Di blog ini, kami akan memberikan pengenalan lengkap tentang Hadoop Mapper . saya
Di blog ini kita akan menjawab apa itu Mapper di Hadoop MapReduce, bagaimana cara kerja hadoop mapper, apa saja proses mapper di Mapreduce, bagaimana Hadoop menghasilkan Key-value pair di MapReduce.
Pengantar Hadoop Mapper
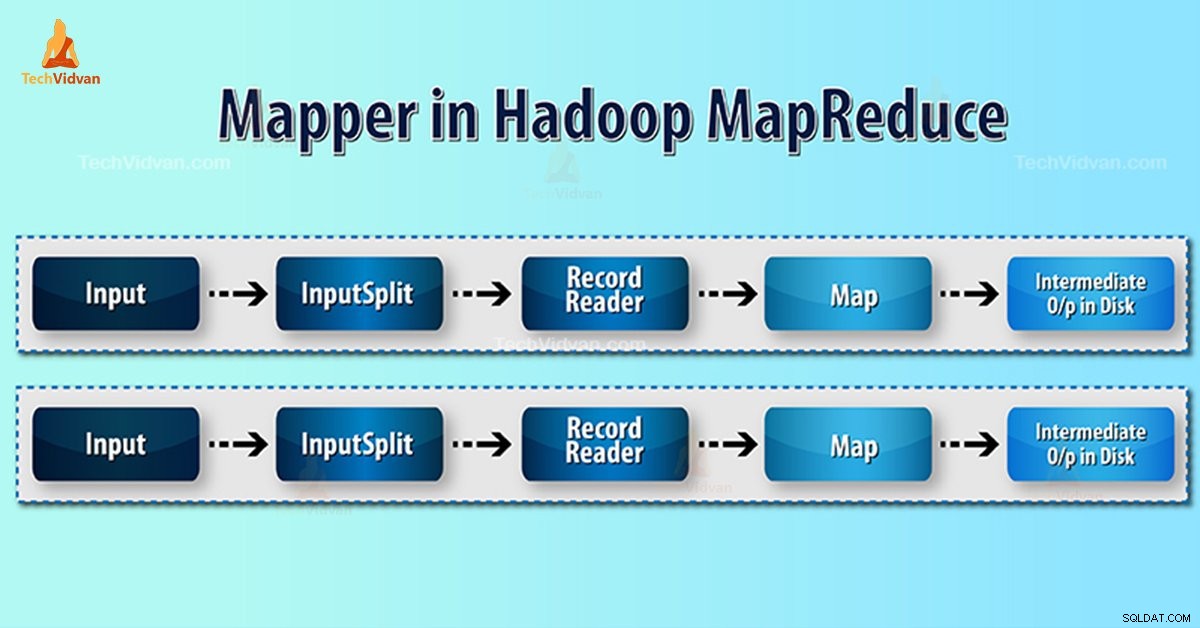
Pemeta Hadoop memproses catatan input yang dihasilkan oleh RecordReader dan menghasilkan pasangan kunci-nilai menengah. Output antara benar-benar berbeda dari pasangan input.
Keluaran dari mapper adalah kumpulan lengkap dari pasangan nilai kunci. Sebelum menulis output untuk setiap tugas mapper, partisi output dilakukan berdasarkan kunci. Dengan demikian, partisi memerinci bahwa semua nilai untuk setiap kunci dikelompokkan bersama.
Hadoop MapReduce menghasilkan satu tugas peta untuk setiap InputSplit.
Hadoop MapReduce hanya memahami pasangan data nilai kunci. Jadi, sebelum mengirim data ke mapper, framework Hadoop harus menyembunyikan data ke dalam key-value pair.
Bagaimana pasangan nilai kunci dihasilkan di Hadoop?
Setelah kita memahami apa itu mapper di hadoop, sekarang kita akan membahas bagaimana Hadoop menghasilkan key-value pair?
- Pemisahan Masukan – Ini adalah representasi logis dari data yang dihasilkan oleh InputFormat. Dalam program MapReduce, ini menggambarkan unit kerja yang berisi tugas peta tunggal.
- Pembaca Rekaman- Ini berkomunikasi dengan inputSplit. Dan kemudian mengubah data menjadi pasangan nilai kunci yang sesuai untuk dibaca oleh Pemeta. RecordReader secara default menggunakan TextInputFormat untuk mengonversi data menjadi pasangan nilai kunci.
Proses Pemeta di Hadoop MapReduce
Pemisahan Masukan mengonversi representasi fisik blok menjadi logis untuk Mapper. Misalnya, untuk membaca file 100MB, diperlukan 2 InputSplit. Untuk setiap blok, kerangka kerja membuat satu InputSplit. Setiap InputSplit membuat satu mapper.
MapReduce InputSplit tidak selalu bergantung pada jumlah blok data . Kita dapat mengubah jumlah pembagian dengan menyetel properti mapred.max.split.size selama pelaksanaan pekerjaan.
MapReduce RecordReader bertanggung jawab untuk membaca/mengonversi data menjadi pasangan nilai kunci hingga akhir file. RecordReader memberikan Byte offset untuk setiap baris yang ada dalam file.
Kemudian Mapper menerima pasangan kunci ini. Mapper menghasilkan keluaran perantara (pasangan nilai kunci yang dapat dimengerti untuk dikurangi).
Berapa banyak tugas Peta di Hadoop?
Jumlah tugas peta tergantung pada jumlah blok file input. Di peta MapReduce, tingkat paralelisme yang tepat tampaknya sekitar 10-100 peta/simpul. Tapi ada 300 peta untuk tugas peta ringan CPU.
Misalnya, kami memiliki ukuran blok 128 MB. Dan kami mengharapkan 10TB data input. Dengan demikian menghasilkan 82.000 peta. Oleh karena itu jumlah peta tergantung pada InputFormat.
Mapper =(ukuran data total)/ (ukuran pemisahan masukan)
Contoh – ukuran data adalah 1 TB. Ukuran split input adalah 100 MB.
Pemeta =(1000*1000)/100 =10.000
Kesimpulan
Oleh karena itu, Mapper di Hadoop mengambil satu set data dan mengubahnya menjadi set data lain. Dengan demikian, ia memecah elemen individual menjadi tupel (pasangan kunci/nilai).
Semoga Anda menyukai blok ini, jika Anda memiliki pertanyaan untuk Hadoop mapper, jadi silakan tinggalkan komentar di bagian yang diberikan di bawah ini. Kami akan dengan senang hati menyelesaikannya.



