Catatan:Posting ini awalnya diterbitkan hanya di eBook kami, High Performance Techniques for SQL Server, Volume 4. Anda dapat mengetahui tentang eBook kami di sini.
Saya secara teratur mendapatkan pertanyaan, "Di mana saya memulai ketika mencoba untuk menyetel contoh SQL Server?" Tanggapan pertama saya adalah bertanya kepada mereka tentang konfigurasi instance mereka. Jika hal-hal tertentu tidak dikonfigurasi dengan benar, maka mulai melihat kueri yang berjalan lama atau berbiaya tinggi segera dapat membuang-buang usaha.
Saya telah membuat blog tentang hal-hal umum yang terlewatkan oleh administrator di mana saya membagikan banyak pengaturan yang harus diubah oleh administrator dari instalasi default SQL Server. Untuk item terkait kinerja, saya memberi tahu mereka bahwa mereka harus memeriksa yang berikut:
- Setelan memori
- Memperbarui statistik
- Pemeliharaan indeks
- MAXDOP dan ambang biaya untuk paralelisme
- praktik terbaik tempdb
- Optimalkan beban kerja ad hoc
Setelah saya melewati item konfigurasi, saya bertanya apakah mereka telah melihat statistik file dan menunggu serta kueri berbiaya tinggi. Sebagian besar waktu jawabannya adalah "tidak" – dengan penjelasan bahwa mereka tidak yakin bagaimana menemukan informasi itu.
Biasanya kepatuhan umum ketika seseorang menyatakan bahwa mereka perlu menyetel SQL Server adalah bahwa itu berjalan lambat. Apa artinya lambat? Apakah itu laporan tertentu, aplikasi tertentu, atau semuanya? Apakah itu baru saja mulai terjadi, atau semakin memburuk dari waktu ke waktu? Saya mulai dengan mengajukan pertanyaan triase biasa tentang apa yang dibandingkan dengan memori, CPU, dan penggunaan disk ketika semuanya normal, apakah masalahnya baru saja mulai terjadi, dan apa yang baru saja berubah. Kecuali jika klien menangkap garis dasar, mereka tidak memiliki metrik untuk dibandingkan untuk mengetahui apakah statistik saat ini tidak normal.
Hampir setiap SQL Server yang saya kerjakan menghosting lebih dari satu database pengguna. Ketika klien melaporkan bahwa SQL Server berjalan lambat, sebagian besar waktu mereka khawatir tentang aplikasi tertentu yang menyebabkan masalah bagi pelanggan mereka. Reaksi spontan adalah untuk segera fokus pada database tertentu, namun sering kali proses lain dapat memakan sumber daya yang berharga dan database aplikasi sedang terpengaruh. Misalnya, jika Anda memiliki database pelaporan yang besar dan seseorang memulai laporan besar yang memenuhi disk, meningkatkan CPU, dan menghapus cache paket, Anda dapat bertaruh bahwa database pengguna lain akan melambat saat laporan tersebut dibuat.
Saya selalu suka memulai dengan melihat statistik file. Untuk SQL Server 2005 dan yang lebih baru, Anda dapat meminta sys.dm_io_virtual_file_stats DMV untuk mendapatkan statistik I/O untuk setiap data dan file log. DMV ini menggantikan fungsi fn_virtualfilestats. Untuk menangkap statistik file, saya suka menggunakan skrip yang disatukan oleh Paul Randal:menangkap latensi IO untuk jangka waktu tertentu. Skrip ini akan menangkap garis dasar dan, 30 menit kemudian (kecuali jika Anda mengubah durasi di bagian WAITFOR DELAY), menangkap statistik dan menghitung delta di antara mereka. Skrip Paul juga melakukan sedikit matematika untuk menentukan latensi baca dan tulis, yang membuatnya lebih mudah bagi kita untuk membaca dan memahami.
Di laptop saya, saya memulihkan salinan database AdventureWorks2014 ke drive USB sehingga saya memiliki kecepatan disk yang lebih lambat; Saya kemudian memulai proses untuk menghasilkan beban terhadapnya. Anda dapat melihat hasilnya di bawah ini di mana latensi tulis saya untuk file data saya adalah 240ms dan latensi tulis untuk file log saya adalah 46ms. Latensi setinggi ini merepotkan.
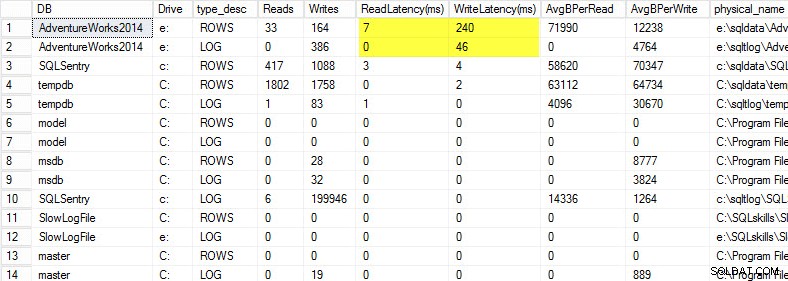
Apa pun yang lebih dari 20 ms harus dianggap buruk, seperti yang saya bagikan di posting sebelumnya:memantau latensi baca/tulis. Latensi baca saya lumayan, tetapi database AdventureWorks2014 mengalami penulisan yang lambat. Dalam hal ini saya akan menyelidiki apa yang menghasilkan penulisan serta menyelidiki kinerja subsistem I/O saya. Jika ini adalah latensi baca yang terlalu tinggi, saya akan mulai menyelidiki kinerja kueri (mengapa ia melakukan begitu banyak pembacaan, misalnya dari indeks yang hilang), serta kinerja subsistem I/O secara keseluruhan.
Penting untuk mengetahui kinerja keseluruhan subsistem I/O Anda, dan cara terbaik untuk mengetahui kemampuannya adalah dengan membandingkannya. Glenn Berry membicarakan hal ini dalam artikelnya yang menganalisis kinerja I/O untuk SQL Server. Glenn menjelaskan latency, IOPS, dan throughput dan menunjukkan CrystalDiskMark yang merupakan alat gratis yang dapat Anda gunakan untuk baseline penyimpanan Anda.
Setelah mengetahui bagaimana kinerja statistik file, saya suka melihat statistik menunggu dengan menggunakan DMV sys.dm_os_wait_stats, yang mengembalikan informasi tentang semua waktu tunggu yang terjadi. Untuk ini saya beralih ke skrip lain yang disediakan Paul Randal dalam menangkap statistik tunggu untuk periode waktu posting blog. Skrip Paul melakukan sedikit perhitungan untuk kita lagi, tetapi yang lebih penting, skrip ini mengecualikan banyak penantian ramah yang biasanya tidak kita pedulikan. Script ini juga memiliki WAITFOR DELAY dan disetel ke 30 menit. Membaca statistik menunggu bisa sedikit lebih rumit:Anda dapat memiliki waktu menunggu yang tampaknya tinggi berdasarkan persentase, tetapi rata-rata menunggu sangat rendah sehingga tidak ada yang perlu dikhawatirkan.
Saya memulai proses pemuatan yang sama dan menangkap statistik tunggu saya, yang telah saya tunjukkan di bawah. Untuk penjelasan dari banyak jenis menunggu ini, Anda dapat membaca salah satu posting blog Paul yang lain, statistik tunggu, atau tolong beri tahu saya di mana itu sakit, ditambah beberapa postingnya di blog ini.
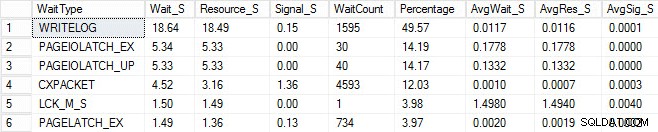
Dalam keluaran yang dibuat-buat ini, penantian PAGEIOLATCH dapat mengindikasikan kemacetan dengan subsistem I/O saya, tetapi juga bisa menjadi masalah memori, pencarian tabel sebagai gantinya, atau sejumlah masalah lainnya. Dalam kasus saya, kami tahu ini adalah masalah disk, karena saya menyimpan database pada stik USB. Waktu tunggu LCK_M_S sangat tinggi, namun hanya ada satu contoh waktu tunggu. WRITELOG saya juga lebih tinggi daripada yang ingin saya lihat, tetapi dapat dimengerti mengetahui masalah latensi dengan stik USB. Ini juga menunjukkan CXPACKET menunggu, dan akan mudah untuk bereaksi spontan dan berpikir Anda memiliki masalah paralelisme/MAXDOP, namun penghitung AvgWait_S sangat rendah. Hati-hati saat menggunakan menunggu untuk pemecahan masalah. Biarkan itu menjadi panduan untuk memberi tahu Anda hal-hal yang bukan masalah serta memberi Anda arah ke mana harus mencari masalah. Pemecahan masalah yang tepat adalah menghubungkan perilaku dari beberapa area untuk mempersempit masalah.
Setelah melihat file dan menunggu statistik, saya kemudian mulai menggali kueri berbiaya tinggi berdasarkan masalah yang saya temukan. Untuk ini saya beralih ke Pertanyaan Informasi Diagnostik Glenn Berry. Kumpulan kueri ini adalah skrip masuk yang digunakan banyak konsultan. Glenn dan komunitasnya terus memberikan pembaruan untuk menjadikannya seinformasi dan sekuat mungkin. Salah satu kueri favorit saya adalah kueri cache teratas berdasarkan jumlah eksekusi. Saya suka menemukan kueri atau prosedur tersimpan yang memiliki execution_count tinggi ditambah dengan total_logical_reads tinggi. Jika kueri tersebut memiliki peluang penyetelan, maka Anda dapat dengan cepat membuat perbedaan besar pada server. Juga termasuk dalam skrip adalah SP cache teratas berdasarkan total pembacaan logis dan SP cache teratas berdasarkan total pembacaan fisik. Keduanya bagus untuk mencari bacaan tinggi dengan jumlah eksekusi tinggi sehingga Anda dapat mengurangi jumlah I/O.
Selain skrip Glenn, saya suka menggunakan sp_whoisactive Adam Machanic untuk melihat apa yang sedang berjalan.
Ada lebih banyak hal untuk penyetelan kinerja daripada hanya melihat statistik file dan menunggu dan kueri berbiaya tinggi, namun di situlah saya ingin memulai. Ini adalah cara untuk dengan cepat melakukan triase lingkungan untuk mulai menentukan apa yang menyebabkan masalah. Tidak ada cara yang benar-benar terbukti bodoh untuk menyetel:apa yang dibutuhkan setiap produksi DBA adalah daftar periksa hal-hal yang harus dijalankan untuk dihilangkan dan kumpulan skrip yang sangat bagus untuk dijalankan guna menganalisis kesehatan sistem. Memiliki dasar adalah kunci untuk dengan cepat mengesampingkan perilaku normal vs abnormal. Teman baik saya Erin Stellato memiliki seluruh kursus tentang Pluralsight yang disebut SQL Server:Benchmarking dan Baselining jika Anda memerlukan bantuan untuk menyiapkan dan menangkap baseline Anda.
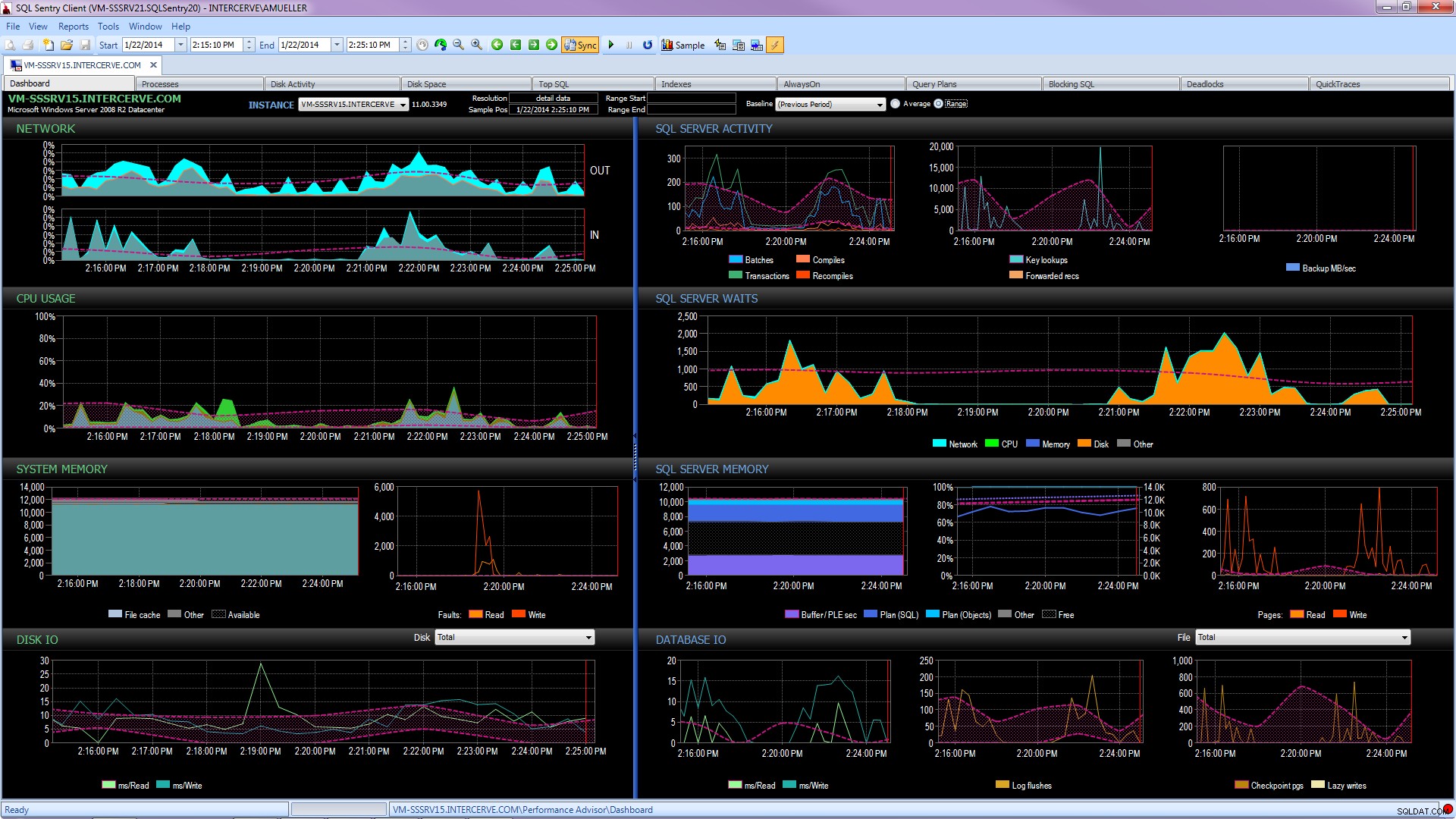
Lebih baik lagi, dapatkan alat canggih seperti SQL Sentry Performance Advisor yang tidak hanya akan mengumpulkan dan menyimpan informasi historis untuk pembuatan profil dan tren, dan memberikan akses mudah ke semua detail yang disebutkan di atas dan banyak lagi, tetapi juga memberikan kemampuan untuk membandingkan aktivitas dengan baseline bawaan atau yang ditentukan pengguna, mempertahankan indeks secara efisien tanpa mengangkat jari, dan memperingatkan atau mengotomatiskan respons berdasarkan arsitektur kondisi kustom yang sangat kuat. Tangkapan layar berikut menggambarkan tampilan historis dasbor Performance Advisor, dengan disk menunggu dalam warna oranye, I/O basis data di kanan bawah, dan garis dasar yang membandingkan periode saat ini dan sebelumnya pada setiap grafik (klik untuk memperbesar):
Alat pemantauan kualitas tidak gratis, tetapi menyediakan banyak fungsi dan dukungan yang memungkinkan Anda untuk fokus pada masalah kinerja di server Anda, daripada berfokus pada kueri, pekerjaan, dan peringatan yang mungkin memungkinkan Anda untuk fokus pada masalah kinerja Anda – tetapi hanya setelah Anda melakukannya dengan benar. Sering kali ada nilai bagus dengan tidak menemukan kembali roda.