Artikel ini adalah bagian kedelapan dari seri tentang ekspresi tabel. Sejauh ini saya memberikan latar belakang untuk ekspresi tabel, mencakup aspek logis dan optimisasi dari tabel turunan, aspek logis CTE, dan beberapa aspek optimisasi CTE. Bulan ini saya melanjutkan cakupan aspek pengoptimalan CTE, yang secara khusus membahas cara menangani beberapa referensi CTE.
Artikel ini adalah bagian kedelapan dari seri tentang ekspresi tabel. Sejauh ini saya memberikan latar belakang untuk ekspresi tabel, mencakup aspek logis dan optimisasi dari tabel turunan, aspek logis CTE, dan beberapa aspek optimisasi CTE. Bulan ini saya melanjutkan cakupan aspek pengoptimalan CTE, yang secara khusus membahas cara menangani beberapa referensi CTE.
Dalam contoh saya, saya akan terus menggunakan database sampel TSQLV5. Anda dapat menemukan skrip yang membuat dan mengisi TSQLV5 di sini, dan diagram ER-nya di sini.
Beberapa referensi dan nondeterminisme
Bulan lalu saya menjelaskan dan menunjukkan bahwa CTE tidak bersarang, sedangkan tabel sementara dan variabel tabel sebenarnya menyimpan data. Saya memberikan rekomendasi dalam hal kapan masuk akal untuk menggunakan CTE versus kapan masuk akal untuk menggunakan objek sementara dari sudut pandang kinerja kueri. Tetapi ada aspek penting lain dari pengoptimalan CTE, atau pemrosesan fisik, yang perlu dipertimbangkan di luar kinerja solusi—bagaimana banyak referensi ke CTE dari kueri luar ditangani. Penting untuk disadari bahwa jika Anda memiliki kueri luar dengan banyak referensi ke CTE yang sama, masing-masing akan tidak disarangkan secara terpisah. Jika Anda memiliki perhitungan nondeterministik dalam kueri dalam CTE, perhitungan tersebut dapat memiliki hasil yang berbeda dalam referensi yang berbeda.
Katakanlah misalnya bahwa Anda memanggil fungsi SYSDATETIME dalam kueri dalam CTE, membuat kolom hasil yang disebut dt. Umumnya, dengan asumsi tidak ada perubahan pada input, fungsi bawaan dievaluasi sekali per kueri dan referensi, terlepas dari jumlah baris yang terlibat. Jika Anda merujuk ke CTE hanya sekali dari kueri luar, tetapi berinteraksi dengan kolom dt beberapa kali, semua referensi seharusnya mewakili evaluasi fungsi yang sama dan mengembalikan nilai yang sama. Namun, jika Anda merujuk ke CTE beberapa kali di kueri luar, baik itu dengan beberapa subkueri yang merujuk ke CTE atau gabungan antara beberapa instance dari CTE yang sama (katakanlah alias sebagai C1 dan C2), referensi ke C1.dt dan C2.dt mewakili evaluasi yang berbeda dari ekspresi yang mendasarinya dan dapat menghasilkan nilai yang berbeda.
Untuk mendemonstrasikannya, pertimbangkan tiga kelompok berikut:
-- Batch 1 MENYATAKAN @i SEBAGAI INT =1; WHILE @@ROWCOUNT =1 PILIH @i +=1 WHERE SYSDATETIME() =SYSDATETIME(); PRINT @i;GO -- Batch 2 MENYATAKAN @i SEBAGAI INT =1; WHILE @@ROWCOUNT =1 DENGAN C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 FROM C WHERE dt =dt; PRINT @i;GO -- Batch 3 MENYATAKAN @i SEBAGAI INT =1; WHILE @@ROWCOUNT =1 DENGAN C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 WHERE (SELECT dt FROM C) =(SELECT dt FROM C); CETAK @i;GO
Berdasarkan apa yang baru saja saya jelaskan, dapatkah Anda mengidentifikasi batch mana yang memiliki infinite loop dan mana yang akan berhenti di beberapa titik karena dua perbandingan predikat yang mengevaluasi nilai yang berbeda?
Ingat bahwa saya mengatakan bahwa panggilan ke fungsi nondeterministik bawaan seperti SYSDATETIME dievaluasi sekali per kueri dan referensi. Ini berarti bahwa di Batch 1 Anda memiliki dua evaluasi yang berbeda dan setelah iterasi yang cukup dari loop mereka akan menghasilkan nilai yang berbeda. Cobalah. Berapa banyak iterasi yang dilaporkan kode?
Untuk Batch 2, kode memiliki dua referensi ke kolom dt dari instance CTE yang sama, artinya keduanya mewakili evaluasi fungsi yang sama dan harus mewakili nilai yang sama. Akibatnya, Batch 2 memiliki loop tak terbatas. Jalankan untuk waktu berapa pun yang Anda suka, tetapi pada akhirnya Anda harus menghentikan eksekusi kode.
Adapun Batch 3, kueri luar memiliki dua subkueri berbeda yang berinteraksi dengan CTE C, masing-masing mewakili contoh berbeda yang melalui proses unnesting secara terpisah. Kode tidak secara eksplisit menetapkan alias berbeda ke instance CTE yang berbeda karena kedua subkueri muncul dalam cakupan independen, tetapi untuk membuatnya lebih mudah dipahami, Anda dapat menganggap keduanya menggunakan alias yang berbeda seperti C1 dalam satu subkueri dan C2 di sisi lain. Jadi seolah-olah satu subquery berinteraksi dengan C1.dt dan yang lainnya dengan C2.dt. Referensi yang berbeda mewakili evaluasi yang berbeda dari ekspresi yang mendasarinya dan karenanya dapat menghasilkan nilai yang berbeda. Coba jalankan kode dan lihat kode itu berhenti di beberapa titik. Berapa banyak iterasi yang diperlukan sampai berhenti?
Sangat menarik untuk mencoba dan mengidentifikasi kasus di mana Anda memiliki evaluasi tunggal versus beberapa dari ekspresi yang mendasari dalam rencana eksekusi kueri. Gambar 1 memiliki rencana eksekusi grafis untuk tiga kelompok (klik untuk memperbesar).
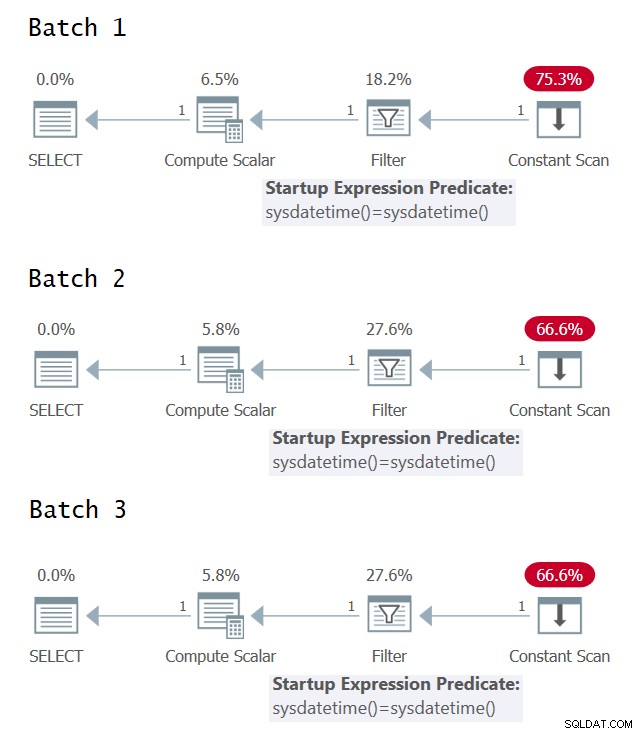 Gambar 1:Rencana eksekusi grafis untuk Batch 1, Batch 2 dan Batch 3
Gambar 1:Rencana eksekusi grafis untuk Batch 1, Batch 2 dan Batch 3
Sayangnya, tidak ada kegembiraan dari rencana eksekusi grafis; mereka semua tampak identik meskipun, secara semantik, ketiga kelompok tersebut tidak memiliki arti yang sama. Terima kasih kepada @CodeRecce dan Forrest (@tsqladdict), sebagai komunitas kami berhasil menyelesaikan ini dengan cara lain.
Seperti yang ditemukan @CodeRecce, paket XML menyimpan jawabannya. Berikut adalah bagian XML yang relevan untuk ketiga kumpulan:
Gelombang 1
…
…
−− Angkatan 2
…
…
−− Angkatan 3
…
…
Anda dapat melihat dengan jelas dalam paket XML untuk Batch 1 bahwa predikat filter membandingkan hasil dari dua pemanggilan langsung terpisah dari fungsi SYSDATETIME intrinsik.
Dalam paket XML untuk Batch 2, predikat filter membandingkan ekspresi konstanta ConstExpr1002 yang mewakili satu pemanggilan fungsi SYSDATETIME dengan dirinya sendiri.
Dalam paket XML untuk Batch 3, predikat filter membandingkan dua ekspresi konstanta berbeda yang disebut ConstExpr1005 dan ConstExpr1006, masing-masing mewakili pemanggilan terpisah dari fungsi SYSDATETIME.
Sebagai opsi lain, Forrest (@tsqladdict) menyarankan menggunakan trace flag 8605, yang menunjukkan representasi pohon kueri awal yang dibuat oleh SQL Server, setelah mengaktifkan trace flag 3604 yang menyebabkan output TF 8605 diarahkan ke klien SSMS. Gunakan kode berikut untuk mengaktifkan kedua tanda jejak:
DBCC TRACEON(3604); -- output langsung ke clientGO DBCC TRACEON(8605); -- tampilkan treeGO kueri awal
Selanjutnya Anda menjalankan kode yang ingin Anda dapatkan pohon kuerinya. Berikut adalah bagian relevan dari output yang saya dapatkan dari TF 8605 untuk tiga batch:
Gelombang 1
*** Pohon yang Dikonversi:***
LogOp_Project COL:Ekspr1000
LogOp_Pilih
LogOp_ConstTableDapatkan (1) [kosong]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
Daftar AncOp_Prj
AncOp_PrjEl COL:Ekspr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Tidak Dimiliki,Nilai=1)
Gelombang 2
*** Pohon yang Dikonversi:***
LogOp_Project COL:Expr1001
LogOp_Pilih
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableDapatkan (1) [kosong]
Daftar AncOp_Prj
AncOp_PrjEl COL:Ekspr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Ekspr1000
ScaOp_Identifier COL:Ekspr1000
Daftar AncOp_Prj
AncOp_PrjEl COL:Ekspr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Tidak Dimiliki,Nilai=1)
Gelombang 3
*** Pohon yang Dikonversi:***
LogOp_Project COL:Expr1004
LogOp_Pilih
LogOp_ConstTableDapatkan (1) [kosong]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableDapatkan (1) [kosong]
Daftar AncOp_Prj
AncOp_PrjEl COL:Ekspr1000
ScaOp_Intrinsic sysdatetime
Daftar AncOp_Prj
AncOp_PrjEl COL:Ekspr1001
ScaOp_Identifier COL:Ekspr1000
ScaOp_Subquery COL:Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableDapatkan (1) [kosong]
Daftar AncOp_Prj
AncOp_PrjEl COL:Ekspr1002
ScaOp_Intrinsic sysdatetime
Daftar AncOp_Prj
AncOp_PrjEl COL:Ekspr1003
ScaOp_Identifier COL:Expr1002
Daftar AncOp_Prj
AncOp_PrjEl COL:Ekspr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Tidak Dimiliki,Nilai=1)
Di Batch 1, Anda dapat melihat perbandingan antara hasil dua evaluasi terpisah dari fungsi intrinsik SYSDATETIME.
Di Batch 2, Anda melihat satu evaluasi fungsi yang menghasilkan kolom bernama Expr1000, lalu perbandingan antara kolom ini dan dirinya sendiri.
Di Batch 3, Anda melihat dua evaluasi fungsi yang terpisah. Satu di kolom yang disebut Expr1000 (kemudian diproyeksikan oleh kolom subquery yang disebut Expr1001). Lain di kolom yang disebut Expr1002 (kemudian diproyeksikan oleh kolom subquery yang disebut Expr1003). Anda kemudian memiliki perbandingan antara Expr1001 dan Expr1003.
Jadi, dengan sedikit lebih menggali di luar apa yang ditampilkan oleh rencana eksekusi grafis, Anda benar-benar dapat mengetahui kapan ekspresi yang mendasari dievaluasi hanya sekali versus beberapa kali. Sekarang setelah Anda memahami kasus yang berbeda, Anda dapat mengembangkan solusi berdasarkan perilaku yang diinginkan yang Anda cari.
Fungsi jendela dengan urutan nondeterministik
Ada kelas komputasi lain yang dapat membuat Anda mendapat masalah saat digunakan dalam solusi dengan banyak referensi ke CTE yang sama. Itu adalah fungsi jendela yang mengandalkan pemesanan nondeterministik. Ambil fungsi jendela ROW_NUMBER sebagai contoh. Saat digunakan dengan pemesanan sebagian (diurutkan berdasarkan elemen yang tidak mengidentifikasi baris secara unik), setiap evaluasi kueri yang mendasarinya dapat menghasilkan penetapan nomor baris yang berbeda meskipun data yang mendasarinya tidak berubah. Dengan beberapa referensi CTE, ingatlah bahwa masing-masing tidak bersarang secara terpisah, dan Anda bisa mendapatkan kumpulan hasil yang berbeda. Bergantung pada apa yang dilakukan kueri luar dengan setiap referensi, mis. kolom mana dari setiap referensi yang berinteraksi dengannya dan bagaimana, pengoptimal dapat memutuskan untuk mengakses data untuk setiap instance menggunakan indeks yang berbeda dengan persyaratan pemesanan yang berbeda.
Perhatikan kode berikut sebagai contoh:
GUNAKAN TSQLV5; DENGAN C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER GABUNG C AS C2 PADA C1.rownum =C2. rownumWHERE C1.orderid <> C2.orderid;
Bisakah kueri ini mengembalikan kumpulan hasil yang tidak kosong? Mungkin reaksi awal Anda adalah tidak bisa. Tetapi pikirkan tentang apa yang baru saja saya jelaskan sedikit lebih hati-hati dan Anda akan menyadari bahwa, setidaknya secara teori, karena dua proses pemisahan CTE terpisah yang akan berlangsung di sini—satu dari C1 dan satu lagi dari C2—adalah mungkin. Namun, adalah satu hal untuk berteori bahwa sesuatu dapat terjadi, dan hal lain untuk menunjukkannya. Misalnya, ketika saya menjalankan kode ini tanpa membuat indeks baru, saya terus mendapatkan kumpulan hasil kosong:
orderid shipcountry orderid----------- --------------- -----------(0 baris terpengaruh)Saya mendapatkan rencana yang ditunjukkan pada Gambar 23 untuk kueri ini.
Gambar 2:Rencana pertama untuk kueri dengan dua referensi CTE
Yang menarik untuk dicatat di sini adalah bahwa pengoptimal memang memilih untuk menggunakan indeks yang berbeda untuk menangani referensi CTE yang berbeda karena itulah yang dianggap optimal. Bagaimanapun, setiap referensi dalam kueri luar berkaitan dengan subset kolom CTE yang berbeda. Satu referensi menghasilkan pemindaian maju berurutan dari indeks idx_nc_orderedate, dan yang lainnya dalam pemindaian tidak berurutan dari indeks berkerumun diikuti oleh operasi pengurutan berdasarkan urutan tanggal naik. Meskipun indeks idx_nc_orderedate secara eksplisit didefinisikan hanya pada kolom orderdate sebagai kunci, dalam praktiknya itu didefinisikan pada (orderdate, orderid) sebagai kuncinya karena orderid adalah kunci indeks berkerumun, dan disertakan sebagai kunci terakhir di semua indeks nonclustered. Jadi pemindaian indeks yang dipesan sebenarnya memancarkan baris yang dipesan berdasarkan orderdate, orderid. Adapun pemindaian tidak berurutan dari indeks berkerumun, pada tingkat mesin penyimpanan, data dipindai dalam urutan kunci indeks (berdasarkan orderid) untuk mengatasi ekspektasi konsistensi minimal dari tingkat isolasi default yang dilakukan. Oleh karena itu, operator Sortir mencerna data yang diurutkan berdasarkan orderid, mengurutkan baris berdasarkan orderdate, dan dalam praktiknya akhirnya memancarkan baris yang diurutkan berdasarkan orderdate, orderid.
Sekali lagi, secara teori tidak ada jaminan bahwa kedua referensi akan selalu mewakili kumpulan hasil yang sama meskipun data dasarnya tidak berubah. Cara sederhana untuk mendemonstrasikan ini adalah dengan mengatur dua indeks optimal yang berbeda untuk dua referensi, tetapi memiliki satu mengurutkan data berdasarkan ASC orderdate, ASC orderid, dan yang lainnya mengurutkan data berdasarkan orderdate DESC, ASC orderid (atau justru sebaliknya). Kami sudah memiliki indeks sebelumnya. Berikut kode untuk membuat yang terakhir:
BUAT INDEX idx_nc_odD_oid_I_sc PADA Penjualan.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);Jalankan kode untuk kedua kalinya setelah membuat indeks:
DENGAN C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 PADA C1.rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Saya mendapatkan output berikut saat menjalankan kode ini setelah membuat indeks baru:
orderid shipcountry orderid----------- --------------- -----------10251 Prancis 1025010250 Brasil 1025110261 Brasil 1026010260 Jerman 1026110271 AS 10270...11070 Jerman 1107311077 AS 1107411076 Prancis 1107511075 Swiss 1107611074 Denmark 11077(546 baris terpengaruh)Ups.
Periksa rencana kueri untuk eksekusi ini seperti yang ditunjukkan pada Gambar 3:
Gambar 3:Rencana kedua untuk kueri dengan dua referensi CTE
Perhatikan bahwa cabang teratas dari rencana memindai indeks idx_nc_orderdate secara berurutan, menyebabkan operator Proyek Urutan yang menghitung nomor baris untuk menyerap data dalam praktik yang diurutkan berdasarkan ASC tanggal pesanan, ASC urutan. Cabang bawah dari rencana memindai indeks baru idx_nc_odD_oid_I_sc dengan urutan mundur, menyebabkan operator Proyek Urutan menyerap data dalam praktik yang diurutkan berdasarkan ASC tanggal pesanan, DESC pesanan. Ini menghasilkan susunan nomor baris yang berbeda untuk dua referensi CTE setiap kali ada lebih dari satu kemunculan nilai tanggal pemesanan yang sama. Akibatnya, kueri menghasilkan kumpulan hasil yang tidak kosong.
Jika Anda ingin menghindari bug seperti itu, satu opsi yang jelas adalah mempertahankan hasil kueri dalam di objek sementara seperti tabel sementara atau variabel tabel. Namun, jika Anda memiliki situasi di mana Anda lebih suka tetap menggunakan CTE, solusi sederhana adalah menggunakan pesanan total dalam fungsi jendela dengan menambahkan tiebreaker. Dengan kata lain, pastikan Anda memesan dengan kombinasi ekspresi yang secara unik mengidentifikasi baris. Dalam kasus kami, Anda cukup menambahkan orderid secara eksplisit sebagai tiebreaker, seperti:
DENGAN C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER GABUNG C SEBAGAI C2 PADA C1 .rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Anda mendapatkan set hasil kosong seperti yang diharapkan:
orderid shipcountry orderid----------- --------------- -----------(0 baris terpengaruh)Tanpa menambahkan indeks lebih lanjut, Anda mendapatkan rencana yang ditunjukkan pada Gambar 4:
Gambar 4:Paket ketiga untuk kueri dengan dua referensi CTE
Cabang atas dari denah sama dengan denah sebelumnya yang ditunjukkan pada Gambar 3. Cabang bawah sedikit berbeda. Indeks baru yang dibuat sebelumnya tidak terlalu ideal untuk kueri baru karena tidak memiliki data yang diurutkan seperti yang dibutuhkan fungsi ROW_NUMBER (tanggal pemesanan, id pesanan). Ini masih merupakan indeks penutup tersempit yang dapat ditemukan pengoptimal untuk referensi CTE masing-masing, jadi ini yang dipilih; namun, itu dipindai dengan cara Memerintahkan:Salah. Operator Sortir eksplisit kemudian mengurutkan data berdasarkan orderdate, orderid seperti kebutuhan komputasi ROW_NUMBER. Tentu saja, Anda dapat mengubah definisi indeks agar orderdate dan orderid menggunakan arah yang sama dan dengan cara ini penyortiran eksplisit akan dihilangkan dari rencana. Poin utamanya adalah bahwa dengan menggunakan pemesanan total, Anda terhindar dari masalah karena bug khusus ini.
Setelah selesai, jalankan kode berikut untuk pembersihan:
JAUHKAN INDEKS JIKA ADA idx_nc_odD_oid_I_sc PADA Penjualan.Pesanan;Kesimpulan
Penting untuk dipahami bahwa banyak referensi ke CTE yang sama dari kueri luar menghasilkan evaluasi terpisah dari kueri dalam CTE. Berhati-hatilah dengan perhitungan nondeterministik, karena evaluasi yang berbeda dapat menghasilkan nilai yang berbeda.
Saat menggunakan fungsi jendela seperti ROW_NUMBER dan menggabungkan dengan bingkai, pastikan untuk menggunakan urutan total untuk menghindari mendapatkan hasil yang berbeda untuk baris yang sama dalam referensi CTE yang berbeda.