“Waitstats membantu kami mengidentifikasi penghitung terkait kinerja. Tetapi menunggu informasi saja tidak cukup untuk mendiagnosis masalah kinerja secara akurat. Komponen antrian dari metodologi kami berasal dari penghitung Monitor Kinerja, yang memberikan tampilan kinerja sistem dari sudut pandang sumber daya.”Tom Davidson, Membuka Kotak Alat Penyesuaian Kinerja Microsoft
SQL Server Pro Magazine, Desember 2003
Waits and Queues telah digunakan sebagai metodologi penyetelan kinerja SQL Server sejak Tom Davidson menerbitkan artikel di atas serta whitepaper SQL Server 2005 Waits and Queues yang terkenal pada tahun 2006. Ketika diterapkan dalam kombinasi dengan metrik sumber daya, menunggu dapat bermanfaat untuk menilai karakteristik kinerja tertentu dari beban kerja dan membantu upaya penyetelan kemudi. Data tunggu ditampilkan oleh banyak solusi pemantauan kinerja SQL Server, dan saya telah menganjurkan penyetelan menggunakan metodologi ini sejak awal. Pendekatan tersebut berpengaruh dalam desain dasbor kinerja SQL Sentry, yang menyajikan waktu tunggu yang diapit oleh antrean (metrik sumber daya utama) untuk memberikan tampilan kinerja server yang komprehensif.
Namun, beberapa tampaknya telah melewatkan poin Davidson mengenai pentingnya sumber daya dan hampir sepenuhnya bergantung pada menunggu untuk menyajikan gambaran kinerja kueri dan kesehatan sistem. Statistik tunggu datang langsung dari mesin SQL Server dan mudah dikonsumsi dan dikategorikan. Kueri menunggu berarti menunggu aplikasi dan pengguna, dan tidak ada yang suka menunggu! Lebih mudah untuk memulai penyetelan dengan menunggu sebagai solusi tunggal untuk membuat kueri dan aplikasi lebih cepat daripada menceritakan kisah lengkapnya, yang lebih melibatkan.
Sayangnya, pendekatan yang berfokus pada menunggu dengan mengesampingkan analisis sumber daya dapat menyesatkan, dan kasus terburuk membuat Anda buta. Anggota tim SentryOne Kevin Kline dan Steve Wright sebelumnya telah membahas ini di sini dan di sini. Dalam postingan ini, saya akan membahas lebih dalam tentang beberapa penelitian terbaru yang dimungkinkan oleh Query Store yang telah memberikan pencerahan baru tentang bagaimana sebenarnya kekurangan penyetelan eksklusif menunggu.
Kueri Teratas yang Bukan
Baru-baru ini, pelanggan SentryOne menghubungi saya tentang masalah kinerja dengan database SentryOne mereka. Ada satu database SQL Server di jantung setiap lingkungan pemantauan SentryOne, dan pelanggan ini memantau sekitar 600 server dengan perangkat lunak kami. Pada skala itu, bukan hal yang aneh untuk melihat masalah kinerja kueri sesekali dan melakukan sedikit penyesuaian, dan beberapa kueri yang dianggap baru dalam beban kerja menjadi sumber kekhawatiran mereka.
Saya bergabung dalam sesi berbagi layar untuk melihat, dan pelanggan pertama kali memberi saya data dari sistem berbeda yang juga memantau database SentryOne. Sistem menggunakan pendekatan menunggu tingkat kueri dan menunjukkan dua prosedur tersimpan yang bertanggung jawab atas kira-kira setengah dari menunggu di server database SQL Sentry. Ini tidak biasa karena kedua prosedur ini selalu berjalan sangat cepat dan tidak pernah menunjukkan masalah kinerja nyata dalam database kami. Bingung, saya beralih ke SQL Sentry untuk melihat apa yang akan ditunjukkannya kepada kita, dan terkejut melihat bahwa pada interval yang sama prosedur #1 di sistem lain adalah #6, #7 dan #8 dalam hal durasi total, CPU dan pembacaan logis masing-masing:
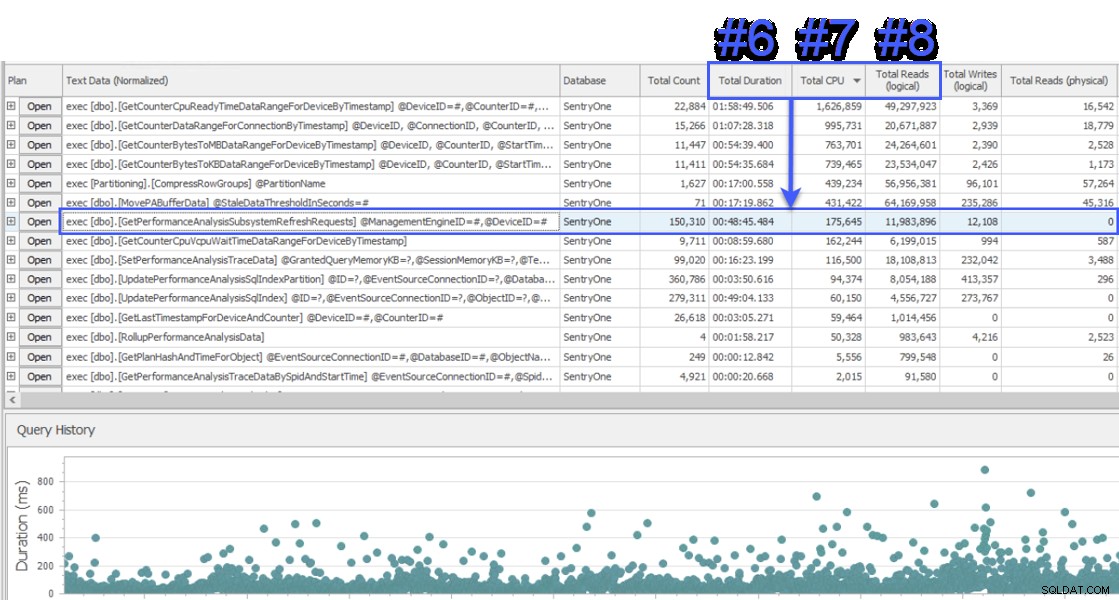 Tampilan “SQL Teratas” SQL Sentry
Tampilan “SQL Teratas” SQL Sentry
Dari sudut pandang konsumsi sumber daya, ini berarti bahwa kueri di atasnya mewakili 75% dari total durasi, 87% dari total CPU, dan 88% dari pembacaan logis. Selain itu, prosedur # 2 di sistem lain bahkan tidak masuk dalam 30 besar di SQL Sentry, dengan ukuran apa pun! Kedua kueri ini jauh dari 2 kueri teratas, dan kueri yang menyumbang sebagian besar aktual konsumsi pada sistem sangat kurang terwakili.
Saya selalu berasumsi bahwa ada korelasi yang lebih kuat antara pelayan teratas dan konsumen sumber daya teratas tetapi tidak pernah melakukan perbandingan tingkat kueri langsung seperti ini, jadi hasil ini setidaknya mengejutkan. Ketertarikan saya terusik, saya memutuskan untuk menyelidiki untuk menentukan apakah situasi ini tipikal atau anomali.
Penyimpanan Kueri 2017 untuk Menyelamatkan
Di SQL Server 2017 dan di atasnya, penyimpanan kueri menangkap tingkat kueri menunggu selain konsumsi sumber daya kueri. Erin Stellato melakukan posting yang bagus di Query Store menunggu di sini. Ini overhead yang lebih rendah dan lebih akurat daripada kueri menunggu DMV setiap detik dengan harapan dapat menangkap kueri dalam penerbangan, pendekatan standar yang digunakan oleh alat lain termasuk yang disebutkan di atas.
SQL Sentry selalu menangkap waktu tunggu tetapi pada tingkat instance SQL Server, karena kekhawatiran tentang overhead dan akurasi ini. Waktu tunggu kueri yang mendetail tersedia sesuai permintaan melalui Plan Explorer yang terintegrasi, dan kami sedang mengevaluasi penambahan waktu tunggu tingkat instans dengan data tingkat kueri dari Penyimpanan Kueri, jika tersedia.
Untuk upaya ini, saya meminta bantuan Dewan Penasihat Produk SentryOne, sekelompok pelanggan, mitra, dan teman SentryOne di industri yang berpartisipasi dalam saluran Slack pribadi. Saya membagikan skrip ini untuk membuang data 8 jam sebelumnya dari Query Store dan menerima hasil kembali untuk 11 server produksi di beberapa vertikal termasuk layanan keuangan, penerbitan game, pelacakan kebugaran, dan asuransi.
Kategori tunggu Toko Kueri didokumentasikan di sini. Semua kategori dimasukkan dalam analisis kecuali kategori ini, yang dihapus karena alasan yang dikutip:
- Paralelisme – Ini dapat secara liar meningkatkan waktu tunggu kueri jauh melewati durasi sebenarnya karena beberapa utas dapat membuang waktu tunggu yang terkait, mengacaukan korelasi dengan durasi dan metrik lainnya. Selanjutnya, meskipun pemisahan CXPACKET/CXCONSUMER berguna, CXPACKET tetap hanya berarti bahwa Anda memiliki paralelisme dan tidak selalu bermasalah atau dapat ditindaklanjuti.
- CPU – Waktu tunggu sinyal dapat membantu untuk memastikan kemacetan CPU melalui korelasi dengan menunggu sumber daya, tetapi Query Store saat ini hanya menyertakan SOS_SCHEDULER_YIELD dalam kategori ini, yang bukan menunggu dalam pengertian tradisional seperti yang dibahas di sini. Itu tidak cocok untuk perbandingan atau korelasi yang mudah, terutama ketika SQL Server ada di VM yang hidup di host yang berlangganan berlebihan. Misalnya, pada satu server, waktu tunggu CPU di Penyimpanan Kueri adalah 227% dari total waktu CPU di semua kueri tanpa paralelisme apa pun, yang seharusnya tidak dimungkinkan.
- Pengguna Tunggu dan Menganggur – Kategori ini secara eksklusif terdiri dari timer dan antrian menunggu dan dikecualikan untuk alasan yang sama yang harus selalu mengecualikan jenis ini – mereka tidak berbahaya dan hanya membuat kebisingan.
Selain itu, saya baru-baru ini berbicara dengan ayah dari Query Store, Conor Cunningham, tentang kemungkinan perubahan di masa mendatang pada jenis dan kategori tunggu Query Store dan dia menunjukkan bahwa itu pasti mungkin… jadi kita harus mengawasi itu.
Hasil Analisis TL;DR
Setelah analisis ekstensif, saya telah mengkonfirmasi bahwa hasil yang diamati pada sistem pelanggan tidak anomali, melainkan biasa. Ini berarti bahwa jika Anda bergantung pada alat yang berfokus pada menunggu untuk memantau dan menyesuaikan beban kerja Anda, kemungkinan besar Anda berfokus pada kueri yang salah dan melewatkan mereka yang bertanggung jawab atas sebagian besar durasi kueri dan konsumsi sumber daya pada sistem. Karena konsumsi CPU dan IO diterjemahkan langsung ke perangkat keras server dan pengeluaran cloud, ini signifikan.
Sebagian Besar Kueri Jangan Menunggu
Temuan menarik dan penting yang akan saya bahas terlebih dahulu adalah bahwa sebagian besar kueri tidak menghasilkan waktu tunggu sama sekali. Dari 56.438 total kueri di semua server, hanya 9.781 (17%) yang memiliki waktu tunggu, dan hanya 8.092 (14%) yang memiliki waktu tunggu dari jenis yang signifikan. Jika Anda menggunakan wait saja untuk menentukan kueri mana yang akan dioptimalkan, Anda akan kehilangan sebagian besar kueri dalam beban kerja.
Menghubungkan Waktu Tunggu dan Sumber Daya
Saya menganalisis bagaimana menunggu berhubungan dengan konsumsi sumber daya dengan memberi peringkat semua kueri pada setiap sistem dengan menunggu dan sumber daya dan menggunakan peringkat untuk menghitung korelasi Spearman. Apa yang pada akhirnya kami coba tentukan adalah apakah pelayan teratas cenderung menjadi konsumen teratas. Ternyata tidak.
Tabel 1 menunjukkan koefisien korelasi skala warna untuk rata-rata kueri tunggu waktu untuk ukuran lain – nilai 1,00 (biru tua) mewakili data yang berkorelasi sempurna. Seperti yang Anda lihat, korelasi dengan waktu tunggu dan ukuran lain di sebagian besar server tidak kuat, dan untuk satu server ada korelasi negatif dengan sebagian besar ukuran.
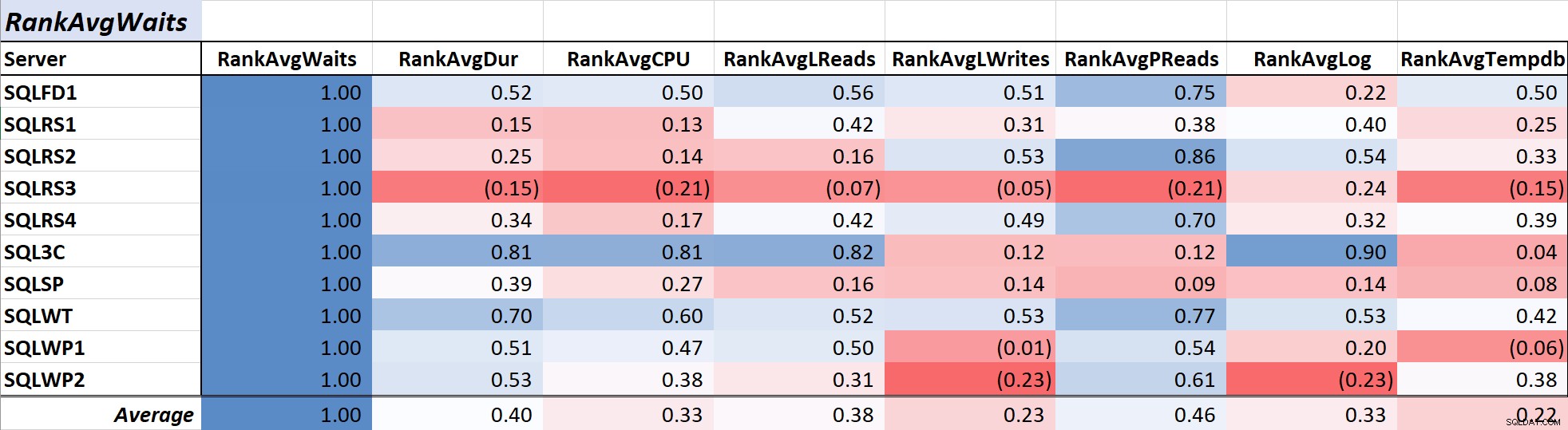 Tabel 1:Korelasi dengan Rata-Rata Waktu Tunggu Kueri (md)
Tabel 1:Korelasi dengan Rata-Rata Waktu Tunggu Kueri (md)
Durasi kueri sering menjadi perhatian utama DBA dan pengembang karena diterjemahkan langsung ke pengalaman pengguna, dan Tabel 2 menunjukkan korelasi antara rata-rata durasi kueri dan langkah-langkah lainnya. Korelasi dengan durasi dan dua ukuran sumber daya utama, CPU dan pembacaan logis, cukup kuat masing-masing di 0,97 dan ,75.
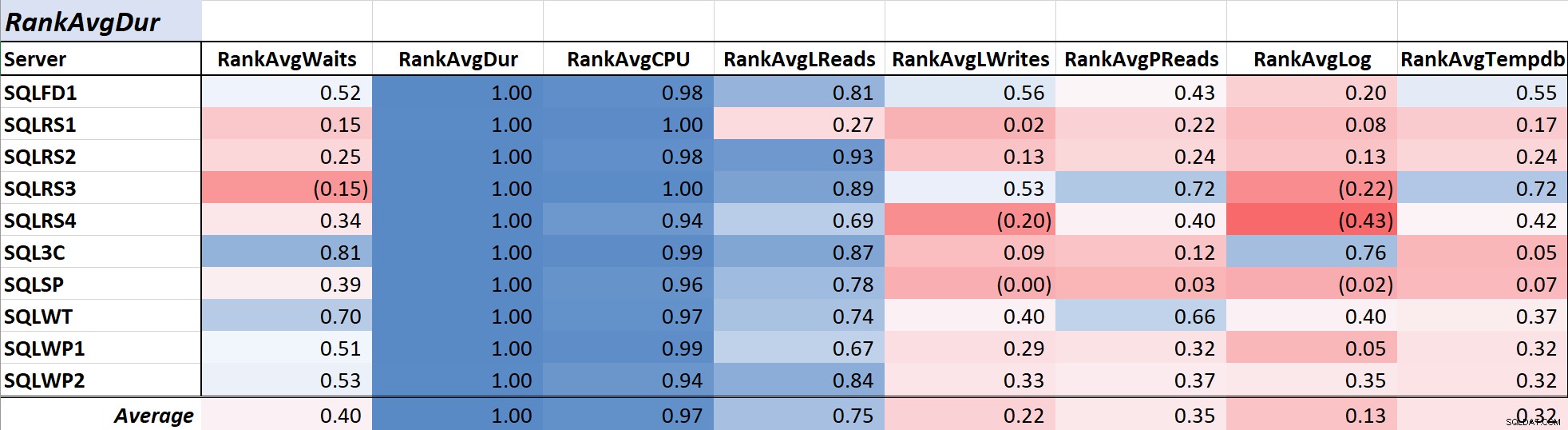 Tabel 2:Korelasi dengan Durasi Kueri Rata-rata (md)
Tabel 2:Korelasi dengan Durasi Kueri Rata-rata (md)
Karena pembacaan logis selalu menggunakan CPU, dan, seperti durasi, CPU diukur dalam milidetik, hubungan ini tidak mengejutkan. Hasilnya konsisten dengan gagasan bahwa jika Anda ingin aplikasi database Anda berjalan secepat mungkin, fokus pada pengurangan CPU kueri dan pembacaan logis akan lebih efektif dalam mengurangi durasi daripada menggunakan menunggu saja. Untungnya, melakukannya melalui desain kueri yang lebih baik, pengindeksan, dll. biasanya merupakan proposisi yang lebih mudah daripada mengurangi waktu tunggu kueri secara langsung. Kolega Aaron Bertrand secara efektif menyajikan beberapa peringatan saat menyetel dengan menunggu di sini.
% dari Total Waktu Tunggu
Selanjutnya, saya melihat apakah kueri dengan waktu tunggu tertinggi cenderung memperhitungkan konsumsi sumber daya paling banyak. Kami ingin menentukan apakah apa yang kami lihat di sistem pelanggan tidak biasa, di mana 2 kueri menunggu teratas mewakili persentase yang relatif kecil dari total konsumsi sumber daya.
Bagan 1 di bawah ini menunjukkan % dari total CPU dan pembacaan logis untuk setiap server yang diperhitungkan oleh kueri yang mewakili 75% dari total waktu tunggu. Hanya satu server yang memiliki sumber daya melebihi 75% – membaca di SQLRS3. Selebihnya, kueri yang bertanggung jawab atas 75% waktu tunggu menghabiskan kurang dari 75% sumber daya – seringkali jauh lebih sedikit. Ini mencerminkan apa yang kami lihat di sistem pelanggan dan konsisten dengan analisis korelasi.
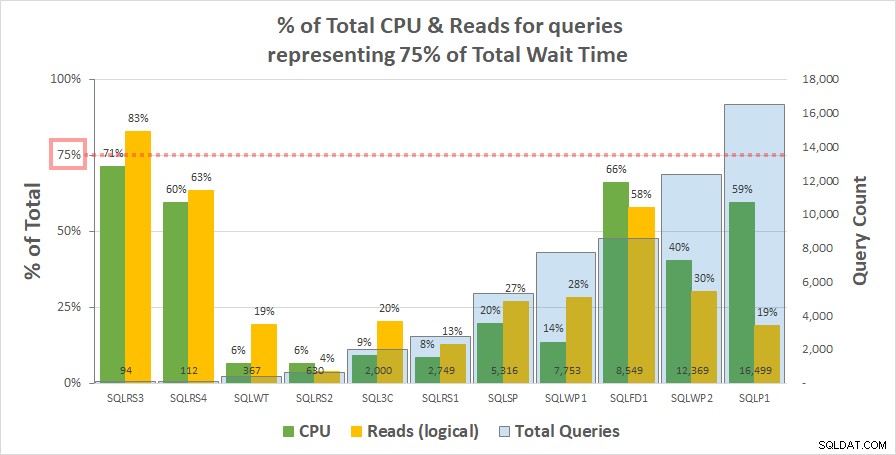 Bagan 1
Bagan 1
Perhatikan bahwa tampaknya ada hubungan dengan jumlah total kueri dalam beban kerja. Ini diwakili oleh rangkaian kolom biru muda pada sumbu y sekunder dan bagan diurutkan secara menaik menurut rangkaian ini. Dua server dengan ukuran sumber daya tertinggi pada 75% waktu tunggu juga memiliki kueri paling sedikit (SQLRS3 dan SQLRS4). Semakin kecil set beban kerja, semakin besar pengaruh potensial dari sejumlah kecil kueri, dan tentu saja, di kedua server hanya dua kueri yang menyumbang sebagian besar waktu tunggu dan sumber daya. Salah satu cara untuk melihat hal ini adalah menunggu sangat membantu untuk mengidentifikasi kueri terberat Anda saat Anda tidak membutuhkannya.
Waktu Tunggu dan Durasi Kueri
Terakhir, saya mengevaluasi % dari total waktu tunggu hingga total durasi kueri pada setiap sistem. Tabel 3 memiliki kolom untuk:
- Total durasi kueri dalam md
- Total waktu tunggu md – mentah
- Total waktu tunggu md – tanpa Paralelisme, Menganggur, dan Menunggu Pengguna (Rev1)
- Total waktu tunggu md – tanpa Paralelisme, Idle, Waktu Tunggu Pengguna, dan CPU (Rev2)
- % durasi untuk 3 kolom waktu tunggu, dengan bilah data
- Total jumlah kueri unik, dengan bilah data
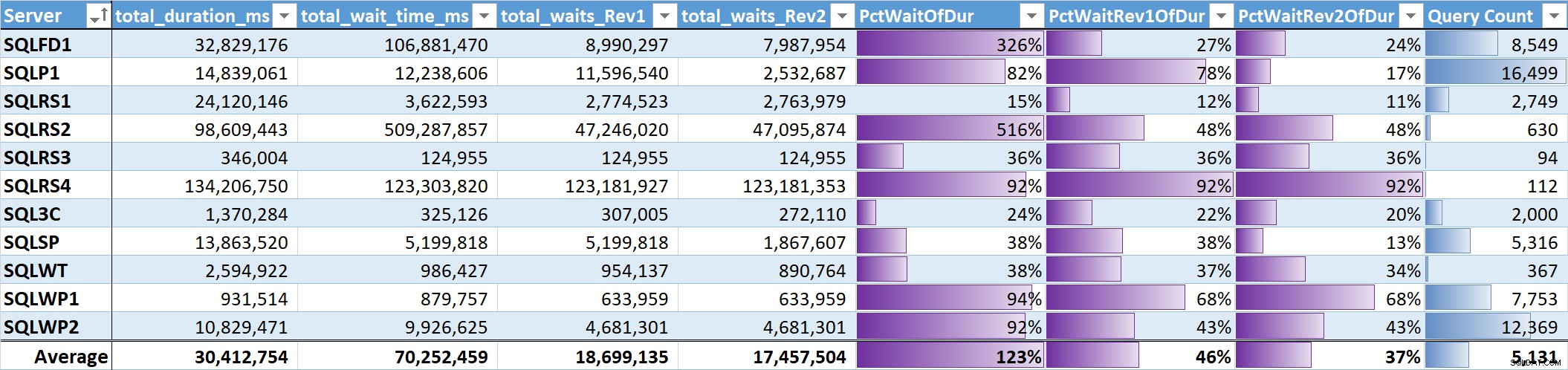 Tabel 3
Tabel 3
Rata-rata tidak tertimbang untuk penantian yang berarti (Rev2) di semua sistem adalah 37% dari total durasi kueri. Pada lima sistem itu kurang dari 25%, dan hanya pada dua sistem itu di atas 50%. Pada sistem dengan 92% waktu tunggu (SQLRS4), satu dengan kueri paling sedikit, dua kueri menyumbang 99% dari menunggu, 97% dari durasi, 84% dari CPU, dan 86% dari pembacaan.
Meskipun waktu tunggu dapat mewakili sebagian besar waktu proses kueri pada sistem tertentu, dan tampaknya intuitif bahwa jika Anda mengurangi waktu tunggu, durasi kueri juga akan turun, kami telah melihat bahwa waktu tunggu dan durasi berkorelasi lemah. Tidak mungkin sesederhana itu, dan pengalaman saya sendiri menguatkan hal ini. Penelitian lebih lanjut diperlukan di sini.
Penyetelan Komprehensif dengan Plan Explorer dan SQL Sentry
Seperti yang sering disarankan oleh whitepaper SQLskills yang luar biasa ini, akar dari penantian yang tinggi sering kali adalah kueri dan indeks yang tidak dioptimalkan. SentryOne Plan Explorer gratis dibuat khusus untuk mengurangi konsumsi sumber daya melalui penyetelan kueri yang efisien menggunakan modul Analisis Indeks dan banyak fitur inovatif lainnya. SQL Sentry mengintegrasikan Plan Explorer langsung ke modul Top SQL, Blocking, dan Deadlock, sehingga Anda dapat secara otomatis menangkap dan menyesuaikan kueri bermasalah di satu tempat. Anda dapat dengan mudah memilih rentang minat pada grafik tunggu historis, CPU, atau IO dasbor SQL Sentry dan melompat ke tampilan SQL Teratas untuk menemukan kueri yang menghabiskan banyak sumber daya selama waktu tersebut. Kemudian dengan satu klik, Anda dapat membuka kueri di Plan Explorer dan mendapatkan penantian tingkat kueri yang mendetail dan sumber daya sesuai permintaan saat dibutuhkan. Saya rasa tidak ada perwujudan yang lebih baik dari metodologi penyetelan Waits and Queues selain ini.
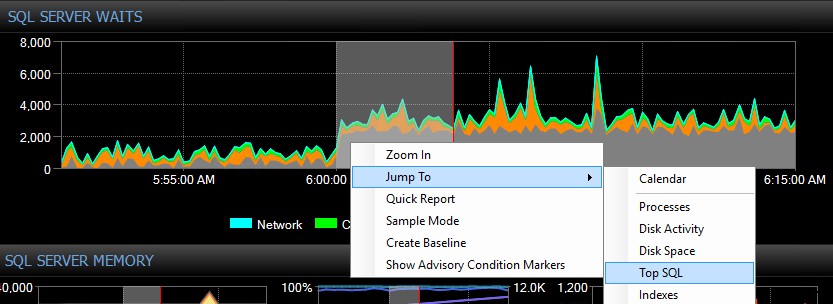 Bagan “Menunggu” Dasbor SQL Sentry
Bagan “Menunggu” Dasbor SQL Sentry
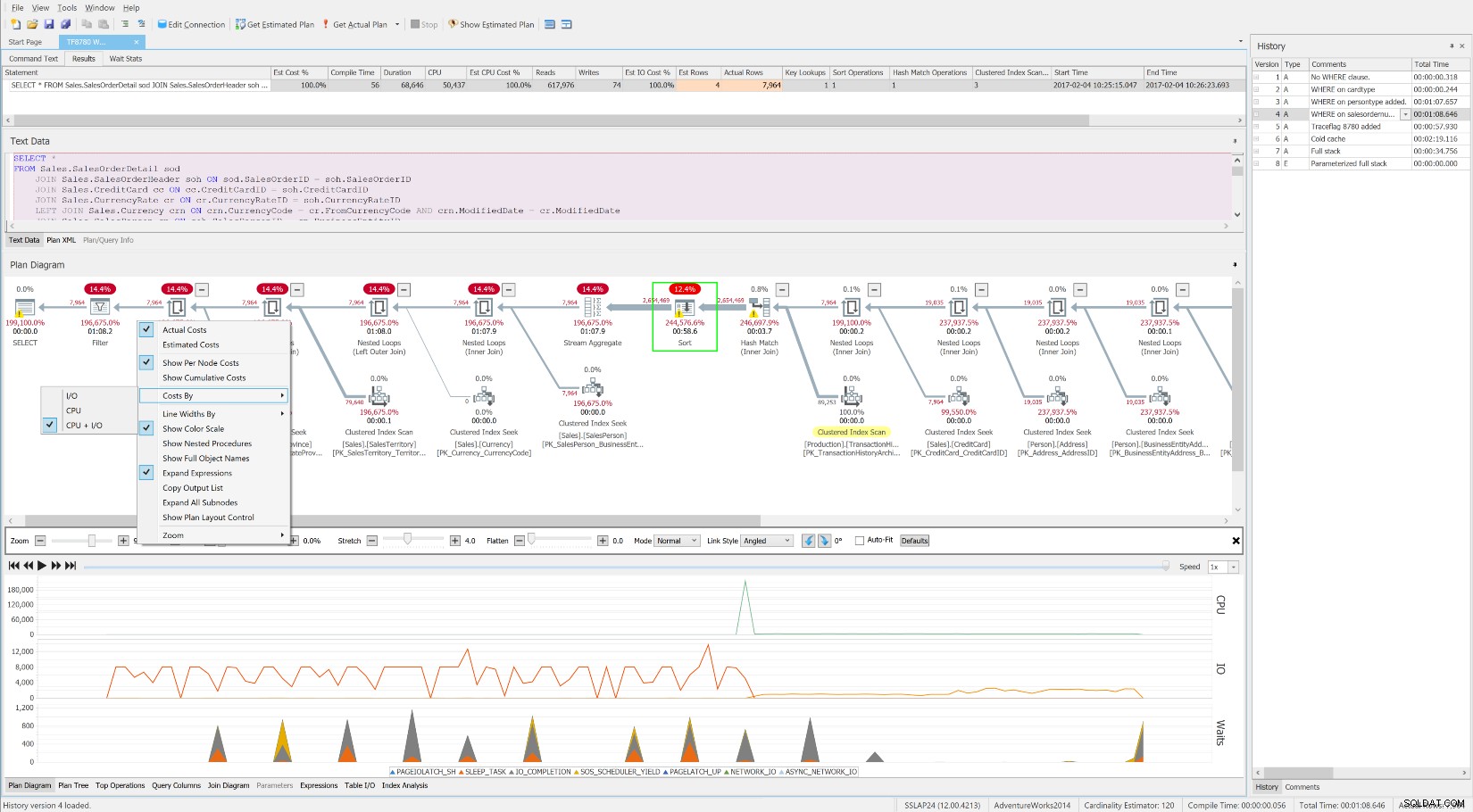 Penjelajah Paket SentryOne gratis yang ditampilkan menunggu seiring waktu, bersama dengan tingkat operasi biaya dan sumber daya
Penjelajah Paket SentryOne gratis yang ditampilkan menunggu seiring waktu, bersama dengan tingkat operasi biaya dan sumber daya
Kesimpulan
Penyetelan dengan menunggu dan antrian sama berlakunya untuk kinerja SQL Server hari ini seperti pada tahun 2006. Namun, berfokus pada menunggu dengan mengesampingkan sumber daya adalah bisnis yang berbahaya, karena jelas dari data bahwa hal itu akan menyebabkan umumnya tidak dioptimalkan dan sistem biaya yang tidak efisien. Dalam hal sumber daya perangkat keras dan pembelanjaan cloud, Anda pada akhirnya membayar untuk sumber daya komputasi dan IO, bukan waktu tunggu, jadi sebaiknya optimalkan langsung untuk konsumsi. Dalam pengalaman saya, saat konsumsi sumber daya dan pertentangan terkait diturunkan, waktu tunggu yang berkurang secara alami akan mengikuti.
Penghargaan
Saya ingin berterima kasih kepada Fred Frost, Ilmuwan Data Utama di SentryOne, atas masukannya yang berharga dan tinjauan kritisnya terhadap analisis ini.