Perutean transaksi musim semi
Pertama, kita akan membuat DataSourceType Java Enum yang mendefinisikan opsi perutean transaksi kami:
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
Untuk merutekan transaksi baca-tulis ke node Primer dan transaksi hanya baca ke node Replica, kita dapat mendefinisikan ReadWriteDataSource yang menghubungkan ke node Primer dan ReadOnlyDataSource yang terhubung ke node Replika.
Perutean transaksi baca-tulis dan baca-saja dilakukan oleh AbstractRoutingDataSource Spring abstraksi, yang diimplementasikan oleh TransactionRoutingDatasource , seperti yang diilustrasikan oleh diagram berikut:
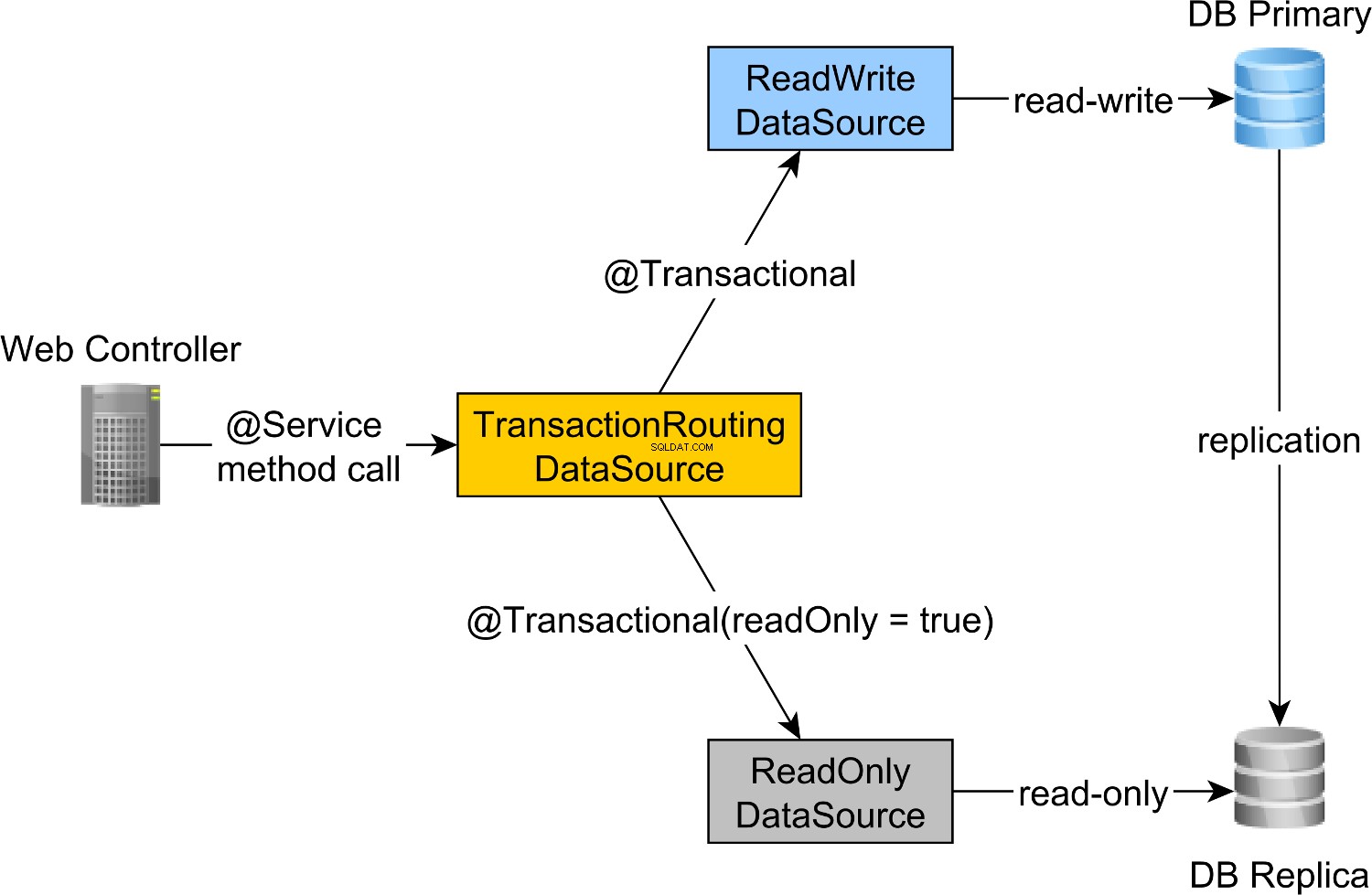
TransactionRoutingDataSource sangat mudah diimplementasikan dan terlihat sebagai berikut:
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
Pada dasarnya, kami memeriksa Spring TransactionSynchronizationManager class yang menyimpan konteks transaksional saat ini untuk memeriksa apakah transaksi Spring yang sedang berjalan adalah hanya-baca atau tidak.
determineCurrentLookupKey metode mengembalikan nilai diskriminator yang akan digunakan untuk memilih DataSource read-write atau read-only JDBC .
Konfigurasi musim semi baca-tulis dan baca-saja JDBC DataSource
DataSource konfigurasi terlihat sebagai berikut:
@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
/META-INF/jdbc-postgresql-replication.properties file resource menyediakan konfigurasi untuk JDBC baca-tulis dan baca-saja DataSource komponen:
hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
jdbc.url.primary properti mendefinisikan URL dari node Primer sedangkan jdbc.url.replica mendefinisikan URL dari node Replika.
readWriteDataSource Komponen pegas mendefinisikan DataSource baca-tulis JDBC sedangkan readOnlyDataSource komponen mendefinisikan DataSource JDBC hanya-baca .
Perhatikan bahwa sumber data baca-tulis dan baca-saja menggunakan HikariCP untuk penyatuan koneksi.
actualDataSource bertindak sebagai fasad untuk sumber data baca-tulis dan baca-saja dan diimplementasikan menggunakan TransactionRoutingDataSource utilitas.
readWriteDataSource terdaftar menggunakan DataSourceType.READ_WRITE kunci dan readOnlyDataSource menggunakan DataSourceType.READ_ONLY kunci.
Jadi, saat menjalankan @Transactional baca-tulis metode, readWriteDataSource akan digunakan saat menjalankan @Transactional(readOnly = true) metode, readOnlyDataSource akan digunakan sebagai gantinya.
Perhatikan bahwa
additionalPropertiesmetode mendefinisikanhibernate.connection.provider_disables_autocommitProperti Hibernate, yang saya tambahkan ke Hibernate untuk menunda akuisisi database untuk transaksi RESOURCE_LOCAL JPA.Tidak hanya itu
hibernate.connection.provider_disables_autocommitmemungkinkan Anda untuk memanfaatkan koneksi database dengan lebih baik, tetapi ini adalah satu-satunya cara kami dapat membuat contoh ini berfungsi karena, tanpa konfigurasi ini, koneksi diperoleh sebelum memanggildetermineCurrentLookupKeymetodeTransactionRoutingDataSource.
Komponen Spring yang tersisa diperlukan untuk membangun EntityManagerFactory JPA didefinisikan oleh AbstractJPAConfiguration kelas dasar.
Pada dasarnya, actualDataSource selanjutnya dibungkus oleh DataSource-Proxy dan diberikan ke EntityManagerFactory JPA . Anda dapat memeriksa kode sumber di GitHub untuk detail lebih lanjut.
Waktu pengujian
Untuk memeriksa apakah perutean transaksi berfungsi, kita akan mengaktifkan log kueri PostgreSQL dengan mengatur properti berikut di postgresql.conf file konfigurasi:
log_min_duration_statement = 0
log_line_prefix = '[%d] '
log_min_duration_statement pengaturan properti adalah untuk mencatat semua pernyataan PostgreSQL sementara yang kedua menambahkan nama database ke log SQL.
Jadi, saat memanggil newPost dan findAllPostsByTitle metode, seperti ini:
Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
Kita dapat melihat bahwa PostgreSQL mencatat pesan berikut:
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
Pernyataan log menggunakan high_performance_java_persistence awalan dieksekusi pada node Utama sedangkan yang menggunakan high_performance_java_persistence_replica pada simpul Replika.
Jadi, semuanya bekerja seperti pesona!
Semua kode sumber dapat ditemukan di repositori GitHub Java Persistence High-Persistence saya, sehingga Anda dapat mencobanya juga.
Kesimpulan
Anda perlu memastikan bahwa Anda mengatur ukuran yang tepat untuk kumpulan koneksi Anda karena itu dapat membuat perbedaan besar. Untuk ini, saya sarankan menggunakan Flexy Pool.
Anda harus sangat rajin dan memastikan Anda menandai semua transaksi hanya-baca. Tidak biasa bahwa hanya 10% dari transaksi Anda yang bersifat read-only. Mungkinkah Anda memiliki aplikasi paling banyak menulis atau Anda menggunakan transaksi tulis di mana Anda hanya mengeluarkan pernyataan kueri?
Untuk pemrosesan batch, Anda pasti membutuhkan transaksi read-write, jadi pastikan Anda mengaktifkan batching JDBC, seperti ini:
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
Untuk pengelompokan, Anda juga dapat menggunakan DataSource yang terpisah yang menggunakan kumpulan koneksi berbeda yang terhubung ke node Utama.
Pastikan ukuran total koneksi Anda dari semua kumpulan koneksi kurang dari jumlah koneksi yang telah dikonfigurasi dengan PostgreSQL.
Setiap tugas batch harus menggunakan transaksi khusus, jadi pastikan Anda menggunakan ukuran batch yang wajar.
Lebih dari itu, Anda ingin menahan kunci dan menyelesaikan transaksi secepat mungkin. Jika prosesor batch menggunakan pekerja pemrosesan bersamaan, pastikan ukuran kumpulan koneksi terkait sama dengan jumlah pekerja, sehingga mereka tidak menunggu orang lain melepaskan koneksi.