Kebutuhan paling umum untuk menghapus waktu dari nilai datetime adalah untuk mendapatkan semua baris yang mewakili pesanan (atau kunjungan, atau kecelakaan) yang terjadi pada hari tertentu. Namun, tidak semua teknik yang digunakan untuk melakukannya efisien atau bahkan aman.
TL;DR versi
Jika Anda menginginkan kueri rentang aman yang berkinerja baik, gunakan rentang terbuka atau, untuk kueri satu hari di SQL Server 2008 dan yang lebih baru, gunakan CONVERT(DATE) :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Beberapa peringatan:
- Hati-hati dengan
DATEDIFFpendekatan, karena ada beberapa anomali estimasi kardinalitas yang dapat terjadi (lihat posting blog ini dan pertanyaan Stack Overflow yang mendorongnya untuk informasi lebih lanjut). - Meskipun yang terakhir masih berpotensi menggunakan pencarian indeks (tidak seperti setiap ekspresi non-sargable lainnya yang pernah saya temui), Anda harus berhati-hati dalam mengonversi kolom menjadi tanggal sebelum membandingkan. Pendekatan ini juga dapat menghasilkan estimasi kardinalitas yang salah secara fundamental. Lihat jawaban ini oleh Martin Smith untuk detail lebih lanjut.
Bagaimanapun, baca terus untuk memahami mengapa ini adalah satu-satunya dua pendekatan yang saya rekomendasikan.
Tidak semua pendekatan aman
Sebagai contoh yang tidak aman, saya melihat yang ini banyak digunakan:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Ada beberapa masalah dengan pendekatan ini, tetapi yang paling menonjol adalah perhitungan "akhir" hari ini – jika tipe data dasarnya adalah SMALLDATETIME , rentang akhir itu akan dibulatkan; jika DATETIME2 , Anda secara teoritis bisa kehilangan data di penghujung hari. Jika Anda memilih menit atau nanodetik atau celah lain untuk mengakomodasi tipe data saat ini, kueri Anda akan mulai memiliki perilaku aneh jika tipe data berubah nanti (dan jujur saja, jika seseorang mengubah tipe kolom itu menjadi lebih atau kurang granular, mereka tidak berlarian memeriksa setiap kueri yang mengaksesnya). Harus membuat kode dengan cara ini tergantung pada jenis data tanggal/waktu di kolom yang mendasarinya terfragmentasi dan rawan kesalahan. Jauh lebih baik menggunakan rentang tanggal terbuka untuk ini:
Saya berbicara lebih banyak tentang ini di beberapa posting blog lama:
- Apa kesamaan ANTARA dan iblis?
- Kebiasaan Buruk untuk Ditendang :salah menangani kueri tanggal/rentang
Tetapi saya ingin membandingkan kinerja beberapa pendekatan yang lebih umum yang saya lihat di luar sana. Saya selalu menggunakan rentang terbuka, dan sejak SQL Server 2008 kami dapat menggunakan CONVERT(DATE) dan masih menggunakan indeks pada kolom itu, yang cukup kuat.
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Uji Kinerja Sederhana
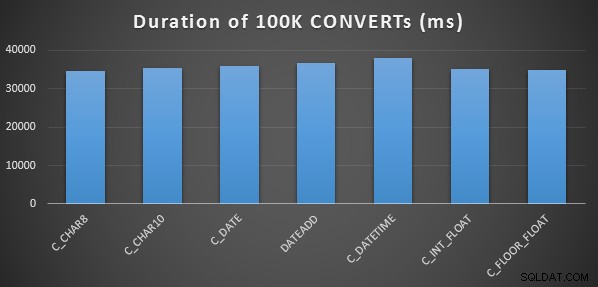
Untuk melakukan tes kinerja awal yang sangat sederhana, saya melakukan hal berikut untuk setiap pernyataan di atas, menyetel variabel ke output perhitungan 100.000 kali:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
Saya melakukan ini tiga kali untuk setiap metode, dan semuanya berjalan dalam kisaran 34-38 detik. Jadi sebenarnya, ada perbedaan yang sangat kecil dalam metode ini saat melakukan operasi di memori:
Uji Kinerja yang Lebih Rumit
Saya juga ingin membandingkan metode ini dengan tipe data yang berbeda (DATETIME , SMALLDATETIME , dan DATETIME2 ), terhadap indeks berkerumun dan tumpukan, dan dengan dan tanpa kompresi data. Jadi pertama saya membuat database sederhana. Melalui eksperimen, saya menentukan bahwa ukuran optimal untuk menangani 120 juta baris dan semua aktivitas log yang mungkin terjadi (dan untuk mencegah peristiwa pertumbuhan otomatis mengganggu pengujian) adalah file data 20 GB dan log 3 GB:
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
Selanjutnya, saya membuat 12 tabel:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Lalu ulangi lagi untuk DATETIME dan DATETIME2.]
Selanjutnya, saya memasukkan 10.000.000 baris ke setiap tabel. Saya melakukan ini dengan membuat tampilan yang akan menghasilkan 10.000.000 tanggal yang sama setiap kali:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
Ini memungkinkan saya untuk mengisi tabel dengan cara ini:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Kemudian ulangi lagi untuk tumpukan dan indeks berkerumun yang tidak terkompresi. Saya memberikan CHECKPOINT antara setiap sisipan untuk memastikan penggunaan kembali log (model pemulihan sederhana).]
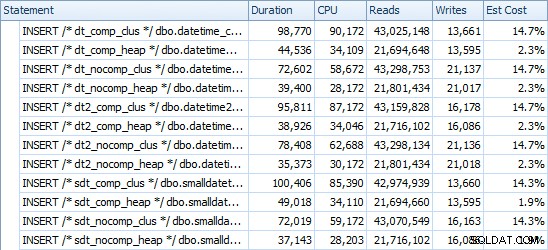
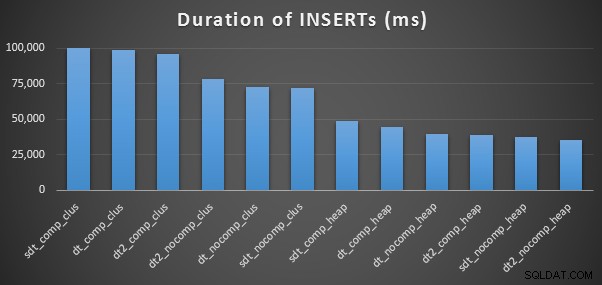
MASUKKAN Waktu &Ruang yang Digunakan
Berikut adalah pengaturan waktu untuk setiap sisipan (seperti yang diambil dengan Plan Explorer):
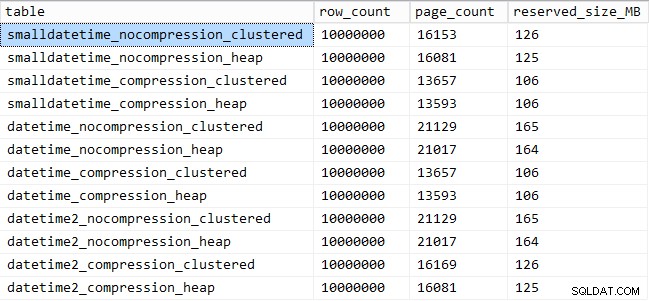
Dan berikut adalah jumlah ruang yang ditempati oleh setiap tabel:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
Kinerja Pola Kueri
Selanjutnya saya mulai menguji dua pola kueri yang berbeda untuk kinerja:
- Menghitung baris untuk hari tertentu, menggunakan tujuh pendekatan di atas, serta rentang tanggal terbuka
- Mengonversi semua 10.000.000 baris menggunakan tujuh pendekatan di atas, serta hanya mengembalikan data mentah (karena memformat di sisi klien mungkin lebih baik)
[Dengan pengecualian FLOAT metode dan DATETIME2 kolom, karena konversi ini tidak sah.]
Untuk pertanyaan pertama, kueri terlihat seperti ini (diulang untuk setiap jenis tabel):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; Hasil terhadap indeks berkerumun terlihat seperti ini (klik untuk memperbesar):
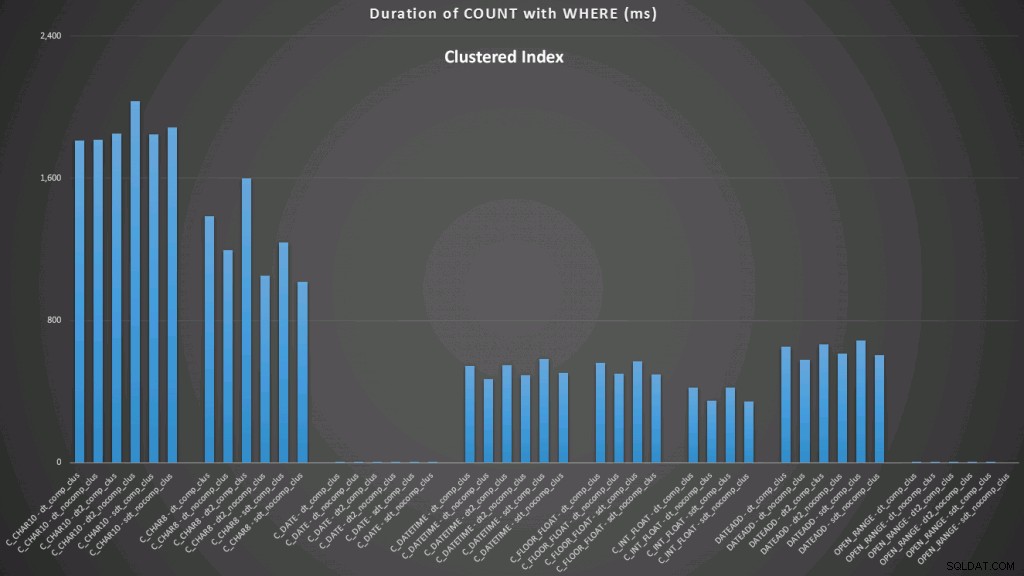
Di sini kita melihat bahwa konversi hingga saat ini dan rentang terbuka menggunakan indeks adalah yang berkinerja terbaik. Namun, dengan banyak kendala, konversi ke tanggal sebenarnya membutuhkan waktu, menjadikan rentang terbuka sebagai pilihan optimal (klik untuk memperbesar):
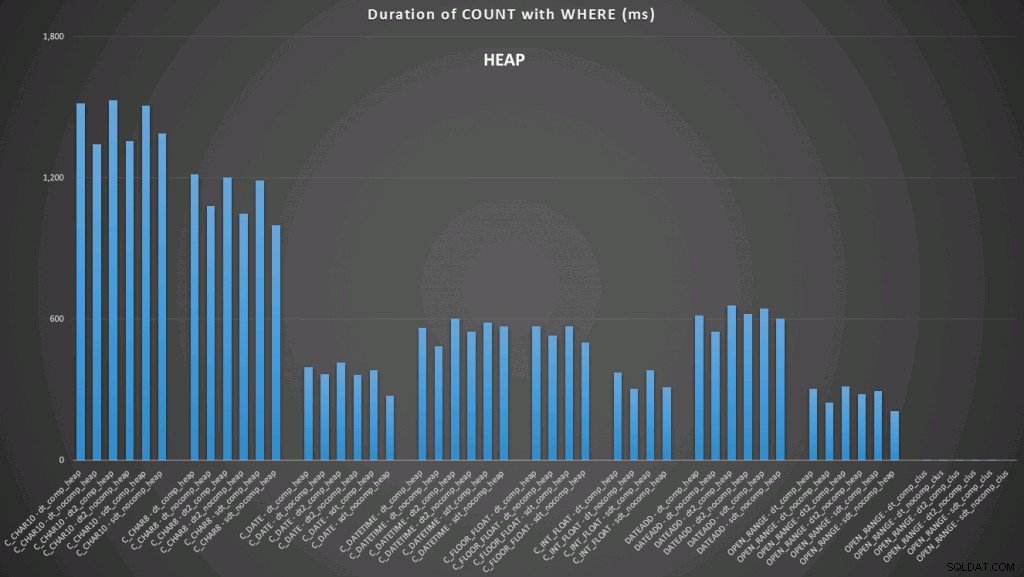
Dan inilah kumpulan kueri kedua (sekali lagi, berulang untuk setiap jenis tabel):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; Berfokus pada hasil untuk tabel dengan indeks berkerumun, jelas bahwa konversi ke tanggal adalah kinerja yang sangat dekat dengan hanya memilih data mentah (klik untuk memperbesar):
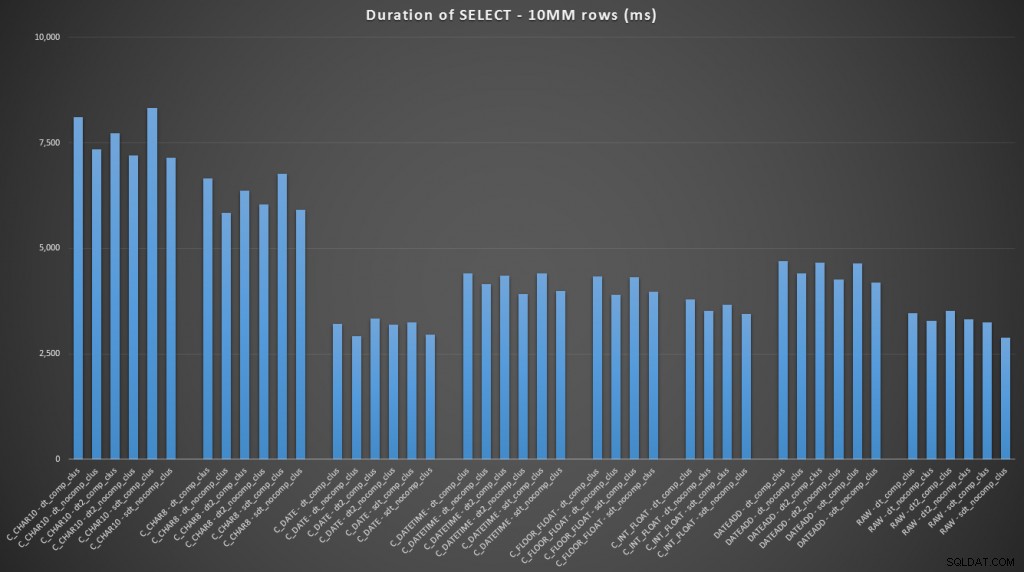
(Untuk kumpulan kueri ini, heap menunjukkan hasil yang sangat mirip – hampir tidak dapat dibedakan.)
Kesimpulan
Jika Anda ingin melompat ke bagian lucunya, hasil ini menunjukkan bahwa konversi dalam memori tidak penting, tetapi jika Anda mengonversi data saat keluar dari tabel (atau sebagai bagian dari predikat pencarian), metode yang Anda pilih dapat memiliki dampak dramatis pada kinerja. Mengonversi ke DATE (untuk satu hari) atau menggunakan rentang tanggal terbuka dalam hal apa pun akan menghasilkan kinerja terbaik, sedangkan metode paling populer di luar sana – mengonversi ke string – benar-benar buruk.
Kami juga melihat bahwa kompresi dapat memiliki efek yang layak pada ruang penyimpanan, dengan dampak yang sangat kecil pada kinerja kueri. Efek pada kinerja penyisipan tampaknya bergantung pada apakah tabel memiliki indeks berkerumun atau tidak daripada apakah kompresi diaktifkan atau tidak. Namun, dengan indeks berkerumun di tempat, ada perbedaan nyata dalam durasi yang dibutuhkan untuk memasukkan 10 juta baris. Sesuatu yang perlu diingat dan diseimbangkan dengan penghematan ruang disk.
Jelas mungkin ada lebih banyak pengujian yang terlibat, dengan beban kerja yang lebih substansial dan bervariasi, yang dapat saya jelajahi lebih lanjut di postingan mendatang.