[ Bagian 1 | Bagian 2 | Bagian 3 ]
Di bagian 1, saya menunjukkan bagaimana kompresi halaman dan penyimpanan kolom dapat mengurangi ukuran tabel 1TB hingga 80% atau lebih. Meskipun saya terkesan bahwa saya dapat mengecilkan tabel dari 1TB menjadi 50GB, saya tidak terlalu senang dengan jumlah waktu yang dibutuhkan (mulai dari 2 hingga 14 jam). Dengan beberapa tip yang dipinjam dari orang-orang seperti Joe Obbish, Lonny Niederstadt, Niko Neugebauer, dan lainnya, dalam posting ini saya akan mencoba membuat beberapa perubahan pada upaya awal saya untuk mendapatkan kinerja pemuatan yang lebih baik. Karena indeks penyimpanan kolom biasa tidak mengompresi lebih baik daripada kompresi halaman pada kumpulan data ini , dan butuh 13 jam lebih lama untuk sampai ke sana, saya hanya akan fokus pada solusi yang lebih canggih menggunakan COLUMNSTORE_ARCHIVE kompresi.
Beberapa masalah yang menurut saya memengaruhi kinerja adalah sebagai berikut:
- Pilihan tata letak file yang buruk – Saya menempatkan 8 file dalam satu filegroup, dengan paralelisme tetapi tidak ada partisi (atau suboptimal), menyemprotkan I/O ke beberapa file dengan sembrono. Untuk mengatasinya, saya akan:
- partisi tabel menjadi 8 partisi (satu per inti)
- letakkan file data setiap partisi pada grup filenya sendiri
- gunakan 8 proses terpisah untuk menghubungkan ke setiap partisi
- gunakan kompresi arsip pada semua kecuali partisi "aktif"
- terlalu banyak kelompok kecil dan populasi kelompok baris yang kurang optimal – dengan memproses 10 juta baris sekaligus, saya mengisi sembilan grup baris dengan 1,048.576 baris yang bagus, dan kemudian 562.816 baris yang tersisa akan berakhir di grup baris lain yang lebih kecil. Dan setiap distribusi tidak rata yang meninggalkan sisa <102.400 baris akan meneteskan sisipan ke dalam struktur penyimpanan delta yang kurang efisien. Untuk mendistribusikan baris lebih seragam dan menghindari toko delta, saya akan:
- memproses data sebanyak mungkin dalam kelipatan tepat 1.048.576 baris
- sebarkan ke 8 partisi secara merata
- gunakan ukuran batch mendekati 10x -> 100 juta baris
- penjadwalan menumpuk – sementara saya tidak memeriksanya, mungkin beberapa pelambatan disebabkan oleh satu penjadwal mengambil terlalu banyak pekerjaan dan penjadwal lain tidak cukup, karena penjadwal round-robining. Sekarang saya akan dengan sengaja memuat data dengan 8 proses maxdop 1 alih-alih satu proses maxdop 8, agar semua penjadwal tetap sibuk, saya akan:
- gunakan prosedur tersimpan yang mencoba menyeimbangkan secara merata di seluruh penjadwal (lihat halaman 189-191 di Panduan SQLCAT untuk:Mesin Relasional untuk inspirasi di balik ide ini)
- aktifkan bendera pelacakan global 2467 dan 2469, seperti yang diperingatkan dalam dokumentasi
- tugas kompresi penyimpanan kolom latar belakang – itu sia-sia untuk membiarkan ini berjalan selama populasi, karena saya berencana untuk membangun kembali pada akhirnya. Kali ini saya akan:
- nonaktifkan tugas ini menggunakan bendera pelacakan global 634
Saya menghapus fungsi dan skema partisi awal, dan membangun yang baru berdasarkan distribusi data yang lebih merata. Saya ingin 8 partisi cocok dengan jumlah inti dan jumlah file data, untuk memaksimalkan "paralelisme orang miskin" yang saya rencanakan untuk digunakan.
Pertama, kita perlu membuat kumpulan filegroup baru, masing-masing dengan filenya sendiri:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
Selanjutnya, saya melihat jumlah baris dalam tabel:3.754.965.954. Untuk mendistribusikan dengan tepat merata di 8 partisi, itu akan menjadi 469.370.744,25 baris per partisi. Untuk membuatnya bekerja dengan baik, mari buat batas partisi mengakomodasi berikutnya kelipatan 1.048.576 baris. Ini 1,048,576 x 448 = 469,762,048 – yang akan menjadi jumlah baris yang kita bidik di 7 partisi pertama, menyisakan 466.631.618 baris di partisi terakhir. Untuk melihat OID yang sebenarnya nilai yang akan berfungsi sebagai batas untuk memuat jumlah baris optimal di setiap partisi, saya menjalankan kueri ini terhadap tabel asli (karena butuh 25 menit untuk dijalankan, saya dengan cepat belajar membuang hasil ini ke tabel terpisah):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
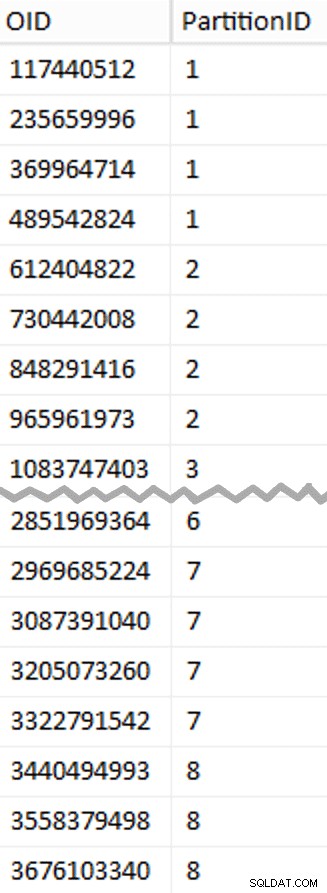 Lebih banyak yang bisa dibongkar di sini daripada yang Anda harapkan. CTE melakukan semua pekerjaan berat, karena harus memindai seluruh tabel 1,14 TB dan menetapkan nomor baris untuk setiap baris . Saya hanya ingin mengembalikan setiap
Lebih banyak yang bisa dibongkar di sini daripada yang Anda harapkan. CTE melakukan semua pekerjaan berat, karena harus memindai seluruh tabel 1,14 TB dan menetapkan nomor baris untuk setiap baris . Saya hanya ingin mengembalikan setiap (1048576*112)th baris, karena ini adalah baris batas batch saya, jadi ini adalah WHERE klausa tidak. Ingat bahwa saya ingin membagi pekerjaan menjadi beberapa batch mendekati 100 juta baris pada satu waktu, tetapi saya juga tidak benar-benar ingin memproses 469 juta baris dalam satu kesempatan. Jadi selain membagi data menjadi 8 partisi, saya ingin membagi masing-masing partisi tersebut menjadi empat batch 117.440.512 (1,048,576*112) baris. Setiap kumpulan empat kumpulan yang berdekatan menjadi milik satu partisi, jadi PartitionID Saya menurunkan hanya menambahkan satu ke hasil dari nomor baris saat ini bilangan bulat dibagi dengan (1,048,576*448) , yang memastikan bahwa batas selalu di set "kiri". Kami kemudian menambahkan satu ke hasil karena jika tidak, kami akan merujuk ke kumpulan partisi berbasis 0, dan tidak ada yang menginginkannya.
Oke, itu banyak kata. Di sebelah kanan adalah gambar yang menunjukkan (disingkat) isi stage tabel (klik untuk menampilkan hasil lengkap, sorot nilai batas partisi).
Kami kemudian dapat memperoleh kueri lain dari tabel pementasan yang menunjukkan kepada kami nilai min dan maks untuk setiap batch di dalam setiap partisi, serta batch tambahan yang tidak diperhitungkan (baris dalam tabel asli dengan OID lebih besar dari nilai batas tertinggi):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Nilai-nilai tersebut terlihat seperti ini:
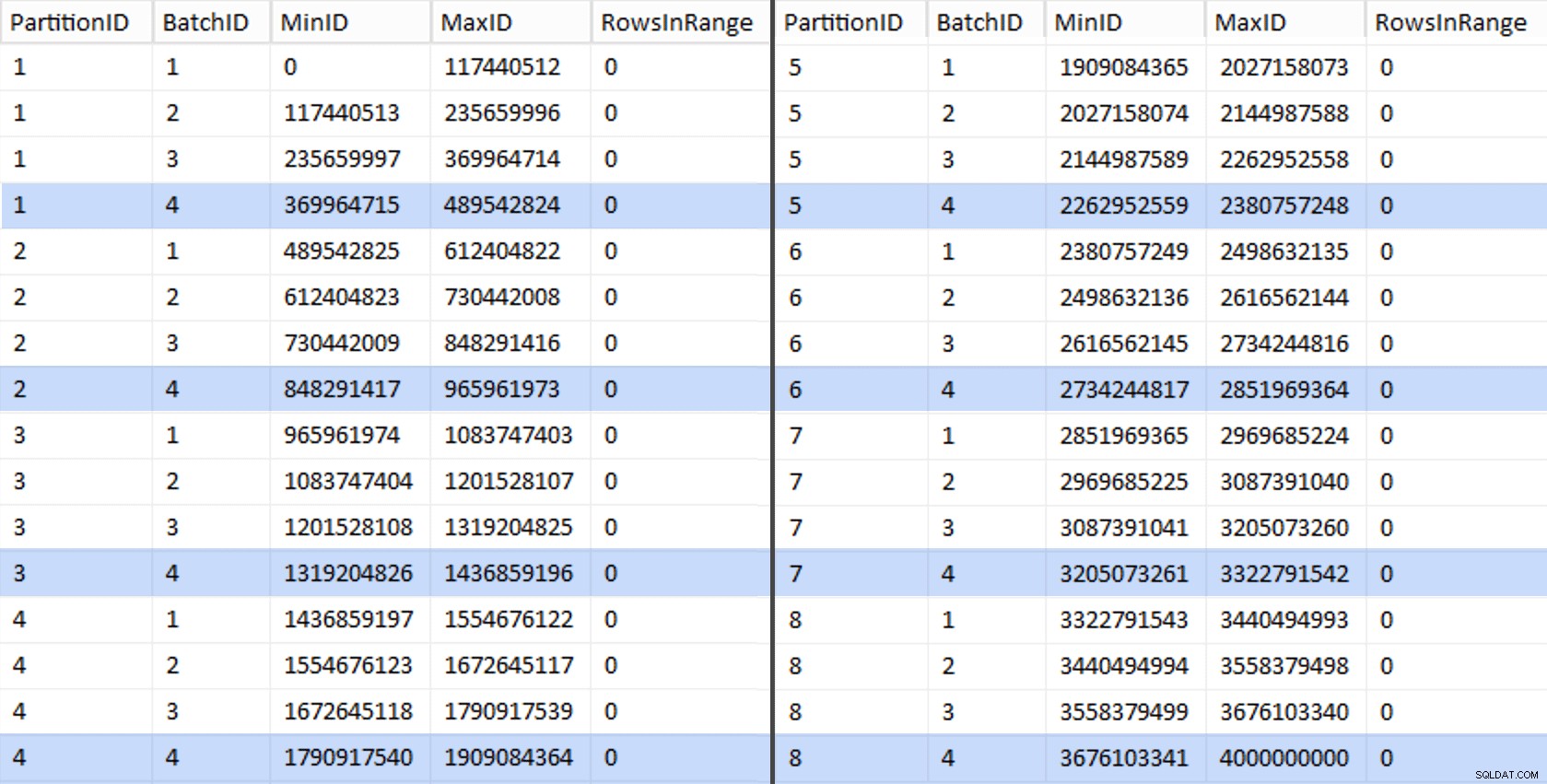
Untuk menguji pekerjaan kami, kami dapat memperoleh dari sana serangkaian kueri yang akan memperbarui BatchQueue dengan jumlah baris aktual dari tabel.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; Ini memakan waktu sekitar 6 menit di sistem saya. Kemudian Anda dapat menjalankan kueri berikut untuk menunjukkan bahwa setiap kumpulan kecuali yang terakhir mampu mengisi penuh grup baris dan tidak meninggalkan sisa untuk penggunaan toko delta potensial:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Sekarang tabelnya terlihat seperti ini:
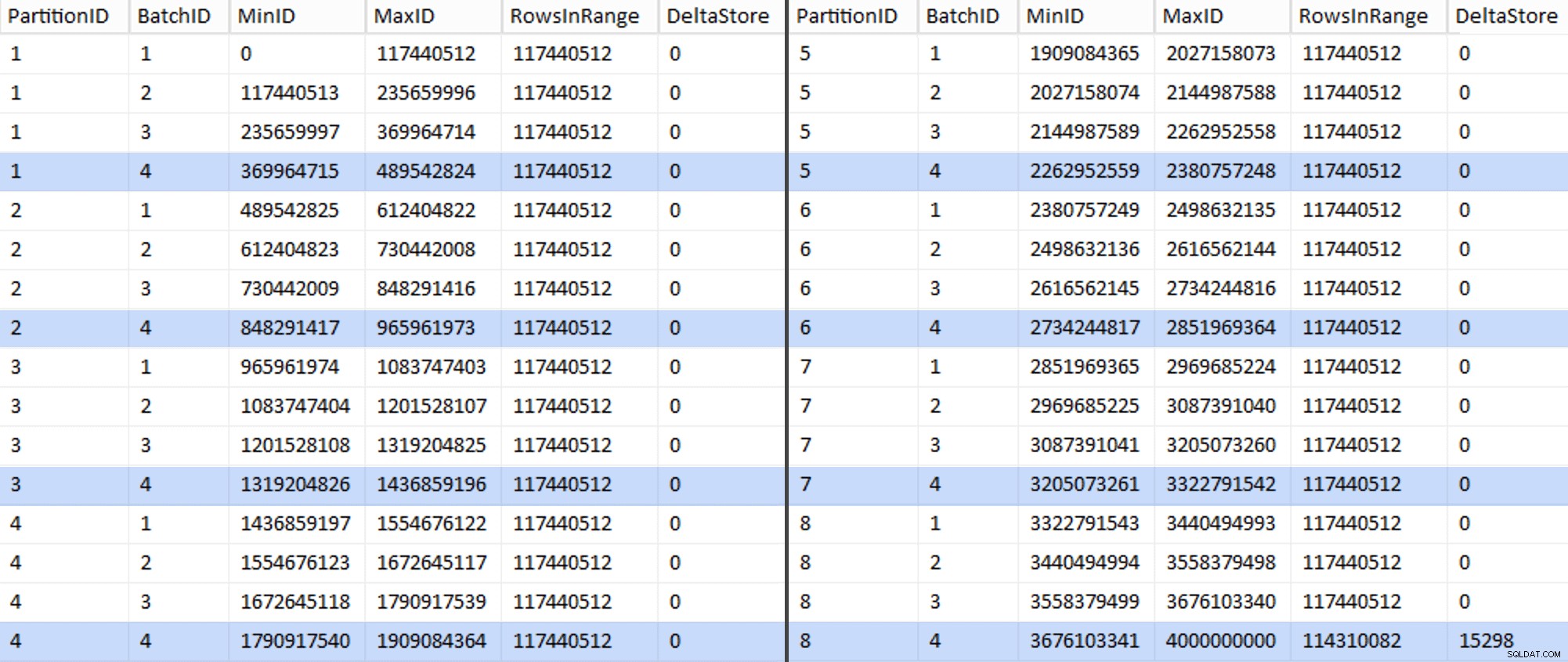
Benar saja, setiap batch memiliki 117.440.512 juta baris yang dihitung, kecuali untuk yang terakhir yang, setidaknya idealnya, berisi satu-satunya toko delta kami yang tidak terkompresi. Kita mungkin dapat mencegah hal ini juga, dengan mengubah ukuran batch sedikit saja untuk partisi ini sehingga keempat batch dijalankan dengan ukuran yang sama, atau dengan mengubah jumlah batch untuk mengakomodasi beberapa kelipatan lainnya 102.400 atau 1.048.576. Karena itu perlu mendapatkan OID baru nilai dari tabel dasar, menambahkan 25 menit lagi plus untuk upaya migrasi kami, saya akan membiarkan partisi yang tidak sempurna ini meluncur — terutama karena kami tidak mendapatkan manfaat kompresi arsip penuh darinya.
BatchQueue tabel mulai menunjukkan tanda-tanda berguna untuk memproses kumpulan kami untuk memigrasikan data ke tabel penyimpanan kolom yang baru, terpartisi, dan berkerumun. Yang perlu kita ciptakan, sekarang kita tahu batas-batasnya. Hanya ada 7 batasan, jadi Anda pasti bisa melakukannya secara manual, tetapi saya ingin membuat SQL dinamis melakukan pekerjaan saya untuk saya:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Hasil:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Setelah dibuat, kita dapat membuat skema partisi dan menetapkan setiap partisi yang berurutan ke file khusus:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Sekarang kita dapat membuat tabel dan menyiapkannya untuk migrasi:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
Di Bagian 3, saya akan mengonfigurasi lebih lanjut BatchQueue tabel, buat prosedur untuk proses untuk mendorong data ke struktur baru, dan menganalisis hasilnya.
[ Bagian 1 | Bagian 2 | Bagian 3 ]