Partisi tabel di SQL Server pada dasarnya adalah cara membuat beberapa tabel fisik (rowset) terlihat seperti satu tabel. Abstraksi ini dilakukan sepenuhnya oleh pemroses kueri, sebuah desain yang membuat segalanya lebih sederhana bagi pengguna, tetapi membuat tuntutan kompleks dari pengoptimal kueri. Posting ini membahas dua contoh yang melebihi kemampuan pengoptimal di SQL Server 2008 dan seterusnya.
Bergabung dengan Kolom Urutan Penting
Contoh pertama ini menunjukkan bagaimana urutan tekstual dari ON kondisi klausa dapat memengaruhi rencana kueri yang dihasilkan saat bergabung dengan tabel yang dipartisi. Untuk memulainya, kita memerlukan skema partisi, fungsi partisi, dan dua tabel:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Selanjutnya, kami memuat kedua tabel dengan 150.000 baris. Data tidak terlalu penting; contoh ini menggunakan tabel Numbers standar yang berisi semua nilai integer dari 1 hingga 150.000 sebagai sumber data. Kedua tabel dimuat dengan data yang sama.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Kueri pengujian kami melakukan gabungan dalam sederhana dari dua tabel ini. Sekali lagi, kueri tidak penting atau dimaksudkan untuk menjadi sangat realistis, ini digunakan untuk menunjukkan efek aneh saat bergabung dengan tabel yang dipartisi. Bentuk kueri pertama menggunakan ON klausa ditulis dengan urutan kolom c3, c2, c1:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Rencana eksekusi yang dihasilkan untuk kueri ini (pada SQL Server 2008 dan yang lebih baru) menampilkan gabungan hash paralel, dengan perkiraan biaya 2,6953 :
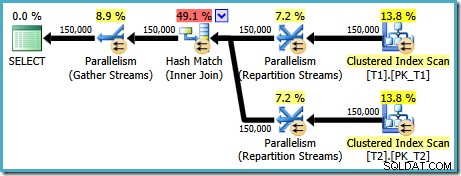
Ini agak tidak terduga. Kedua tabel memiliki indeks berkerumun dalam urutan (c1, c2, c3), dipartisi oleh c1, jadi kami mengharapkan penggabungan gabungan, mengambil keuntungan dari urutan indeks. Mari kita coba menulis ON klausa dalam urutan (c1, c2, c3) sebagai gantinya:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Rencana eksekusi sekarang menggunakan penggabungan gabungan yang diharapkan, dengan perkiraan biaya 1,64119 (turun dari 2,6953 ). Pengoptimal juga memutuskan bahwa tidak layak menggunakan eksekusi paralel:
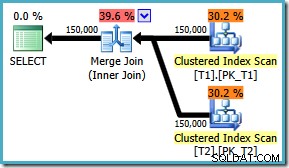
Memperhatikan bahwa rencana penggabungan gabungan jelas lebih efisien, kami dapat mencoba memaksa penggabungan gabungan untuk ON asli urutan klausa menggunakan petunjuk kueri:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Paket yang dihasilkan memang menggunakan gabungan gabungan seperti yang diminta, tetapi juga menampilkan pengurutan pada kedua input, dan kembali menggunakan paralelisme. Perkiraan biaya paket ini adalah 8,71063 who :
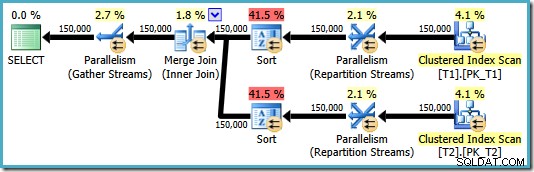
Kedua operator pengurutan memiliki properti yang sama:
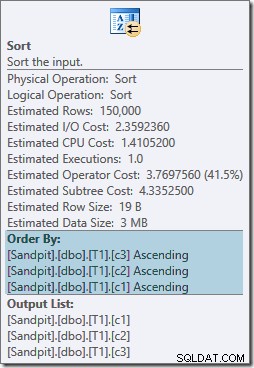
Pengoptimal menganggap penggabungan gabungan perlu inputnya diurutkan dalam urutan tertulis yang ketat dari ON klausa, memperkenalkan jenis eksplisit sebagai hasilnya. Pengoptimal menyadari bahwa penggabungan gabungan memerlukan input yang diurutkan dengan cara yang sama, tetapi juga mengetahui bahwa urutan kolom tidak menjadi masalah. Gabung gabung di (c1, c2, c3) sama-sama senang dengan input yang diurutkan (c3, c2, c1) seperti halnya dengan input yang diurutkan (c2, c1, c3) atau kombinasi lainnya.
Sayangnya, alasan ini rusak dalam pengoptimal kueri saat partisi terlibat. Ini adalah bug pengoptimal yang telah diperbaiki di SQL Server 2008 R2 dan yang lebih baru, meskipun tanda jejak 4199 diperlukan untuk mengaktifkan perbaikan:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Anda biasanya akan mengaktifkan tanda pelacakan ini menggunakan DBCC TRACEON atau sebagai opsi awal, karena QUERYTRACEON petunjuk tidak didokumentasikan untuk digunakan dengan 4199. Bendera pelacakan diperlukan di SQL Server 2008 R2, SQL Server 2012, dan SQL Server 2014 CTP1.
Bagaimanapun, bagaimanapun tandanya diaktifkan, kueri sekarang menghasilkan gabungan gabungan yang optimal apa pun ON urutan klausa:
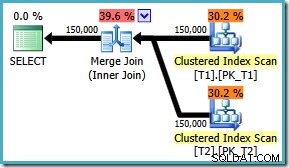
Tidak ada tidak ada perbaikan untuk SQL Server 2008 , solusinya adalah dengan menulis ON klausa dalam urutan 'benar'! Jika Anda menemukan kueri seperti ini di SQL Server 2008, coba paksa gabungkan gabungan dan lihat jenisnya untuk menentukan cara yang 'benar' untuk menulis ON kueri Anda klausa.
Masalah ini tidak muncul di SQL Server 2005 karena rilis tersebut mengimplementasikan kueri yang dipartisi menggunakan APPLY model:

Paket kueri SQL Server 2005 menggabungkan satu partisi dari setiap tabel pada satu waktu, menggunakan tabel dalam memori (Pemindaian Konstan) yang berisi nomor partisi untuk diproses. Setiap partisi digabungkan bergabung secara terpisah di sisi dalam gabungan, dan pengoptimal 2005 cukup pintar untuk melihat bahwa ON urutan kolom klausa tidak masalah.
Paket terbaru ini adalah contoh dari gabungan gabungan yang ditempatkan , fasilitas yang hilang saat berpindah dari SQL Server 2005 ke implementasi partisi baru di SQL Server 2008. Saran tentang Sambungkan untuk memulihkan gabungan gabungan gabungan telah ditutup karena Tidak Dapat Diperbaiki.
Kelompokkan Berdasarkan Urutan Penting
Keunikan kedua yang ingin saya lihat mengikuti tema yang sama, tetapi berkaitan dengan urutan kolom dalam GROUP BY klausa daripada ON klausa dari gabungan dalam. Kita akan membutuhkan tabel baru untuk mendemonstrasikan:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; Tabel memiliki indeks nonclustered yang disejajarkan, di mana 'aligned' berarti tabel dipartisi dengan cara yang sama seperti indeks berkerumun (atau heap):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Kueri pengujian kami mengelompokkan data di tiga kolom indeks nonclustered dan mengembalikan hitungan untuk setiap grup:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Rencana kueri memindai indeks nonclustered dan menggunakan Agregat Pencocokan Hash untuk menghitung baris di setiap grup:
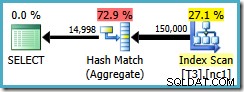
Ada dua masalah dengan Agregat Hash:
- Ini adalah operator pemblokiran. Tidak ada baris yang dikembalikan ke klien sampai semua baris digabungkan.
- Memerlukan hibah memori untuk menyimpan tabel hash.
Dalam banyak skenario dunia nyata, kami lebih memilih Stream Aggregate di sini karena operator tersebut hanya memblokir per grup, dan tidak memerlukan pemberian memori. Dengan menggunakan opsi ini, aplikasi klien akan mulai menerima data lebih awal, tidak perlu menunggu memori diberikan, dan SQL Server dapat menggunakan memori untuk tujuan lain.
Kami dapat meminta pengoptimal kueri untuk menggunakan Agregat Aliran untuk kueri ini dengan menambahkan OPTION (ORDER GROUP) petunjuk kueri. Ini menghasilkan rencana eksekusi berikut:

Operator Sortir sepenuhnya memblokir dan juga memerlukan hibah memori, jadi rencana ini tampaknya lebih buruk daripada hanya menggunakan agregat hash. Tapi mengapa semacam itu dibutuhkan? Properti menunjukkan bahwa baris sedang diurutkan dalam urutan yang ditentukan oleh GROUP BY our kami klausa:
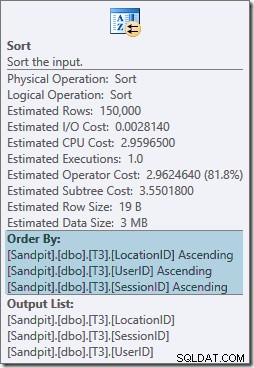
Jenis ini diharapkan karena penyelarasan partisi indeks (dalam SQL Server 2008 dan seterusnya) berarti nomor partisi ditambahkan sebagai kolom utama indeks. Akibatnya, kunci indeks nonclustered adalah (partisi, pengguna, sesi, lokasi) karena partisi. Baris dalam indeks masih diurutkan berdasarkan pengguna, sesi, dan lokasi, tetapi hanya dalam setiap partisi.
Jika kita membatasi kueri ke satu partisi, pengoptimal harus dapat menggunakan indeks untuk memberi makan Agregat Aliran tanpa menyortir. Dalam kasus yang memerlukan beberapa penjelasan, menentukan satu partisi berarti rencana kueri dapat menghilangkan semua partisi lain dari pemindaian indeks nonclustered, menghasilkan aliran baris yang diurutkan oleh (pengguna, sesi, lokasi).
Kita dapat mencapai penghapusan partisi ini secara eksplisit menggunakan $PARTITION fungsi:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Sayangnya, kueri ini masih menggunakan Agregat Hash, dengan perkiraan biaya paket 0,287878 :
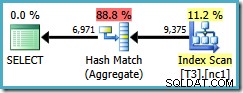
Pemindaian sekarang lebih dari satu partisi, tetapi pemesanan (pengguna, sesi, lokasi) tidak membantu pengoptimal menggunakan Agregat Aliran. Anda mungkin keberatan bahwa (pengguna, sesi, lokasi) pemesanan tidak membantu karena GROUP BY klausa adalah (lokasi, pengguna, sesi), tetapi urutan kunci tidak masalah untuk operasi pengelompokan.
Mari tambahkan ORDER BY klausa dalam urutan kunci indeks untuk membuktikan maksudnya:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Perhatikan bahwa ORDER BY klausa cocok dengan urutan kunci indeks nonclustered, meskipun GROUP BY klausa tidak. Rencana eksekusi untuk kueri ini adalah:
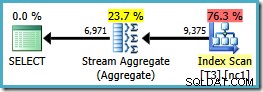
Sekarang kami memiliki Agregat Aliran yang kami cari, dengan perkiraan biaya paket 0,0423925 (dibandingkan dengan 0,287878 untuk paket Hash Aggregate – hampir 7 kali lebih banyak).
Cara lain untuk mencapai Agregat Aliran di sini adalah dengan menyusun ulang GROUP BY kolom agar sesuai dengan kunci indeks nonclustered:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Kueri ini menghasilkan paket Stream Agregate yang sama yang ditunjukkan langsung di atas, dengan biaya yang sama persis. Kepekaan ini terhadap GROUP BY urutan kolom khusus untuk kueri tabel yang dipartisi di SQL Server 2008 dan yang lebih baru.
Anda mungkin menyadari bahwa akar penyebab masalah di sini mirip dengan kasus sebelumnya yang melibatkan Gabung Gabung. Baik Merge Join dan Stream Aggregate memerlukan input yang diurutkan pada kunci gabungan atau agregasi, tetapi tidak ada yang peduli dengan urutan kunci tersebut. Gabung Gabung pada (x, y, z) sama senangnya menerima baris yang diurutkan oleh (y, z, x) atau (z, y, x) dan hal yang sama berlaku untuk Agregat Aliran.
Batasan pengoptimal ini juga berlaku untuk DISTINCT dalam situasi yang sama. Kueri berikut menghasilkan paket Agregat Hash dengan perkiraan biaya 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
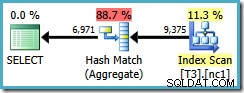
Jika kita menulis DISTINCT kolom dalam urutan kunci indeks nonclustered…
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
…kami mendapatkan paket Stream Aggregate dengan biaya 0,041455 :

Untuk meringkas, ini adalah batasan pengoptimal kueri di SQL Server 2008 dan yang lebih baru (termasuk SQL Server 2014 CTP 1) yang tidak diselesaikan dengan menggunakan bendera pelacakan 4199 seperti yang terjadi pada contoh Gabung Gabung. Masalah hanya terjadi pada tabel yang dipartisi dengan GROUP BY atau DISTINCT lebih dari tiga kolom atau lebih menggunakan indeks partisi yang disejajarkan, tempat satu partisi diproses.
Seperti contoh Gabung Gabung, ini mewakili langkah mundur dari perilaku SQL Server 2005. SQL Server 2005 tidak menambahkan kunci utama tersirat ke indeks yang dipartisi, menggunakan APPLY teknik sebagai gantinya. Di SQL Server 2005, semua kueri disajikan di sini menggunakan $PARTITION untuk menentukan hasil partisi tunggal dalam rencana kueri yang melakukan penghapusan partisi dan menggunakan Agregat Aliran tanpa menyusun ulang teks kueri.
Perubahan pada pemrosesan tabel yang dipartisi di SQL Server 2008 meningkatkan kinerja di beberapa area penting, terutama terkait dengan pemrosesan partisi paralel yang efisien. Sayangnya, perubahan ini memiliki efek samping yang belum semuanya teratasi di rilis selanjutnya.