Sampai sekarang kita telah membahas Pengantar Hadoop dan HDFS Hadoop secara terperinci. Dalam tutorial ini, kami akan memberikan Anda deskripsi mendetail tentang Hadoop Reducer.
Di sini akan dibahas apa itu Reducer di MapReduce, cara kerja Reducer di Hadoop MapReduce, berbagai fase Hadoop Reducer, bagaimana kita bisa mengubah jumlah Reducer di Hadoop MapReduce.
Apa itu Peredam Hadoop?
Peredam di Hadoop MapReduce mengurangi kumpulan nilai perantara yang berbagi kunci ke kumpulan nilai yang lebih kecil.
Dalam alur eksekusi tugas MapReduce, Reducer mengambil satu set pasangan nilai kunci menengah dihasilkan oleh mapper sebagai masukan. Kemudian, Reducer mengagregasi, memfilter, dan menggabungkan pasangan nilai kunci dan ini memerlukan berbagai pemrosesan.
Pemetaan satu-satu terjadi antara kunci dan reduksi dalam eksekusi pekerjaan MapReduce. Mereka berjalan secara paralel karena mereka independen satu sama lain. Pengguna memutuskan jumlah reduksi di MapReduce.
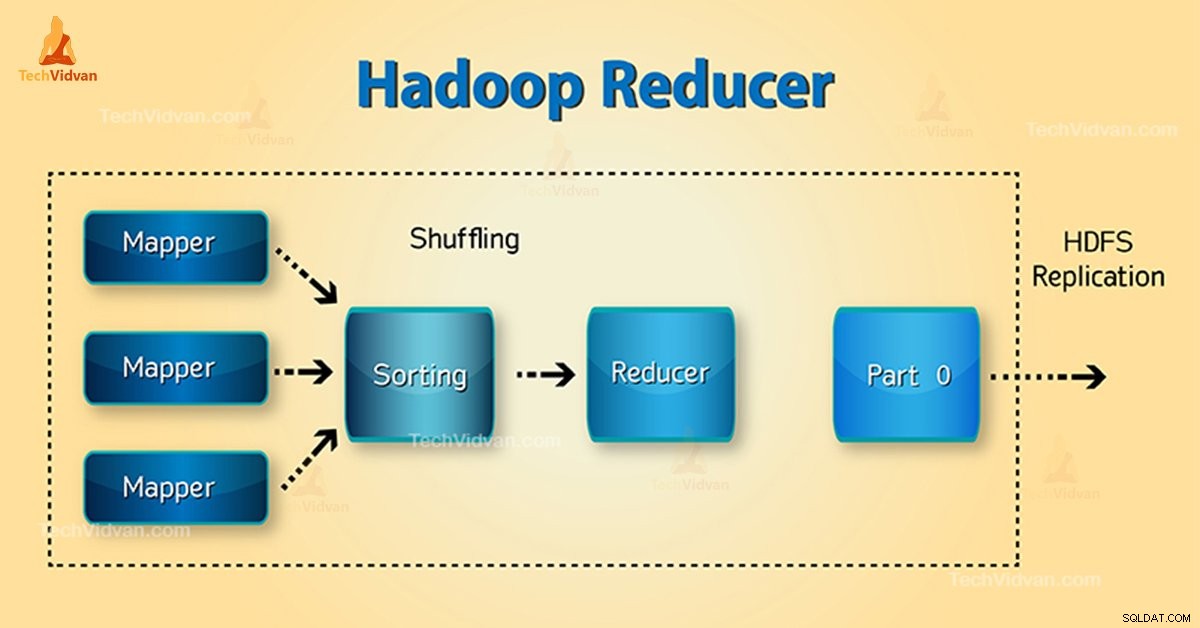
Fase Peredam Hadoop
Tiga fase Reducer adalah sebagai berikut:
1. Fase Acak
Ini adalah fase di mana output yang diurutkan dari mapper adalah input ke peredam. Kerangka kerja dengan bantuan HTTP mengambil partisi yang relevan dari output semua pembuat peta dalam fase ini. Fase Urutkan
2. Urutkan Fase
Ini adalah fase di mana input dari pembuat peta yang berbeda diurutkan kembali berdasarkan kunci yang sama di Pemeta yang berbeda.
Acak dan Urutkan terjadi secara bersamaan.
3. Kurangi Fase
Fase ini terjadi setelah shuffle and sort. Kurangi tugas menggabungkan pasangan nilai kunci. Dengan OutputCollector.collect() properti, output dari tugas pengurangan ditulis ke FileSystem. Output peredam tidak diurutkan.
Jumlah Reducer di Hadoop MapReduce
Pengguna menyetel jumlah reduksi dengan bantuan Job.setNumreduceTasks(int) Properti. Jadi jumlah reduksi yang tepat dengan rumus:
0,95 atau 1,75 dikalikan dengan (
Jadi, dengan 0,95, semua reduksi segera diluncurkan. Kemudian, mulailah mentransfer output peta saat peta selesai.
Node yang lebih cepat menyelesaikan putaran pertama reduksi dengan 1,75. Kemudian meluncurkan peredam gelombang kedua yang melakukan pekerjaan penyeimbangan beban yang jauh lebih baik.
Dengan bertambahnya jumlah reduksi:
- Overhead kerangka kerja meningkat.
- Peningkatan penyeimbangan beban.
- Biaya kegagalan berkurang.
Kesimpulan
Oleh karena itu, Reducer mengambil output pembuat peta sebagai input. Kemudian, proses pasangan nilai kunci dan menghasilkan output. Output peredam adalah output akhir. Jika Anda menyukai blog ini atau Anda memiliki pertanyaan terkait Hadoop Reducer, silakan bagikan dengan kami dengan meninggalkan komentar.
Semoga kami dapat membantu Anda.



