[ Bagian 1 | Bagian 2 | Bagian 3 ]
Di bagian 1 dari seri ini, saya mencoba beberapa cara untuk mengompresi tabel 1TB. Sementara saya mendapatkan hasil yang layak dalam upaya pertama saya, saya ingin melihat apakah saya dapat meningkatkan kinerja di bagian 2. Di sana saya menguraikan beberapa hal yang saya pikir mungkin menjadi masalah kinerja, dan menjelaskan bagaimana saya akan lebih baik mempartisi tabel tujuan untuk kompresi penyimpanan kolom yang optimal. Saya sudah:
- mempartisi tabel menjadi 8 partisi (satu per inti);
- meletakkan file data setiap partisi pada filegroupnya sendiri; dan,
- mengatur kompresi arsip pada semua kecuali partisi "aktif".
Saya masih perlu membuatnya agar setiap penjadwal menulis secara eksklusif ke partisinya sendiri.
Pertama, saya perlu membuat perubahan pada tabel batch yang saya buat. Saya memerlukan kolom untuk menyimpan jumlah baris yang ditambahkan per batch (semacam pemeriksaan kewarasan yang mengaudit sendiri), dan waktu mulai/berakhir untuk mengukur kemajuan.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Selanjutnya, saya perlu membuat tabel untuk menyediakan afinitas – kami tidak pernah ingin lebih dari satu proses berjalan pada penjadwal apa pun, bahkan jika itu berarti kehilangan waktu untuk mencoba kembali logika. Jadi, kita memerlukan tabel yang akan melacak sesi apa pun pada penjadwal tertentu dan mencegah penumpukan:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Idenya adalah saya akan memiliki delapan contoh aplikasi (SQLQueryStress) yang masing-masing akan berjalan pada penjadwal khusus, hanya menangani data yang ditujukan untuk partisi / filegroup / file data tertentu, ~ 100 juta baris sekaligus (klik untuk memperbesar) :
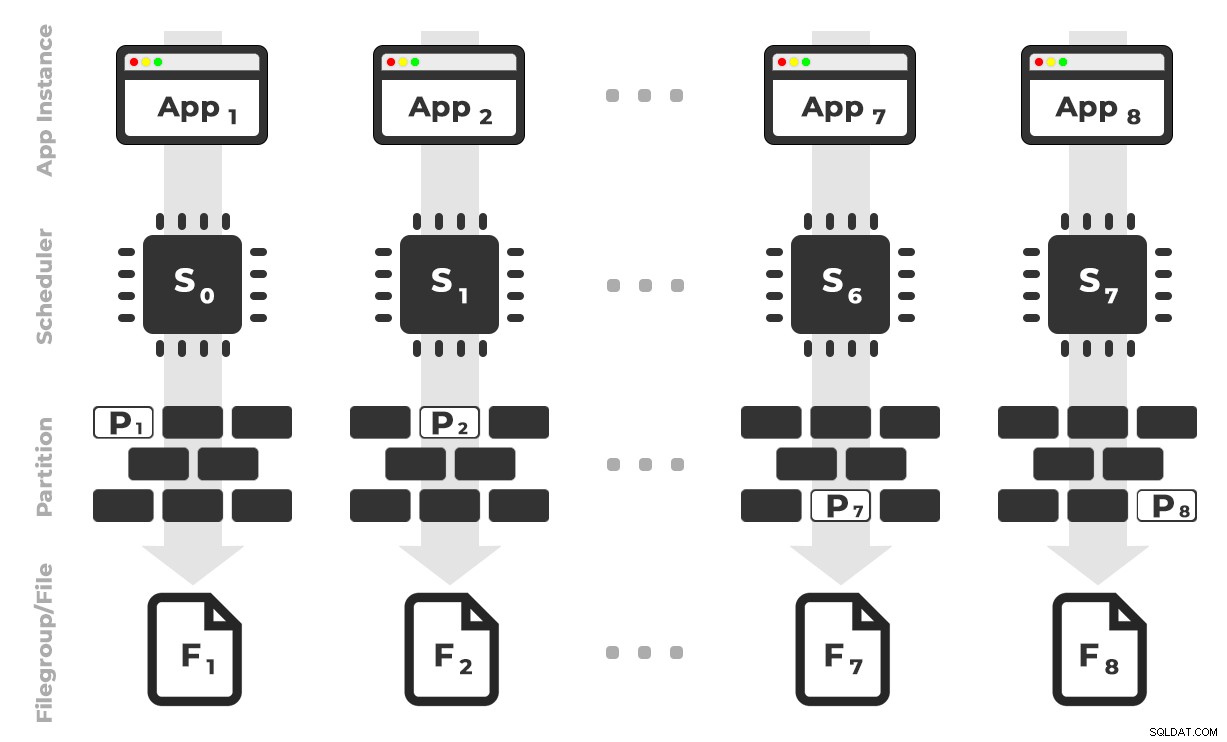 Aplikasi 1 mendapatkan penjadwal 0 dan menulis ke partisi 1 pada filegroup 1, dan seterusnya …
Aplikasi 1 mendapatkan penjadwal 0 dan menulis ke partisi 1 pada filegroup 1, dan seterusnya …
Selanjutnya kita memerlukan prosedur tersimpan yang akan memungkinkan setiap instance aplikasi untuk memesan waktu pada satu penjadwal. Seperti yang saya sebutkan di posting sebelumnya, ini bukan ide asli saya (dan saya tidak akan pernah menemukannya di panduan itu jika bukan karena Joe Obbish). Berikut adalah prosedur yang saya buat di Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Sederhana, bukan? Jalankan 8 instance SQLQueryStress, dan masukkan batch ini ke masing-masing:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
 Paralelisme orang malang
Paralelisme orang malang
Kecuali itu tidak sesederhana itu, karena tugas scheduler seperti sekotak coklat. Butuh banyak percobaan untuk mendapatkan setiap contoh aplikasi pada penjadwal yang diharapkan; Saya akan memeriksa pengecualian pada setiap contoh aplikasi yang diberikan, dan mengubah PartitionID untuk mencocokkan. Inilah sebabnya saya menggunakan lebih dari satu iterasi (tetapi saya masih hanya menginginkan satu utas per instance). Sebagai contoh, instance aplikasi ini diharapkan berada di scheduler 3, tetapi mendapat scheduler 4:
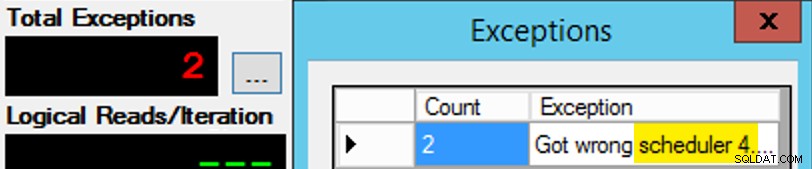 Jika pada awalnya Anda tidak berhasil…
Jika pada awalnya Anda tidak berhasil…
Saya mengubah 3s di jendela kueri menjadi 4s, dan mencoba lagi. Jika saya cepat, tugas penjadwal cukup "lengket" sehingga akan mengambilnya dengan benar dan mulai menenggak. Tapi saya tidak selalu cukup cepat, jadi itu seperti memukul-a-mol untuk pergi. Saya mungkin bisa merancang rutinitas coba ulang/loop yang lebih baik untuk membuat pekerjaan lebih sedikit manual di sini, dan mempersingkat penundaan sehingga saya langsung tahu apakah itu berhasil atau tidak, tetapi ini cukup baik untuk kebutuhan saya. Itu juga membuat waktu mulai yang mengejutkan secara tidak sengaja untuk setiap proses, saran lain dari Mr. Obbish.
Pemantauan
Saat salinan affinitized sedang berjalan, saya bisa mendapatkan petunjuk tentang status saat ini dengan dua pertanyaan berikut:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Jika saya melakukan semuanya dengan benar, kedua kueri akan mengembalikan 8 baris, dan menunjukkan peningkatan pembacaan logis dan durasi. Jenis tunggu akan dibalik antara PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , dan terkadang RESERVED_MEMORY_ALLOCATION_EXT. Ketika batch selesai (saya dapat meninjau ini dengan membatalkan komentar -- AND EndTime IS NULL , saya akan mengonfirmasi bahwa RowsAdded = RowsInRange .
Setelah semua 8 contoh SQLQueryStress selesai, saya bisa melakukan SELECT INTO <newtable> FROM dbo.BatchQueue untuk mencatat hasil akhir untuk analisis nanti.
Pengujian Lainnya
Selain menyalin data ke indeks penyimpanan kolom berkerumun terpartisi yang sudah ada, menggunakan afinitas, saya juga ingin mencoba beberapa hal lain:
- Menyalin data ke tabel baru tanpa mencoba mengontrol afinitas. Saya mengeluarkan logika afinitas dari prosedur dan membiarkan seluruh hal "harap-Anda-mendapatkan-penjadwal-yang-benar" secara kebetulan. Ini membutuhkan waktu lebih lama karena, tentu saja, penumpukan penjadwal melakukannya terjadi. Misalnya, pada titik spesifik ini, penjadwal 3 menjalankan dua proses, sementara penjadwal 0 tidak aktif mengambil istirahat makan siang:
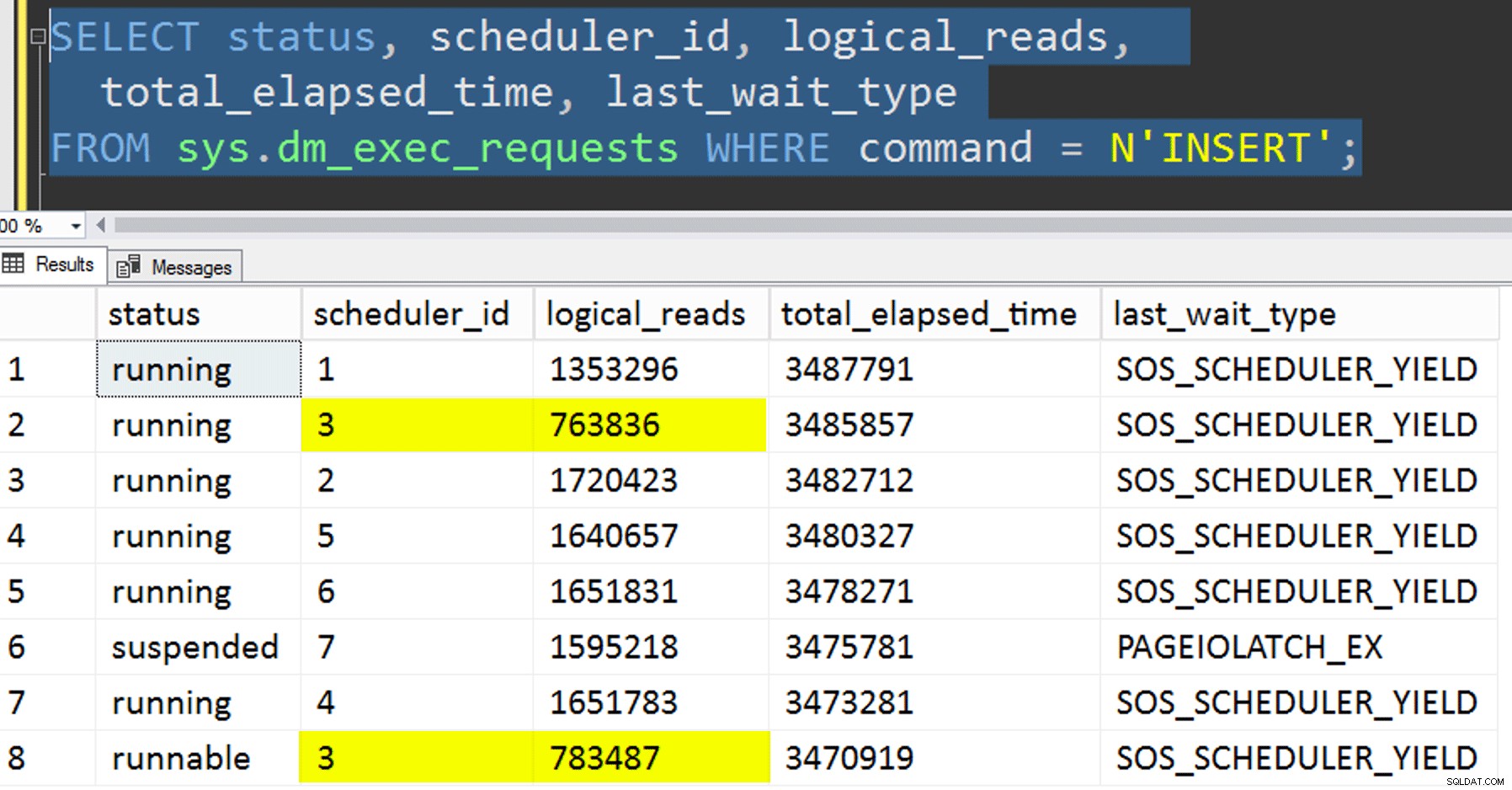 Di mana Anda, penjadwal nomor 0?
Di mana Anda, penjadwal nomor 0? - Menerapkan laman atau baris kompresi (baik online/offline) ke sumber sebelum salinan affinitized (offline), untuk melihat apakah mengompresi data terlebih dahulu dapat mempercepat tujuan. Perhatikan bahwa penyalinan juga dapat dilakukan secara online, tetapi, seperti
intAndy Andy Mallon kebigintkonversi, itu membutuhkan beberapa senam. Perhatikan bahwa dalam kasus ini kami tidak dapat memanfaatkan afinitas CPU (meskipun kami dapat melakukannya jika tabel sumber sudah dipartisi). Saya pintar dan mengambil cadangan dari sumber aslinya, dan membuat prosedur untuk mengembalikan database kembali ke keadaan awal. Jauh lebih cepat dan lebih mudah daripada mencoba kembali ke keadaan tertentu secara manual.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- Dan terakhir, membangun kembali indeks berkerumun ke skema partisi terlebih dahulu, lalu membangun indeks penyimpanan kolom tergugus di atasnya. Kelemahan dari yang terakhir adalah, di SQL Server 2017, Anda tidak dapat menjalankan ini secara online… tetapi Anda akan dapat melakukannya pada tahun 2019.
Di sini kita perlu menghilangkan batasan PK terlebih dahulu; Anda tidak dapat menggunakan
Msg 1907, Level 16, Status 1DROP_EXISTING, karena batasan unik asli tidak dapat diterapkan oleh indeks clustered columnstore, dan Anda tidak dapat mengganti indeks clustered unik dengan indeks clustered non-unik.
Tidak dapat membuat ulang indeks 'pk_tblOriginal'. Definisi indeks baru tidak cocok dengan batasan yang diberlakukan oleh indeks yang ada.Semua detail ini menjadikan ini proses tiga langkah, hanya langkah kedua online. Langkah pertama saya hanya secara eksplisit menguji
OFFLINE; yang berjalan dalam tiga menit, sementaraONLINESaya berhenti setelah 15 menit. Salah satu hal yang mungkin tidak boleh menjadi operasi ukuran data dalam kedua kasus tersebut, tetapi saya akan membiarkannya di lain hari.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Hasil
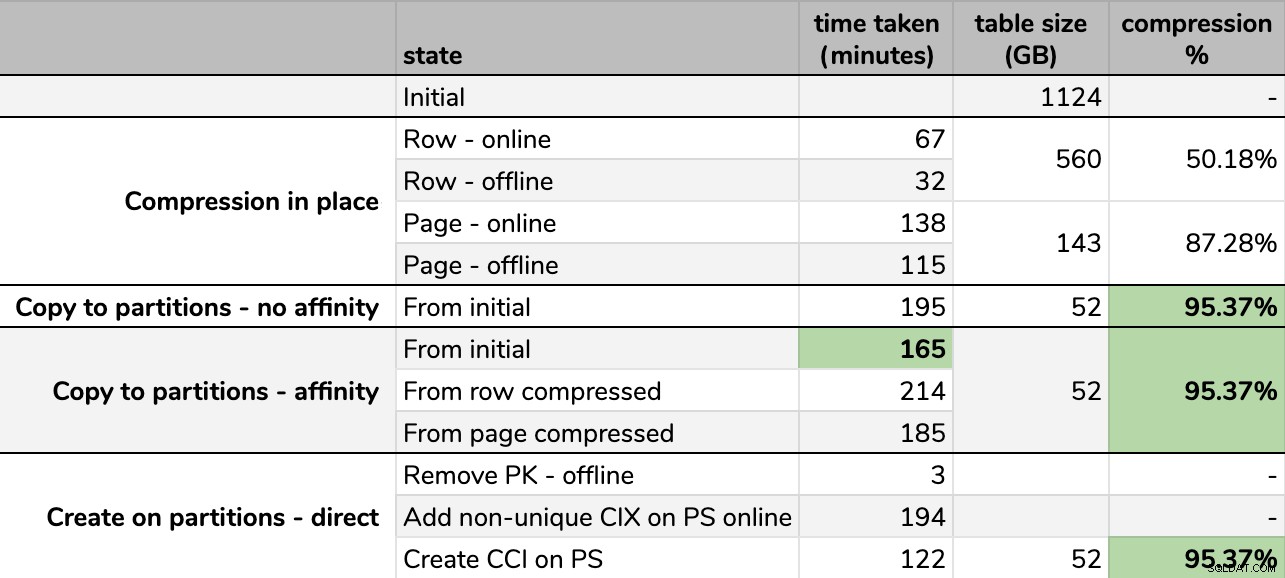
Pengaturan waktu dan tingkat kompresi:
 Beberapa opsi lebih baik daripada yang lain
Beberapa opsi lebih baik daripada yang lain
Perhatikan bahwa saya membulatkan ke GB karena akan ada perbedaan kecil dalam ukuran akhir setiap kali dijalankan, bahkan dengan menggunakan teknik yang sama. Juga, pengaturan waktu untuk metode afinitas didasarkan pada rata-rata runtime penjadwal/batch individual, karena beberapa penjadwal selesai lebih cepat daripada yang lain.
Sulit untuk membayangkan gambaran yang tepat dari spreadsheet seperti yang ditunjukkan, karena beberapa tugas memiliki ketergantungan, jadi saya akan mencoba menampilkan info sebagai garis waktu dan menunjukkan berapa banyak kompresi yang Anda dapatkan dibandingkan dengan waktu yang dihabiskan:
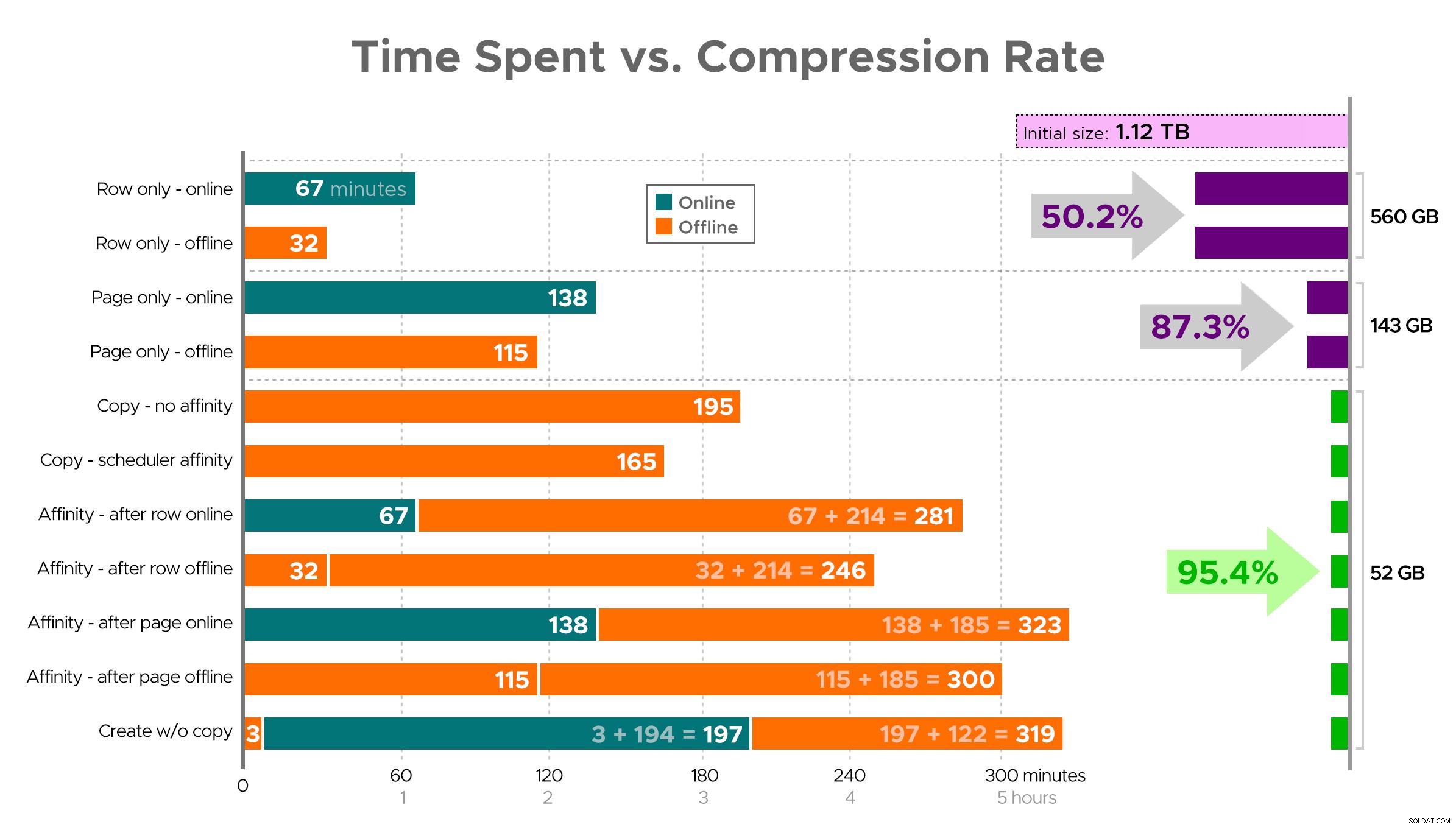 Waktu yang dihabiskan (menit) vs. laju kompresi
Waktu yang dihabiskan (menit) vs. laju kompresi
Beberapa pengamatan dari hasil, dengan peringatan bahwa data Anda mungkin dikompres secara berbeda (dan bahwa operasi online hanya berlaku untuk Anda jika Anda menggunakan Edisi Perusahaan):
- Jika prioritas Anda adalah menghemat ruang secepat mungkin , taruhan terbaik Anda adalah menerapkan kompresi baris di tempatnya. Jika Anda ingin meminimalkan gangguan, gunakan online; jika Anda ingin mengoptimalkan kecepatan, gunakan offline.
- Jika Anda ingin memaksimalkan kompresi tanpa gangguan , Anda dapat mendekati pengurangan penyimpanan 90% tanpa gangguan sama sekali, menggunakan kompresi halaman online.
- Jika ingin memaksimalkan kompresi dan gangguan boleh saja , salin data ke versi tabel baru yang dipartisi, dengan indeks penyimpanan kolom tergugus, dan gunakan proses afinitas yang dijelaskan di atas untuk memigrasikan data. (Dan sekali lagi, Anda dapat menghilangkan gangguan ini jika Anda adalah perencana yang lebih baik dari saya.)
Opsi terakhir bekerja paling baik untuk skenario saya, meskipun kita masih harus mengatasi beban kerja (ya, jamak). Perhatikan juga bahwa di SQL Server 2019 teknik ini mungkin tidak bekerja dengan baik, tetapi Anda dapat membuat indeks toko kolom terklaster secara online di sana, jadi mungkin tidak terlalu penting.
Beberapa dari pendekatan ini mungkin lebih atau kurang dapat diterima oleh Anda, karena Anda mungkin lebih menyukai "tetap tersedia" daripada "menyelesaikan secepat mungkin", atau "meminimalkan penggunaan disk" daripada "tetap tersedia", atau hanya menyeimbangkan kinerja baca dan tulis. .
Jika Anda ingin detail lebih lanjut tentang aspek apa pun dari ini, tanyakan saja. Saya memangkas beberapa lemak untuk menyeimbangkan detail dengan daya cerna, dan saya telah salah tentang keseimbangan itu sebelumnya. Pikiran perpisahan adalah bahwa saya ingin tahu seberapa linier ini – kami memiliki tabel lain dengan struktur serupa yang lebih dari 25 TB, dan saya ingin tahu apakah kami dapat membuat dampak serupa di sana. Sampai saat itu, selamat mengompres!
[ Bagian 1 | Bagian 2 | Bagian 3 ]