Saya sudah lama menjadi pendukung memilih tipe data yang benar. Saya telah berbicara tentang beberapa contoh di posting blog "Kebiasaan Buruk" sebelumnya, tetapi akhir pekan ini di SQL Saturday #162 (Cambridge, UK), topik penggunaan DATETIME secara default muncul. Dalam percakapan setelah presentasi T-SQL :Kebiasaan Buruk dan Praktik Terbaik saya, seorang pengguna menyatakan bahwa mereka hanya menggunakan DATETIME bahkan jika mereka hanya membutuhkan perincian ke menit atau hari, dengan cara ini kolom tanggal/waktu di seluruh perusahaan mereka selalu memiliki tipe data yang sama. Saya menyarankan bahwa ini mungkin sia-sia, dan konsistensi mungkin tidak sepadan, tetapi hari ini saya memutuskan untuk membuktikan teori saya.
TL;DR versi
Pengujian saya di bawah ini mengungkapkan bahwa pasti ada skenario di mana Anda mungkin ingin mempertimbangkan untuk menggunakan tipe data yang lebih kurus daripada tetap menggunakan DATETIME di mana pun. Tetapi penting untuk melihat di mana pengujian saya untuk ini menunjuk ke arah lain, dan juga penting untuk menguji skenario ini terhadap skema Anda, di lingkungan Anda, dengan perangkat keras dan data yang sebenar mungkin untuk produksi. Hasil Anda mungkin, dan hampir pasti akan, bervariasi.
Tabel Tujuan
Mari kita pertimbangkan kasus di mana perincian hanya penting untuk hari itu (kami tidak peduli dengan jam, menit, detik). Untuk ini kita dapat memilih DATETIME (seperti yang diusulkan pengguna), atau SMALLDATETIME , atau DATE pada SQL Server 2008+. Ada juga dua jenis data berbeda yang ingin saya pertimbangkan:
- Data yang akan disisipkan secara berurutan secara real-time (misalnya peristiwa yang sedang terjadi saat ini);
- Data yang akan dimasukkan secara acak (misalnya tanggal lahir anggota baru).
Saya mulai dengan 2 tabel seperti berikut, lalu membuat 4 tabel lagi (2 untuk SMALLDATETIME, 2 untuk DATE):
BUAT TABEL dbo.BirthDatesRandom_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); BUAT INDEKS d PADA dbo.BirthDatesRandom_Datetime(dt);BUAT INDEX d PADA dbo.EventsSequential_Datetime(dt); -- Kemudian ulangi untuk DATE dan SMALLDATETIME.
Dan tujuan saya adalah menguji kinerja penyisipan batch dalam dua cara yang berbeda tersebut, serta dampaknya pada ukuran dan fragmentasi penyimpanan secara keseluruhan, dan terakhir kinerja kueri rentang.
Contoh Data
Untuk menghasilkan beberapa contoh data, saya menggunakan salah satu teknik praktis saya untuk menghasilkan sesuatu yang bermakna dari sesuatu yang bukan:tampilan katalog. Di sistem saya, ini mengembalikan 971 nilai tanggal/waktu yang berbeda (sekaligus 1.000.000 baris) dalam waktu sekitar 12 detik:
;DENGAN y AS ( SELECT TOP (100000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS x(x) ORDER BY NEWID()) SELECT DISTINCT d FROM y;
Saya menempatkan jutaan baris ini ke dalam tabel sehingga saya dapat mensimulasikan penyisipan berurutan/acak menggunakan metode akses yang berbeda untuk data yang sama persis dari tiga jendela sesi yang berbeda:
CREATE TABLE dbo.Staging( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL);;DENGAN Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS GABUNG sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID())INSERT dbo.Staging(source_date) SELECT dt FROM y ORDER BY dt;
Proses ini membutuhkan waktu sedikit lebih lama untuk diselesaikan (20 detik). Kemudian saya membuat tabel kedua untuk menyimpan data yang sama tetapi didistribusikan secara acak (sehingga saya dapat mengulangi distribusi yang sama di semua sisipan).
CREATE TABLE dbo.Staging_Random( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date) PILIH source_date DARI dbo.Staging ORDER BY NEWID();
Kueri untuk Mengisi Tabel
Selanjutnya, saya menulis satu set kueri untuk mengisi tabel lain dengan data ini, menggunakan tiga jendela kueri untuk mensimulasikan setidaknya sedikit konkurensi:
WAITFOR TIME '13:53';PERGI DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- bergantung pada metode / tipe data SELECT source_date FROM dbo.Staging[_Random] -- bergantung pada tujuan WHERE ID % 3 =<0,1,2> -- bergantung pada jendela kueri ORDER DENGAN ID; PILIH TANGGAL(MILLISECOND, @d, SYSDATETIME()); Seperti dalam posting terakhir saya, saya telah memperluas basis data untuk mencegah semua jenis peristiwa pertumbuhan otomatis file data mengganggu hasil. Saya menyadari bahwa tidak sepenuhnya realistis untuk melakukan penyisipan jutaan baris dalam satu lintasan, karena saya tidak dapat mencegah aktivitas log untuk transaksi sebesar itu mengganggu, tetapi harus melakukannya secara konsisten di setiap metode. Mengingat bahwa perangkat keras yang saya uji benar-benar berbeda dari perangkat keras yang Anda gunakan, hasil mutlak seharusnya tidak menjadi pertimbangan utama, hanya perbandingan relatif.
(Dalam pengujian mendatang saya juga akan mencoba ini dengan kumpulan nyata yang datang dari file log dengan data yang relatif beragam, dan menggunakan potongan tabel sumber dalam loop – saya pikir itu akan menjadi eksperimen yang menarik juga. Dan tentu saja menambahkan kompresi ke dalam campuran.)
Hasilnya:
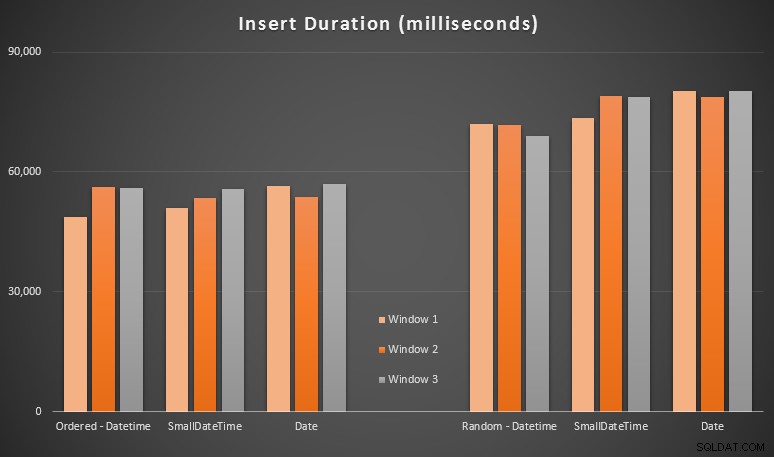
Hasil ini tidak terlalu mengejutkan bagi saya – memasukkan dalam urutan acak menyebabkan runtime lebih lama daripada memasukkan secara berurutan, sesuatu yang kita semua dapat mengambil kembali ke akar pemahaman kita bagaimana indeks di SQL Server bekerja dan bagaimana lebih banyak pemisahan halaman "buruk" dapat terjadi di skenario ini (saya tidak memantau secara khusus untuk pemisahan halaman dalam latihan ini, tetapi ini adalah sesuatu yang akan saya pertimbangkan dalam pengujian mendatang).
Saya perhatikan bahwa, di sisi acak, konversi implisit pada data yang masuk mungkin berdampak pada pengaturan waktu, karena tampaknya sedikit lebih tinggi daripada DATETIME -> DATETIME asli. sisipan. Jadi saya memutuskan untuk membuat dua tabel baru yang berisi data sumber:satu menggunakan DATE dan satu menggunakan SMALLDATETIME . Ini akan mensimulasikan, sampai tingkat tertentu, mengonversi tipe data Anda dengan benar sebelum meneruskannya ke pernyataan penyisipan, sehingga konversi implisit tidak diperlukan selama penyisipan. Berikut adalah tabel baru dan cara pengisiannya:
BUAT TABEL dbo.Staging_Random_SmallDatetime( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
Ini tidak memiliki efek yang saya harapkan – pengaturan waktunya serupa dalam semua kasus. Jadi itu adalah perburuan angsa liar.
Ruang Digunakan &Fragmentasi
Saya menjalankan kueri berikut untuk menentukan berapa banyak halaman yang dicadangkan untuk setiap tabel:
PILIH nama ='dbo.' + OBJECT_NAME([object_id]), halaman =SUM(reserved_page_count)FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id])ORDER BY halaman;
Hasilnya:
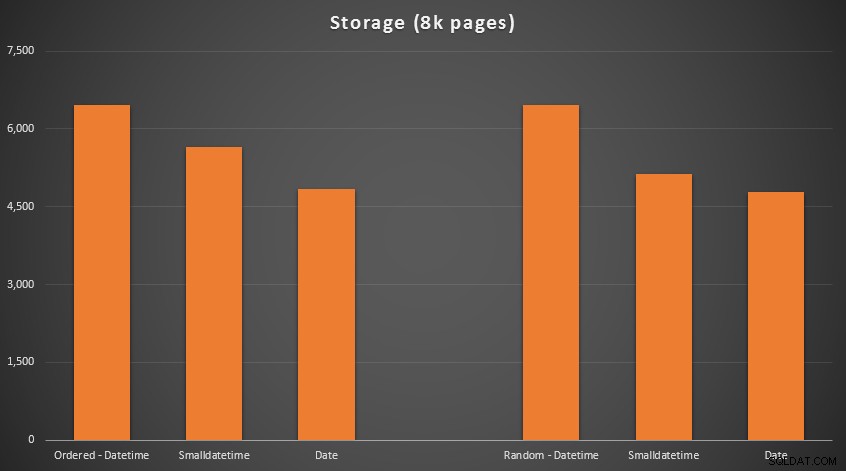
Tidak ada ilmu roket di sini; menggunakan tipe data yang lebih kecil, Anda harus menggunakan lebih sedikit halaman. Beralih dari DATETIME ke DATE secara konsisten menghasilkan pengurangan 25% dalam jumlah halaman yang digunakan, sementara SMALLDATETIME mengurangi persyaratan sebesar 13-20%.
Sekarang untuk fragmentasi dan kepadatan halaman pada indeks non-cluster (ada sedikit perbedaan untuk indeks clustered):
PILIH '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL, 'DETAI index' 'DETAI /pra>
Hasil:
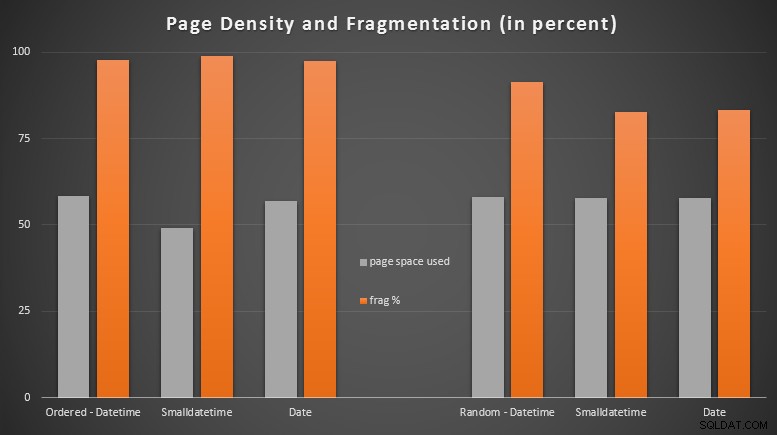
Saya cukup terkejut melihat data yang diurutkan menjadi hampir sepenuhnya terfragmentasi, sedangkan data yang dimasukkan secara acak sebenarnya berakhir dengan penggunaan halaman yang sedikit lebih baik. Saya telah membuat catatan bahwa ini memerlukan penyelidikan lebih lanjut di luar cakupan pengujian khusus ini, tetapi mungkin ada sesuatu yang ingin Anda periksa jika Anda memiliki indeks non-cluster yang mengandalkan sebagian besar sisipan berurutan.
[Pembangunan kembali indeks non-clustered secara online pada semua 6 tabel berjalan dalam 7 detik, mengembalikan kepadatan halaman ke kisaran 99,5%, dan menurunkan fragmentasi hingga di bawah 1%. Tapi saya tidak menjalankannya sampai melakukan tes kueri di bawah…]
Uji Kueri Rentang
Akhirnya, saya ingin melihat dampak pada waktu proses untuk kueri rentang tanggal sederhana terhadap indeks yang berbeda, baik dengan fragmentasi bawaan yang disebabkan oleh aktivitas tulis tipe OLTP, dan pada indeks bersih yang dibangun kembali. Kuerinya sendiri cukup sederhana:
PILIH TOP (200000) dt FROM dbo.{table_name} WHERE dt>='20110101' ORDER BY dt;
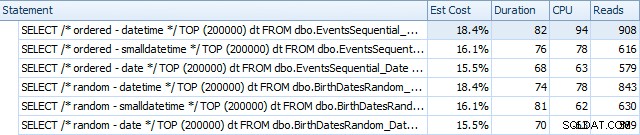
Berikut adalah hasil sebelum indeks dibangun kembali, menggunakan SQL Sentry Plan Explorer:
Dan mereka sedikit berbeda setelah pembangunan kembali:
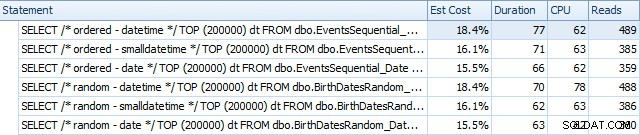
Pada dasarnya kami melihat durasi dan pembacaan yang sedikit lebih tinggi untuk versi DATETIME, tetapi sangat sedikit perbedaan dalam CPU. Dan perbedaan antara SMALLDATETIME dan DATE dapat diabaikan jika dibandingkan. Semua kueri memiliki rencana kueri sederhana seperti ini:

(Pencarian, tentu saja, adalah pemindaian jarak terurut.)
Kesimpulan
Meskipun diakui, tes ini cukup dibuat-buat dan dapat mengambil manfaat dari lebih banyak permutasi, mereka menunjukkan secara kasar apa yang saya harapkan untuk dilihat:dampak terbesar pada pilihan khusus ini adalah pada ruang yang ditempati oleh indeks non-cluster (di mana memilih tipe data yang lebih kurus akan tentu menguntungkan), dan pada waktu yang diperlukan untuk melakukan penyisipan secara acak, bukan berurutan, (di mana DATETIME hanya memiliki tepi marginal).
Saya ingin mendengar ide Anda tentang cara menempatkan pilihan tipe data seperti ini melalui tes yang lebih menyeluruh dan menghukum. Saya berencana untuk membahas lebih detail di postingan mendatang.