Awal bulan ini, saya menerbitkan tip tentang sesuatu yang mungkin kita semua tidak ingin kita lakukan:mengurutkan atau menghapus duplikat dari string yang dibatasi, biasanya melibatkan fungsi yang ditentukan pengguna (UDF). Terkadang Anda perlu menyusun kembali daftar (tanpa duplikat) dalam urutan abjad, dan terkadang Anda mungkin perlu mempertahankan urutan aslinya (bisa berupa daftar kolom kunci dalam indeks yang buruk, misalnya).
Untuk solusi saya, yang membahas kedua skenario, saya menggunakan tabel angka, bersama dengan sepasang fungsi yang ditentukan pengguna (UDF) – satu untuk membagi string, yang lain untuk memasangnya kembali. Anda dapat melihat tip itu di sini:
- Menghapus Duplikat dari String di SQL Server
Tentu saja, ada banyak cara untuk memecahkan masalah ini; Saya hanya menyediakan satu metode untuk dicoba jika Anda terjebak dengan data struktur itu. @Phil_Factor Red-Gate menindaklanjuti dengan posting cepat yang menunjukkan pendekatannya, yang menghindari fungsi dan tabel angka, sebagai gantinya memilih manipulasi XML sebaris. Dia mengatakan dia lebih suka memiliki kueri pernyataan tunggal dan menghindari fungsi dan pemrosesan baris demi baris:
- Menghapus duplikat Daftar Delimited di SQL Server
Kemudian seorang pembaca, Steve Mangiameli, memposting solusi perulangan sebagai komentar di tip. Alasannya adalah bahwa penggunaan tabel angka tampak terlalu direkayasa baginya.
Kami bertiga gagal mengatasi aspek ini yang biasanya akan menjadi sangat penting jika Anda cukup sering melakukan tugas atau pada tingkat skala apa pun:kinerja .
Pengujian
Ingin tahu seberapa baik kinerja pendekatan XML dan perulangan inline dibandingkan dengan solusi berbasis tabel angka saya, saya membuat tabel fiktif untuk melakukan beberapa pengujian; tujuan saya adalah 5.000 baris, dengan panjang string rata-rata lebih dari 250 karakter, dan setidaknya 10 elemen di setiap string. Dengan siklus eksperimen yang sangat singkat, saya dapat mencapai sesuatu yang sangat mirip dengan ini dengan kode berikut:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Ini menghasilkan tabel dengan baris sampel yang terlihat seperti ini (nilai terpotong):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Data secara keseluruhan memiliki profil berikut, yang seharusnya cukup baik untuk mengungkap potensi masalah kinerja:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Perhatikan bahwa saya beralih ke varchar di sini dari nvarchar dalam artikel asli, karena sampel yang diberikan Phil dan Steve diasumsikan varchar , string yang dibatasi hanya 255 atau 8000 karakter, pembatas karakter tunggal, dll. Saya telah mempelajari pelajaran saya dengan cara yang sulit, bahwa jika Anda akan mengambil fungsi seseorang dan memasukkannya ke dalam perbandingan kinerja, Anda mengubahnya sesedikit mungkin – idealnya tidak ada. Pada kenyataannya saya akan selalu menggunakan nvarchar dan tidak berasumsi apa pun tentang string terpanjang yang mungkin. Dalam hal ini saya tahu saya tidak kehilangan data karena string terpanjang hanya 2.905 karakter, dan dalam database ini saya tidak memiliki tabel atau kolom yang menggunakan karakter Unicode.
Selanjutnya, saya membuat fungsi saya (yang membutuhkan tabel angka). Seorang pembaca melihat masalah dalam fungsi di tip saya, di mana saya berasumsi bahwa pembatas akan selalu menjadi satu karakter, dan memperbaikinya di sini. Saya juga mengonversi hampir semuanya menjadi varchar(8000) untuk menyamakan kedudukan dalam hal jenis dan panjang senar.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Selanjutnya, saya membuat satu fungsi bernilai tabel sebaris yang menggabungkan dua fungsi di atas, sesuatu yang sekarang saya harap telah saya lakukan di artikel asli, untuk menghindari fungsi skalar sama sekali. (Meskipun benar bahwa tidak semua fungsi skalar sangat buruk dalam skala, hanya ada sedikit pengecualian.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Saya juga membuat versi terpisah dari TVF inline yang didedikasikan untuk masing-masing dari dua pilihan penyortiran, untuk menghindari volatilitas CASE ekspresi, tapi ternyata tidak berdampak dramatis sama sekali.
Kemudian saya membuat dua fungsi Steve:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Lalu saya memasukkan kueri langsung Phil ke rig pengujian saya (perhatikan bahwa kuerinya mengkodekan < sebagai < untuk melindungi mereka dari kesalahan penguraian XML, tetapi mereka tidak menyandikan > atau & – Saya telah menambahkan placeholder jika Anda perlu menjaga string yang berpotensi mengandung karakter bermasalah tersebut):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Rig pengujian pada dasarnya adalah dua kueri itu, dan juga panggilan fungsi berikut. Setelah saya memvalidasi bahwa mereka semua mengembalikan data yang sama, saya menyelingi skrip dengan DATEDIFF output dan mencatatnya ke tabel:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Dan kemudian saya menjalankan tes kinerja pada dua sistem yang berbeda (satu quad core dengan 8GB, dan satu VM 8-core dengan 32GB), dan dalam setiap kasus, pada SQL Server 2012 dan SQL Server 2016 CTP 3.2 (13.0.900.73).
Hasil
Hasil yang saya amati dirangkum dalam bagan berikut, yang menunjukkan durasi dalam milidetik dari setiap jenis kueri, rata-rata berdasarkan urutan abjad dan asli, empat kombinasi server/versi, dan serangkaian 15 eksekusi untuk setiap permutasi. Klik untuk memperbesar:
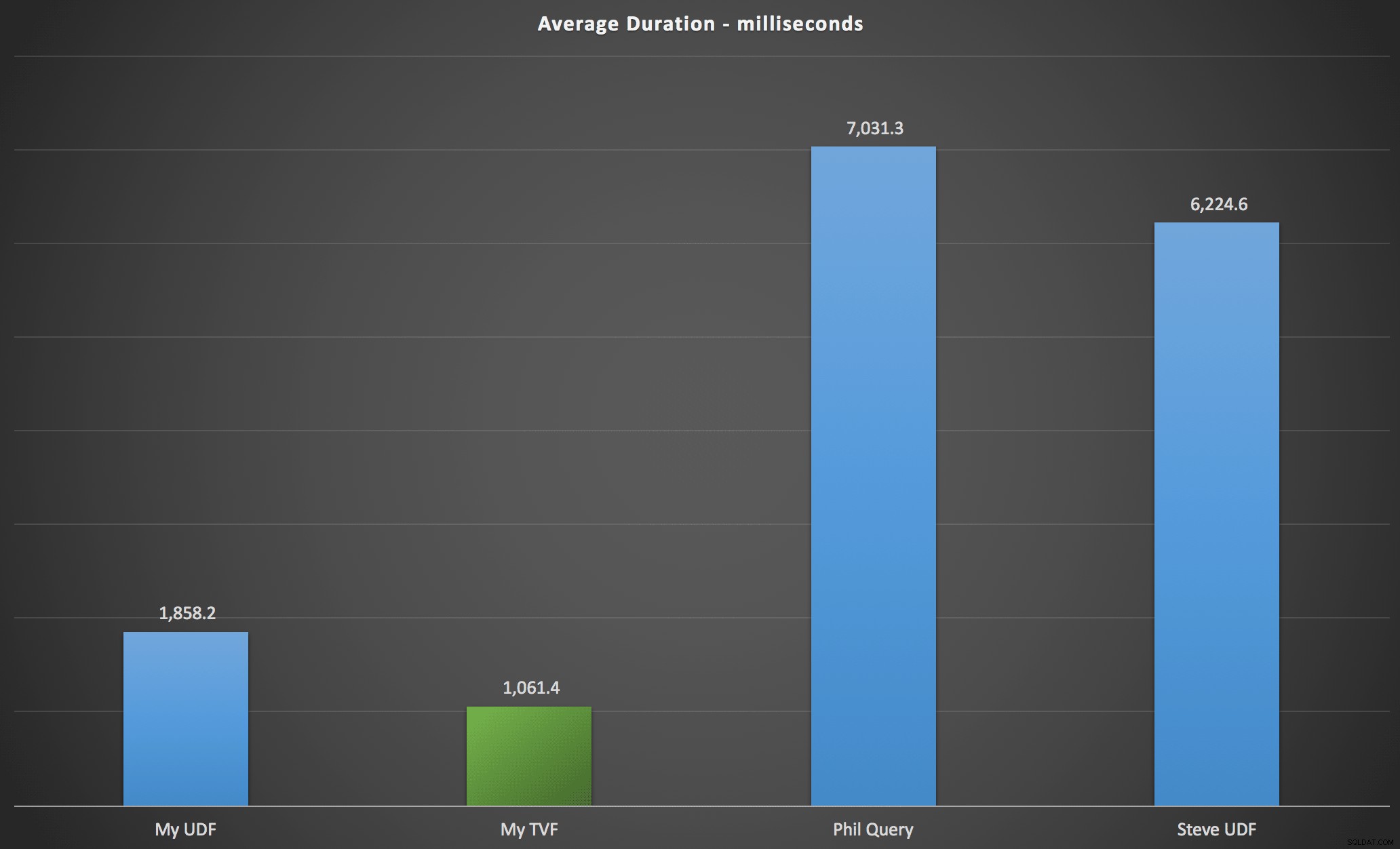
Ini menunjukkan bahwa tabel angka, meskipun dianggap over-engineered, sebenarnya menghasilkan solusi yang paling efisien (setidaknya dalam hal durasi). Ini lebih baik, tentu saja, dengan TVF tunggal yang saya terapkan baru-baru ini daripada dengan fungsi bersarang dari artikel asli, tetapi kedua solusi menjalankan lingkaran di sekitar dua alternatif.
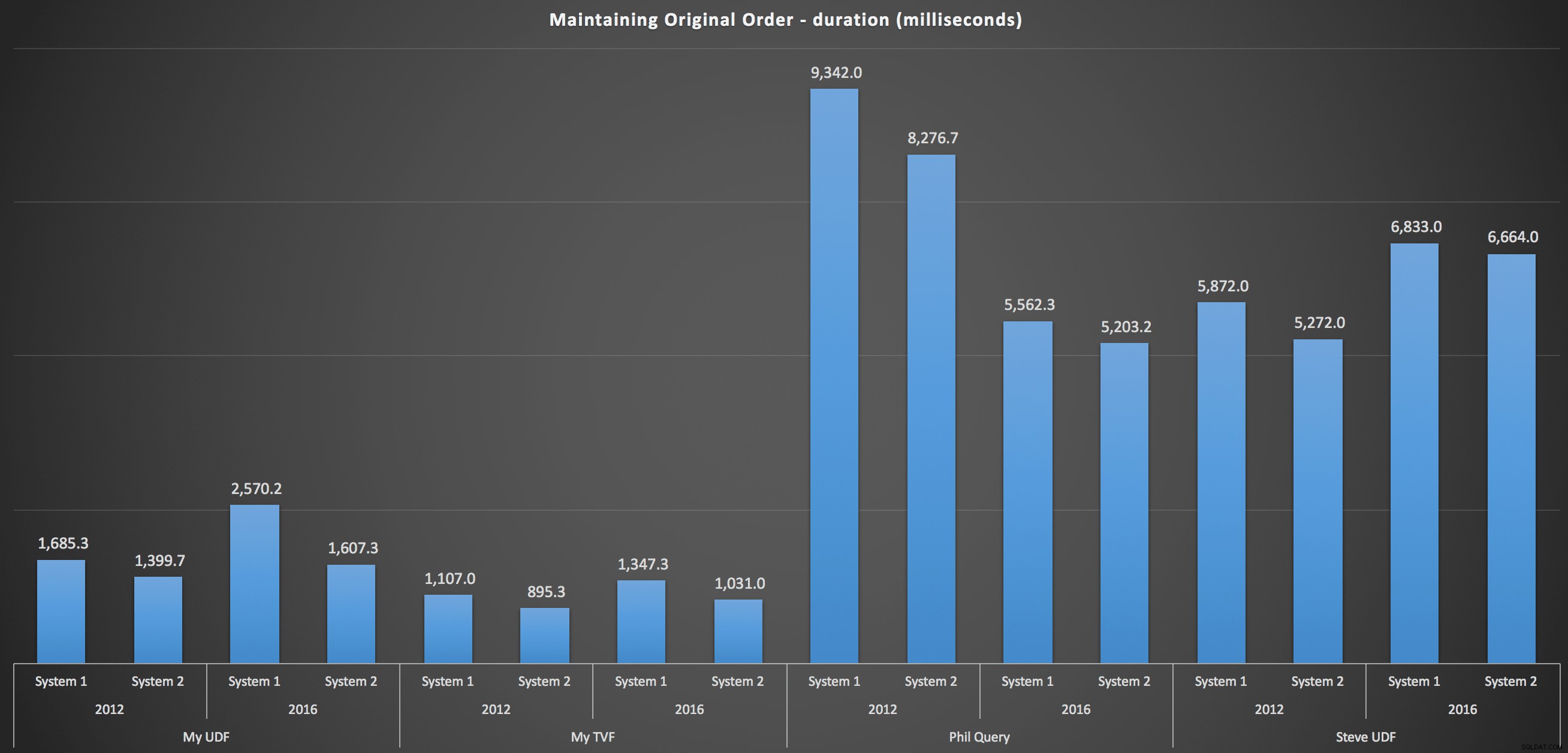
Untuk lebih detail, berikut adalah rincian untuk setiap mesin, versi, dan jenis kueri, untuk mempertahankan pesanan asli:
…dan untuk menyusun kembali daftar dalam urutan abjad:
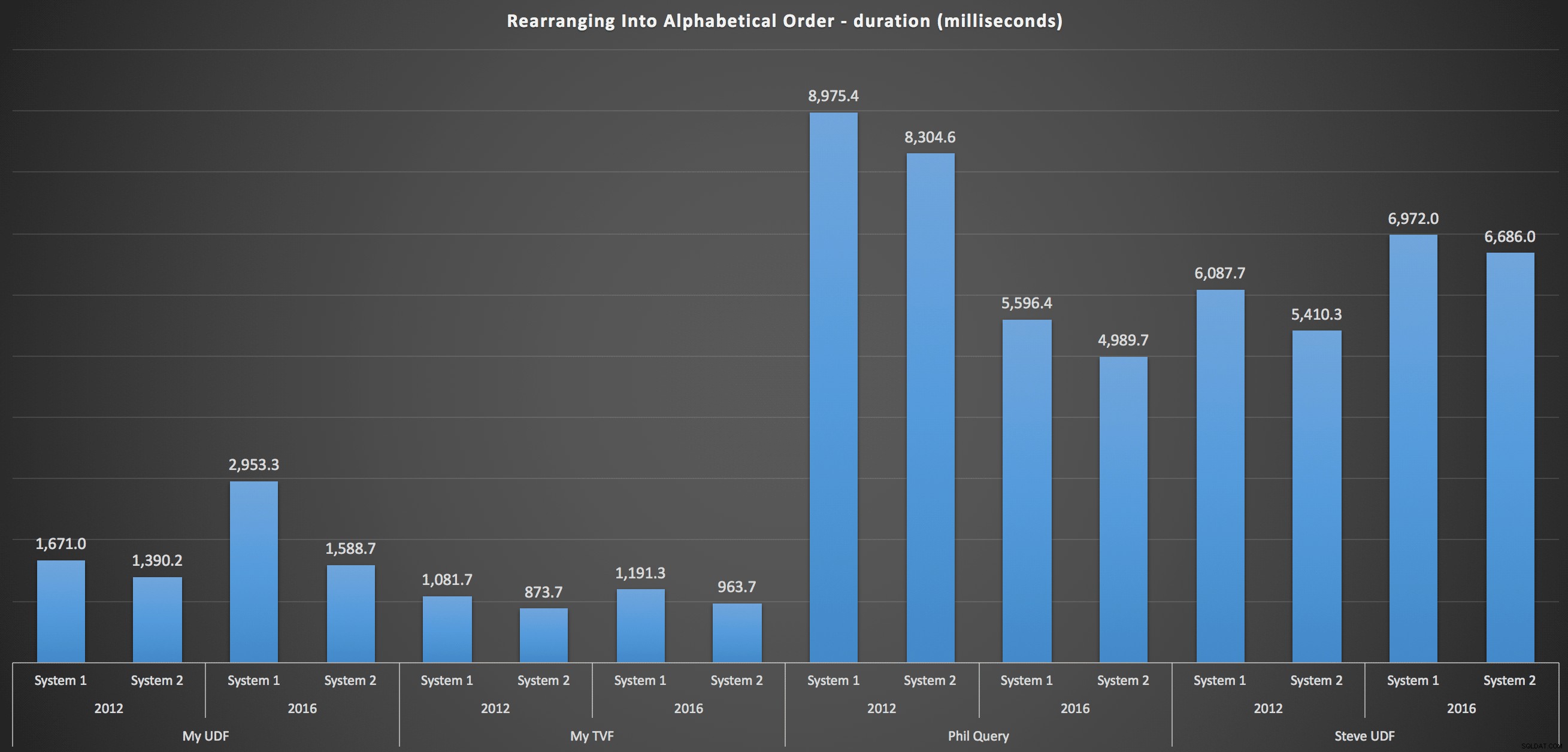
Ini menunjukkan bahwa pilihan penyortiran berdampak kecil pada hasil – kedua grafik hampir identik. Dan itu masuk akal karena, mengingat bentuk data input, tidak ada indeks yang dapat saya bayangkan yang akan membuat penyortiran lebih efisien – ini adalah pendekatan berulang tidak peduli bagaimana Anda mengirisnya atau bagaimana Anda mengembalikan datanya. Namun jelas bahwa beberapa pendekatan berulang pada umumnya bisa lebih buruk daripada yang lain, dan belum tentu penggunaan UDF (atau tabel angka) yang membuatnya seperti itu.
Kesimpulan
Sampai kami memiliki fungsi pemisahan dan penggabungan asli di SQL Server, kami akan menggunakan semua jenis metode yang tidak intuitif untuk menyelesaikan pekerjaan, termasuk fungsi yang ditentukan pengguna. Jika Anda menangani satu string pada satu waktu, Anda tidak akan melihat banyak perbedaan. Tetapi ketika data Anda meningkat, Anda perlu menguji berbagai pendekatan (dan saya sama sekali tidak menyarankan bahwa metode di atas adalah yang terbaik yang akan Anda temukan – saya bahkan tidak melihat CLR, misalnya, atau pendekatan T-SQL lain dari seri ini).