Tahun lalu, saya memposting tip yang disebut Tingkatkan Efisiensi SQL Server dengan Beralih ke BUKAN Pemicu.
Alasan utama saya cenderung menyukai pemicu BUKAN, terutama dalam kasus di mana saya mengharapkan banyak pelanggaran logika bisnis, adalah bahwa tampaknya intuitif bahwa akan lebih murah untuk mencegah suatu tindakan sama sekali, daripada melanjutkan dan melakukannya (dan log it!), hanya untuk menggunakan pemicu SETELAH untuk menghapus baris yang menyinggung (atau memutar kembali seluruh operasi). Hasil yang ditunjukkan pada tip tersebut menunjukkan bahwa ini adalah kasusnya – dan saya menduga mereka akan lebih jelas dengan lebih banyak indeks non-cluster yang terpengaruh oleh operasi.
Namun, itu pada disk yang lambat, dan pada CTP awal SQL Server 2014. Dalam mempersiapkan slide untuk presentasi baru yang akan saya lakukan tahun ini pada pemicu, saya menemukan bahwa pada build SQL Server 2014 yang lebih baru – dikombinasikan dengan perangkat keras yang diperbarui – agak sulit untuk mendemonstrasikan delta yang sama dalam kinerja antara pemicu SETELAH dan BUKAN. Jadi saya mulai mencari tahu alasannya, meskipun saya langsung tahu ini akan menjadi lebih banyak pekerjaan daripada yang pernah saya lakukan untuk satu slide.
Satu hal yang ingin saya sebutkan adalah bahwa pemicu dapat menggunakan tempdb dengan cara yang berbeda, dan ini mungkin menjelaskan beberapa perbedaan ini. Pemicu SETELAH menggunakan penyimpanan versi untuk tabel semu yang dimasukkan dan dihapus, sementara pemicu BUKAN membuat salinan data ini di meja kerja internal. Perbedaannya tidak kentara, tetapi patut ditunjukkan.
Variabel
Saya akan menguji berbagai skenario, termasuk:
- Tiga pemicu berbeda:
- Pemicu AFTER yang menghapus baris tertentu yang gagal
- Pemicu AFTER yang mengembalikan seluruh transaksi jika ada baris yang gagal
- BUKAN pemicu yang hanya menyisipkan baris yang lewat
- Model pemulihan dan setelan isolasi snapshot yang berbeda:
- PENUH dengan SNAPSHOT diaktifkan
- PENUH dengan SNAPSHOT dinonaktifkan
- SEDERHANA dengan SNAPSHOT diaktifkan
- SEDERHANA dengan SNAPSHOT dinonaktifkan
- Tata letak disk yang berbeda*:
- Data di SSD, masuk ke HDD 7200 RPM
- Data di SSD, masuk ke SSD
- Data di HDD 7200 RPM, masuk ke SSD
- Data di HDD 7200 RPM, masuk ke HDD 7200 RPM
- Tingkat kegagalan yang berbeda:
- tingkat kegagalan 10%, 25%, dan 50% di seluruh:
- Insersi batch tunggal dengan 20.000 baris
- 10 kumpulan 2.000 baris
- 100 kumpulan 200 baris
- 1.000 kumpulan 20 baris
- 20.000 sisipan tunggal
*
tempdbadalah file data tunggal pada disk 7200 RPM yang lambat. Ini disengaja dan dimaksudkan untuk memperkuat kemacetan yang disebabkan oleh berbagai penggunaantempdb. Saya berencana untuk mengunjungi kembali tes ini di beberapa titik ketikatempdbmenggunakan SSD yang lebih cepat. - tingkat kegagalan 10%, 25%, dan 50% di seluruh:
Oke, TL;DR Sudah!
Jika Anda hanya ingin tahu hasilnya, lewati saja. Segala sesuatu di tengah hanyalah latar belakang dan penjelasan tentang bagaimana saya mengatur dan menjalankan tes. Saya tidak patah hati karena tidak semua orang akan tertarik pada semua hal kecil.
Skenario
Untuk rangkaian pengujian khusus ini, skenario kehidupan nyata adalah skenario di mana pengguna memilih nama layar, dan pemicu dirancang untuk menangkap kasus di mana nama yang dipilih melanggar beberapa aturan. Misalnya, tidak boleh ada variasi "ninny-muggins" (Anda tentu bisa menggunakan imajinasi Anda di sini).
Saya membuat tabel dengan 20.000 nama pengguna unik:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Kemudian saya membuat tabel yang akan menjadi sumber untuk "nama nakal" saya untuk diperiksa. Dalam hal ini hanya ninny-muggins-00001 melalui ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Saya membuat tabel ini dalam model database sehingga setiap kali saya membuat database, itu akan ada secara lokal, dan saya berencana untuk membuat banyak database untuk menguji matriks skenario yang tercantum di atas (daripada hanya mengubah pengaturan database, menghapus log, dll). Harap diperhatikan, jika Anda membuat objek dalam model untuk tujuan pengujian, pastikan Anda menghapus objek tersebut setelah selesai.
Selain itu, saya akan dengan sengaja mengabaikan pelanggaran utama dan penanganan kesalahan lainnya dari ini, membuat asumsi naif bahwa nama yang dipilih diperiksa keunikannya jauh sebelum penyisipan dicoba, tetapi dalam transaksi yang sama (seperti cek terhadap tabel nama nakal bisa saja dibuat terlebih dahulu).
Untuk mendukung ini, saya juga membuat tiga tabel berikut yang hampir identik di model , untuk tujuan isolasi pengujian:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
Dan tiga pemicu berikut, satu untuk setiap tabel:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Anda mungkin ingin mempertimbangkan penanganan tambahan untuk memberi tahu pengguna bahwa pilihan mereka dibatalkan atau diabaikan – tetapi ini juga diabaikan untuk kesederhanaan.
Pengaturan Pengujian
Saya membuat data sampel yang mewakili tiga tingkat kegagalan yang ingin saya uji, mengubah 10 persen menjadi 25 dan kemudian 50, dan menambahkan tabel ini juga ke model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Setiap tabel memiliki 20.000 baris, dengan campuran nama yang berbeda yang akan lulus dan gagal, dan kolom nomor baris memudahkan untuk membagi data menjadi ukuran batch yang berbeda untuk pengujian yang berbeda, tetapi dengan tingkat kegagalan berulang untuk semua pengujian.
Tentu kita membutuhkan tempat untuk mengabadikan hasil tersebut. Saya memilih untuk menggunakan database terpisah untuk ini, menjalankan setiap pengujian beberapa kali, hanya merekam durasi.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Saya mengisi dbo.Tests tabel dengan skrip berikut, sehingga saya dapat menjalankan bagian yang berbeda untuk menyiapkan empat database agar sesuai dengan parameter pengujian saat ini. Perhatikan bahwa D:\ adalah SSD, sedangkan G:\ adalah disk 7200 RPM:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Maka mudah untuk menjalankan semua tes beberapa kali:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
Di sistem saya ini membutuhkan waktu hampir 6 jam, jadi bersiaplah untuk membiarkan ini berjalan tanpa gangguan. Juga, pastikan Anda tidak memiliki koneksi aktif atau jendela kueri yang terbuka terhadap model database, jika tidak, Anda mungkin mendapatkan kesalahan ini saat skrip mencoba membuat database:
Tidak dapat memperoleh kunci eksklusif pada 'model' basis data. Coba lagi operasinya nanti.
Hasil
Ada banyak titik data untuk dilihat (dan semua kueri yang digunakan untuk memperoleh data dirujuk dalam Lampiran). Ingatlah bahwa setiap durasi rata-rata yang dilambangkan di sini adalah lebih dari 10 pengujian dan memasukkan total 100.000 baris ke dalam tabel tujuan.
Grafik 1 – Keseluruhan Agregat
Grafik pertama menunjukkan agregat keseluruhan (durasi rata-rata) untuk variabel yang berbeda secara terpisah (jadi *semua* pengujian menggunakan pemicu AFTER yang menghapus, *semua* pengujian menggunakan pemicu AFTER yang memutar kembali, dll).
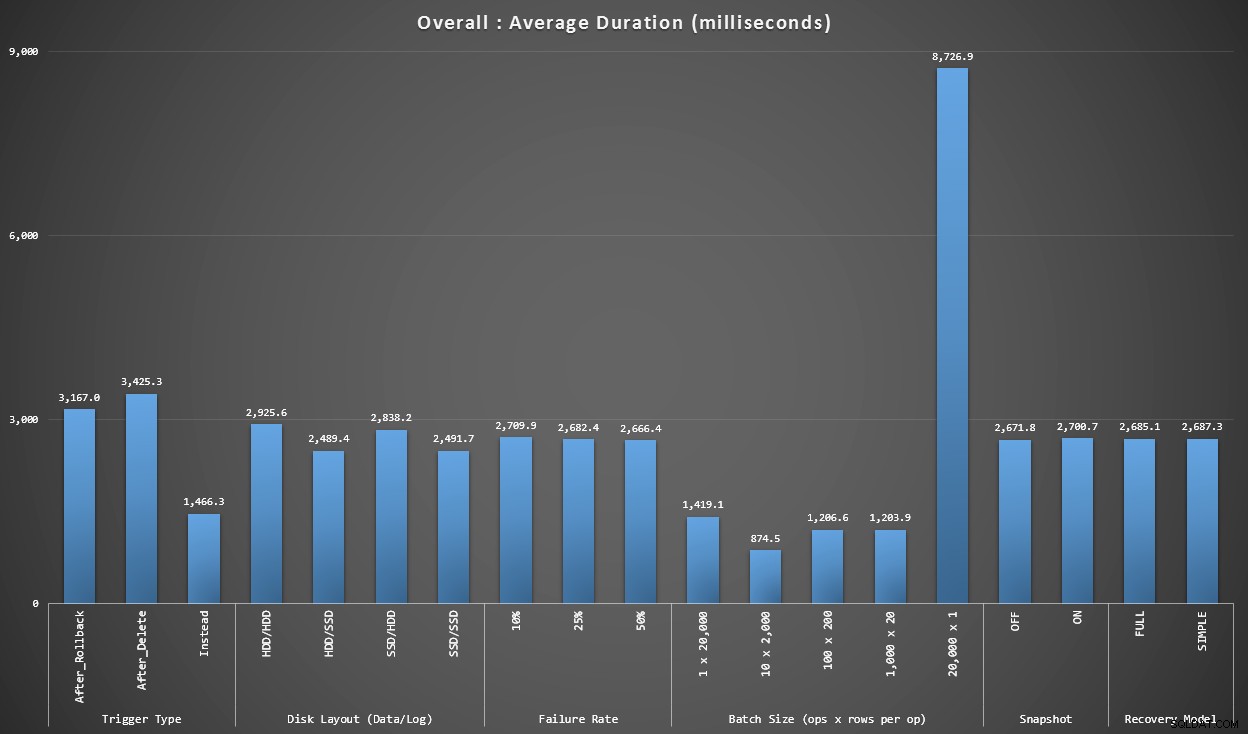
Durasi rata-rata, dalam milidetik, untuk setiap variabel dalam isolasi
Beberapa hal langsung muncul pada kami:
- BUKAN pemicu di sini dua kali lebih cepat dari kedua pemicu SETELAH.
- Memiliki log transaksi di SSD membuat sedikit perbedaan. Lokasi file data apalagi.
- Batch 20.000 insert tunggal 7-8x lebih lambat daripada distribusi batch lainnya.
- Insersi batch tunggal dari 20.000 baris lebih lambat daripada distribusi non-tunggal mana pun.
- Tingkat kegagalan, isolasi snapshot, dan model pemulihan hanya berdampak kecil pada performa.
Grafik 2 – 10 Terbaik Secara Keseluruhan
Grafik ini menunjukkan 10 hasil tercepat ketika setiap variabel dipertimbangkan. Ini semua BUKAN pemicu di mana persentase terbesar baris gagal (50%). Anehnya, yang tercepat (meskipun tidak banyak) memiliki data dan masuk ke HDD yang sama (bukan SSD). Ada campuran tata letak disk dan model pemulihan di sini, tetapi semua 10 memiliki isolasi snapshot yang diaktifkan, dan 7 hasil teratas semuanya melibatkan ukuran batch 10 x 2.000 baris.
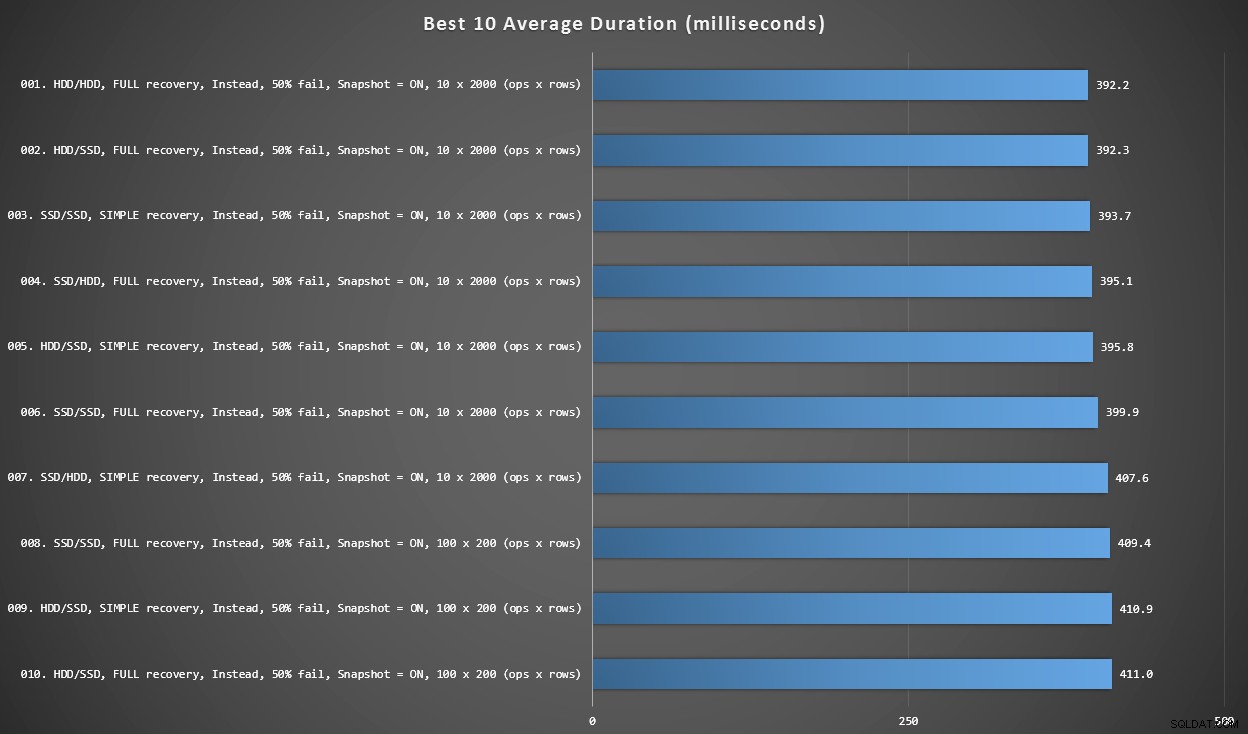
10 durasi terbaik, dalam milidetik, dengan mempertimbangkan setiap variabel
Pemicu AFTER tercepat – varian ROLLBACK dengan tingkat kegagalan 10% dalam ukuran batch baris 100 x 200 – berada di posisi #144 (806 md).
Grafik 3 – 10 Terburuk Secara Keseluruhan
Grafik ini menunjukkan 10 hasil paling lambat ketika setiap variabel dipertimbangkan; semua varian SETELAH, semua melibatkan 20.000 sisipan tunggal, dan semua memiliki data dan log pada HDD lambat yang sama.
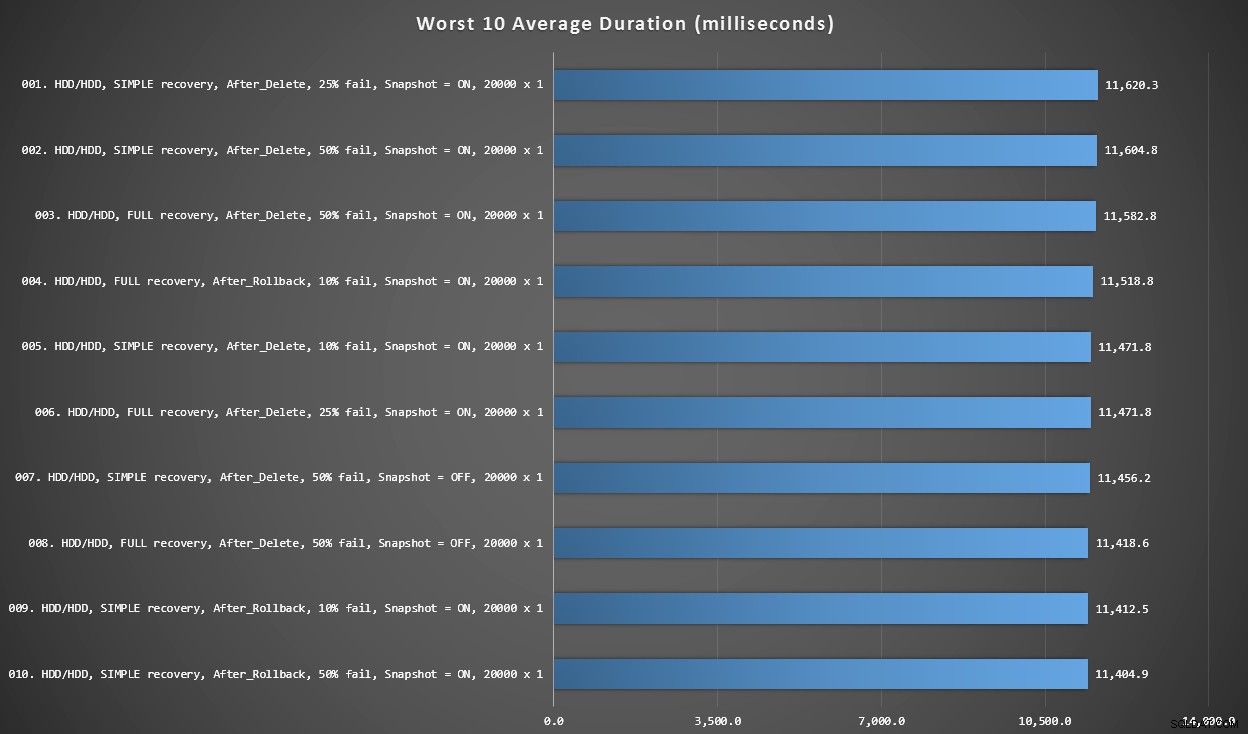
10 durasi terburuk, dalam milidetik, dengan mempertimbangkan setiap variabel
BUKAN pengujian paling lambat berada di posisi #97, pada 5.680 ms – pengujian insert tunggal 20.000 di mana 10% gagal. Menarik juga untuk mengamati bahwa tidak satu pun pemicu SETELAH menggunakan ukuran batch insert 20.000 singleton bernasib lebih baik – sebenarnya hasil terburuk ke-96 adalah tes SETELAH (hapus) yang datang pada 10.219 ms – hampir dua kali lipat hasil paling lambat berikutnya.
Grafik 4 – Jenis Disk Log, Sisipan Tunggal
Grafik di atas memberi kita gambaran kasar tentang masalah terbesar, tetapi grafik tersebut terlalu diperbesar atau tidak cukup diperbesar. Grafik ini menyaring data berdasarkan kenyataan:dalam kebanyakan kasus, jenis operasi ini akan menjadi penyisipan tunggal. Saya pikir saya akan membaginya berdasarkan tingkat kegagalan dan jenis disk tempat log digunakan, tetapi hanya melihat baris di mana kumpulan terdiri dari 20.000 sisipan individu.
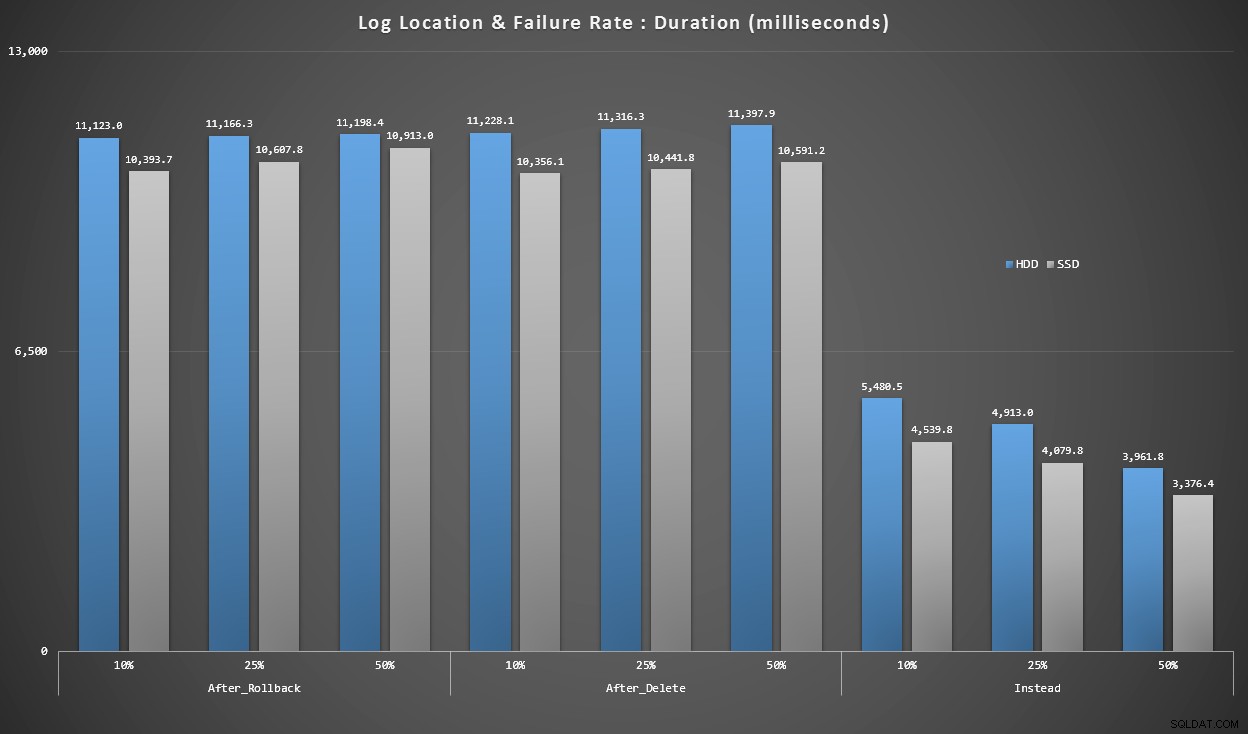
Durasi, dalam milidetik, dikelompokkan menurut tingkat kegagalan dan lokasi log, untuk 20.000 sisipan individu
Di sini kita melihat bahwa semua pemicu AFTER rata-rata dalam rentang 10-11 detik (bergantung pada lokasi log), sementara semua pemicu INSTEAD OF berada jauh di bawah tanda 6 detik.
Kesimpulan
Sejauh ini, tampak jelas bagi saya bahwa BUKAN pemicu adalah pemenang dalam banyak kasus – dalam beberapa kasus lebih dari yang lain (misalnya, karena tingkat kegagalan naik). Faktor lain, seperti model pemulihan, tampaknya tidak terlalu berdampak pada kinerja secara keseluruhan.
Jika Anda memiliki ide lain tentang cara memecah data, atau ingin salinan data untuk melakukan pemotongan dan pemotongan Anda sendiri, beri tahu saya. Jika Anda membutuhkan bantuan untuk menyiapkan lingkungan ini sehingga Anda dapat menjalankan pengujian Anda sendiri, saya juga dapat membantu.
Sementara tes ini menunjukkan bahwa BUKAN pemicu pasti layak dipertimbangkan, itu bukan keseluruhan cerita. Saya benar-benar menyatukan pemicu ini menggunakan logika yang menurut saya paling masuk akal untuk setiap skenario, tetapi kode pemicu – seperti pernyataan T-SQL lainnya – dapat disetel untuk rencana yang optimal. Dalam postingan lanjutan, saya akan melihat potensi pengoptimalan yang dapat membuat pemicu AFTER lebih kompetitif.
Lampiran
Kueri yang digunakan untuk bagian Hasil:
Grafik 1 – Keseluruhan Agregat
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Grafik 2 &3 – 10 Terbaik &Terburuk
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Grafik 4 – Jenis Disk Log, Sisipan Tunggal
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;