Artikel ini adalah angsuran ketiga dalam seri kompleksitas NULL. Di Bagian 1 saya membahas arti penanda NULL dan bagaimana perilakunya dalam perbandingan. Di Bagian 2 saya menjelaskan ketidakkonsistenan perlakuan NULL dalam elemen bahasa yang berbeda. Bulan ini saya menjelaskan fitur penanganan NULL standar yang kuat yang belum sampai ke T-SQL, dan solusi yang digunakan orang saat ini.
Saya akan terus menggunakan database sampel TSQLV5 seperti bulan lalu di beberapa contoh saya. Anda dapat menemukan skrip yang membuat dan mengisi database ini di sini, dan diagram ER-nya di sini.
predikat BERBEDA
Di Bagian 1 dalam seri saya menjelaskan bagaimana NULL berperilaku dalam perbandingan dan kompleksitas di sekitar logika predikat tiga nilai yang digunakan SQL dan T-SQL. Perhatikan predikat berikut:
X =YJika ada predikat NULL — termasuk jika keduanya NULL — hasil dari predikat ini adalah nilai logika UNKNOWN. Dengan pengecualian operator IS NULL dan IS NOT NULL, hal yang sama berlaku untuk semua operator lain, termasuk berbeda dari (<>):
X <> YSeringkali dalam praktiknya Anda ingin NULL berperilaku seperti nilai non-NULL untuk tujuan perbandingan. Itu terutama terjadi ketika Anda menggunakannya untuk mewakili hilang tetapi tidak dapat diterapkan nilai-nilai. Standar memiliki solusi untuk kebutuhan ini dalam bentuk fitur yang disebut predikat DISTINCT, yang menggunakan bentuk berikut:
Alih-alih menggunakan semantik kesetaraan atau ketidaksetaraan, predikat ini menggunakan semantik berbasis perbedaan saat membandingkan predikat. Sebagai alternatif untuk operator kesetaraan (=), Anda akan menggunakan formulir berikut untuk mendapatkan TRUE ketika kedua predikatnya sama, termasuk jika keduanya NULL, dan FALSE jika tidak, termasuk jika salah satunya NULL dan lainnya tidak:
X TIDAK BERBEDA DENGAN YSebagai alternatif untuk berbeda dari operator (<>), Anda akan menggunakan formulir berikut untuk mendapatkan TRUE ketika dua predikat berbeda, termasuk ketika satu NULL dan yang lainnya tidak, dan FALSE ketika keduanya sama, termasuk ketika keduanya NULL:
X BERBEDA DENGAN YMari kita terapkan predikat DISTINCT pada contoh yang kita gunakan di Bagian 1 dalam rangkaian ini. Ingatlah bahwa Anda perlu menulis kueri yang memberikan parameter input @dt mengembalikan pesanan yang dikirim pada tanggal input jika bukan NULL, atau yang tidak dikirim sama sekali jika inputnya NULL. Menurut standar, Anda akan menggunakan kode berikut dengan predikat DISTINCT untuk menangani kebutuhan ini:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
Untuk saat ini, ingat kembali dari Bagian 1 bahwa Anda dapat menggunakan kombinasi predikat EXISTS dan operator INTERSECT sebagai solusi SARGable di T-SQL, seperti:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Untuk mengembalikan pesanan yang dikirim pada tanggal yang berbeda dari (berbeda dari) tanggal input @dt, Anda akan menggunakan kueri berikut:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
Solusi yang berhasil di T-SQL menggunakan kombinasi predikat EXISTS dan operator EXCEPT, seperti:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Di Bagian 1 saya juga membahas skenario di mana Anda perlu menggabungkan tabel dan menerapkan semantik berbasis perbedaan dalam predikat gabungan. Dalam contoh saya, saya menggunakan tabel yang disebut T1 dan T2, dengan kolom gabungan NULLable yang disebut k1, k2 dan k3 di kedua sisi. Menurut standar, Anda akan menggunakan kode berikut untuk menangani gabungan seperti itu:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
Untuk saat ini, mirip dengan tugas pemfilteran sebelumnya, Anda dapat menggunakan kombinasi predikat EXISTS dan operator INTERSECT dalam klausa ON gabungan untuk meniru predikat berbeda di T-SQL, seperti:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Saat digunakan dalam filter, formulir ini SARGable, dan saat digunakan dalam gabungan, formulir ini berpotensi mengandalkan urutan indeks.
Jika Anda ingin melihat predikat DISTINCT ditambahkan ke T-SQL, Anda dapat memilihnya di sini.
Jika setelah membaca bagian ini Anda masih merasa sedikit tidak nyaman dengan predikat DISTINCT, Anda tidak sendirian. Mungkin predikat ini jauh lebih baik daripada solusi apa pun yang ada saat ini yang kami miliki di T-SQL, tetapi agak bertele-tele, dan sedikit membingungkan. Ini menggunakan bentuk negatif untuk menerapkan apa yang ada dalam pikiran kita sebagai perbandingan positif, dan sebaliknya. Yah, tidak ada yang mengatakan bahwa semua saran standar itu sempurna. Seperti yang dicatat Charlie dalam salah satu komentarnya di Bagian 1, bentuk sederhana berikut akan berfungsi lebih baik:
Ini ringkas dan jauh lebih intuitif. Alih-alih X TIDAK BERBEDA DARI Y, Anda akan menggunakan:
X IS YDan alih-alih X IS DISTINCT FROM Y, Anda akan menggunakan:
X BUKAN YOperator yang diusulkan ini sebenarnya selaras dengan operator IS NULL dan IS NOT NULL yang sudah ada.
Diterapkan pada tugas kueri kami, untuk mengembalikan pesanan yang dikirim pada tanggal input (atau yang tidak dikirim jika inputnya NULL), Anda akan menggunakan kode berikut:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
Untuk mengembalikan pesanan yang dikirim pada tanggal yang berbeda dari tanggal input, Anda dapat menggunakan kode berikut:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Jika Microsoft pernah memutuskan untuk menambahkan predikat yang berbeda, akan lebih baik jika mereka mendukung baik bentuk verbose standar, dan bentuk tidak standar namun lebih ringkas dan lebih intuitif ini. Anehnya, prosesor kueri SQL Server sudah mendukung operator perbandingan internal IS, yang menggunakan semantik yang sama dengan operator IS yang diinginkan yang saya jelaskan di sini. Anda dapat menemukan detail tentang operator ini di artikel Paul White Rencana Kueri Tidak Berdokumen:Perbandingan Kesetaraan (lihat “IS, bukan EQ”). Apa yang hilang adalah mengeksposnya secara eksternal sebagai bagian dari T-SQL.
klausul perlakuan NULL (ABAIKAN NULLS | RESPECT NULLS)
Saat menggunakan fungsi jendela offset LAG, LEAD, FIRST_VALUE dan LAST_VALUE, terkadang Anda perlu mengontrol perilaku perlakuan NULL. Secara default, fungsi-fungsi ini mengembalikan hasil ekspresi yang diminta di posisi yang diminta, terlepas dari apakah hasil ekspresi adalah nilai aktual atau NULL. Namun, terkadang Anda ingin terus bergerak ke arah yang relevan, (mundur untuk LAG dan LAST_VALUE, maju untuk LEAD dan FIRST_VALUE), dan kembalikan nilai non-NULL pertama jika ada, dan NULL jika tidak. Standar memberi Anda kendali atas perilaku ini menggunakan klausul perlakuan NULL dengan sintaks berikut:
offset_function(Default jika klausa perlakuan NULL tidak ditentukan adalah opsi RESPECT NULLS, yang berarti mengembalikan apa pun yang ada di posisi yang diminta meskipun NULL. Sayangnya, klausa ini belum tersedia di T-SQL. Saya akan memberikan contoh untuk sintaks standar menggunakan fungsi LAG dan FIRST_VALUE, serta solusi yang berfungsi di T-SQL. Anda dapat menggunakan teknik serupa jika Anda membutuhkan fungsionalitas seperti itu dengan LEAD dan LAST_VALUE.
Sebagai contoh data, saya akan menggunakan tabel bernama T4 yang Anda buat dan isi menggunakan kode berikut:
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Ada tugas umum yang melibatkan pengembalian relevan terakhir nilai. NULL di col1 menunjukkan tidak ada perubahan nilai, sedangkan nilai non-NULL menunjukkan nilai baru yang relevan. Anda harus mengembalikan nilai col1 non-NULL terakhir berdasarkan pemesanan id. Menggunakan klausa perawatan NULL standar, Anda akan menangani tugas seperti ini:
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Inilah hasil yang diharapkan dari kueri ini:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
Ada solusi di T-SQL, tetapi ini melibatkan dua lapisan fungsi jendela dan ekspresi tabel.
Pada langkah pertama, Anda menggunakan fungsi jendela MAX untuk menghitung kolom bernama grp yang menyimpan nilai id maksimum sejauh ini ketika col1 bukan NULL, seperti:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Kode ini menghasilkan output berikut:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Seperti yang Anda lihat, nilai grp unik dibuat setiap kali ada perubahan nilai col1.
Pada langkah kedua Anda menentukan CTE berdasarkan kueri dari langkah pertama. Kemudian, di kueri luar Anda mengembalikan nilai col1 maksimum sejauh ini, di dalam setiap partisi yang ditentukan oleh grp. Itu nilai col1 non-NULL terakhir. Berikut kode solusi lengkapnya:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; Jelas, itu lebih banyak kode dan pekerjaan dibandingkan dengan hanya mengatakan IGNORE_NULLS.
Kebutuhan umum lainnya adalah mengembalikan nilai relevan pertama. Dalam kasus kami, misalkan Anda perlu mengembalikan nilai col1 non-NULL pertama sejauh ini berdasarkan pemesanan id. Menggunakan klausa perlakuan NULL standar, Anda akan menangani tugas dengan fungsi FIRST_VALUE dan opsi IGNORE NULLS, seperti:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Inilah hasil yang diharapkan dari kueri ini:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
Solusi di T-SQL menggunakan teknik yang mirip dengan yang digunakan untuk nilai non-NULL terakhir, hanya saja, alih-alih pendekatan MAX ganda, Anda menggunakan fungsi FIRST_VALUE di atas fungsi MIN.
Pada langkah pertama, Anda menggunakan fungsi jendela MIN untuk menghitung kolom yang disebut grp yang memegang nilai id minimum sejauh ini ketika col1 bukan NULL, seperti:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Kode ini menghasilkan output berikut:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
Jika ada NULL yang ada sebelum nilai relevan pertama, Anda akan mendapatkan dua grup—yang pertama dengan NULL sebagai nilai grp dan yang kedua dengan id non-NULL pertama sebagai nilai grp.
Pada langkah kedua Anda menempatkan kode langkah pertama dalam ekspresi tabel. Kemudian di kueri luar Anda menggunakan fungsi FIRST_VALUE, dipartisi oleh grp, untuk mengumpulkan nilai relevan pertama (non-NULL) jika ada, dan NULL jika tidak, seperti:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Sekali lagi, itu banyak kode dan pekerjaan dibandingkan dengan hanya menggunakan opsi IGNORE_NULLS.
Jika Anda merasa fitur ini berguna bagi Anda, Anda dapat memilih untuk memasukkannya ke dalam T-SQL di sini.
PESAN DENGAN NULLS TERLEBIH DAHULU | NULLS TERAKHIR
Saat Anda memesan data, baik untuk tujuan presentasi, windowing, pemfilteran TOP/OFFSET-FETCH, atau tujuan lainnya, ada pertanyaan tentang bagaimana NULL harus berperilaku dalam konteks ini? Standar SQL mengatakan bahwa NULL harus diurutkan bersama sebelum atau sesudah non-NULL, dan mereka menyerahkannya pada implementasi untuk menentukan satu atau lain cara. Namun, apa pun yang dipilih vendor, itu harus konsisten. Dalam T-SQL, NULL diurutkan terlebih dahulu (sebelum non-NULL) saat menggunakan urutan menaik. Pertimbangkan kueri berikut sebagai contoh:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Kueri ini menghasilkan keluaran berikut:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
Output menunjukkan bahwa pesanan yang belum terkirim, yang memiliki tanggal pengiriman NULL, memesan sebelum pesanan terkirim, yang memiliki tanggal pengiriman yang berlaku.
Tetapi bagaimana jika Anda membutuhkan NULL untuk memesan terakhir saat menggunakan urutan menaik? Standar ISO/IEC SQL mendukung klausa yang Anda terapkan pada ekspresi pengurutan yang mengontrol apakah NULL memesan pertama atau terakhir. Sintaks dari klausa ini adalah:
Untuk menangani kebutuhan kami, mengembalikan pesanan yang diurutkan berdasarkan tanggal pengiriman, menaik, tetapi dengan pesanan yang belum terkirim dikembalikan terakhir, dan kemudian dengan ID pesanan mereka sebagai tiebreak, Anda akan menggunakan kode berikut:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Sayangnya, klausa pemesanan NULLS ini tidak tersedia di T-SQL.
Solusi umum yang digunakan orang dalam T-SQL adalah mendahului ekspresi pengurutan dengan ekspresi CASE yang mengembalikan konstanta dengan nilai pengurutan yang lebih rendah untuk nilai non-NULL daripada untuk NULL, seperti ini (kami akan menyebut solusi ini Kueri 1):
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Kueri ini menghasilkan keluaran yang diinginkan dengan NULL yang muncul terakhir:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
Ada indeks penutup yang ditentukan pada tabel Sales.Orders, dengan kolom tanggal pengiriman sebagai kuncinya. Namun, serupa dengan cara kolom pemfilteran yang dimanipulasi mencegah kemampuan SARG dari filter dan kemampuan untuk menerapkan indeks pencarian, kolom pengurutan yang dimanipulasi mencegah kemampuan untuk mengandalkan pengurutan indeks untuk mendukung klausa ORDER BY kueri. Oleh karena itu, SQL Server membuat rencana untuk Query 1 dengan operator Sort yang eksplisit, seperti yang ditunjukkan pada Gambar 1.
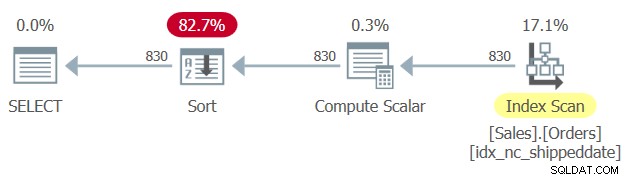 Gambar 1:Rencana untuk Kueri 1
Gambar 1:Rencana untuk Kueri 1
Terkadang ukuran data tidak terlalu besar sehingga penyortiran eksplisit menjadi masalah. Tapi terkadang memang begitu. Dengan penyortiran eksplisit, skalabilitas kueri menjadi ekstra-linear (Anda membayar lebih banyak per baris, semakin banyak baris yang Anda miliki), dan waktu respons (waktu yang dibutuhkan baris pertama untuk dikembalikan) tertunda.
Ada trik yang dapat Anda gunakan untuk menghindari pengurutan eksplisit dalam kasus seperti itu dengan solusi yang dioptimalkan menggunakan operator Merge Join Concatenation yang mempertahankan pesanan. Anda dapat menemukan cakupan rinci dari teknik ini yang digunakan dalam skenario yang berbeda di SQL Server:Menghindari Sortir dengan Merge Join Concatenation. Langkah pertama dalam solusi menyatukan hasil dua kueri:satu kueri mengembalikan baris di mana kolom pengurutan bukan NULL dengan kolom hasil (kita akan menyebutnya sortcol) berdasarkan konstanta dengan beberapa nilai pengurutan, katakanlah 0, dan kueri lain yang mengembalikan baris dengan NULL, dengan sortcol disetel ke konstanta dengan nilai pengurutan yang lebih tinggi daripada di kueri pertama, katakanlah 1. Pada langkah kedua, Anda kemudian menentukan ekspresi tabel berdasarkan kode dari langkah pertama, lalu di kueri luar Anda mengurutkan baris dari ekspresi tabel terlebih dahulu dengan sortcol, lalu dengan elemen pengurutan yang tersisa. Berikut kode solusi lengkap yang menerapkan teknik ini (kami akan menyebut solusi ini Query 2):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
Rencana untuk kueri ini ditunjukkan pada Gambar 2.
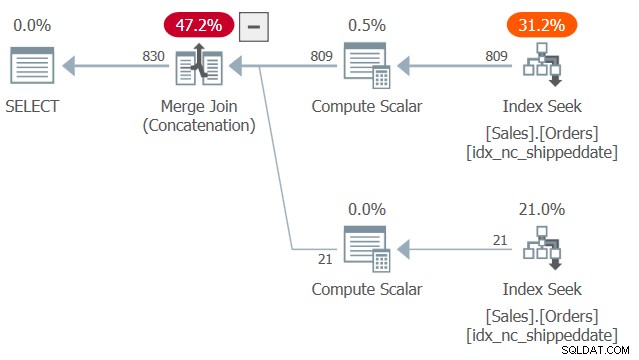 Gambar 2:Rencana untuk Kueri 2
Gambar 2:Rencana untuk Kueri 2
Perhatikan dua pencarian dan pemindaian rentang terurut dalam indeks penutup idx_nc_shippeddate—satu menarik baris di mana tanggal pengiriman bukan NULL dan satu lagi menarik baris dengan tanggal pengiriman NULL. Kemudian, mirip dengan cara kerja algoritma Gabung Gabung dalam gabungan, algoritma Gabung Gabung (Penggabungan) menyatukan baris dari dua sisi yang dipesan dengan cara seperti ritsleting, dan mempertahankan urutan yang diserap untuk mendukung kebutuhan pemesanan presentasi kueri. Saya tidak mengatakan bahwa teknik ini selalu lebih cepat daripada solusi yang lebih umum dengan ekspresi CASE, yang menggunakan penyortiran eksplisit. Namun, yang pertama memiliki penskalaan linier dan yang terakhir memiliki n log n penskalaan. Jadi yang pertama akan cenderung lebih baik dengan jumlah baris yang banyak dan yang terakhir dengan jumlah yang kecil.
Jelas ada baiknya memiliki solusi untuk kebutuhan bersama ini, tetapi akan jauh lebih baik jika T-SQL menambahkan dukungan untuk klausa pemesanan NULL standar di masa mendatang.
Kesimpulan
Standar ISO/IEC SQL memiliki cukup banyak fitur penanganan NULL yang belum mencapai T-SQL. Dalam artikel ini saya membahas beberapa di antaranya:predikat DISTINCT, klausa perawatan NULL, dan mengontrol apakah NULLs memesan pertama atau terakhir. Saya juga menyediakan solusi untuk fitur-fitur ini yang didukung di T-SQL, tetapi mereka jelas tidak praktis. Bulan depan saya melanjutkan diskusi dengan membahas batasan unik standar, perbedaannya dengan implementasi T-SQL dan solusi yang dapat diterapkan di T-SQL.