Kualitas rencana eksekusi sangat tergantung pada keakuratan perkiraan jumlah baris yang dihasilkan oleh setiap operator rencana. Jika perkiraan jumlah baris menyimpang secara signifikan dari jumlah baris sebenarnya, hal ini dapat berdampak signifikan pada kualitas rencana eksekusi kueri. Kualitas paket yang buruk dapat menyebabkan I/O yang berlebihan, CPU yang meningkat, tekanan memori, penurunan throughput, dan pengurangan keseluruhan konkurensi.
Dengan "kualitas rencana" - Saya sedang berbicara tentang membuat SQL Server menghasilkan rencana eksekusi yang menghasilkan pilihan operator fisik yang mencerminkan keadaan data saat ini. Dengan membuat keputusan seperti itu berdasarkan data yang akurat, ada kemungkinan lebih baik bahwa kueri akan tampil dengan benar. Nilai perkiraan kardinalitas digunakan sebagai masukan untuk biaya operator, dan ketika nilai terlalu jauh dari kenyataan, dampak negatif terhadap rencana pelaksanaan dapat diucapkan. Estimasi ini diumpankan ke berbagai model biaya yang terkait dengan kueri itu sendiri, dan estimasi baris yang buruk dapat memengaruhi berbagai keputusan termasuk pemilihan indeks, operasi pencarian vs pemindaian, eksekusi paralel vs serial, pemilihan algoritma gabung, gabungan fisik dalam vs luar. pemilihan (mis. build vs. probe), pembuatan spool, pencarian bookmark vs. akses tabel cluster atau heap penuh, pemilihan agregat aliran atau hash, dan apakah modifikasi data menggunakan rencana lebar atau sempit.
Sebagai contoh, katakanlah Anda memiliki SELECT berikut ini kueri (menggunakan basis data Kredit):
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
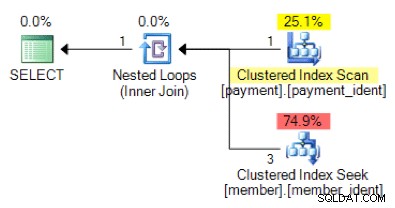
Berdasarkan logika kueri, apakah rencana berikut membentuk apa yang Anda harapkan?
Dan bagaimana dengan rencana alternatif ini, di mana alih-alih loop bersarang kita memiliki kecocokan hash?
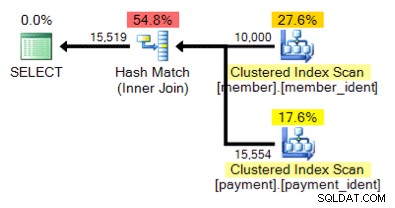
Jawaban "benar" bergantung pada beberapa faktor lain – tetapi salah satu faktor utama adalah jumlah baris di setiap tabel. Dalam beberapa kasus, satu algoritme gabungan fisik lebih sesuai daripada yang lain – dan jika asumsi perkiraan kardinalitas awal tidak benar, kueri Anda mungkin menggunakan pendekatan yang tidak optimal.
Identifikasi masalah estimasi kardinalitas relatif mudah. Jika Anda memiliki rencana eksekusi aktual, Anda dapat membandingkan taksiran dengan nilai jumlah baris aktual untuk operator dan mencari kemiringan. SQL Sentry Plan Explorer menyederhanakan tugas ini dengan memungkinkan Anda melihat baris aktual versus perkiraan untuk semua operator dalam satu tab pohon rencana dibandingkan dengan mengarahkan kursor ke masing-masing operator dalam paket grafis:

Sekarang, kemiringan tidak selalu menghasilkan rencana berkualitas buruk, tetapi jika Anda mengalami masalah kinerja dengan kueri dan Anda melihat penyimpangan seperti itu dalam rencana, ini adalah satu area yang layak untuk diselidiki lebih lanjut.
Identifikasi masalah perkiraan kardinalitas relatif mudah, tetapi penyelesaiannya seringkali tidak. Ada sejumlah penyebab utama mengapa masalah perkiraan kardinalitas dapat terjadi, dan saya akan membahas sepuluh alasan yang lebih umum dalam posting ini.
Statistik Hilang atau Kedaluwarsa
Dari semua alasan masalah perkiraan kardinalitas, inilah yang harapkan untuk dilihat, karena sering kali paling mudah untuk diatasi. Dalam skenario ini, statistik Anda hilang atau kedaluwarsa. Anda mungkin menonaktifkan opsi basis data untuk pembuatan dan pembaruan statistik otomatis, "tidak ada penghitungan ulang" yang diaktifkan untuk statistik tertentu, atau memiliki tabel yang cukup besar sehingga pembaruan statistik otomatis Anda tidak cukup sering terjadi.
Masalah Pengambilan Sampel
Mungkin presisi histogram statistik tidak memadai – misalnya, jika Anda memiliki tabel yang sangat besar dengan kemiringan data yang signifikan dan/atau sering. Anda mungkin perlu mengubah pengambilan sampel dari default atau jika itu tidak membantu – selidiki menggunakan tabel terpisah, statistik yang difilter, atau indeks yang difilter.
Korelasi Kolom Tersembunyi
Pengoptimal kueri mengasumsikan bahwa kolom dalam tabel yang sama adalah independen. Misalnya, jika Anda memiliki kolom kota dan negara bagian, kami mungkin secara intuitif mengetahui bahwa kedua kolom ini berkorelasi, tetapi SQL Server tidak memahami hal ini kecuali kami membantunya dengan indeks multi-kolom terkait, atau dengan multi-kolom yang dibuat secara manual. statistik kolom. Tanpa membantu pengoptimal dengan korelasi, selektivitas predikat Anda mungkin dilebih-lebihkan.
Di bawah ini adalah contoh dua predikat yang berkorelasi:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Saya kebetulan tahu bahwa 10% dari 10.000 baris member tabel memenuhi syarat untuk kombinasi ini, tetapi pengoptimal kueri menebak bahwa itu adalah 1% dari 10.000 baris:
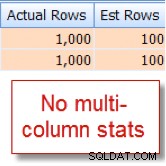
Sekarang bandingkan ini dengan perkiraan yang sesuai yang saya lihat setelah menambahkan statistik multi-kolom:
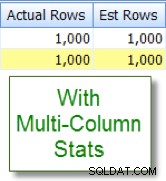
Perbandingan Kolom Intra-Tabel
Masalah estimasi kardinalitas dapat terjadi saat membandingkan kolom dalam tabel yang sama. Ini adalah masalah yang diketahui. Jika Anda harus melakukannya, Anda dapat meningkatkan perkiraan kardinalitas dari perbandingan kolom dengan menggunakan kolom yang dihitung sebagai gantinya atau dengan menulis ulang kueri untuk menggunakan self-join atau ekspresi tabel umum.
Penggunaan Variabel Tabel
Menggunakan variabel tabel banyak? Variabel tabel menunjukkan perkiraan kardinalitas "1" – yang untuk sejumlah kecil baris mungkin tidak menjadi masalah, tetapi untuk kumpulan hasil yang besar atau tidak stabil dapat memengaruhi kualitas rencana kueri secara signifikan. Di bawah ini adalah tangkapan layar perkiraan operator 1 baris versus 1.600.000 baris sebenarnya dari @charge variabel tabel:

Jika ini adalah penyebab utama Anda, sebaiknya Anda mencari alternatif seperti tabel sementara dan atau tabel pementasan permanen jika memungkinkan.
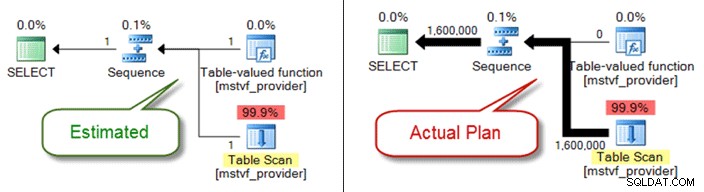
UDF Skalar dan MSTV
Mirip dengan variabel tabel, nilai tabel multi-pernyataan dan fungsi skalar adalah kotak hitam dari perspektif estimasi kardinalitas. Jika Anda mengalami masalah kualitas rencana karena hal tersebut, pertimbangkan fungsi tabel sebaris sebagai alternatif – atau bahkan mencabut referensi fungsi seluruhnya dan hanya mereferensikan objek secara langsung.
Di bawah ini menunjukkan perkiraan versus rencana aktual saat menggunakan fungsi bernilai tabel multi-pernyataan:
Masalah Jenis Data
Masalah tipe data implisit dalam hubungannya dengan kondisi pencarian dan penggabungan dapat menyebabkan masalah perkiraan kardinalitas. Mereka juga dapat secara diam-diam menggerogoti sumber daya tingkat server (CPU, I/O, memori), jadi penting untuk mengatasinya bila memungkinkan.
Predikat Kompleks
Anda mungkin pernah melihat pola ini sebelumnya – kueri dengan WHERE klausa yang memiliki setiap referensi kolom tabel yang dibungkus dengan berbagai fungsi, operasi penggabungan, operasi matematika, dan lainnya. Dan meskipun tidak semua pembungkusan fungsi menghalangi perkiraan kardinalitas yang tepat (seperti untuk LOWER , UPPER dan GETDATE ) ada banyak cara untuk menyembunyikan predikat Anda hingga pengoptimal kueri tidak dapat lagi membuat perkiraan yang akurat.
Kompleksitas Kueri
Mirip dengan predikat terkubur, apakah pertanyaan Anda sangat kompleks? Saya menyadari "kompleks" adalah istilah subjektif, dan penilaian Anda mungkin berbeda, tetapi sebagian besar dapat setuju bahwa tampilan bersarang dalam tampilan dalam tampilan bahwa referensi tabel yang tumpang tindih cenderung tidak optimal – terutama jika digabungkan dengan 10+ tabel gabungan, referensi fungsi dan predikat terkubur. Meskipun pengoptimal kueri melakukan pekerjaan yang mengagumkan, ini bukanlah keajaiban, dan jika Anda memiliki kemiringan yang signifikan, kompleksitas kueri (kueri pisau tentara Swiss) pasti dapat membuat hampir mustahil untuk mendapatkan taksiran baris yang akurat untuk operator.
Kueri Terdistribusi
Apakah Anda menggunakan kueri terdistribusi dengan server tertaut dan Anda melihat masalah perkiraan kardinalitas yang signifikan? Jika demikian, pastikan untuk memeriksa izin yang terkait dengan prinsip server tertaut yang digunakan untuk mengakses data. Tanpa db_ddladmin minimum memperbaiki peran basis data untuk akun server tertaut, kurangnya visibilitas ke statistik jarak jauh karena izin yang tidak memadai dapat menjadi sumber masalah estimasi kardinalitas Anda.
Dan masih banyak lagi…
Ada alasan lain mengapa perkiraan kardinalitas dapat miring, tetapi saya yakin saya telah membahas yang paling umum. Poin kuncinya adalah memperhatikan kemiringan yang terkait dengan kueri yang dikenal dan berkinerja buruk. Jangan berasumsi bahwa rencana dibuat berdasarkan kondisi penghitungan baris yang akurat. Jika angka-angka ini miring, Anda harus mencoba memecahkan masalah ini terlebih dahulu.