Rekan kerja saya Steve Wright (blog | @SQL_Steve) mendorong saya dengan pertanyaan baru-baru ini tentang hasil aneh yang dia lihat. Untuk menguji beberapa fungsionalitas di alat terbaru kami, SQL Sentry Plan Explorer PRO, dia telah membuat tabel lebar dan besar, dan menjalankan berbagai kueri terhadapnya. Dalam satu kasus dia mengembalikan banyak data, tetapi STATISTICS IO menunjukkan bahwa sangat sedikit pembacaan yang terjadi. Saya melakukan ping ke beberapa orang di #sqlhelp dan, karena sepertinya tidak ada yang melihat masalah ini, saya pikir saya akan membuat blog tentangnya.
TL;DR Versi
Singkatnya, perhatikan bahwa ada beberapa skenario di mana Anda tidak dapat mengandalkan STATISTICS IO untuk mengatakan yang sebenarnya. Dalam beberapa kasus (yang ini melibatkan TOP dan paralelisme), itu akan sangat mengurangi pembacaan logis. Ini dapat membuat Anda percaya bahwa Anda memiliki kueri yang sangat ramah I/O padahal tidak. Ada kasus lain yang lebih jelas – seperti ketika Anda memiliki banyak I/O yang disembunyikan dengan menggunakan fungsi skalar yang ditentukan pengguna. Kami pikir Plan Explorer membuat kasus tersebut lebih jelas; yang ini, bagaimanapun, sedikit lebih rumit.
Pertanyaan masalah
Tabel memiliki 37 juta baris, hingga 250 byte per baris, sekitar 1 juta halaman, dan fragmentasi yang sangat rendah (0,42% pada level 0, 15% pada level 1, dan 0 lebih dari itu). Tidak ada kolom yang dihitung, tidak ada UDF yang dimainkan, dan tidak ada indeks kecuali kunci utama yang dikelompokkan pada INT terkemuka kolom. Kueri sederhana yang mengembalikan 500.000 baris, semua kolom, menggunakan TOP dan SELECT * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(Dan ya, saya menyadari bahwa saya melanggar aturan saya sendiri dan menggunakan SELECT * dan TOP tanpa ORDER BY , tetapi demi kesederhanaan, saya mencoba yang terbaik untuk meminimalkan pengaruh saya pada pengoptimal.)
Hasil:
(500.000 baris terpengaruh)Tabel 'OrderHistory'. Hitungan pindai 1, pembacaan logis 23, pembacaan fisik 0, pembacaan depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Kami mengembalikan 500.000 baris, dan dibutuhkan sekitar 10 detik. Saya segera tahu ada yang salah dengan angka pembacaan logis. Bahkan jika saya belum tahu tentang data yang mendasarinya, saya dapat mengetahui dari hasil kisi di Management Studio bahwa ini menarik lebih dari 23 halaman data, apakah itu dari memori atau cache, dan ini harus tercermin di suatu tempat di STATISTICS IO . Melihat rencananya…
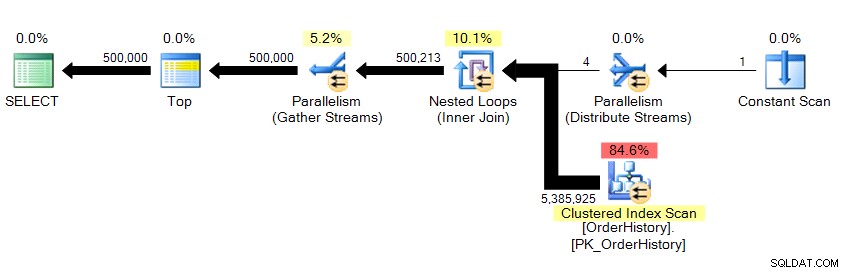
…kami melihat paralelisme ada di sana, dan kami telah memindai seluruh tabel. Jadi bagaimana mungkin hanya ada 23 pembacaan logis?
Kueri "identik" lainnya
Salah satu pertanyaan pertama saya kembali ke Steve adalah:"Apa yang terjadi jika Anda menghilangkan paralelisme?" Jadi saya mencobanya. Saya mengambil versi subquery asli dan menambahkan MAXDOP 1 :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Hasil dan rencana:
(500.000 baris terpengaruh)Tabel 'OrderHistory'. Hitungan pindai 1, pembacaan logis 149589, pembacaan fisik 0, pembacaan depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
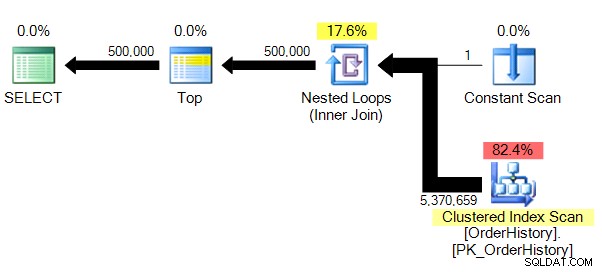
Kami memiliki rencana yang sedikit kurang rumit, dan tanpa paralelisme (untuk alasan yang jelas), STATISTICS IO menunjukkan kepada kita angka yang jauh lebih dapat dipercaya untuk jumlah pembacaan logis.
Apa kebenarannya?
Tidak sulit untuk melihat bahwa salah satu pertanyaan ini tidak mengatakan yang sebenarnya. Sementara STATISTICS IO mungkin tidak menceritakan keseluruhan cerita, mungkin jejak akan. Jika kami mengambil metrik waktu proses dengan membuat rencana eksekusi aktual di Plan Explorer, kami melihat bahwa kueri baca rendah yang ajaib, pada kenyataannya, menarik data dari memori atau disk, dan bukan dari awan debu peri ajaib. Bahkan ia memiliki *lebih banyak* bacaan daripada versi lainnya:

Jadi jelas bahwa pembacaan sedang terjadi, hanya saja tidak muncul dengan benar di STATISTICS IO keluaran.
Apa masalahnya?
Yah, saya akan cukup jujur:Saya tidak tahu, selain fakta bahwa paralelisme pasti memainkan peran, dan tampaknya menjadi semacam kondisi balapan. STATISTICS IO (dan, karena di situlah kami mendapatkan data, tab Tabel I/O kami) menunjukkan jumlah pembacaan yang sangat menyesatkan. Jelas bahwa kueri mengembalikan semua data yang kami cari, dan jelas dari hasil penelusuran bahwa kueri menggunakan pembacaan dan bukan osmosis untuk melakukannya. Saya bertanya kepada Paul White (blog | @SQL_Kiwi) tentang hal itu dan dia menyarankan bahwa hanya beberapa jumlah I/O pra-utas yang disertakan dalam total (dan setuju bahwa ini adalah bug).
Jika Anda ingin mencoba ini di rumah, yang Anda butuhkan hanyalah AdventureWorks (ini harus repro terhadap versi 2008, 2008 R2 dan 2012), dan kueri berikut:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Perhatikan bahwa SETCPUWEIGHT hanya digunakan untuk membujuk paralelisme. Untuk info lebih lanjut, lihat posting blog Paul White di Plan Costing.)
Hasil:
Tabel 'SalesOrderHeader'. Hitungan pindai 1, pembacaan logis 4, pembacaan fisik 0, pembacaan depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.Tabel 'SalesOrderHeader'. Hitungan pemindaian 1, pembacaan logis 333, pembacaan fisik 0, pembacaan ke depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob membaca 0.
Paul menunjukkan kesalahan yang lebih sederhana:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Hasil:
Tabel 'Riwayat Transaksi'. Hitungan pemindaian 1, pembacaan logis 5, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob pembacaan 0.Tabel 'TransactionHistory'. Hitungan pemindaian 1, pembacaan logis 110, pembacaan fisik 0, pembacaan depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Jadi sepertinya kita dapat dengan mudah mereproduksi ini sesuka hati dengan TOP operator dan DOP yang cukup rendah. Saya telah mengajukan bug:
- STATISTICS IO kurang melaporkan pembacaan logis untuk paket paralel
Dan Paul telah mengajukan dua bug lain yang agak terkait yang melibatkan paralelisme, yang pertama sebagai hasil dari percakapan kami:
- Kesalahan Estimasi Kardinalitas Dengan Predikat yang Ditekan pada Pencarian [ posting blog terkait ]
- Kinerja Buruk dengan Paralelisme dan [ postingan blog terkait ]
(Untuk nostalgia, berikut adalah enam bug paralelisme lain yang saya tunjukkan beberapa tahun yang lalu.)
Apa pelajarannya?
Berhati-hatilah dalam mempercayai satu sumber. Jika Anda hanya melihat STATISTICS IO setelah mengubah kueri seperti ini, Anda mungkin tergoda untuk fokus pada penurunan ajaib dalam pembacaan alih-alih peningkatan durasi. Pada titik mana Anda dapat menepuk punggung Anda, meninggalkan pekerjaan lebih awal dan menikmati akhir pekan Anda, berpikir Anda baru saja membuat dampak kinerja yang luar biasa pada kueri Anda. Ketika tentu saja tidak ada yang lebih jauh dari kebenaran.



