Saya menulis posting baru-baru ini tentang DISTINCT dan GROUP BY. Itu adalah perbandingan yang menunjukkan bahwa GROUP BY umumnya merupakan pilihan yang lebih baik daripada DISTINCT. Itu ada di situs yang berbeda, tapi pastikan untuk kembali ke sqlperformance.com setelahnya..
Salah satu perbandingan kueri yang saya tunjukkan di pos itu adalah antara GROUP BY dan DISTINCT untuk sub-kueri, menunjukkan bahwa DISTINCT jauh lebih lambat, karena harus mengambil Nama Produk untuk setiap baris di tabel Penjualan, bukan dari hanya untuk setiap ProductID yang berbeda. Ini cukup jelas dari rencana kueri, di mana Anda dapat melihat bahwa dalam kueri pertama, Agregat beroperasi pada data hanya dari satu tabel, bukan pada hasil gabungan. Oh, dan kedua kueri memberikan 266 baris yang sama.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

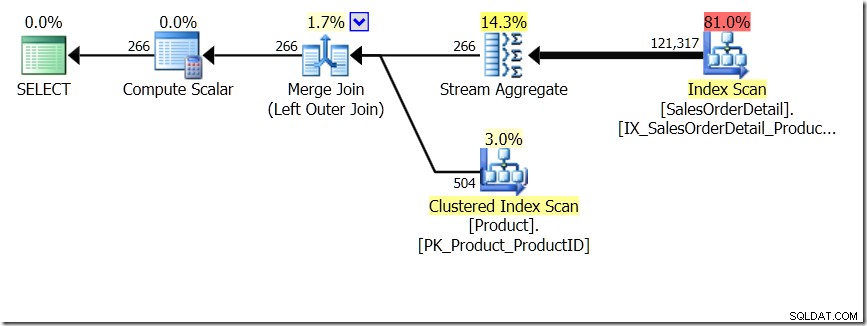
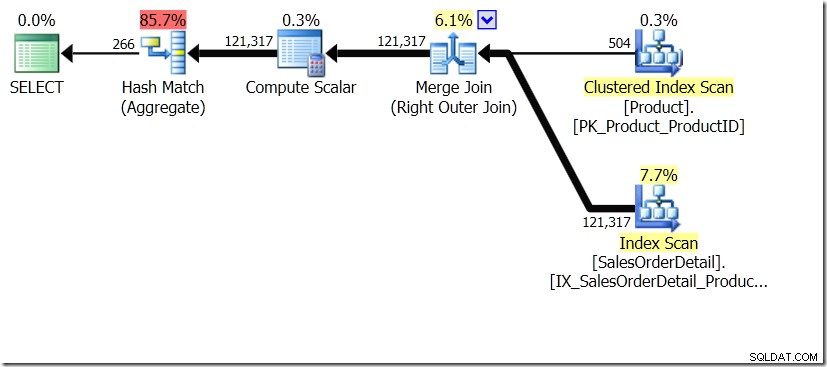
Sekarang, telah ditunjukkan, termasuk oleh Adam Machanic (@adammachanic) dalam tweet yang merujuk pada posting Aaron tentang GROUP BY v DISTINCT bahwa kedua kueri pada dasarnya berbeda, yang sebenarnya meminta set kombinasi yang berbeda pada hasil sub-kueri, daripada menjalankan sub-kueri di seluruh nilai berbeda yang diteruskan. Itulah yang kami lihat dalam rencana, dan merupakan alasan mengapa kinerjanya sangat berbeda.
Masalahnya adalah kita semua akan berasumsi bahwa hasilnya akan sama.
Tapi itu asumsi, dan bukan asumsi yang baik.
Saya akan membayangkan sejenak bahwa Pengoptimal Kueri telah membuat rencana yang berbeda. Saya menggunakan petunjuk untuk ini, tetapi seperti yang Anda ketahui, Pengoptimal Kueri dapat memilih untuk membuat rencana dalam semua jenis bentuk untuk semua jenis alasan.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
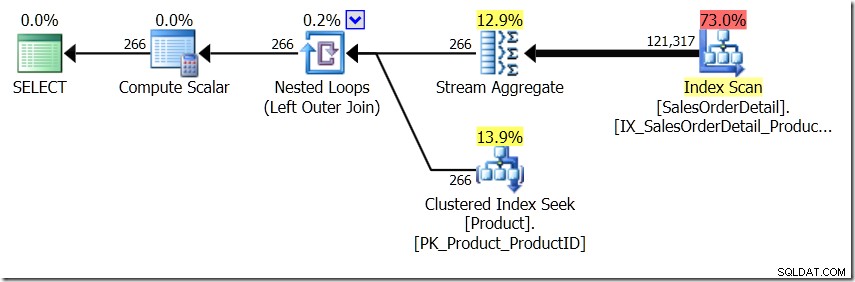
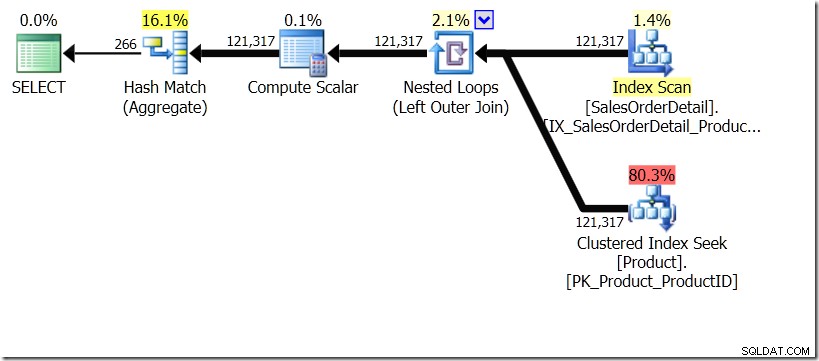
Dalam situasi ini, kami melakukan 266 Pencarian ke dalam tabel Produk, satu untuk setiap ProductID berbeda yang kami minati, atau 121.317 Pencarian. Jadi jika kita berpikir tentang ProductID tertentu, kita tahu bahwa kita akan mendapatkan satu Nama kembali dari yang pertama. Dan kami berasumsi bahwa kami akan mendapatkan satu Nama kembali untuk ProductID itu, bahkan jika kami harus memintanya ratusan kali. Kami hanya berasumsi bahwa kami akan mendapatkan hasil yang sama kembali.
Tapi bagaimana jika kita tidak melakukannya?
Ini terdengar seperti hal tingkat isolasi, jadi mari kita gunakan NOLOCK ketika kita menekan tabel Produk. Dan mari kita jalankan (di jendela yang berbeda) skrip yang mengubah teks di kolom Nama. Saya akan melakukannya berulang kali, untuk mencoba mendapatkan beberapa perubahan di antara kueri saya.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Sekarang, hasil saya berbeda. Rencananya sama (kecuali untuk jumlah baris yang keluar dari Agregat Hash di kueri kedua), tetapi hasil saya berbeda.
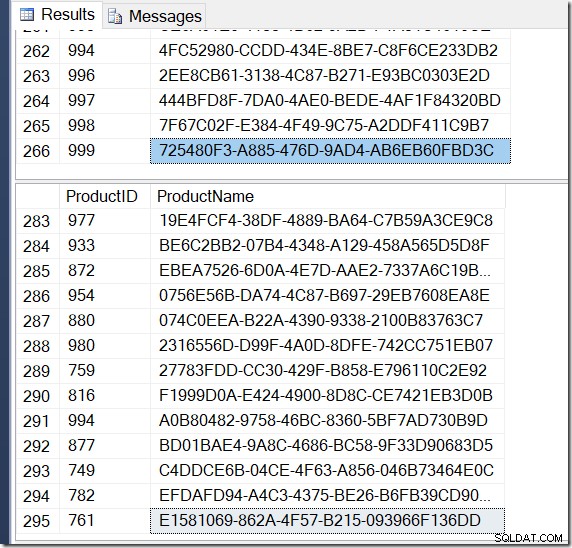
Benar saja, saya memiliki lebih banyak baris dengan DISTINCT, karena ia menemukan nilai Nama yang berbeda untuk ID Produk yang sama. Dan saya tidak harus memiliki 295 baris. Lain saya menjalankannya, saya mungkin mendapatkan 273, atau 300, atau mungkin, 121.317.
Tidak sulit untuk menemukan contoh ProductID yang menunjukkan beberapa nilai Nama, mengonfirmasi apa yang terjadi.

Jelas, untuk memastikan bahwa kita tidak melihat baris ini dalam hasil, kita perlu TIDAK menggunakan DISTINCT, atau menggunakan tingkat isolasi yang lebih ketat.
Masalahnya adalah meskipun saya menyebutkan menggunakan NOLOCK untuk contoh ini, saya tidak perlu melakukannya. Situasi ini terjadi bahkan dengan READ COMMITTED, yang merupakan tingkat isolasi default pada banyak sistem SQL Server.
Anda tahu, kami membutuhkan tingkat isolasi REPEATABLE READ untuk menghindari situasi ini, untuk menahan kunci pada setiap baris setelah dibaca. Jika tidak, utas terpisah dapat mengubah data, seperti yang kita lihat.
Tapi… Saya tidak bisa menunjukkan kepada Anda bahwa hasilnya sudah pasti, karena saya tidak bisa menghindari kebuntuan pada kueri.
Jadi mari kita ubah kondisinya, dengan memastikan bahwa kueri kita yang lain tidak terlalu bermasalah. Alih-alih memperbarui seluruh tabel sekaligus (yang kemungkinannya jauh lebih kecil di dunia nyata), mari kita perbarui satu baris dalam satu waktu.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Sekarang, kami masih dapat mendemonstrasikan masalah di bawah tingkat isolasi yang lebih rendah, seperti READ COMMITTED atau READ UNCOMMITTED (walaupun Anda mungkin perlu menjalankan kueri beberapa kali jika Anda mendapatkan 266 pertama kali, karena kemungkinan memperbarui baris selama kueri lebih sedikit), dan sekarang kami dapat menunjukkan bahwa REPEATABLE READ memperbaikinya (tidak peduli berapa kali kami menjalankan kueri).
REPEATABLE READ melakukan apa yang tertulis di kaleng. Setelah Anda membaca satu baris dalam suatu transaksi, itu terkunci untuk memastikan Anda dapat mengulangi membaca dan mendapatkan hasil yang sama. Tingkat isolasi yang lebih rendah tidak menghilangkan kunci itu sampai Anda mencoba mengubah data. Jika paket kueri Anda tidak perlu mengulang pembacaan (seperti halnya dengan bentuk paket GROUP BY kami), maka Anda tidak perlu REPEATABLE READ.
Boleh dibilang, kita harus selalu menggunakan tingkat isolasi yang lebih tinggi, seperti REPEATABLE READ atau SERIALIZABLE, tetapi semuanya bermuara pada mencari tahu apa yang dibutuhkan sistem kita. Level ini dapat menyebabkan penguncian yang tidak diinginkan, dan level isolasi SNAPSHOT memerlukan versi yang disertakan dengan harga juga. Bagi saya, saya pikir ini adalah trade-off. Jika saya meminta kueri yang dapat dipengaruhi oleh perubahan data, saya mungkin perlu menaikkan level isolasi untuk sementara waktu.
Idealnya, Anda tidak perlu memperbarui data yang baru saja dibaca dan mungkin perlu dibaca lagi selama kueri, sehingga Anda tidak perlu BACA BERULANG. Namun, sangat penting untuk memahami apa yang bisa terjadi, dan menyadari bahwa ini adalah jenis skenario ketika DISTINCT dan GROUP BY mungkin tidak sama.
@rob_farley