SQL Server secara tradisional menghindar dari memberikan solusi asli untuk beberapa pertanyaan statistik yang lebih umum, seperti menghitung median. Menurut WikiPedia, "median digambarkan sebagai nilai numerik yang memisahkan bagian yang lebih tinggi dari sampel, populasi, atau distribusi probabilitas, dari bagian yang lebih rendah. Median dari daftar angka yang terbatas dapat ditemukan dengan mengatur semua pengamatan dari nilai terendah ke nilai tertinggi dan memilih yang tengah. Jika jumlah pengamatan genap, maka tidak ada nilai tengah tunggal; median biasanya didefinisikan sebagai rata-rata dari dua nilai tengah."
Dalam hal kueri SQL Server, hal utama yang akan Anda ambil darinya adalah Anda perlu "mengatur" (mengurutkan) semua nilai. Penyortiran di SQL Server biasanya merupakan operasi yang cukup mahal jika tidak ada indeks pendukung, dan menambahkan indeks untuk mendukung operasi yang mungkin tidak diminta sering kali tidak bermanfaat.
Mari kita periksa bagaimana kita biasanya memecahkan masalah ini di versi SQL Server sebelumnya. Pertama mari kita buat tabel yang sangat sederhana sehingga kita dapat melihat bahwa logika kita benar dan menurunkan median yang akurat. Kita dapat menguji dua tabel berikut, satu dengan jumlah baris genap, dan yang lainnya dengan jumlah baris ganjil:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Dari pengamatan biasa, kita dapat melihat bahwa median untuk tabel dengan baris ganjil adalah 6, dan untuk tabel genap adalah 7,5 ((6+9)/2). Jadi sekarang mari kita lihat beberapa solusi yang telah digunakan selama bertahun-tahun:
SQL Server 2000
Di SQL Server 2000, kami dibatasi pada dialek T-SQL yang sangat terbatas. Saya sedang menyelidiki opsi ini untuk perbandingan karena beberapa orang di luar sana masih menjalankan SQL Server 2000, dan yang lain mungkin telah memutakhirkan tetapi, karena perhitungan median mereka ditulis "dulu," kodenya mungkin masih terlihat seperti ini hari ini.
2000_A – maksimal satu setengah, minimal setengah lainnya
Pendekatan ini mengambil nilai tertinggi dari 50 persen pertama, nilai terendah dari 50 persen terakhir, kemudian dibagi dua. Ini berfungsi untuk baris genap atau ganjil karena, dalam kasus genap, dua nilai adalah dua baris tengah, dan dalam kasus ganjil, kedua nilai sebenarnya dari baris yang sama.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #tabel sementara
Contoh ini pertama-tama membuat tabel #temp, dan menggunakan tipe matematika yang sama seperti di atas, menentukan dua baris "tengah" dengan bantuan dari IDENTITY yang berdekatan kolom yang diurutkan oleh kolom val. (Urutan penetapan IDENTITY nilai hanya dapat diandalkan karena MAXDOP pengaturan.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 memperkenalkan beberapa fungsi jendela baru yang menarik, seperti ROW_NUMBER() , yang dapat membantu memecahkan masalah statistik seperti median sedikit lebih mudah daripada yang kita bisa di SQL Server 2000. Semua pendekatan ini bekerja di SQL Server 2005 dan di atasnya:
2005_A – duel nomor baris
Contoh ini menggunakan ROW_NUMBER() untuk berjalan naik dan turun nilai sekali di setiap arah, kemudian menemukan "tengah" satu atau dua baris berdasarkan perhitungan itu. Ini sangat mirip dengan contoh pertama di atas, dengan sintaks yang lebih mudah:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B – nomor baris + hitungan
Yang ini sangat mirip dengan yang di atas, menggunakan perhitungan tunggal ROW_NUMBER() dan kemudian menggunakan total COUNT() untuk menemukan satu atau dua baris "tengah":
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C – variasi nomor baris + hitungan
Rekan MVP Itzik Ben-Gan menunjukkan kepada saya metode ini, yang mencapai jawaban yang sama seperti dua metode di atas, tetapi dengan cara yang sedikit berbeda:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
Di SQL Server 2012, kami memiliki kemampuan windowing baru di T-SQL yang memungkinkan perhitungan statistik seperti median diekspresikan secara lebih langsung. Untuk menghitung median sekumpulan nilai, kita dapat menggunakan PERCENTILE_CONT() . Kami juga dapat menggunakan ekstensi "paging" baru ke ORDER BY klausa (OFFSET / FETCH ).
2012_A – fungsi distribusi baru
Solusi ini menggunakan perhitungan yang sangat mudah menggunakan distribusi (jika Anda tidak ingin rata-rata antara dua nilai tengah dalam kasus jumlah baris genap).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B – trik paging
Contoh ini mengimplementasikan penggunaan cerdas OFFSET / FETCH (dan tidak persis satu yang dimaksudkan) – kita cukup pindah ke baris yang satu sebelum setengah hitungan, lalu mengambil satu atau dua baris berikutnya tergantung pada apakah hitungannya ganjil atau genap. Terima kasih kepada Itzik Ben-Gan karena telah menunjukkan pendekatan ini.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Tapi mana yang berkinerja lebih baik?
Kami telah memverifikasi bahwa semua metode di atas menghasilkan hasil yang diharapkan pada tabel kecil kami, dan kami tahu bahwa versi SQL Server 2012 memiliki sintaks paling bersih dan paling logis. Tapi mana yang harus Anda gunakan di lingkungan produksi Anda yang sibuk? Kami dapat membuat tabel yang jauh lebih besar dari metadata sistem, memastikan kami memiliki banyak nilai duplikat. Skrip ini akan menghasilkan tabel dengan 10.000.000 bilangan bulat tidak unik:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
Di sistem saya, median untuk tabel ini adalah 146.099.561. Saya dapat menghitung ini dengan cukup cepat tanpa pemeriksaan manual 10.000.000 baris dengan menggunakan kueri berikut:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Hasil:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Jadi sekarang kita dapat membuat prosedur tersimpan untuk setiap metode, memverifikasi bahwa masing-masing menghasilkan output yang benar, dan kemudian mengukur metrik kinerja seperti durasi, CPU, dan pembacaan. Kami akan melakukan semua langkah ini dengan tabel yang ada, dan juga dengan salinan tabel yang tidak memanfaatkan indeks berkerumun (kami akan menghapusnya dan membuat ulang tabel sebagai tumpukan).
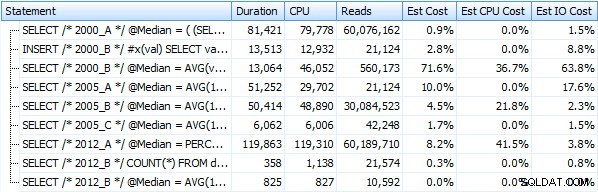
Saya telah membuat tujuh prosedur yang mengimplementasikan metode kueri di atas. Untuk singkatnya saya tidak akan mencantumkannya di sini, tetapi masing-masing diberi nama dbo.Median_<version> , misalnya dbo.Median_2000_A , dbo.Median_2000_B , dll. sesuai dengan pendekatan yang dijelaskan di atas. Jika kita menjalankan tujuh prosedur ini menggunakan SQL Sentry Plan Explorer gratis, berikut adalah apa yang kita amati dalam hal durasi, CPU, dan pembacaan (perhatikan bahwa kita menjalankan DBCC FREEPROCCACHE dan DBCC DROPCLEANBUFFERS di antara eksekusi):
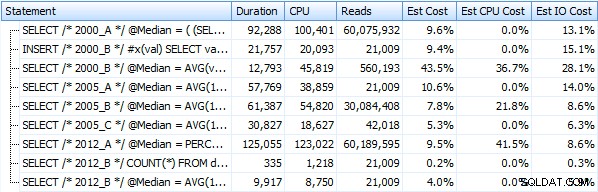
Dan metrik ini tidak banyak berubah sama sekali jika kami beroperasi melawan tumpukan. Perubahan persentase terbesar adalah metode yang tetap menjadi yang tercepat:trik paging menggunakan OFFSET / FETCH:
Berikut adalah representasi grafis dari hasilnya. Untuk membuatnya lebih jelas, saya menyoroti pemain paling lambat dengan warna merah dan pendekatan tercepat dengan warna hijau.
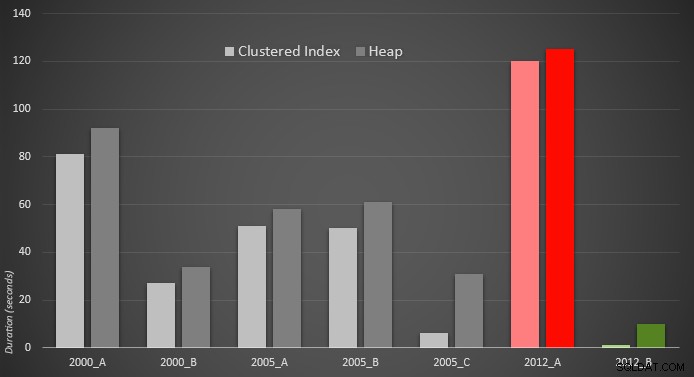
Saya terkejut melihat bahwa, dalam kedua kasus, PERCENTILE_CONT() – yang dirancang untuk jenis perhitungan ini – sebenarnya lebih buruk daripada semua solusi sebelumnya lainnya. Saya kira itu hanya menunjukkan bahwa terkadang sintaks yang lebih baru mungkin membuat pengkodean kami lebih mudah, itu tidak selalu menjamin bahwa kinerja akan meningkat. Saya juga terkejut melihat OFFSET / FETCH terbukti sangat berguna dalam skenario yang biasanya tidak sesuai dengan tujuannya – pagination.
Bagaimanapun, saya harap saya telah menunjukkan pendekatan mana yang harus Anda gunakan, tergantung pada versi SQL Server Anda (dan pilihannya harus sama apakah Anda memiliki indeks pendukung untuk penghitungan atau tidak).