Kegagalan otomatis untuk Replikasi MySQL telah menjadi bahan perdebatan selama bertahun-tahun.
Apakah itu hal yang baik atau buruk?
Bagi mereka yang memiliki memori lama di dunia MySQL, mereka mungkin ingat pemadaman GitHub pada tahun 2012 yang terutama disebabkan oleh perangkat lunak yang mengambil keputusan yang salah.
GitHub baru saja bermigrasi ke kombinasi MySQL Replication, Corosync, Pacemaker, dan Percona Replication Manager. PRM memutuskan untuk melakukan failover setelah gagal dalam pemeriksaan kesehatan pada master, yang kelebihan beban selama migrasi skema. Master baru dipilih, tetapi kinerjanya buruk karena cache dingin. Beban kueri yang tinggi dari situs yang sibuk menyebabkan detak jantung PRM gagal lagi pada master dingin, dan PRM kemudian memicu failover lain ke master asli. Dan masalah terus berlanjut, seperti yang dirangkum di bawah ini.
 Sumber:Henrik Ingo &Massimo Brignoli di Percona Live 2013
Sumber:Henrik Ingo &Massimo Brignoli di Percona Live 2013 Maju cepat beberapa tahun dan GitHub kembali dengan kerangka kerja yang cukup canggih untuk mengelola Replikasi MySQL dan failover otomatis! Seperti yang dikatakan Shlomi Noach:
“Untuk itu, kami menggunakan failover master otomatis. Waktu yang dibutuhkan manusia untuk membangunkan &memperbaiki master yang gagal berada di luar perkiraan ketersediaan kami, dan mengoperasikan failover semacam itu terkadang tidak sepele. Kami berharap kegagalan master terdeteksi dan dipulihkan secara otomatis dalam waktu 30 detik atau kurang, dan kami berharap kegagalan menghasilkan sedikit hilangnya host yang tersedia.”
Sebagian besar perusahaan bukan GitHub, tetapi orang dapat berargumen bahwa tidak ada perusahaan yang menyukai pemadaman. Pemadaman mengganggu bisnis apa pun, dan juga membutuhkan biaya. Dugaan saya adalah bahwa sebagian besar perusahaan di luar sana mungkin berharap mereka memiliki semacam failover otomatis, dan alasan untuk tidak mengimplementasikannya mungkin adalah kompleksitas dari solusi yang ada, kurangnya kompetensi dalam mengimplementasikan solusi tersebut, atau kurangnya kepercayaan pada perangkat lunak yang akan digunakan. keputusan yang begitu penting.
Ada sejumlah solusi failover otomatis di luar sana, termasuk (dan tidak terbatas pada) MHA, MMM, MRM, mysqlfailover, Orchestrator, dan ClusterControl. Beberapa dari mereka telah berada di pasar selama beberapa tahun, yang lain lebih baru. Itu pertanda baik, banyak solusi berarti ada pasar dan orang-orang mencoba mengatasi masalah.
Saat kami merancang failover otomatis dalam ClusterControl, kami menggunakan beberapa prinsip panduan:
-
Pastikan master benar-benar mati sebelum Anda melakukan failover
Dalam kasus partisi jaringan, di mana perangkat lunak failover kehilangan kontak dengan master, ia akan berhenti melihatnya. Tetapi master mungkin bekerja dengan baik dan dapat dilihat oleh topologi replikasi lainnya.
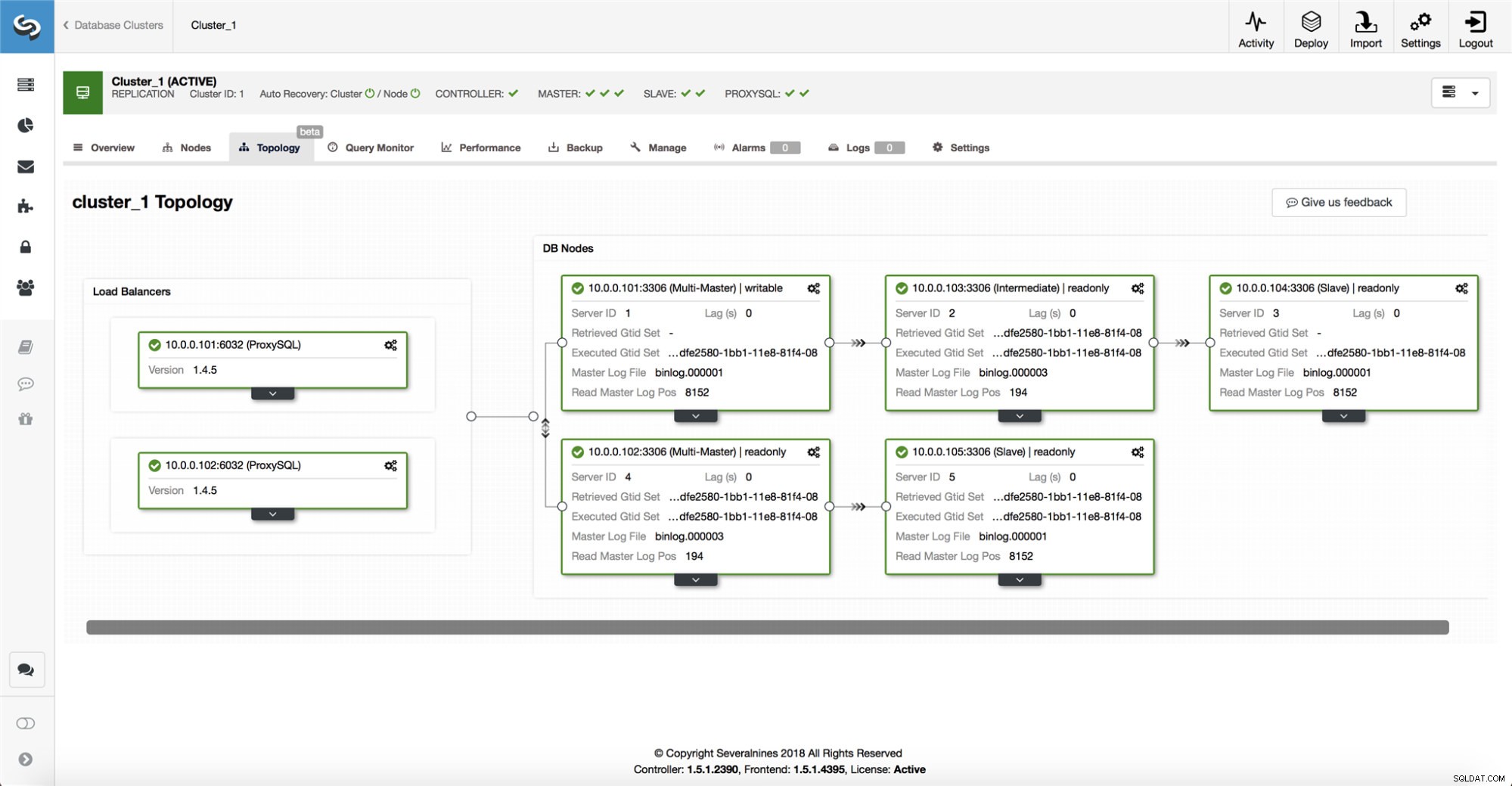
ClusterControl mengumpulkan informasi dari semua node database serta proxy database/penyeimbang beban yang digunakan, dan kemudian membangun representasi topologi. Itu tidak akan mencoba failover jika budak dapat melihat master, atau jika ClusterControl tidak 100% yakin tentang status master.
ClusterControl juga memudahkan untuk memvisualisasikan topologi penyiapan, serta status node yang berbeda (ini adalah pemahaman ClusterControl tentang status sistem, berdasarkan informasi yang dikumpulkannya).
-
Kegagalan hanya sekali
Banyak yang telah ditulis tentang mengepak. Ini bisa menjadi sangat berantakan jika alat ketersediaan memutuskan untuk melakukan beberapa failover. Itu situasi yang berbahaya. Setiap master yang dipilih, betapapun singkatnya periode memegang peran master, mungkin memiliki serangkaian perubahan mereka sendiri yang tidak pernah direplikasi ke server mana pun. Jadi, Anda mungkin berakhir dengan ketidakkonsistenan di semua master terpilih.
-
Jangan melakukan failover ke budak yang tidak konsisten
Saat memilih budak untuk dipromosikan sebagai master, kami memastikan budak tidak memiliki inkonsistensi, mis. transaksi yang salah, karena ini dapat merusak replikasi.
-
Hanya menulis ke master
Replikasi berjalan dari master ke slave. Menulis langsung ke slave akan membuat kumpulan data yang berbeda, dan itu bisa menjadi sumber masalah potensial. Kami mengatur budak ke read_only, dan super_read_only di versi MySQL atau MariaDB yang lebih baru. Kami juga menyarankan penggunaan penyeimbang beban, misalnya, ProxySQL atau MaxScale, untuk melindungi lapisan aplikasi dari topologi database yang mendasarinya dan perubahan apa pun padanya. Penyeimbang beban juga memberlakukan penulisan pada master saat ini.
-
Jangan memulihkan master yang gagal secara otomatis
Jika master gagal dan master baru telah dipilih, ClusterControl tidak akan mencoba memulihkan master yang gagal. Mengapa? Server itu mungkin memiliki data yang belum direplikasi, dan administrator perlu melakukan penyelidikan atas kegagalan tersebut. Oke, Anda masih dapat mengonfigurasi ClusterControl untuk menghapus data pada master yang gagal dan membuatnya bergabung sebagai budak dari master baru - jika Anda setuju dengan kehilangan beberapa data. Tetapi secara default, ClusterControl akan membiarkan master yang gagal, sampai seseorang melihatnya dan memutuskan untuk memasukkannya kembali ke dalam topologi.
Jadi, haruskah Anda mengotomatiskan failover? Itu tergantung pada bagaimana Anda telah mengonfigurasi replikasi. Pengaturan replikasi melingkar dengan beberapa master yang dapat ditulisi atau topologi kompleks mungkin bukan kandidat yang baik untuk failover otomatis. Kami akan tetap berpegang pada prinsip di atas saat merancang solusi replikasi.
Di PostgreSQL
Dalam hal replikasi streaming PostgreSQL, ClusterControl menggunakan prinsip serupa untuk mengotomatiskan failover. Untuk PostgreSQL, ClusterControl mendukung model replikasi asinkron dan sinkron antara master dan slave. Dalam kedua kasus dan jika terjadi kegagalan, budak dengan data terbaru dipilih sebagai master baru. Master yang gagal tidak dipulihkan/diperbaiki secara otomatis untuk bergabung kembali dengan penyiapan replikasi.
Ada beberapa tindakan perlindungan yang diambil untuk memastikan master yang gagal mati dan tetap di bawah, mis. itu dihapus dari set penyeimbang beban di proxy dan dimatikan jika mis. pengguna akan memulai ulang secara manual. Agak lebih menantang di sana untuk mendeteksi pemisahan jaringan antara ClusterControl dan master, karena budak tidak memberikan informasi apa pun tentang status master tempat mereka mereplikasi. Jadi proxy di depan pengaturan basis data penting karena dapat memberikan jalur lain ke master.
Di MongoDB
Replikasi MongoDB dalam sebuah replicaset melalui oplog sangat mirip dengan replikasi binlog, jadi bagaimana bisa MongoDB secara otomatis memulihkan master yang gagal? Masalahnya masih ada, dan MongoDB mengatasinya dengan memutar kembali setiap perubahan yang tidak direplikasi ke budak pada saat kegagalan. Data tersebut dihapus dan ditempatkan di folder 'kembalikan', jadi terserah administrator untuk memulihkannya.
Untuk mengetahui lebih lanjut, lihat ClusterControl; dan jangan ragu untuk berkomentar atau mengajukan pertanyaan di bawah.



