yang tidak berkerumun tampaknya sejalan dengan indeks tradisional, hingga kita melampaui bagian tengah tabel. Melihat rencana, kita dapat melihat bahwa pada halaman 5.000, pemindaian indeks tradisional digunakan, dan indeks ColumnStore sepenuhnya diabaikan:
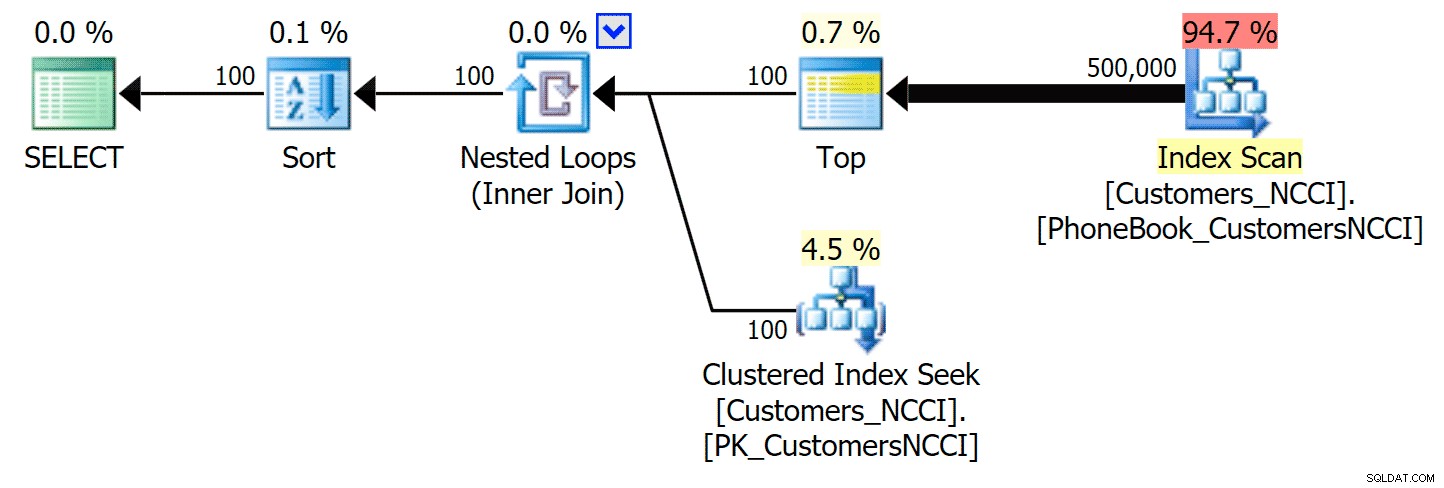 Paket Buku Telepon mengabaikan indeks ColumnStore non-clustered
Paket Buku Telepon mengabaikan indeks ColumnStore non-clustered
Tetapi di suatu tempat antara titik tengah 5.000 halaman dan "akhir" tabel pada 9.999 halaman, pengoptimal telah mencapai semacam titik kritis dan – untuk kueri yang sama persis – sekarang memilih untuk memindai indeks ColumnStore yang tidak berkerumun :
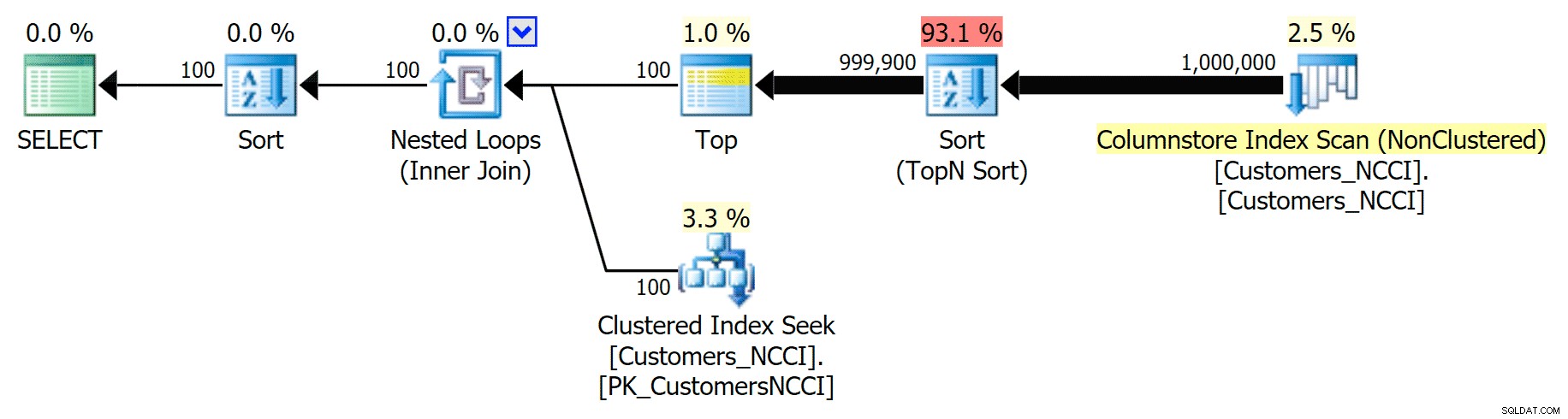 Rencana Buku Telepon 'tips' dan menggunakan indeks ColumnStore
Rencana Buku Telepon 'tips' dan menggunakan indeks ColumnStore
Ini ternyata menjadi keputusan yang tidak terlalu bagus oleh pengoptimal, terutama karena biaya operasi pengurutan. Anda dapat melihat seberapa baik durasinya jika Anda mengisyaratkan indeks reguler:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Ini menghasilkan paket berikut, hampir identik dengan paket pertama di atas (namun biaya pemindaian sedikit lebih tinggi, hanya karena ada lebih banyak keluaran):
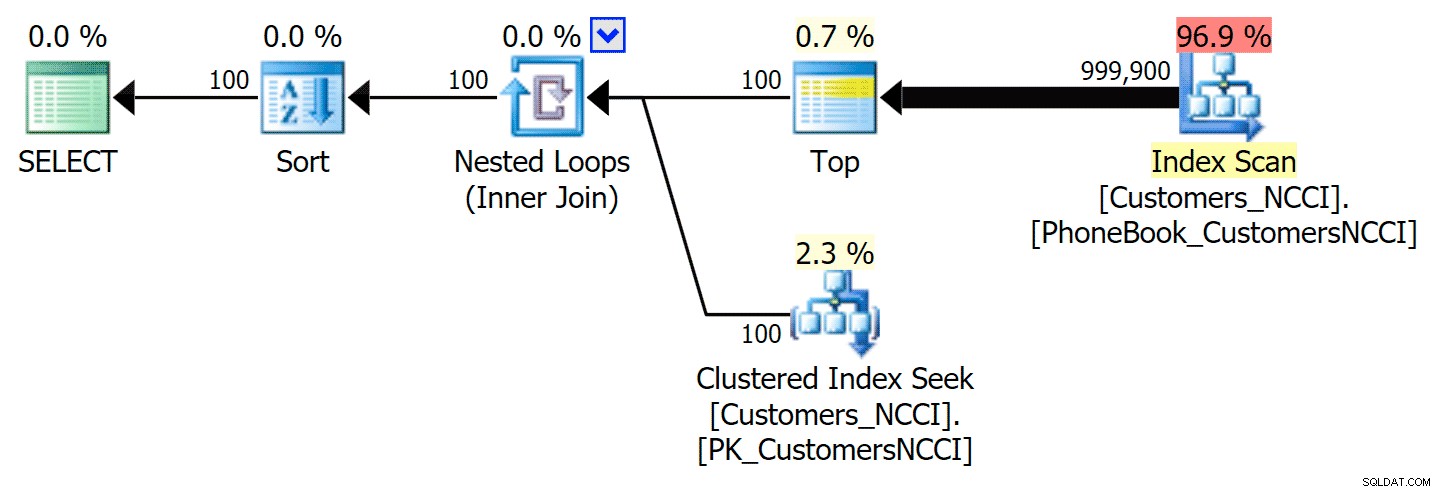 Paket Buku Telepon dengan indeks petunjuk
Paket Buku Telepon dengan indeks petunjuk
Anda dapat mencapai hal yang sama menggunakan OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) alih-alih petunjuk indeks eksplisit. Ingatlah bahwa ini sama saja dengan tidak memiliki indeks ColumnStore di tempat pertama.
Kesimpulan
Meskipun ada beberapa kasus tepi di atas di mana indeks ColumnStore mungkin (hampir tidak) membuahkan hasil, bagi saya tampaknya mereka tidak cocok untuk skenario pagination khusus ini. Saya pikir, yang paling penting, sementara ColumnStore menunjukkan penghematan ruang yang signifikan karena kompresi, kinerja runtime tidak fantastis karena persyaratan pengurutan (meskipun jenis ini diperkirakan berjalan dalam mode batch, pengoptimalan baru untuk SQL Server 2016).
Secara umum, ini bisa dilakukan dengan lebih banyak waktu yang dihabiskan untuk penelitian dan pengujian; dalam membonceng artikel sebelumnya, saya ingin mengubah sesedikit mungkin. Saya ingin menemukan titik kritis itu, misalnya, dan saya juga ingin mengakui bahwa ini bukan tes skala besar (karena ukuran VM dan keterbatasan memori), dan saya membuat Anda menebak-nebak tentang banyak hal. metrik runtime (kebanyakan untuk singkatnya, tetapi saya tidak tahu bahwa bagan pembacaan yang tidak selalu sebanding dengan durasi akan benar-benar memberi tahu Anda). Pengujian ini juga mengasumsikan kemewahan SSD, memori yang cukup, cache yang selalu hangat, dan lingkungan pengguna tunggal. Saya benar-benar ingin melakukan pengujian baterai yang lebih besar terhadap lebih banyak data, pada server yang lebih besar dengan disk yang lebih lambat dan instans dengan memori yang lebih sedikit, sementara itu dengan simulasi konkurensi.
Yang mengatakan, ini juga bisa menjadi skenario yang ColumnStore tidak dirancang untuk membantu memecahkan di tempat pertama, sebagai solusi yang mendasari dengan indeks tradisional sudah cukup efisien dalam menarik keluar set sempit baris – tidak persis ruang kemudi ColumnStore. Mungkin variabel lain untuk ditambahkan ke matriks adalah ukuran halaman – semua pengujian di atas menarik 100 baris sekaligus, tetapi bagaimana jika kita mengejar 10.000 atau 100.000 baris sekaligus, terlepas dari seberapa besar tabel yang mendasarinya?
Apakah Anda memiliki situasi di mana beban kerja OLTP Anda ditingkatkan hanya dengan penambahan indeks ColumnStore? Saya tahu bahwa mereka dirancang untuk beban kerja gaya gudang data, tetapi jika Anda telah melihat manfaatnya di tempat lain, saya ingin mendengar tentang skenario Anda dan melihat apakah saya dapat memasukkan pembeda apa pun ke dalam rig pengujian saya.