Ini adalah bagian keempat dari seri tentang solusi untuk tantangan generator seri nomor. Terima kasih banyak kepada Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea, dan Paul White untuk berbagi ide dan komentar Anda.
Saya suka karya Paul White. Saya terus dikejutkan oleh penemuannya, dan bertanya-tanya bagaimana dia tahu apa yang dia lakukan. Saya juga menyukai gaya penulisannya yang efisien dan fasih. Seringkali saat membaca artikel atau postingannya, saya menggelengkan kepala dan memberi tahu istri saya, Lilach, bahwa ketika saya besar nanti, saya ingin menjadi seperti Paul.
Ketika saya awalnya memposting tantangan, saya diam-diam berharap Paul akan memposting solusi. Saya tahu bahwa jika dia melakukannya, itu akan menjadi hal yang sangat istimewa. Ya, dia melakukannya, dan itu menarik! Ini memiliki kinerja yang sangat baik, dan ada banyak hal yang dapat Anda pelajari darinya. Artikel ini didedikasikan untuk solusi Paul.
Saya akan melakukan pengujian di tempdb, mengaktifkan I/O dan statistik waktu:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME, IO ON;
Keterbatasan ide sebelumnya
Mengevaluasi solusi sebelumnya, salah satu faktor penting untuk mendapatkan kinerja yang baik adalah kemampuan untuk menggunakan pemrosesan batch. Tapi apakah kita sudah memanfaatkannya semaksimal mungkin?
Mari kita periksa rencana untuk dua solusi sebelumnya yang menggunakan pemrosesan batch. Di Bagian 1 saya membahas fungsi dbo.GetNumsAlanCharlieItzikBatch, yang menggabungkan ide dari Alan, Charlie, dan saya sendiri.
Berikut definisi fungsinya:
-- Helper dummy table
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
GO
-- Function definition
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Solusi ini mendefinisikan konstruktor nilai tabel dasar dengan 16 baris, dan serangkaian CTE berjenjang dengan gabungan silang untuk meningkatkan jumlah baris hingga berpotensi 4B. Solusinya menggunakan fungsi ROW_NUMBER untuk membuat urutan dasar angka dalam CTE yang disebut Nums, dan filter TOP untuk menyaring kardinalitas deret angka yang diinginkan. Untuk mengaktifkan pemrosesan batch, solusinya menggunakan dummy left join dengan kondisi false antara Nums CTE dan tabel yang disebut dbo.BatchMe, yang memiliki indeks columnstore.
Gunakan kode berikut untuk menguji fungsi dengan teknik penetapan variabel:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
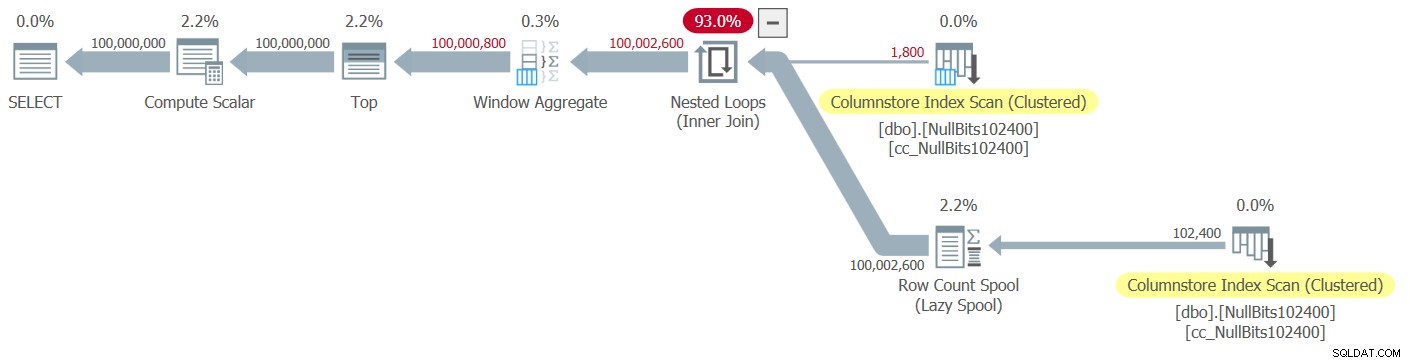
Penggambaran Plan Explorer dari sebenarnya rencana untuk eksekusi ini ditunjukkan pada Gambar 1.
 Gambar 1:Rencanakan fungsi dbo.GetNumsAlanCharlieItzikBatch
Gambar 1:Rencanakan fungsi dbo.GetNumsAlanCharlieItzikBatch
Saat menganalisis mode batch vs pemrosesan mode baris, cukup bagus untuk mengetahui hanya dengan melihat rencana pada tingkat tinggi mode pemrosesan mana yang digunakan setiap operator. Memang, Plan Explorer menunjukkan gambar batch biru muda di bagian kiri bawah operator ketika mode eksekusi yang sebenarnya adalah Batch. Seperti yang Anda lihat pada Gambar 1, satu-satunya operator yang menggunakan mode batch adalah operator Agregat Jendela, yang menghitung nomor baris. Masih banyak pekerjaan yang dilakukan oleh operator lain dalam mode baris.
Berikut adalah angka kinerja yang saya dapatkan dalam pengujian saya:
Waktu CPU =10032 md, waktu berlalu =10025 md.pembacaan logis 0
Untuk mengidentifikasi operator mana yang membutuhkan waktu paling lama untuk mengeksekusi, gunakan opsi Rencana Eksekusi Aktual di SSMS, atau opsi Dapatkan Paket Aktual di Plan Explorer. Pastikan Anda membaca artikel terbaru Paul Memahami Waktu Operator Rencana Eksekusi. Artikel tersebut menjelaskan cara menormalkan waktu eksekusi operator yang dilaporkan untuk mendapatkan angka yang benar.
Dalam rencana di Gambar 1, sebagian besar waktu dihabiskan oleh operator Nested Loops dan Top paling kiri, keduanya mengeksekusi dalam mode baris. Selain mode baris kurang efisien dibandingkan mode batch untuk operasi intensif CPU, perlu diingat juga bahwa beralih dari mode baris ke mode batch dan kembali membutuhkan biaya ekstra.
Di Bagian 2 saya membahas solusi lain yang menggunakan pemrosesan batch, diimplementasikan dalam fungsi dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2. Solusi ini menggabungkan ide-ide dari John Number2, Dave Mason, Joe Obbish, Alan, Charlie dan saya sendiri. Perbedaan utama antara solusi sebelumnya dan yang ini adalah bahwa sebagai unit dasar, yang pertama menggunakan konstruktor nilai tabel virtual dan yang terakhir menggunakan tabel aktual dengan indeks columnstore, memberi Anda pemrosesan batch "gratis." Berikut kode yang membuat tabel dan mengisinya menggunakan pernyataan INSERT dengan 102.400 baris agar tabel dikompresi:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Berikut definisi fungsinya:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Penggabungan silang tunggal antara dua contoh tabel dasar sudah cukup untuk menghasilkan jauh melampaui potensi baris 4B yang diinginkan. Sekali lagi di sini, solusinya menggunakan fungsi ROW_NUMBER untuk menghasilkan urutan angka dasar dan filter TOP untuk membatasi kardinalitas deret angka yang diinginkan.
Berikut kode untuk menguji fungsi menggunakan teknik penetapan variabel:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
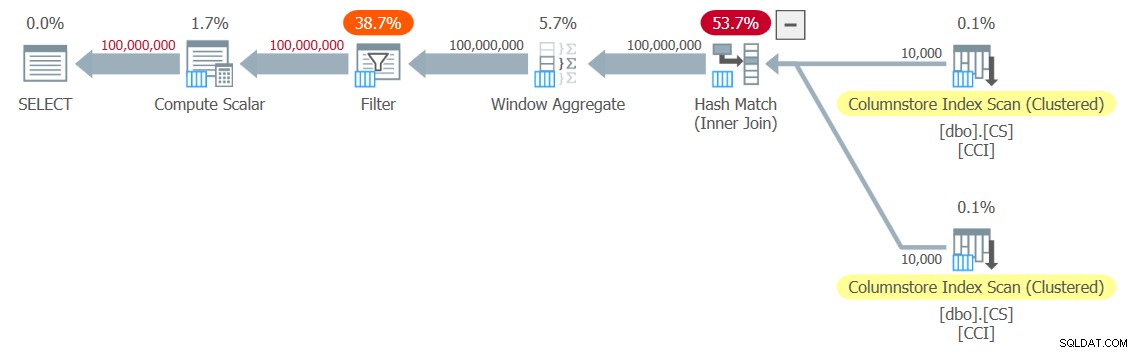
Rencana eksekusi ini ditunjukkan pada Gambar 2.
 Gambar 2:Rencanakan fungsi dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Gambar 2:Rencanakan fungsi dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Perhatikan bahwa hanya dua operator dalam paket ini yang menggunakan mode batch—pindaian teratas dari indeks penyimpanan kolom terklaster tabel, yang digunakan sebagai input luar dari gabungan Nested Loops, dan operator Agregat Jendela, yang digunakan untuk menghitung nomor baris dasar .
Saya mendapatkan nomor kinerja berikut untuk pengujian saya:
Waktu CPU =9812 md, waktu berlalu =9813 md.Tabel 'NullBits102400'. Hitungan pemindaian 2, pembacaan logis 0, pembacaan fisik 0, pembacaan server halaman 0, pembacaan ke depan membaca 0, pembacaan server halaman pembacaan ke depan 0, pembacaan logika lob 8, pembacaan fisik lob 0, server halaman lob membaca 0, pembacaan lob- ke depan membaca 0, server halaman lob membaca ke depan membaca 0.
Tabel 'NullBits102400'. Segmen dibaca 2, segmen dilewati 0.
Sekali lagi, sebagian besar waktu dalam eksekusi rencana ini dihabiskan oleh operator Nested Loops dan Top paling kiri, yang dieksekusi dalam mode baris.
Solusi Paul
Sebelum saya mempresentasikan solusi Paul, saya akan memulai dengan teori saya tentang proses berpikir yang dia lalui. Ini sebenarnya adalah latihan pembelajaran yang bagus, dan saya sarankan Anda melakukannya sebelum melihat solusinya. Paul mengenali efek melemahkan dari rencana yang menggabungkan mode batch dan baris, dan memberikan tantangan pada dirinya sendiri untuk menemukan solusi yang mendapatkan rencana mode semua batch. Jika berhasil, potensi solusi seperti itu untuk bekerja dengan baik cukup tinggi. Sangat menarik untuk melihat apakah tujuan tersebut bahkan dapat dicapai mengingat masih banyak operator yang belum mendukung mode batch dan banyak faktor yang menghambat pemrosesan batch. Misalnya, pada saat penulisan, satu-satunya algoritma join yang mendukung pemrosesan batch adalah algoritma hash join. Penggabungan silang dioptimalkan menggunakan algoritma loop bersarang. Selanjutnya, operator Top saat ini diimplementasikan hanya dalam mode baris. Kedua elemen ini adalah elemen fundamental penting yang digunakan dalam rencana untuk banyak solusi yang saya bahas sejauh ini, termasuk dua di atas.
Dengan asumsi bahwa Anda memberikan tantangan untuk membuat solusi dengan rencana mode semua batch percobaan yang layak, mari lanjutkan ke latihan kedua. Saya pertama-tama akan menyajikan solusi Paul saat dia memberikannya, dengan komentar sebarisnya. Saya juga akan menjalankannya untuk membandingkan kinerjanya dengan solusi lain. Saya belajar banyak dengan mendekonstruksi dan merekonstruksi solusinya, selangkah demi selangkah, untuk memastikan saya memahami dengan cermat mengapa dia menggunakan setiap teknik yang dia lakukan. Saya akan menyarankan Anda melakukan hal yang sama sebelum melanjutkan membaca penjelasan saya.
Inilah solusi Paul, yang melibatkan tabel penyimpanan kolom pembantu yang disebut dbo.CS dan fungsi yang disebut dbo.GetNums_SQLkiwi:
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scala
@low - 2 + N.rn < @high;
GO Berikut kode yang saya gunakan untuk menguji fungsi dengan teknik penetapan variabel:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000);
Saya mendapatkan rencana yang ditunjukkan pada Gambar 3 untuk pengujian saya.
 Gambar 3:Rencanakan fungsi dbo.GetNums_SQLkiwi
Gambar 3:Rencanakan fungsi dbo.GetNums_SQLkiwi
Ini adalah paket mode semua-batch! Itu cukup mengesankan.
Berikut adalah angka kinerja yang saya dapatkan untuk pengujian ini di mesin saya:
Waktu CPU =7812 md, waktu berlalu =7876 md.Tabel 'CS'. Hitungan pemindaian 2, pembacaan logis 0, pembacaan fisik 0, pembacaan server halaman 0, pembacaan ke depan 0, pembacaan ke depan server halaman pembacaan 0, pembacaan logika lob 44, pembacaan fisik lob 0, pembacaan server halaman lob 0, pembacaan lob- ke depan membaca 0, server halaman lob membaca ke depan membaca 0.
Tabel 'CS'. Segmen dibaca 2, segmen dilewati 0.
Mari kita juga memverifikasi bahwa jika Anda perlu mengembalikan angka yang diurutkan oleh n, solusinya adalah mempertahankan urutan sehubungan dengan rn—setidaknya saat menggunakan konstanta sebagai input—dan dengan demikian menghindari pengurutan eksplisit dalam rencana. Berikut kode untuk mengujinya dengan pesanan:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
Anda mendapatkan paket yang sama seperti pada Gambar 3, dan oleh karena itu angka kinerja serupa:
Waktu CPU =7765 md, waktu berlalu =7822 md.Tabel 'CS'. Hitungan pemindaian 2, pembacaan logis 0, pembacaan fisik 0, pembacaan server halaman 0, pembacaan ke depan 0, pembacaan ke depan server halaman pembacaan 0, pembacaan logika lob 44, pembacaan fisik lob 0, pembacaan server halaman lob 0, pembacaan lob- ke depan membaca 0, server halaman lob membaca ke depan membaca 0.
Tabel 'CS'. Segmen dibaca 2, segmen dilewati 0.
Itu adalah sisi penting dari solusi.
Mengubah metodologi pengujian kami
Performa solusi Paul adalah peningkatan yang layak dalam waktu yang telah berlalu dan waktu CPU dibandingkan dengan dua solusi sebelumnya, tetapi sepertinya bukan peningkatan yang lebih dramatis yang diharapkan dari paket mode semua-batch. Mungkin kita melewatkan sesuatu?
Coba kita analisa waktu eksekusi operator dengan melihat Actual Execution Plan di SSMS seperti pada Gambar 4.
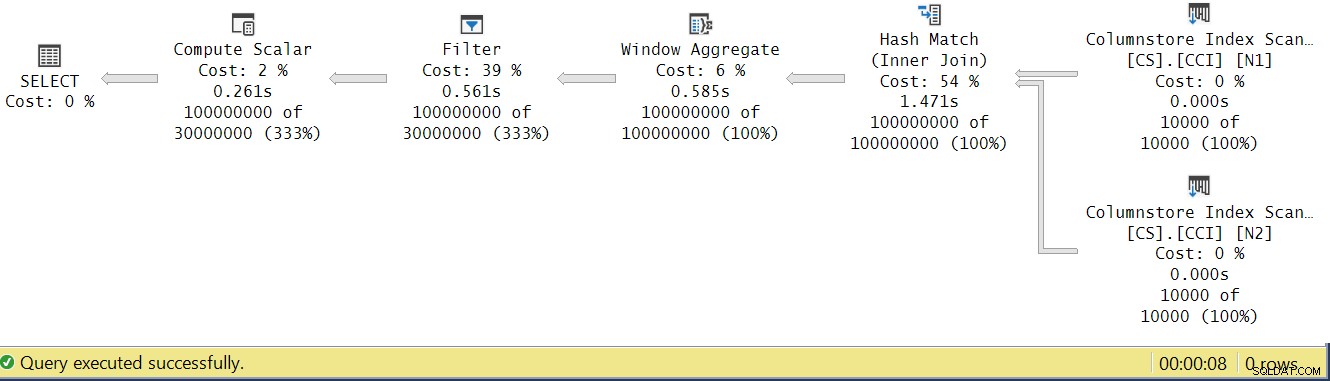 Gambar 4:Waktu eksekusi operator untuk fungsi dbo.GetNums_SQLkiwi
Gambar 4:Waktu eksekusi operator untuk fungsi dbo.GetNums_SQLkiwi
Dalam artikel Paul tentang menganalisis waktu eksekusi operator, dia menjelaskan bahwa dengan mode batch, masing-masing operator melaporkan waktu eksekusinya sendiri. Jika Anda menjumlahkan waktu eksekusi semua operator dalam paket aktual ini, Anda akan mendapatkan 2,878 detik, namun paket tersebut membutuhkan 7,876 untuk dieksekusi. 5 detik dari waktu eksekusi tampaknya hilang. Jawabannya terletak pada teknik pengujian yang kami gunakan, dengan penugasan variabel. Ingatlah bahwa kami memutuskan untuk menggunakan teknik ini untuk menghilangkan kebutuhan untuk mengirim semua baris dari server ke pemanggil dan untuk menghindari I/Os yang akan terlibat dalam penulisan hasil ke tabel. Sepertinya itu pilihan yang sempurna. Namun, biaya sebenarnya dari penugasan variabel disembunyikan dalam rencana ini, dan tentu saja, dijalankan dalam mode baris. Misteri terpecahkan.
Jelas pada akhirnya, tes yang baik adalah tes yang cukup mencerminkan penggunaan solusi produksi Anda. Jika Anda biasanya menulis data ke tabel, Anda memerlukan pengujian untuk mencerminkan hal itu. Jika Anda mengirim hasilnya ke penelepon, Anda memerlukan tes Anda untuk mencerminkan hal itu. Bagaimanapun, penugasan variabel tampaknya mewakili sebagian besar waktu eksekusi dalam pengujian kami, dan jelas tidak mungkin mewakili penggunaan fungsi produksi yang khas. Paul menyarankan bahwa alih-alih penugasan variabel, tes dapat menerapkan agregat sederhana seperti MAX ke kolom angka yang dikembalikan (n/rn/op). Operator agregat dapat memanfaatkan pemrosesan batch, sehingga rencana tersebut tidak akan melibatkan konversi dari mode batch ke mode baris sebagai akibat dari penggunaannya, dan kontribusinya terhadap total waktu berjalan seharusnya cukup kecil dan diketahui.
Jadi mari kita uji ulang ketiga solusi yang tercakup dalam artikel ini. Berikut kode untuk menguji fungsi dbo.GetNumsAlanCharlieItzikBatch:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Saya mendapatkan rencana yang ditunjukkan pada Gambar 5 untuk tes ini.
 Gambar 5:Rencanakan fungsi dbo.GetNumsAlanCharlieItzikBatch dengan agregat
Gambar 5:Rencanakan fungsi dbo.GetNumsAlanCharlieItzikBatch dengan agregat
Berikut adalah angka performa yang saya dapatkan untuk tes ini:
Waktu CPU =8469 md, waktu berlalu =8733 md.pembacaan logis 0
Amati bahwa run time turun dari 10,025 detik menggunakan teknik penugasan variabel menjadi 8,733 menggunakan teknik agregat. Itu sedikit lebih dari satu detik dari waktu eksekusi yang dapat kita kaitkan dengan penugasan variabel di sini.
Berikut kode untuk menguji fungsi dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
SELECT MAX(n) AS mx FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Saya mendapatkan rencana yang ditunjukkan pada Gambar 6 untuk tes ini.
 Gambar 6:Rencanakan fungsi dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 dengan agregat
Gambar 6:Rencanakan fungsi dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 dengan agregat
Berikut adalah angka performa yang saya dapatkan untuk tes ini:
Waktu CPU =7031 md, waktu berlalu =7053 md.Tabel 'NullBits102400'. Hitungan pemindaian 2, pembacaan logis 0, pembacaan fisik 0, pembacaan server halaman 0, pembacaan ke depan membaca 0, pembacaan server halaman pembacaan ke depan 0, pembacaan logika lob 8, pembacaan fisik lob 0, server halaman lob membaca 0, pembacaan lob- ke depan membaca 0, server halaman lob membaca ke depan membaca 0.
Tabel 'NullBits102400'. Segmen dibaca 2, segmen dilewati 0.
Amati bahwa run time turun dari 9,813 detik menggunakan teknik penugasan variabel menjadi 7,053 menggunakan teknik agregat. Itu sedikit lebih dari dua detik dari waktu eksekusi yang dapat kita kaitkan dengan penugasan variabel di sini.
Dan inilah kode untuk menguji solusi Paul:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Saya mendapatkan rencana yang ditunjukkan pada Gambar 7 untuk tes ini.
 Gambar 7:Rencanakan fungsi dbo.GetNums_SQLkiwi dengan agregat
Gambar 7:Rencanakan fungsi dbo.GetNums_SQLkiwi dengan agregat
Dan sekarang untuk momen besar. Saya mendapatkan angka kinerja berikut untuk tes ini:
Waktu CPU =3125 md, waktu yang berlalu =3149 md.Tabel 'CS'. Hitungan pemindaian 2, pembacaan logis 0, pembacaan fisik 0, pembacaan server halaman 0, pembacaan ke depan 0, pembacaan ke depan server halaman pembacaan 0, pembacaan logika lob 44, pembacaan fisik lob 0, pembacaan server halaman lob 0, pembacaan lob- ke depan membaca 0, server halaman lob membaca ke depan membaca 0.
Tabel 'CS'. Segmen dibaca 2, segmen dilewati 0.
Waktu lari turun dari 7,822 detik menjadi 3,149 detik! Mari kita periksa waktu eksekusi operator dalam rencana aktual di SSMS, seperti yang ditunjukkan pada Gambar 8.
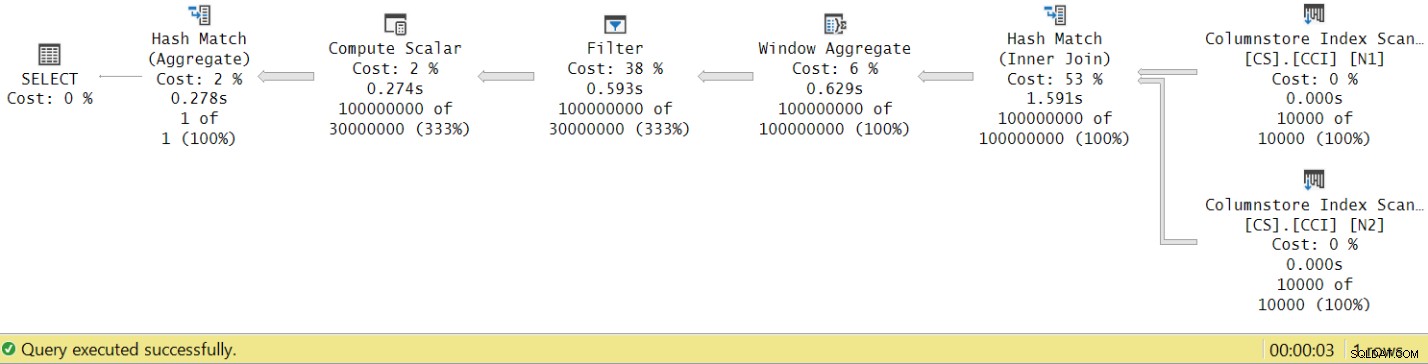 Gambar 8:Waktu eksekusi operator untuk fungsi dbo.GetNums dengan agregat
Gambar 8:Waktu eksekusi operator untuk fungsi dbo.GetNums dengan agregat
Sekarang jika Anda mengumpulkan waktu eksekusi dari masing-masing operator, Anda akan mendapatkan angka yang sama dengan total waktu eksekusi rencana.
Gambar 9 memiliki perbandingan kinerja dalam hal waktu yang telah berlalu antara tiga solusi menggunakan baik penugasan variabel dan teknik pengujian agregat.
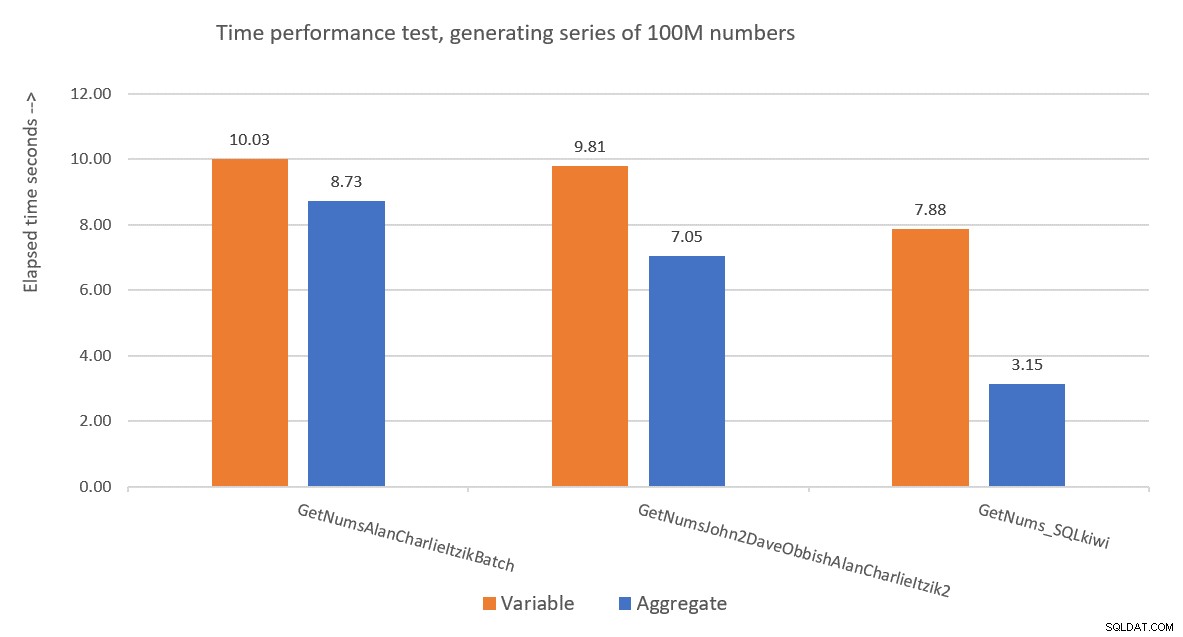 Gambar 9:Perbandingan kinerja
Gambar 9:Perbandingan kinerja
Solusi Paul adalah pemenang yang jelas, dan ini terutama terlihat saat menggunakan teknik pengujian agregat. Sungguh prestasi yang mengesankan!
Mendekonstruksi dan merekonstruksi solusi Paul
Mendekonstruksi dan kemudian merekonstruksi solusi Paul adalah latihan yang bagus, dan Anda bisa belajar banyak saat melakukannya. Seperti yang disarankan sebelumnya, saya sarankan Anda menjalani prosesnya sendiri sebelum melanjutkan membaca.
Pilihan pertama yang perlu Anda buat adalah teknik yang akan Anda gunakan untuk menghasilkan jumlah baris 4B potensial yang diinginkan. Paul memilih untuk menggunakan tabel columnstore dan mengisinya dengan baris sebanyak akar kuadrat dari angka yang diperlukan, yang berarti 65.536 baris, sehingga dengan satu gabungan silang, Anda akan mendapatkan nomor yang diperlukan. Mungkin Anda berpikir bahwa dengan kurang dari 102.400 baris Anda tidak akan mendapatkan grup baris terkompresi, tetapi ini berlaku saat Anda mengisi tabel dengan pernyataan INSERT seperti yang kami lakukan dengan tabel dbo.NullBits102400. Itu tidak berlaku saat Anda membuat indeks penyimpanan kolom pada tabel yang telah diisi sebelumnya. Jadi Paul menggunakan pernyataan SELECT INTO untuk membuat dan mengisi tabel sebagai heap berbasis rowstore dengan 65.536 baris, lalu membuat indeks columnstore berkerumun, menghasilkan grup baris terkompresi.
Tantangan selanjutnya adalah mencari tahu bagaimana cara mendapatkan cross join untuk diproses dengan operator mode batch. Untuk ini, Anda memerlukan algoritma join menjadi hash. Ingat bahwa gabungan silang dioptimalkan menggunakan algoritma loop bersarang. Anda entah bagaimana perlu mengelabui pengoptimal untuk berpikir bahwa Anda menggunakan equijoin dalam (hash membutuhkan setidaknya satu predikat berbasis kesetaraan), tetapi dapatkan cross join dalam praktiknya.
Upaya pertama yang jelas adalah menggunakan inner join dengan predikat artificial join yang selalu benar, seperti:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON 0 = 0; Tetapi kode ini gagal dengan kesalahan berikut:
Pesan 8622, Level 16, Status 1, Baris 246Pemroses kueri tidak dapat menghasilkan rencana kueri karena petunjuk yang ditentukan dalam kueri ini. Kirim ulang kueri tanpa menentukan petunjuk apa pun dan tanpa menggunakan SET FORCEPLAN.
Pengoptimal SQL Server mengenali bahwa ini adalah predikat gabungan dalam buatan, menyederhanakan gabungan dalam menjadi gabungan silang, dan menghasilkan kesalahan yang mengatakan bahwa ia tidak dapat mengakomodasi petunjuk untuk memaksa algoritme gabungan hash.
Untuk mengatasi ini, Paul membuat kolom INT NOT NULL (lebih lanjut tentang mengapa spesifikasi ini segera) disebut n1 di tabel dbo.CS-nya, dan mengisinya dengan 0 di semua baris. Dia kemudian menggunakan predikat gabungan N2.n1 =N1.n1, secara efektif mendapatkan proposisi 0 =0 di semua evaluasi kecocokan, sambil mematuhi persyaratan minimal untuk algoritme gabungan hash.
Ini berfungsi dan menghasilkan paket mode semua-batch:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON N2.n1 = N1.n1; Adapun alasan n1 didefinisikan sebagai INT NOT NULL; mengapa melarang NULL, dan mengapa tidak menggunakan BIGINT? Alasan untuk pilihan ini adalah untuk menghindari sisa pemeriksaan hash (filter tambahan yang diterapkan oleh operator gabungan hash di luar predikat gabungan asli), yang dapat mengakibatkan biaya tambahan yang tidak perlu. Lihat artikel Paul Bergabung dengan Performa, Konversi Implisit, dan Residual untuk detailnya. Inilah bagian dari artikel yang relevan bagi kami:
"Jika gabungan berada pada satu kolom yang diketik sebagai tinyint, smallint, atau integer dan jika kedua kolom dibatasi menjadi NOT NULL, fungsi hash adalah 'sempurna' — artinya tidak ada kemungkinan tabrakan hash, dan pemroses kueri tidak perlu memeriksa nilainya lagi untuk memastikan nilainya benar-benar cocok.Perhatikan bahwa pengoptimalan ini tidak berlaku untuk kolom bigint."
Untuk memeriksa aspek ini, mari buat tabel lain bernama dbo.CS2 dengan kolom n1 yang dapat dibatalkan:
DROP TABLE IF EXISTS dbo.CS2; SELECT * INTO dbo.CS2 FROM dbo.CS; ALTER TABLE dbo.CS2 ALTER COLUMN n1 INT NULL; CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS2 WITH (MAXDOP = 1);
Mari kita uji kueri terlebih dahulu terhadap dbo.CS (di mana n1 didefinisikan sebagai INT NOT NULL), menghasilkan 4B nomor baris dasar dalam kolom yang disebut rn, dan menerapkan agregat MAX ke kolom:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
) AS N; Kami akan membandingkan paket untuk kueri ini dengan paket untuk kueri serupa terhadap dbo.CS2 (di mana n1 didefinisikan sebagai INT NULL):
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS2 AS N1
JOIN dbo.CS2 AS N2
ON N2.n1 = N1.n1
) AS N; Rencana untuk kedua kueri ditunjukkan pada Gambar 10.
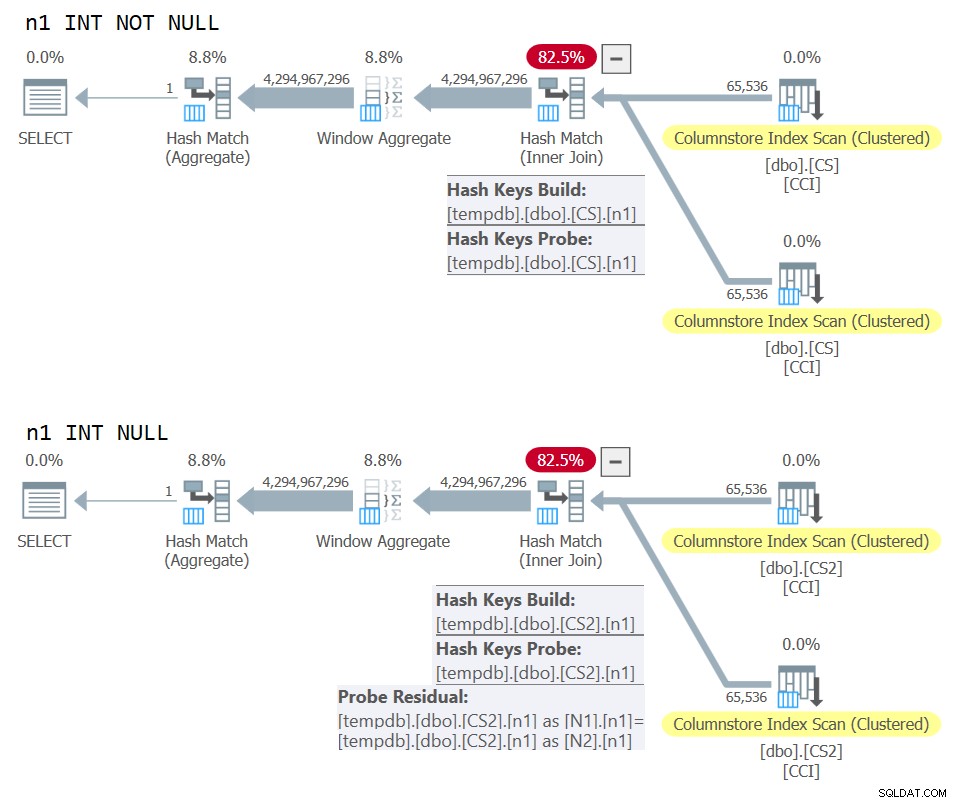 Gambar 10:Perbandingan paket untuk NOT NULL vs NULL join key
Gambar 10:Perbandingan paket untuk NOT NULL vs NULL join key
Anda dapat dengan jelas melihat sisa pemeriksaan tambahan yang diterapkan pada rencana kedua tetapi bukan yang pertama.
Di mesin saya, kueri terhadap dbo.CS selesai dalam 91 detik, dan kueri terhadap dbo.CS2 selesai dalam 92 detik. Dalam artikel Paul, dia melaporkan perbedaan 11% yang mendukung kasus NOT NULL untuk contoh yang dia gunakan.
BTW, Anda yang jeli akan memperhatikan penggunaan ORDER BY @@TRANCOUNT sebagai spesifikasi pemesanan fungsi ROW_NUMBER. Jika Anda membaca dengan cermat komentar sebaris Paul dalam solusinya, ia menyebutkan bahwa penggunaan fungsi @@TRANCOUNT adalah penghambat paralelisme, sedangkan penggunaan @@SPID tidak. Jadi Anda dapat menggunakan @@TRANCOUNT sebagai konstanta waktu proses dalam spesifikasi pemesanan saat Anda ingin memaksakan paket serial dan @@SPID saat tidak.
Seperti yang disebutkan, dibutuhkan kueri terhadap dbo.CS 91 detik untuk berjalan di mesin saya. Pada titik ini mungkin menarik untuk menguji kode yang sama dengan gabungan silang yang sebenarnya, membiarkan pengoptimal menggunakan algoritma gabungan loop bersarang mode baris:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
CROSS JOIN dbo.CS AS N2
) AS N; Butuh kode ini 104 detik untuk diselesaikan di mesin saya. Jadi kami mendapatkan peningkatan kinerja yang cukup besar dengan penggabungan hash mode batch.
Masalah kami berikutnya adalah kenyataan bahwa ketika menggunakan TOP untuk memfilter jumlah baris yang diinginkan, Anda mendapatkan paket dengan operator Top mode baris. Berikut ini upaya untuk mengimplementasikan fungsi dbo.GetNums_SQLkiwi dengan filter TOP:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT TOP (100000000 - 1 + 1)
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
ORDER BY rn
) AS N;
GO Mari kita uji fungsinya:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Saya mendapatkan rencana yang ditunjukkan pada Gambar 11 untuk tes ini.
 Gambar 11:Rencanakan dengan filter TOP
Gambar 11:Rencanakan dengan filter TOP
Perhatikan bahwa operator Top adalah satu-satunya dalam paket yang menggunakan pemrosesan mode baris.
Saya mendapatkan statistik waktu berikut untuk eksekusi ini:
Waktu CPU =6078 md, waktu yang berlalu =6071 md.Bagian terbesar dari waktu berjalan dalam paket ini dihabiskan oleh operator Top mode baris dan fakta bahwa paket tersebut harus melalui konversi mode batch-ke-baris dan sebaliknya.
Tantangan kami adalah menemukan alternatif pemfilteran mode batch untuk TOP mode baris. Filter berbasis predikat seperti yang diterapkan dengan klausa WHERE berpotensi dapat ditangani dengan pemrosesan batch.
Pendekatan Paul adalah memperkenalkan kolom kedua yang diketik INT (lihat komentar sebaris “semuanya dinormalisasi ke 64-bit dalam mode columnstore/batch” ) memanggil n2 ke tabel dbo.CS, dan mengisinya dengan barisan bilangan bulat 1 hingga 65.536. Dalam kode solusi ia menggunakan dua filter berbasis predikat. Salah satunya adalah filter kasar dalam kueri dalam dengan predikat yang melibatkan kolom n2 dari kedua sisi gabungan. Filter kasar ini dapat menghasilkan beberapa hasil positif palsu. Inilah upaya sederhana pertama pada filter semacam itu:
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1)))) Dengan input 1 dan 100.000.000 sebagai @low dan @high, Anda tidak mendapatkan kesalahan positif. Tapi coba dengan 1 dan 100.000.001, dan Anda mendapatkan beberapa. Anda akan mendapatkan urutan 100.020.001 angka, bukan 100.000.001.
Untuk menghilangkan positif palsu, Paul menambahkan filter kedua, tepat, yang melibatkan kolom rn di kueri luar. Inilah upaya sederhana pertama pada filter yang tepat:
WHERE
-- Precise filter:
N.rn < @high - @low + 2 Mari kita revisi definisi fungsi untuk menggunakan filter berbasis predikat di atas alih-alih TOP, ambil 1:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
N.rn < @high - @low + 2;
GO Mari kita uji fungsinya:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Saya mendapatkan rencana yang ditunjukkan pada Gambar 12 untuk tes ini.
 Gambar 12:Rencanakan dengan filter WHERE, ambil 1
Gambar 12:Rencanakan dengan filter WHERE, ambil 1
Sayangnya, ada sesuatu yang tidak beres. SQL Server mengonversi filter berbasis predikat kami yang melibatkan kolom rn ke filter berbasis TOP, dan mengoptimalkannya dengan operator Top—yang persis seperti yang kami coba hindari. Untuk menambahkan penghinaan pada cedera, pengoptimal juga memutuskan untuk menggunakan algoritme loop bersarang untuk penggabungan.
Butuh kode ini 18,8 detik untuk menyelesaikan di mesin saya. Tidak terlihat bagus.
Mengenai gabungan loop bersarang, ini adalah sesuatu yang bisa kita tangani dengan mudah menggunakan petunjuk bergabung di kueri dalam. Hanya untuk melihat dampak kinerja, berikut adalah pengujian dengan petunjuk kueri gabungan hash paksa yang digunakan dalam kueri pengujian itu sendiri:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(HASH JOIN);
Waktu berjalan berkurang menjadi 13,2 detik.
Kami masih memiliki masalah dengan konversi filter WHERE terhadap rn ke filter TOP. Mari kita coba dan pahami bagaimana ini terjadi. Kami menggunakan filter berikut dalam kueri luar:
WHERE N.rn < @high - @low + 2
Ingat bahwa rn mewakili ekspresi berbasis ROW_NUMBER yang tidak dimanipulasi. Filter berdasarkan ekspresi yang tidak dimanipulasi seperti itu dalam rentang tertentu sering dioptimalkan dengan operator Top, yang bagi kami adalah berita buruk karena penggunaan pemrosesan mode baris.
Solusi Paul adalah menggunakan predikat yang setara, tetapi predikat yang menerapkan manipulasi ke rn, seperti:
WHERE @low - 2 + N.rn < @high
Memfilter ekspresi yang menambahkan manipulasi ke ekspresi berbasis ROW_NUMBER akan menghambat konversi filter berbasis predikat ke filter berbasis TOP. Itu brilian!
Mari kita revisi definisi fungsi untuk menggunakan predikat WHERE di atas, ambil 2:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
@low - 2 + N.rn < @high;
GO Uji fungsi lagi, tanpa petunjuk khusus atau apa pun:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Ini secara alami mendapatkan paket mode semua-batch dengan algoritma hash join dan tanpa operator Top, menghasilkan waktu eksekusi 3,177 detik. Terlihat bagus.
Langkah selanjutnya adalah memeriksa apakah solusi menangani input yang buruk dengan baik. Mari kita coba dengan delta negatif:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
Eksekusi ini gagal dengan kesalahan berikut.
Msg 3623, Level 16, State 1, Line 436Terjadi operasi floating point yang tidak valid.
Kegagalan ini disebabkan oleh upaya untuk menerapkan akar kuadrat dari angka negatif.
Solusi Paul melibatkan dua tambahan. Salah satunya adalah menambahkan predikat berikut ke klausa WHERE kueri dalam:
@high >= @low
Filter ini melakukan lebih dari yang terlihat pada awalnya. Jika Anda telah membaca komentar sebaris Paul dengan cermat, Anda dapat menemukan bagian ini:
“Cobalah untuk menghindari SQRT pada angka negatif dan aktifkan penyederhanaan ke pemindaian konstan tunggal jika @rendah> @tinggi (dengan literal). Tidak ada filter start-up dalam mode batch.”Bagian yang menarik di sini adalah potensi untuk menggunakan pemindaian konstan dengan konstanta sebagai input. Saya akan segera menyelesaikannya.
Penambahan lainnya adalah menerapkan fungsi IIF ke ekspresi input ke fungsi SQRT. Ini dilakukan untuk menghindari input negatif saat menggunakan nonkonstanta sebagai input ke fungsi angka kami, dan jika pengoptimal memutuskan untuk menangani predikat yang melibatkan SQRT sebelum predikat @high>=@low.
Sebelum penambahan IIF, misalnya, predikat yang melibatkan N1.n2 terlihat seperti ini:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
After adding IIF, it looks like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
With these two additions, we’re now basically ready for the final definition of the dbo.GetNums_SQLkiwi function:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Now back to the comment about the constant scan. When using constants that result in a negative range as inputs to the function, e.g., 100,000,000 and 1 as @low and @high, after parameter embedding the WHERE filter of the inner query looks like this:
WHERE
1 >= 100000000
AND ... The whole plan can then be simplified to a single Constant Scan operator. Cobalah:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
The plan for this execution is shown in Figure 13.
 Figure 13:Plan with constant scan
Figure 13:Plan with constant scan
Unsurprisingly, I got the following performance numbers for this execution:
CPU time =0 ms, elapsed time =0 ms.logical reads 0
When passing a negative range with nonconstants as inputs, the use of the IIF function will prevent any attempt to compute a square root of a negative input.
Now let’s test the function with a valid input range:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
You get the all-batch-mode plan shown in Figure 14.
 Figure 14:Plan for dbo.GetNums_SQLkiwi function
Figure 14:Plan for dbo.GetNums_SQLkiwi function
This is the same plan you saw earlier in Figure 7.
I got the following time statistics for this execution:
CPU time =3000 ms, elapsed time =3111 ms.Ladies and gentlemen, I think we have a winner! :)
Kesimpulan
I’ll have what Paul’s having.
Are we done yet, or is this series going to last forever?
No and no.