Perubahan dalam representasi internal tabel yang dipartisi antara SQL Server 2005 dan SQL Server 2008 menghasilkan peningkatan rencana kueri dan kinerja di sebagian besar kasus (terutama ketika eksekusi paralel terlibat). Sayangnya, perubahan yang sama menyebabkan beberapa hal yang bekerja dengan baik di SQL Server 2005 tiba-tiba tidak berfungsi dengan baik di SQL Server 2008 dan yang lebih baru. Posting ini melihat satu contoh di mana pengoptimal kueri SQL Server 2005 menghasilkan rencana eksekusi yang unggul dibandingkan dengan versi yang lebih baru.
Contoh Tabel dan Data
Contoh dalam posting ini menggunakan tabel dan data yang dipartisi berikut:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Tata Letak Data Terpartisi
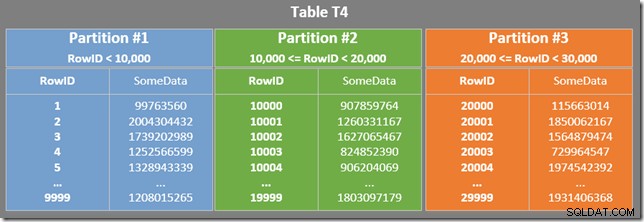
Tabel kami memiliki indeks berkerumun yang dipartisi. Dalam hal ini, kunci pengelompokan juga berfungsi sebagai kunci partisi (meskipun ini bukan persyaratan, secara umum). Partisi menghasilkan unit penyimpanan fisik terpisah (rowset) yang disajikan oleh prosesor kueri kepada pengguna sebagai satu kesatuan.
Diagram di bawah menunjukkan tiga partisi pertama dari tabel kita (klik untuk memperbesar):
Indeks nonclustered dipartisi dengan cara yang sama (ini "disejajarkan"):

Setiap partisi indeks nonclustered mencakup rentang nilai RowID. Dalam setiap partisi, data diurutkan oleh SomeData (tetapi nilai RowID tidak akan diurutkan secara umum).
Masalah MIN/MAX
Cukup diketahui bahwa MIN dan MAX agregat tidak dioptimalkan dengan baik pada tabel yang dipartisi (kecuali kolom yang diagregasikan juga merupakan kolom partisi). Batasan ini (yang masih ada di SQL Server 2014 CTP 1) telah ditulis berkali-kali selama bertahun-tahun; liputan favorit saya ada di artikel ini oleh Itzik Ben-Gan. Untuk mengilustrasikan masalah ini secara singkat, pertimbangkan kueri berikut:
SELECT MIN(SomeData) FROM dbo.T4;
Rencana eksekusi pada SQL Server 2008 atau yang lebih baru adalah sebagai berikut:

Paket ini membaca semua 150.000 baris dari indeks dan Stream Aggregate menghitung nilai minimum (rencana eksekusi pada dasarnya sama jika kami meminta nilai maksimum sebagai gantinya). Rencana eksekusi SQL Server 2005 sedikit berbeda (meskipun tidak lebih baik):
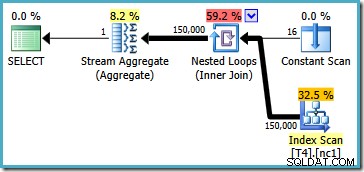
Paket ini mengulangi nomor partisi (tercantum dalam Pemindaian Konstan) memindai partisi secara penuh pada satu waktu. Semua 150.000 baris pada akhirnya masih dibaca dan diproses oleh Stream Aggregate.
Lihat kembali tabel yang dipartisi dan diagram indeks dan pikirkan tentang bagaimana kueri dapat diproses lebih efisien pada kumpulan data kita. Indeks nonclustered tampaknya merupakan pilihan yang baik untuk menyelesaikan kueri karena berisi nilai SomeData dalam urutan yang dapat dieksploitasi saat menghitung agregat.
Sekarang, fakta bahwa indeks dipartisi memang sedikit memperumit masalah:setiap partisi indeks diurutkan oleh kolom SomeData, tetapi kita tidak bisa begitu saja membaca nilai terendah dari tertentu mana pun. partisi untuk mendapatkan jawaban yang tepat untuk seluruh kueri.
Setelah sifat dasar masalah dipahami, manusia dapat melihat bahwa strategi yang efisien adalah menemukan nilai SomeData terendah di setiap partisi indeks, lalu ambil nilai terendah dari hasil per-partisi.
Ini pada dasarnya adalah solusi yang disajikan Itzik dalam artikelnya; tulis ulang kueri untuk menghitung agregat per partisi (menggunakan APPLY sintaks) dan kemudian agregat lagi atas hasil per-partisi tersebut. Dengan menggunakan pendekatan itu, MIN . yang ditulis ulang query menghasilkan rencana eksekusi ini (lihat artikel Itzik untuk sintaks yang tepat):
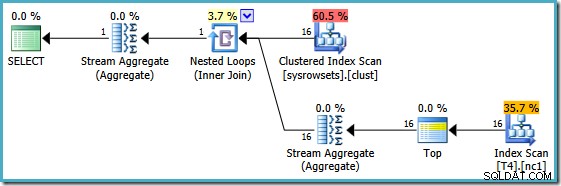
Paket ini membaca nomor partisi dari tabel sistem, dan mengambil nilai SomeData terendah di setiap partisi. Stream Aggregate akhir hanya menghitung minimum atas hasil per-partisi.
Fitur penting dalam rencana ini adalah bahwa ia membaca satu baris dari setiap partisi (mengeksploitasi urutan indeks dalam setiap partisi). Ini jauh lebih efisien daripada rencana pengoptimal yang memproses 150.000 baris dalam tabel.
MIN dan MAX dalam satu partisi
Sekarang perhatikan kueri berikut untuk menemukan nilai minimum di kolom SomeData, untuk rentang nilai RowID yang terdapat dalam satu partisi :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Kami telah melihat bahwa pengoptimal bermasalah dengan MIN dan MAX lebih dari beberapa partisi, tetapi kami berharap batasan tersebut tidak berlaku untuk kueri partisi tunggal.
Partisi tunggal adalah partisi yang dibatasi oleh nilai RowID 10.000 dan 20.000 (lihat kembali definisi fungsi partisi). Fungsi partisi didefinisikan sebagai RANGE RIGHT , jadi nilai batas 10.000 milik partisi #2 dan batas 20.000 milik partisi #3. Rentang nilai RowID yang ditentukan oleh kueri baru kami hanya ada di dalam partisi 2.
Rencana eksekusi grafis untuk kueri ini terlihat sama di semua versi SQL Server mulai tahun 2005 dan seterusnya:
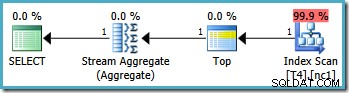
Analisis Rencana
Pengoptimal mengambil rentang RowID yang ditentukan dalam WHERE klausa dan membandingkannya dengan definisi fungsi partisi untuk menentukan bahwa hanya partisi 2 dari indeks nonclustered yang perlu diakses. Properti paket SQL Server 2005 untuk Pemindaian Indeks menunjukkan akses partisi tunggal dengan jelas:
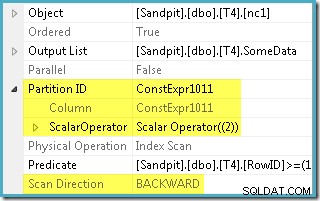
Properti lain yang disorot adalah Arah Pemindaian. Urutan pemindaian berbeda tergantung pada apakah kueri mencari nilai SomeData minimum atau maksimum. Indeks nonclustered diurutkan (per partisi, ingat) pada nilai SomeData menaik, jadi arah Pemindaian Indeks adalah FORWARD jika kueri meminta nilai minimum, dan BACKWARD jika diperlukan nilai maksimal (screen shot di atas diambil dari MAX rencana kueri).
Ada juga Predikat sisa pada Pemindaian Indeks untuk memeriksa apakah nilai RowID yang dipindai dari partisi 2 cocok dengan WHERE predikat klausa. Pengoptimal mengasumsikan bahwa nilai RowID didistribusikan cukup acak melalui indeks nonclustered, sehingga mengharapkan untuk menemukan baris pertama yang cocok dengan WHERE predikat klausa cukup cepat. Diagram tata letak data yang dipartisi menunjukkan bahwa nilai-nilai RowID memang cukup terdistribusi secara acak dalam indeks (yang diurutkan oleh kolom SomeData ingat):
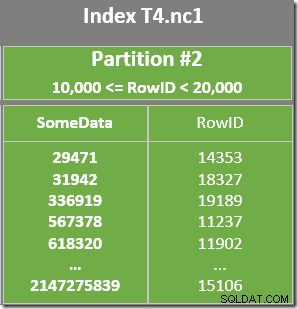
Operator Top dalam rencana kueri membatasi Pemindaian Indeks ke satu baris (baik dari ujung bawah atau atas indeks tergantung pada Arah Pemindaian). Pemindaian Indeks dapat menjadi masalah dalam rencana kueri, tetapi operator Top menjadikannya opsi yang efisien di sini:pemindaian hanya dapat menghasilkan satu baris, lalu berhenti. Kombinasi Pemindaian Indeks Atas dan Terurut secara efektif melakukan pencarian ke nilai tertinggi atau terendah dalam indeks yang juga cocok dengan WHERE predikat klausa. Agregat Aliran juga muncul dalam rencana untuk memastikan bahwa NULL dihasilkan jika tidak ada baris yang dikembalikan oleh Pemindaian Indeks. Skalar MIN dan MAX agregat didefinisikan untuk mengembalikan NULL ketika inputnya adalah himpunan kosong.
Secara keseluruhan, ini adalah strategi yang sangat efisien, dan rencana tersebut memiliki perkiraan biaya hanya 0,0032921 unit sebagai hasilnya. Sejauh ini bagus.
Masalah Nilai Batas
Contoh berikut ini memodifikasi ujung atas rentang RowID:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
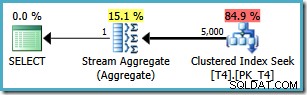
Perhatikan bahwa kueri mengecualikan nilai 20.000 dengan menggunakan operator “kurang dari”. Ingat bahwa nilai 20.000 milik partisi 3 (bukan partisi 2) karena fungsi partisi didefinisikan sebagai RANGE RIGHT . SQL Server 2005 pengoptimal menangani situasi ini dengan benar, menghasilkan rencana kueri partisi tunggal yang optimal, dengan perkiraan biaya 0,0032878 :
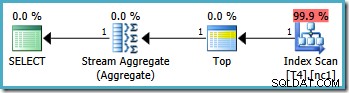
Namun, kueri yang sama menghasilkan paket yang berbeda pada SQL Server 2008 dan yang lebih baru (termasuk SQL Server 2014 CTP 1):
Sekarang kita memiliki Pencarian Indeks Cluster (bukan kombinasi Pemindaian Indeks dan operator Top yang diinginkan). Semua 5.000 baris yang cocok dengan WHERE klausa diproses melalui Stream Aggregate dalam rencana eksekusi baru ini. Perkiraan biaya paket ini adalah 0,0199319 unit – lebih dari enam kali biaya paket SQL Server 2005.
Penyebab
Pengoptimal SQL Server 2008 (dan yang lebih baru) tidak cukup mendapatkan logika internal yang benar saat referensi interval, tetapi mengecualikan , nilai batas milik partisi yang berbeda. Pengoptimal salah mengira bahwa beberapa partisi akan diakses, dan menyimpulkan bahwa ia tidak dapat menggunakan pengoptimalan satu partisi untuk MIN dan MAX agregat.
Solusi
Salah satu opsi adalah menulis ulang kueri menggunakan operator>=dan <=sehingga kami tidak mereferensikan nilai batas dari partisi lain (bahkan untuk mengecualikannya!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Ini menghasilkan rencana yang optimal, menyentuh satu partisi:
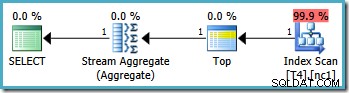
Sayangnya, tidak selalu mungkin untuk menentukan nilai batas yang benar dengan cara ini (tergantung pada jenis kolom partisi). Contohnya adalah dengan tipe tanggal &waktu di mana yang terbaik adalah menggunakan interval setengah terbuka. Keberatan lain untuk solusi ini lebih subjektif:fungsi partisi mengecualikan satu batas dari rentang, jadi tampaknya paling wajar untuk menulis kueri juga menggunakan sintaks interval setengah terbuka.
Solusi kedua adalah menentukan nomor partisi secara eksplisit (dan mempertahankan interval setengah terbuka):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Ini menghasilkan rencana yang optimal, dengan biaya yang membutuhkan predikat ekstra dan mengandalkan pengguna untuk menentukan nomor partisi yang seharusnya.
Tentu saja akan lebih baik jika pengoptimal 2008 dan yang lebih baru menghasilkan rencana optimal yang sama seperti yang dilakukan SQL Server 2005. Di dunia yang sempurna, solusi yang lebih komprehensif juga akan mengatasi kasus multi-partisi, membuat solusi yang dijelaskan Itzik juga tidak perlu.