Ada dua keterampilan pelengkap yang sangat berguna dalam penyetelan kueri. Salah satunya adalah kemampuan untuk membaca dan menginterpretasikan rencana eksekusi. Yang kedua adalah mengetahui sedikit tentang cara kerja pengoptimal kueri untuk menerjemahkan teks SQL ke dalam rencana eksekusi. Menggabungkan kedua hal tersebut dapat membantu kami menemukan waktu ketika pengoptimalan yang diharapkan tidak diterapkan, sehingga menghasilkan rencana eksekusi yang tidak seefisien mungkin. Kurangnya dokumentasi seputar pengoptimalan yang tepat yang dapat diterapkan SQL Server (dan dalam situasi apa) berarti bahwa banyak dari hal ini bergantung pada pengalaman.
Contoh
Permintaan sampel untuk artikel ini didasarkan pada pertanyaan yang diajukan oleh SQL Server MVP Fabiano Amorim beberapa bulan yang lalu, berdasarkan masalah dunia nyata yang dia temui. Skema dan kueri pengujian di bawah ini adalah penyederhanaan dari situasi sebenarnya, tetapi tetap mempertahankan semua fitur penting.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Uji 1 – 10.000 baris, SQL Server 2005+
Data tabel spesifik tidak terlalu penting untuk pengujian ini. Kueri berikut cukup memuat 10.000 baris dari tabel angka ke masing-masing dari tiga tabel pengujian:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Dengan data yang dimuat, rencana eksekusi yang dihasilkan untuk kueri pengujian adalah:
SELECT MAX(c1) FROM dbo.V1;
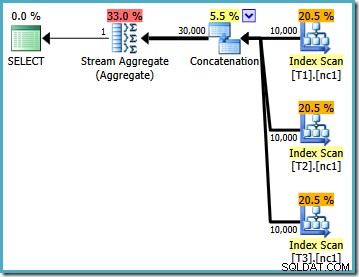
Rencana eksekusi ini adalah implementasi yang cukup langsung dari kueri SQL logis (setelah referensi tampilan V1 diperluas). Pengoptimal melihat kueri setelah perluasan tampilan, hampir seolah-olah kueri telah ditulis secara lengkap:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Membandingkan teks yang diperluas dengan rencana eksekusi, keterusterangan implementasi pengoptimal kueri jelas. Ada Pemindaian Indeks untuk setiap pembacaan tabel dasar, operator Penggabungan untuk mengimplementasikan UNION ALL , dan Agregat Aliran untuk MAX final terakhir agregat.
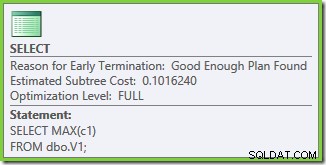
Properti rencana eksekusi menunjukkan bahwa pengoptimalan berbasis biaya telah dimulai (tingkat pengoptimalan adalah FULL ), tetapi itu dihentikan lebih awal karena rencana 'cukup baik' ditemukan. Perkiraan biaya paket yang dipilih adalah 0,1016240 unit pengoptimal ajaib.
Uji 2 – 50.000 baris, SQL Server 2008 dan 2008 R2
Jalankan skrip berikut untuk mengatur ulang lingkungan pengujian agar berjalan dengan 50.000 baris:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
Rencana eksekusi untuk pengujian ini bergantung pada versi SQL Server yang Anda jalankan. Di SQL Server 2008 dan 2008 R2, kami mendapatkan paket berikut:
Properti paket menunjukkan bahwa pengoptimalan berbasis biaya masih berakhir lebih awal karena alasan yang sama seperti sebelumnya. Perkiraan biaya lebih tinggi dari sebelumnya di 0,41375 unit tetapi itu diharapkan karena kardinalitas yang lebih tinggi dari tabel dasar.
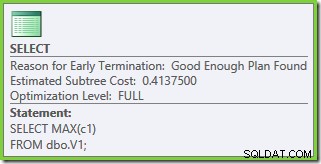
Uji 3 – 50.000 baris, SQL Server 2005 dan 2012
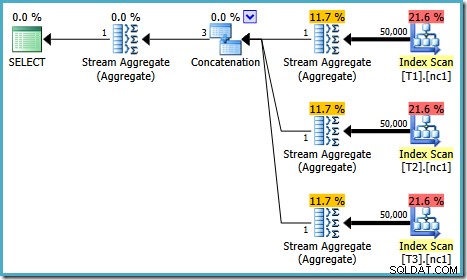
Kueri yang sama yang dijalankan pada tahun 2005 atau 2012 menghasilkan rencana eksekusi yang berbeda:
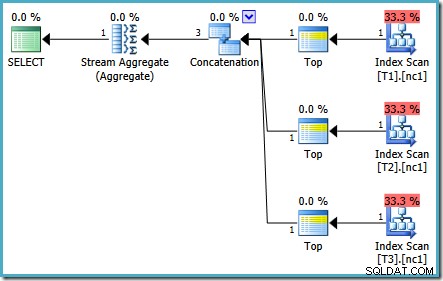
Pengoptimalan berakhir lebih awal lagi, tetapi perkiraan biaya paket untuk 50.000 baris per tabel dasar turun menjadi 0,0098585 (dari 0,41375 pada SQL Server 2008 dan 2008 R2).
Penjelasan
Seperti yang Anda ketahui, pengoptimal kueri SQL Server memisahkan upaya pengoptimalan menjadi beberapa tahap, dengan tahap selanjutnya menambahkan lebih banyak teknik pengoptimalan dan memungkinkan lebih banyak waktu. Tahapan optimasinya adalah:
- Rencana sepele
- Pengoptimalan berbasis biaya
- Pemrosesan Transaksi (pencarian 0)
- Rencana Cepat (pencarian 1)
- Rencana Cepat dengan paralelisme diaktifkan
- Optimasi Penuh (pencarian 2)
Tak satu pun dari pengujian yang dilakukan di sini memenuhi syarat untuk rencana sepele karena agregat dan serikat pekerja memiliki beberapa kemungkinan implementasi, yang memerlukan keputusan berbasis biaya.
Pemrosesan Transaksi
Tahap Pemrosesan Transaksi (TP) mengharuskan kueri berisi setidaknya tiga referensi tabel, jika tidak, pengoptimalan berbasis biaya akan melewati tahap ini dan langsung beralih ke Rencana Cepat. Tahap TP ditujukan untuk kueri navigasi berbiaya rendah yang khas dari beban kerja OLTP. Ini mencoba sejumlah teknik pengoptimalan yang terbatas, dan terbatas untuk menemukan rencana dengan Nested Loop Joins (kecuali Hash Join diperlukan untuk menghasilkan rencana yang valid).
Dalam beberapa hal, mengejutkan bahwa kueri pengujian memenuhi syarat untuk tahap yang bertujuan menemukan rencana OLTP. Meskipun kueri berisi tiga referensi tabel yang diperlukan, kueri tersebut tidak berisi gabungan apa pun. Persyaratan tiga tabel hanyalah heuristik, jadi saya tidak akan membahasnya.
Tahap Pengoptimal Manakah yang Dijalankan?
Ada beberapa metode, yang didokumentasikan adalah untuk membandingkan isi sys.dm_exec_query_optimizer_info sebelum dan sesudah kompilasi. Ini bagus, tetapi ini merekam informasi di seluruh instance sehingga Anda harus berhati-hati bahwa Anda adalah satu-satunya kompilasi kueri yang terjadi di antara snapshot.
Alternatif tidak berdokumen (tetapi cukup terkenal) yang berfungsi pada semua versi SQL Server yang saat ini didukung adalah dengan mengaktifkan tanda pelacakan 8675 dan 3604 saat mengompilasi kueri.
Uji 1
Pengujian ini menghasilkan keluaran trace flag 8675 yang mirip dengan berikut ini:

Perkiraan biaya 0,101624 setelah tahap TP cukup rendah sehingga pengoptimal tidak terus mencari paket yang lebih murah. Rencana sederhana yang kami dapatkan cukup masuk akal mengingat kardinalitas tabel dasar yang relatif rendah, bahkan jika itu tidak benar-benar optimal.
Uji 2
Dengan 50.000 baris di setiap tabel dasar, bendera jejak mengungkapkan informasi yang berbeda:

Kali ini, perkiraan biaya setelah tahap TP adalah 0.428735 (lebih banyak baris =biaya lebih tinggi). Ini cukup untuk mendorong pengoptimal ke tahap Rencana Cepat. Dengan lebih banyak teknik pengoptimalan yang tersedia, tahap ini menemukan rencana dengan biaya 0,41375 . Ini tidak menunjukkan peningkatan besar dibandingkan rencana pengujian 1, tetapi lebih rendah dari ambang biaya default untuk paralelisme, dan tidak cukup untuk memasuki Pengoptimalan Penuh, jadi sekali lagi pengoptimalan berakhir lebih awal.
Uji 3
Untuk menjalankan SQL Server 2005 dan 2012, keluaran bendera pelacakan adalah:

Ada sedikit perbedaan dalam jumlah tugas yang dijalankan antar versi, tetapi perbedaan penting adalah bahwa pada SQL Server 2005 dan 2012, tahap Rencana Cepat menemukan paket yang hanya seharga 0,0098543 unit. Ini adalah paket yang berisi operator Top alih-alih tiga Agregat Aliran di bawah operator Penggabungan yang terlihat di paket SQL Server 2008 dan 2008 R2.
Perbaikan Bug dan Tidak Terdokumentasi
SQL Server 2008 dan 2008 R2 berisi bug regresi (dibandingkan dengan 2005) yang diperbaiki di bawah bendera jejak 4199, tetapi tidak didokumentasikan sejauh yang saya tahu. Ada dokumentasi untuk TF 4199 yang mencantumkan perbaikan yang tersedia di bawah tanda pelacakan terpisah sebelum dicakup oleh 4199, tetapi seperti yang dikatakan artikel Basis Pengetahuan itu:
Bendera satu jejak ini dapat digunakan untuk mengaktifkan semua perbaikan yang sebelumnya dibuat untuk prosesor kueri di bawah banyak bendera jejak. Selain itu, semua perbaikan prosesor kueri di masa mendatang akan dikontrol dengan menggunakan tanda pelacakan ini.
Bug dalam kasus ini adalah salah satu dari 'perbaikan prosesor kueri di masa mendatang'. Aturan pengoptimalan tertentu, ScalarGbAggToTop , tidak diterapkan pada agregat baru yang terlihat pada rencana uji 2. Dengan flag trace 4199 diaktifkan pada build SQL Server 2008 dan 2008 R2 yang sesuai, bug telah diperbaiki dan rencana optimal dari pengujian 3 diperoleh:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Kesimpulan
Setelah Anda mengetahui bahwa pengoptimal dapat mengubah skalar MIN atau MAX agregat ke TOP (1) pada aliran yang dipesan, rencana yang ditunjukkan pada pengujian 2 tampak aneh. Agregat skalar di atas pemindaian indeks (yang dapat memberikan urutan jika diminta untuk melakukannya) menonjol sebagai pengoptimalan yang terlewatkan yang biasanya diterapkan.
Inilah poin yang saya sampaikan dalam pendahuluan:setelah Anda merasakan hal-hal yang dapat dilakukan pengoptimal, ini dapat membantu Anda mengenali kasus di mana ada yang tidak beres.
Jawabannya tidak selalu untuk mengaktifkan bendera pelacakan 4199, karena Anda mungkin menemukan masalah yang belum diperbaiki. Anda juga mungkin tidak ingin perbaikan QP lainnya yang dicakup oleh tanda pelacakan untuk diterapkan dalam kasus tertentu – perbaikan pengoptimal tidak selalu membuat segalanya lebih baik. Jika ya, tidak perlu melindungi dari regresi rencana yang tidak menguntungkan menggunakan tanda ini.
Solusi dalam kasus lain mungkin untuk merumuskan kueri SQL menggunakan sintaks yang berbeda, untuk memecah kueri menjadi potongan yang lebih ramah pengoptimal, atau sesuatu yang lain sama sekali. Apa pun jawabannya, tetap ada baiknya mengetahui sedikit tentang pengoptimal internal sehingga Anda dapat mengenali bahwa ada masalah sejak awal :)