Dengan diperkenalkannya Azure SQL Database dan penambahan lebih banyak fungsionalitas di v12, administrator database mulai melihat organisasi mereka lebih tertarik untuk memindahkan database ke platform ini.
Baru-baru ini saya mulai lebih mendalami Azure SQL Database untuk melihat apa yang secara drastis berbeda dari mendukung versi kotak di pusat data di seluruh dunia dan Azure SQL Database. Dalam artikel saya sebelumnya, "Menala:Tempat yang Baik untuk Memulai," saya membahas pendekatan saya untuk memulai dengan menyetel SQL Server. Saya memutuskan untuk meninjau ini terhadap Azure SQL Database untuk menemukan perbedaan utama.
Dalam artikel asli saya, saya mulai dengan pengaturan tingkat instance umum yang saya lihat diabaikan atau dibiarkan sebagai default, serta item pemeliharaan. Ini termasuk memori, maxdop, ambang biaya untuk paralelisme, mengaktifkan pengoptimalan untuk beban kerja ad hoc, dan mengonfigurasi tempdb. Dengan Azure SQL Database, Anda tidak bertanggung jawab atas instans, dan tidak dapat mengubah pengaturan tersebut. Azure SQL Database adalah Platform as a Service (PaaS), artinya Microsoft mengelola instans untuk Anda; Anda hanyalah penyewa dengan database atau database Anda.
Namun, Anda bertanggung jawab untuk pemeliharaan, jadi Anda harus memperbarui statistik dan menangani fragmentasi indeks seperti yang Anda lakukan untuk produk kotak. Untuk tugas tersebut, saya menemukan bahwa sebagian besar klien mengelola proses tersebut dengan Azure VM khusus yang menjalankan SQL Server dan menggunakan SQL Server Agent dengan tugas terjadwal.
Mengikuti langkah-langkah dari artikel saya, area berikutnya yang saya mulai cari adalah statistik file dan tunggu dan kueri berbiaya tinggi. Jika Anda bertanya-tanya apakah aspek pekerjaan Anda sebagai dba produksi dengan database lokal akan berubah saat bekerja dengan Azure SQL Database, jawabannya adalah tidak juga . Statistik file dan menunggu masih ada, tetapi kita harus mendapatkannya dengan cara yang sedikit berbeda. Jika Anda terbiasa menggunakan skrip Paul Randal untuk statistik file dan statistik tunggu (atau kueri untuk statistik file untuk jangka waktu tertentu dan statistik tunggu untuk jangka waktu tertentu), maka Anda harus membuat beberapa perubahan agar skrip tersebut untuk bekerja dengan Azure SQL Database.
Ketika saya pertama kali mencoba skrip statistik file Paul, itu gagal karena Database Azure SQL tidak mendukung sys.master_files :
Nama objek tidak valid 'sys.master_files'.
Saya dapat memodifikasi skrip untuk menggunakan sys.databases di gabung untuk mendapatkan nama database dan hapus bagian skrip untuk mendapatkan nama file individual karena kita hanya akan berurusan dengan satu data dan file log. Anda dapat melihat perubahan yang saya buat pada gambar berikut:
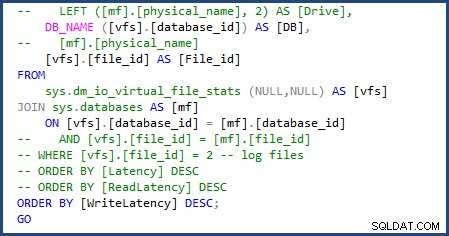
Ketika saya menjalankan skrip file-stats-over-a-period-of-time setelahnya, membuat perubahan yang sama ke sys.databases dan menghapus referensi ke file_id saat bergabung, gagal karena Azure SQL Database v12 tidak mendukung tabel ##temp global.
Setelah saya mengubah semua tabel ##temp global ke lokal, saya memiliki masalah lain dengan skrip yang tidak dapat menghapus tabel temp yang ada yang digunakan, karena tabel #temp lokal tidak dapat direferensikan secara langsung dengan nama seperti tabel ##temp global, tetapi ini mudah diatasi dengan mengubah pemeriksaan tersebut menjadi OBJECT_ID('tempdb..#SQLskillsStats1') . Saya membuat perubahan yang sama untuk tabel sementara kedua, dan memperbarui blok kode di awal dan akhir skrip.
Saya harus membuat satu perubahan lagi dan menghapus [mf].[type_desc] dan LEFT ([mf].[physical_name], 2) AS [Drive] karena itu bergantung pada sys.master_files . Skrip kemudian selesai dan siap digunakan dengan Azure SQL Database.
Saya menggunakan file-stats-over-a-period-of-time secara teratur ketika memecahkan masalah kinerja. Data kumulatif memiliki tujuannya, tetapi saya lebih tertarik pada segmen waktu tertentu saat beban kerja pengguna dijalankan.
Dengan statistik file, kami memperhatikan latensi kami per file database dan bagaimana kami dapat menyesuaikan untuk membantu mengurangi I/O secara keseluruhan. Pendekatannya sama dengan SQL Server, di mana Anda perlu menyetel kueri Anda dengan benar dan memiliki indeks yang benar. Jika beban kerja terlalu besar, maka Anda harus pindah ke tingkat basis data DTU yang berkinerja lebih cepat. Bagi saya, ini bagus:Anda hanya perlu membuang perangkat keras; tapi itu tidak benar-benar perangkat keras dalam arti tradisional. Dengan Azure SQL Database, Anda dapat memulai dengan tingkat dan skala yang lebih murah seiring pertumbuhan bisnis dan permintaan I/O Anda – pada dasarnya hanya dengan membalik tombol.
Mencoba menemukan metode terbaik untuk mendapatkan statistik tunggu lebih mudah. Skrip standar yang banyak dari kita gunakan masih berfungsi, namun menarik statistik tunggu untuk wadah tempat database Anda berjalan. Menunggu tersebut masih berlaku untuk sistem Anda, tetapi dapat mencakup menunggu yang dikeluarkan oleh database lain dalam wadah yang sama. Azure SQL Database berisi DMV baru, sys.dm_db_wait_stats , yang memfilter ke database saat ini. Jika Anda seperti saya dan terutama menggunakan skrip statistik menunggu Paul yang menghilangkan semua menunggu yang tidak berbahaya, cukup ubah sys.dm_os_wait_stats ke sys.dm_db_wait_stats . Perubahan yang sama juga berlaku untuk skrip wait-over-a-period-of-time, tetapi Anda juga harus membuat perubahan dari variabel global ke lokal.
Ketika datang untuk menemukan kueri berbiaya tinggi, salah satu skrip favorit saya untuk dijalankan menemukan rencana eksekusi yang paling sering digunakan. Dalam pengalaman saya, menyetel kueri yang dipanggil 100.000 kali per hari biasanya merupakan kemenangan yang lebih besar daripada menyetel kueri yang memiliki IO tertinggi tetapi hanya dijalankan sekali per minggu. Kueri berikut adalah yang saya gunakan untuk menemukan paket yang paling sering digunakan:
SELECT usecounts , cacheobjtype , objtype , [text]FROM sys.dm_exec_cached_plans LINTAS APPLY sys.dm_exec_sql_text(plan_handle)WHERE usecounts> 1 AND objtype IN ( N'Adhoc', N'Prepared use' )ORDER; pra>Saat menggunakan kueri ini dalam demo, saya selalu membersihkan cache paket saya untuk mengatur ulang nilainya. Ketika saya mencoba menjalankan
DBCC FREEPROCCACHEdi Azure SQL Database, saya diberi kesalahan berikut:Ternyata
SQL Azure saat ini tidak mendukung DBCC FREEPROCCACHE (Transact-SQL), jadi Anda tidak dapat menghapus rencana eksekusi secara manual dari cache. Namun, jika Anda membuat perubahan pada tabel atau tampilan yang dirujuk oleh kueri (ALTER TABLE dan ALTER VIEW) paket akan dihapus dari cache.DBCC FREEPROCCACHEtidak didukung di Azure SQL Database. Ini mengganggu saya, bagaimana jika saya dalam produksi dan memiliki beberapa rencana buruk dan ingin menghapus cache prosedur seperti yang saya bisa dengan versi kotak. Sedikit riset Google/Bing mengarahkan saya untuk menemukan artikel Microsoft, "Memahami Cache Prosedur pada SQL Azure," yang menyatakan:Saat mendiskusikan hal ini dengan Kimberly Tripp setelah tidak melihat perilaku yang dijelaskan, itu tidak menghapus paket dari cache, tetapi membatalkan paket (dan kemudian paket tersebut pada akhirnya akan dihapus dari cache). Meskipun ini membantu dalam situasi tertentu, ini bukan yang saya butuhkan. Untuk demo saya, saya ingin mengatur ulang penghitung di sys.dm_exec_cached_plans. Membuat rencana baru tidak akan memberi saya hasil yang diinginkan. Saya menghubungi tim saya dan Glenn Berry meminta saya untuk mencoba skrip berikut:
UBAH KONFIGURASI CAKUPAN DATABASE CLEAR PROCEDURE_CACHE;Perintah ini berhasil; Saya dapat menghapus cache prosedur untuk database tertentu. Konfigurasi Cakupan Database adalah fitur baru yang ditambahkan di SQL Server 2016 RC0; Glenn membuat blog tentangnya di sini:Menggunakan ALTER DATABASE SCOPED CONFIGURATION di SQL Server 2016.
Saya bersemangat untuk memindahkan beberapa database saya sendiri ke Azure SQL Database, dan untuk terus belajar tentang fitur baru dan opsi skalabilitas. Saya juga menantikan untuk bekerja dengan SentryOne DB Sentry, tambahan terbaru untuk Platform SentryOne. Saya paling tertarik untuk bereksperimen dengan dasbor Penggunaan DTU, yang dijelaskan Mike Wood dalam posting terbarunya.