Posting ini adalah bagian dari seri tentang tujuan baris. Anda dapat menemukan bagian lain di sini:
- Bagian 1:Menetapkan dan Mengidentifikasi Sasaran Baris
- Bagian 2:Semi Bergabung
- Bagian 3:Anti Bergabung
Terapkan Anti Gabung dengan operator Top
Anda akan sering melihat operator Top (1) sisi dalam di menerapkan anti gabung rencana eksekusi. Misalnya, menggunakan database AdventureWorks:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Rencana menunjukkan operator Top (1) di sisi dalam aplikasi (referensi luar) anti gabung:
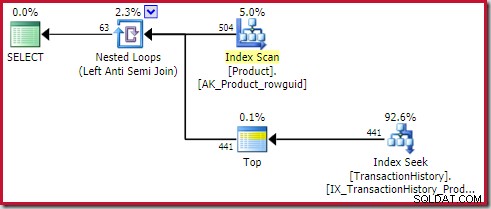
Operator Top ini benar-benar berlebihan . Itu tidak diperlukan untuk kebenaran, efisiensi, atau untuk memastikan tujuan baris telah ditetapkan.
Operator apply anti join akan berhenti memeriksa baris di sisi dalam (untuk iterasi saat ini) segera setelah satu baris terlihat di join. Sangat mungkin untuk membuat rencana anti gabung yang berlaku tanpa Top. Jadi mengapa ada operator Top dalam paket ini?
Sumber operator Top
Untuk memahami dari mana asal operator Top yang tidak berguna ini, kita perlu mengikuti langkah-langkah utama yang diambil selama kompilasi dan pengoptimalan kueri contoh kita.
Seperti biasa, kueri pertama-tama diurai menjadi pohon. Ini menampilkan operator logis 'tidak ada' dengan subkueri, yang sangat cocok dengan bentuk kueri tertulis dalam kasus ini:

Subkueri yang tidak ada dibuka ke dalam penerapan anti gabung:

Ini kemudian ditransformasikan lebih jauh ke dalam logika kiri anti semi join. Pohon hasil yang diteruskan ke pengoptimalan berbasis biaya terlihat seperti ini:

Eksplorasi pertama yang dilakukan oleh pengoptimal berbasis biaya adalah untuk memperkenalkan pembedaan logis operasi pada input anti join yang lebih rendah, untuk menghasilkan nilai unik untuk kunci anti join. Ide umumnya adalah bahwa alih-alih menguji nilai duplikat saat bergabung, rencana mungkin mendapat manfaat dari pengelompokan nilai-nilai tersebut di awal.
Aturan eksplorasi yang bertanggung jawab disebut LASJNtoLASJNonDist (anti semi join kiri ke kiri anti semi join pada perbedaan). Implementasi fisik atau penetapan biaya belum dilakukan, jadi ini hanya pengoptimal yang mengeksplorasi kesetaraan logis, berdasarkan keberadaan ProductID duplikat nilai-nilai. Pohon baru dengan operasi pengelompokan yang ditambahkan ditunjukkan di bawah ini:

Transformasi logis berikutnya yang dipertimbangkan adalah menulis ulang gabungan sebagai berlaku . Ini dieksplorasi menggunakan aturan LASJNtoApply (kiri anti semi join untuk diterapkan dengan seleksi relasional). Seperti disebutkan sebelumnya dalam seri, transformasi sebelumnya dari apply ke join adalah untuk mengaktifkan transformasi yang bekerja secara khusus pada join. Penggabungan selalu dapat ditulis ulang sebagai permohonan, jadi ini memperluas jangkauan pengoptimalan yang tersedia.
Sekarang, pengoptimal tidak selalu pertimbangkan penerapan penulisan ulang sebagai bagian dari pengoptimalan berbasis biaya. Harus ada sesuatu di pohon logis untuk membuatnya berharga dengan mendorong predikat join ke sisi dalam. Biasanya, ini akan menjadi indeks yang cocok, tetapi ada target lain yang menjanjikan. Dalam hal ini, ini adalah kunci logis pada ProductID dibuat oleh operasi agregat.
Hasil dari aturan ini adalah anti join yang berkorelasi dengan seleksi di sisi dalam:

Selanjutnya, pengoptimal mempertimbangkan untuk memindahkan pilihan relasional (predikat gabungan yang berkorelasi) lebih jauh ke sisi dalam, melewati perbedaan (kelompok demi agregat) yang diperkenalkan oleh pengoptimal sebelumnya. Ini dilakukan dengan aturan SelOnGbAgg , yang memindahkan sebanyak mungkin pilihan (predikat) melewati grup yang sesuai secara agregat (sebagian dari pilihan mungkin tertinggal). Aktivitas ini membantu mendorong pilihan sedekat mungkin dengan operator akses data tingkat daun, untuk menghilangkan baris sebelumnya dan membuat pencocokan indeks nanti lebih mudah.
Dalam hal ini, filter berada pada kolom yang sama dengan operasi pengelompokan, sehingga transformasinya valid. Ini menghasilkan seluruh seleksi didorong di bawah agregat:

Operasi terakhir yang diinginkan dilakukan oleh aturan GbAggToConstScanOrTop . Transformasi ini terlihat untuk mengganti grup berdasarkan agregat dengan Pemindaian Konstan atau Atas operasi logis. Aturan ini cocok dengan pohon kita karena kolom pengelompokan adalah konstan untuk setiap baris yang melewati seleksi yang didorong ke bawah. Semua baris dijamin memiliki ProductID yang sama . Pengelompokan pada nilai tunggal itu akan selalu menghasilkan satu baris. Oleh karena itu, adalah valid untuk mengubah agregat menjadi Top (1). Jadi dari sinilah puncak berasal.
Implementasi dan Penetapan Biaya
Pengoptimal sekarang menjalankan serangkaian aturan implementasi untuk menemukan operator fisik untuk setiap alternatif logis yang menjanjikan yang telah dipertimbangkan sejauh ini (disimpan secara efisien dalam struktur memo). Opsi fisik hash dan gabung anti bergabung berasal dari pohon awal dengan agregat yang diperkenalkan (milik aturan LASJNtoLASJNonDist ingat). Aplikasi membutuhkan sedikit lebih banyak pekerjaan untuk membuat atasan fisik dan mencocokkan pilihan dengan pencarian indeks.
hash anti join terbaik solusi yang ditemukan dihitung biayanya 0,362143 satuan:
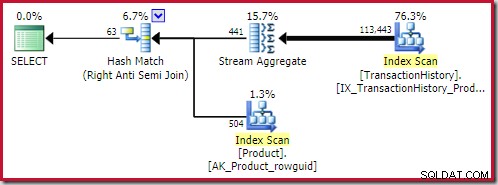
gabungan anti gabung terbaik solusi masuk pada 0,353479 unit (sedikit lebih murah):
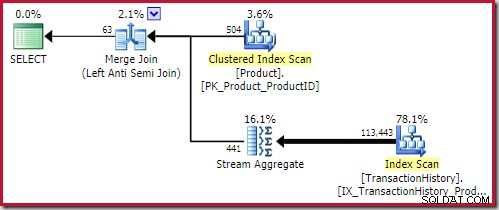
terapkan anti gabung biaya 0,091823 unit (termurah dengan margin lebar):
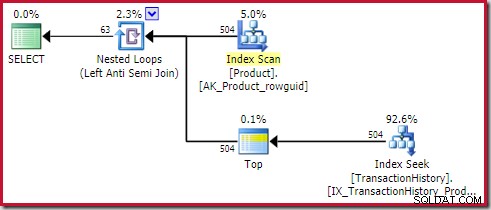
Pembaca yang cerdik mungkin memperhatikan jumlah baris di sisi dalam aplikasi anti join (504) berbeda dari tangkapan layar sebelumnya dari paket yang sama. Sebab, ini merupakan rencana perkiraan, sedangkan rencana sebelumnya adalah pasca pelaksanaan. Ketika rencana ini dijalankan, hanya total 441 baris yang ditemukan di sisi dalam pada semua iterasi. Ini menyoroti salah satu kesulitan tampilan dengan menerapkan rencana semi/anti join:Perkiraan pengoptimal minimum adalah satu baris, tetapi semi atau anti join akan selalu menemukan satu baris atau tidak ada baris pada setiap iterasi. 504 baris yang ditunjukkan di atas mewakili 1 baris pada setiap 504 iterasi. Agar angkanya cocok, perkiraannya harus 441/504 =0,875 baris setiap kali, yang mungkin akan membingungkan orang.
Bagaimanapun, rencana di atas cukup 'beruntung' untuk lolos ke gawang baris di sisi dalam penerapan anti gabung karena dua alasan:
- Anti join diubah dari join menjadi apply di pengoptimal berbasis biaya. Ini menetapkan tujuan baris (sebagaimana ditetapkan di bagian tiga).
- Operator Top(1) juga menetapkan tujuan baris pada subpohonnya.
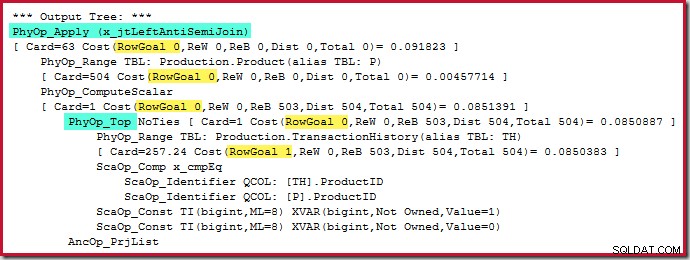
Operator Top itu sendiri tidak memiliki sasaran baris (dari penerapan) karena sasaran baris 1 tidak akan kurang dari perkiraan biasa, yang juga 1 baris (Kartu=1 untuk PhyOp_Top di bawah):
Pola Anti-Gabungan
Bentuk denah umum berikut adalah salah satu yang saya anggap sebagai pola anti:
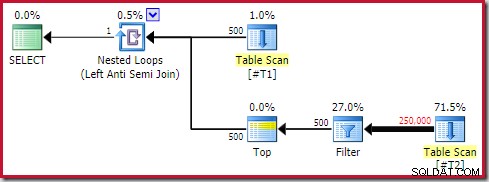
Tidak setiap rencana eksekusi yang berisi penerapan anti join dengan operator Top (1) di sisi dalamnya akan bermasalah. Namun demikian, ini adalah pola untuk dikenali dan pola yang hampir selalu membutuhkan penyelidikan lebih lanjut.
Empat elemen utama yang harus diperhatikan adalah:
- Loop bersarang yang berkorelasi (berlaku ) anti bergabung
- A Atas (1) operator segera di sisi dalam
- Jumlah baris yang signifikan pada input luar (sehingga sisi dalam akan dijalankan berkali-kali)
- Sebuah berpotensi mahal subpohon di bawah Atas
Subpohon "$$$" adalah subpohon yang berpotensi mahal saat runtime . Ini bisa sulit untuk dikenali. Jika kita beruntung, akan ada sesuatu yang jelas seperti full table atau index scan. Dalam kasus yang lebih menantang, subpohon akan terlihat sangat polos pada pandangan pertama, tetapi mengandung sesuatu yang mahal jika dilihat lebih dekat. Untuk memberikan contoh yang cukup umum, Anda mungkin melihat Pencarian Indeks yang diharapkan mengembalikan sejumlah kecil baris, tetapi berisi predikat residu mahal yang menguji sejumlah besar baris untuk menemukan beberapa baris yang memenuhi syarat.
Contoh kode AdventureWorks sebelumnya tidak memiliki subpohon "berpotensi mahal". Pencarian Indeks (tanpa predikat residual) akan menjadi metode akses yang optimal terlepas dari pertimbangan tujuan baris. Ini adalah poin penting:memberikan pengoptimal dengan selalu efisien jalur akses data di sisi dalam dari gabungan yang berkorelasi selalu merupakan ide yang bagus. Ini bahkan lebih benar ketika aplikasi berjalan dalam mode anti join dengan operator Top (1) di sisi dalam.
Sekarang mari kita lihat contoh yang memiliki kinerja runtime yang cukup buruk karena pola anti ini.
Contoh
Skrip berikut membuat dua tabel sementara tumpukan. Yang pertama memiliki 500 baris yang berisi bilangan bulat dari 1 hingga 500 inklusif. Tabel kedua memiliki 500 salinan dari setiap baris di tabel pertama, dengan total 250.000 baris. Kedua tabel menggunakan sql_variant tipe data.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Kinerja
Kami sekarang menjalankan kueri mencari baris di tabel yang lebih kecil yang tidak ada di tabel yang lebih besar (tentu saja tidak ada):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Kueri ini berjalan sekitar 20 detik , yang merupakan waktu yang sangat lama untuk membandingkan 500 baris dengan 250.000. Perkiraan rencana SSMS membuat sulit untuk melihat mengapa kinerja mungkin sangat buruk:
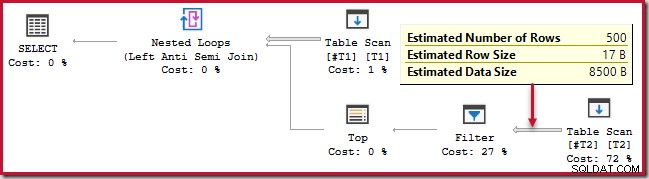
Pengamat perlu menyadari bahwa rencana perkiraan SSMS menunjukkan perkiraan sisi dalam per iterasi dari loop bersarang bergabung. Yang membingungkan, paket sebenarnya SSMS menunjukkan jumlah baris pada semua iterasi . Plan Explorer secara otomatis melakukan perhitungan sederhana yang diperlukan untuk perkiraan rencana untuk juga menunjukkan jumlah total baris yang diharapkan:
Meski begitu, performa runtime jauh lebih buruk dari yang diperkirakan. Rencana eksekusi pasca-eksekusi (sebenarnya) adalah:
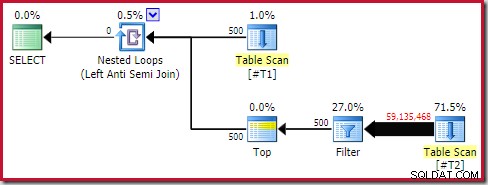
Perhatikan Filter terpisah, yang biasanya akan didorong ke bawah ke dalam pindaian sebagai predikat residual. Ini adalah alasan untuk menggunakan sql_variant tipe data; itu mencegah mendorong predikat, yang membuat sejumlah besar baris dari pemindaian lebih mudah dilihat.
Analisis
Alasan perbedaan tersebut terletak pada bagaimana pengoptimal memperkirakan jumlah baris yang perlu dibaca dari Pemindaian Tabel untuk memenuhi sasaran satu baris yang ditetapkan di Filter. Asumsi sederhananya adalah bahwa nilai terdistribusi secara seragam dalam tabel, jadi untuk menemukan 1 dari 500 nilai unik yang ada, SQL Server perlu membaca 250.000 / 500 =500 baris. Lebih dari 500 iterasi, menjadi 250.000 baris.
Asumsi keseragaman pengoptimal adalah asumsi umum, tetapi tidak berfungsi dengan baik di sini. Anda dapat membaca lebih lanjut tentang ini di A Row Goal Request oleh Joe Obbish, dan memilih sarannya di forum umpan balik penggantian Connect di Use More Than Density to Cost a Scan in the Inner Side of Nested Loop with TOP.
Pandangan saya tentang aspek spesifik ini adalah bahwa pengoptimal harus dengan cepat mundur dari asumsi keseragaman sederhana ketika operator berada di sisi dalam dari gabungan loop bersarang (yaitu perkiraan rewinds plus rebinds lebih besar dari satu). Ini adalah satu hal untuk mengasumsikan bahwa kita perlu membaca 500 baris untuk menemukan kecocokan pada iterasi pertama dari loop. Untuk mengasumsikan ini pada setiap iterasi tampaknya sangat tidak mungkin akurat; itu berarti 500 baris pertama yang ditemui harus berisi satu dari setiap nilai yang berbeda. Hal ini sangat tidak mungkin terjadi dalam praktiknya.
Rangkaian Peristiwa yang Tidak Menyenangkan
Terlepas dari cara biaya operator Top yang berulang, menurut saya seluruh situasi harus dihindari sejak awal . Ingat bagaimana Top dalam rencana ini dibuat:
- Pengoptimal memperkenalkan agregat sisi dalam yang berbeda sebagai pengoptimalan kinerja .
- Agregat ini memberikan kunci pada kolom gabungan menurut definisi (menghasilkan keunikan).
- Kunci yang dibuat ini memberikan target untuk konversi dari gabungan ke penerapan.
- Predikat (seleksi) yang terkait dengan penerapan didorong ke bawah melewati agregat.
- Agregat sekarang dijamin untuk beroperasi pada satu nilai berbeda per iterasi (karena ini adalah nilai korelasi).
- Agregat diganti dengan Top (1).
Semua transformasi ini valid secara individual. Mereka adalah bagian dari operasi pengoptimal normal karena mencari rencana eksekusi yang wajar. Sayangnya, hasilnya di sini adalah agregat spekulatif yang diperkenalkan oleh pengoptimal akhirnya berubah menjadi Top (1) dengan sasaran baris terkait . Sasaran baris mengarah ke penetapan biaya yang tidak akurat berdasarkan asumsi keseragaman, dan kemudian ke pemilihan rencana yang sangat kecil kemungkinannya untuk berkinerja baik.
Sekarang, orang mungkin keberatan bahwa penerapan anti join akan tetap memiliki tujuan baris – tanpa urutan transformasi di atas. Argumen tandingannya adalah bahwa pengoptimal tidak akan mempertimbangkan transformasi dari anti join menjadi apply anti join (menetapkan tujuan baris) tanpa agregat yang diperkenalkan pengoptimal memberikan LASJNtoApply mengatur sesuatu untuk mengikat. Selain itu, kita telah melihat (di bagian tiga) bahwa jika anti gabung telah memasukkan pengoptimalan berbasis biaya sebagai penerapan (bukan gabungan), lagi-lagi tidak ada sasaran baris .
Singkatnya, tujuan baris dalam rencana akhir sepenuhnya buatan, dan tidak memiliki dasar dalam spesifikasi kueri asli. Masalah dengan sasaran Top and row adalah efek samping dari aspek yang lebih mendasar ini.
Solusi
Ada banyak solusi potensial untuk masalah ini. Menghapus salah satu langkah dalam urutan pengoptimalan di atas akan memastikan pengoptimal tidak menghasilkan penerapan anti gabung dengan biaya yang dikurangi secara dramatis (dan artifisial). Semoga masalah ini akan segera diatasi di SQL Server.
Sementara itu, saran saya adalah mewaspadai pola anti join anti. Pastikan bagian dalam dari apply anti join selalu memiliki jalur akses yang efisien untuk semua kondisi runtime. Jika ini tidak memungkinkan, Anda mungkin perlu menggunakan petunjuk, menonaktifkan sasaran baris, menggunakan panduan rencana, atau memaksa rencana penyimpanan kueri untuk mendapatkan kinerja yang stabil dari kueri anti-gabung.
Ringkasan Seri
Kami telah membahas banyak hal selama empat angsuran, jadi inilah ringkasan tingkat tinggi:
- Bagian 1 – Menetapkan dan Mengidentifikasi Sasaran Baris
- Sintaks kueri tidak menentukan ada atau tidaknya sasaran baris.
- Sasaran baris hanya ditetapkan bila sasaran kurang dari perkiraan biasa.
- Operator Top Fisik (termasuk yang diperkenalkan oleh pengoptimal) menambahkan sasaran baris ke subpohonnya.
- A
FASTatauSET ROWCOUNTpernyataan menetapkan tujuan baris di akar rencana. - Semi join dan anti join boleh tambahkan sasaran baris.
- SQL Server 2017 CU3 menambahkan atribut showplan EstimateRowsWithoutRowGoal untuk operator yang terpengaruh oleh sasaran baris
- Informasi sasaran baris dapat diungkapkan oleh tanda jejak tidak berdokumen 8607 dan 8612.
- Bagian 2 – Setengah Bergabung
- Tidak mungkin mengekspresikan semi join secara langsung di T-SQL, jadi kami menggunakan sintaks tidak langsung mis.
IN,EXISTS, atauINTERSECT. - Sintaks ini diuraikan menjadi pohon yang berisi apply (gabungan berkorelasi).
- Pengoptimal mencoba mengubah penerapan menjadi gabungan biasa (tidak selalu memungkinkan).
- Hash, merge, dan loop bersarang reguler semi join tidak menetapkan tujuan baris.
- Terapkan semi gabung selalu menetapkan sasaran baris.
- Terapkan semi join dapat dikenali dengan memiliki Referensi Luar pada loop bersarang bergabung dengan operator.
- Terapkan semi join tidak menggunakan operator Top (1) di sisi dalam.
- Bagian 3 – Anti Bergabung
- Juga diuraikan menjadi aplikasi, dengan upaya untuk menulis ulang itu sebagai gabungan (tidak selalu memungkinkan).
- Hash, merge, dan loop bersarang reguler anti join tidak menetapkan tujuan baris.
- Terapkan anti gabung tidak selalu menetapkan sasaran baris.
- Hanya aturan pengoptimalan berbasis biaya (CBO) yang mengubah anti-gabung menjadi penerapan yang menetapkan sasaran baris.
- Anti join harus masuk CBO sebagai join (tidak berlaku). Jika tidak, penggabungan untuk menerapkan transformasi tidak dapat terjadi.
- Untuk masuk CBO sebagai bergabung, penulisan ulang pra-CBO dari apply to join harus berhasil.
- CBO hanya mengeksplorasi penulisan ulang anti join ke aplikasi dalam kasus yang menjanjikan.
- Penyederhanaan pra-CBO dapat dilihat dengan tanda jejak tidak berdokumen 8621.
- Bagian 4 – Pola Anti-Gabungan
- Pengoptimal hanya menetapkan sasaran baris untuk menerapkan anti gabung jika ada alasan yang menjanjikan untuk melakukannya.
- Sayangnya, beberapa transformasi pengoptimal yang berinteraksi menambahkan operator Top (1) ke sisi dalam anti join yang berlaku.
- Operator Top berlebihan; itu tidak diperlukan untuk kebenaran atau efisiensi.
- Top selalu menetapkan sasaran baris (tidak seperti yang berlaku, yang membutuhkan alasan yang baik).
- Gol baris yang tidak beralasan dapat menyebabkan performa yang sangat buruk.
- Hati-hati dengan subpohon yang berpotensi mahal di bawah Top buatan (1).