T-SQL Tuesday bulan ini dipandu oleh Mike Donnelly (@SQLMD), dan dia merangkum topiknya sebagai berikut:
Topik bulan ini lurus ke depan, tapi sangat terbuka berakhir. Anda harus mempelajari sesuatu yang baru dan kemudian menulis posting blog yang menjelaskannya.Nah, sejak Mike mengumumkan topiknya, saya tidak benar-benar berangkat untuk mempelajari sesuatu yang baru, dan saat akhir pekan mendekat dan saya tahu Senin akan menyerang saya dengan tugas juri, saya pikir saya harus duduk di kursi ini. keluar bulan.
Kemudian, Martin Smith mengajari saya sesuatu yang tidak pernah saya ketahui, atau sudah lama saya ketahui tetapi telah saya lupakan (terkadang Anda tidak mengetahui apa yang tidak Anda ketahui, dan terkadang Anda tidak dapat mengingat apa yang tidak pernah Anda ketahui dan apa yang tidak dapat Anda ingat). ingat). Ingatan saya adalah bahwa mengubah kolom dari NOT NULL ke NULL harus menjadi operasi metadata saja, dengan menulis ke halaman mana pun ditunda hingga halaman itu diperbarui karena alasan lain, karena NULL bitmap tidak perlu ada sampai setidaknya satu baris bisa menjadi NULL .
Pada postingan yang sama, @ypercube juga mengingatkan saya pada kutipan terkait dari Books Online (salah ketik dan semuanya):
Mengubah kolom dari NOT NULL ke NULL tidak didukung sebagai operasi online ketika kolom yang diubah adalah referensi oleh indeks nonclustered."Bukan operasi online" dapat diartikan sebagai "bukan operasi metadata saja" – artinya ini sebenarnya operasi ukuran data (semakin besar indeks Anda, semakin lama waktu yang dibutuhkan).
Saya mulai membuktikan ini dengan eksperimen yang cukup sederhana (tetapi panjang) terhadap kolom target tertentu untuk mengonversi dari NOT NULL ke NULL . Saya akan membuat 3 tabel, semua dengan kunci utama berkerumun, tetapi masing-masing dengan indeks non-berkelompok yang berbeda. Satu akan memiliki kolom target sebagai kolom kunci, yang kedua sebagai INCLUDE kolom, dan yang ketiga tidak akan mereferensikan kolom target sama sekali.
Berikut adalah tabel saya dan bagaimana saya mengisinya:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Setiap tabel memiliki 100.000 baris, indeks yang dikelompokkan memiliki 310 halaman, dan indeks yang tidak dikelompokkan memiliki 272 halaman (test1 dan test2 ) atau 174 halaman (test3 ). (Nilai-nilai ini mudah diperoleh dari sys.dm_db_index_physical_stats .)
Selanjutnya, saya membutuhkan cara sederhana untuk menangkap operasi yang dicatat di tingkat halaman – saya memilih sys.fn_dblog() , meskipun saya bisa menggali lebih dalam dan melihat halaman secara langsung. Saya tidak repot-repot mengotak-atik nilai LSN untuk diteruskan ke fungsi, karena saya tidak menjalankan ini dalam produksi dan tidak terlalu peduli dengan kinerja, jadi setelah tes saya hanya membuang hasil fungsi, tidak termasuk data apa pun yang telah dicatat sebelum ALTER TABLE operasi.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Sekarang saya dapat menjalankan pengujian saya, yang jauh lebih sederhana daripada penyiapannya.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Sekarang saya dapat memeriksa operasi yang dicatat dalam setiap kasus:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Hasilnya tampaknya menunjukkan bahwa setiap halaman daun dari indeks non-clustered disentuh untuk kasus di mana kolom target disebutkan dalam indeks dengan cara apa pun, tetapi tidak ada operasi seperti itu terjadi untuk kasus di mana kolom target tidak disebutkan dalam indeks tidak berkerumun:
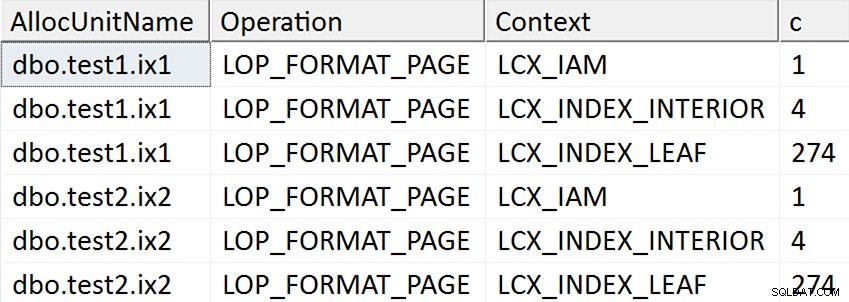
Faktanya, dalam dua kasus pertama, halaman baru dialokasikan (Anda dapat memvalidasinya dengan DBCC IND , seperti yang dilakukan Spörri dalam jawabannya), sehingga operasi dapat terjadi secara online, tetapi itu tidak berarti cepat (karena masih harus menulis salinan semua data itu, dan membuat NULL bitmap berubah sebagai bagian dari menulis setiap halaman baru, dan mencatat semua aktivitas itu).
Saya pikir kebanyakan orang akan curiga bahwa mengubah kolom dari NOT NULL ke NULL hanya metadata di semua skenario, tetapi saya telah menunjukkan di sini bahwa ini tidak benar jika kolom direferensikan oleh indeks non-cluster (dan hal serupa terjadi apakah itu kunci atau INCLUDE kolom). Mungkin operasi ini juga bisa dipaksa menjadi ONLINE di Azure SQL Database hari ini, atau mungkinkah di versi utama berikutnya? Ini tidak serta merta membuat operasi fisik yang sebenarnya terjadi lebih cepat, tetapi akibatnya akan mencegah pemblokiran.
Saya tidak menguji skenario itu (dan analisis apakah itu benar-benar online lebih sulit di Azure), saya juga tidak mengujinya di tumpukan. Sesuatu yang dapat saya kunjungi kembali di posting mendatang. Sementara itu, berhati-hatilah dengan asumsi apa pun yang mungkin Anda buat tentang operasi metadata saja.