Tujuan utama dari Tutorial Hadoop ini adalah untuk memberi Anda deskripsi mendetail tentang setiap komponen yang digunakan dalam kerja Hadoop. Dalam tutorial ini, kita akan membahas Partitioner di Hadoop.
Apa itu Partitioner Hadoop, apa kebutuhan Partitioner di Hadoop, Apa Partitioner default di MapReduce, Berapa banyak Partitioner MapReduce yang digunakan di Hadoop?
Kami akan menjawab semua pertanyaan ini dalam tutorial MapReduce ini.
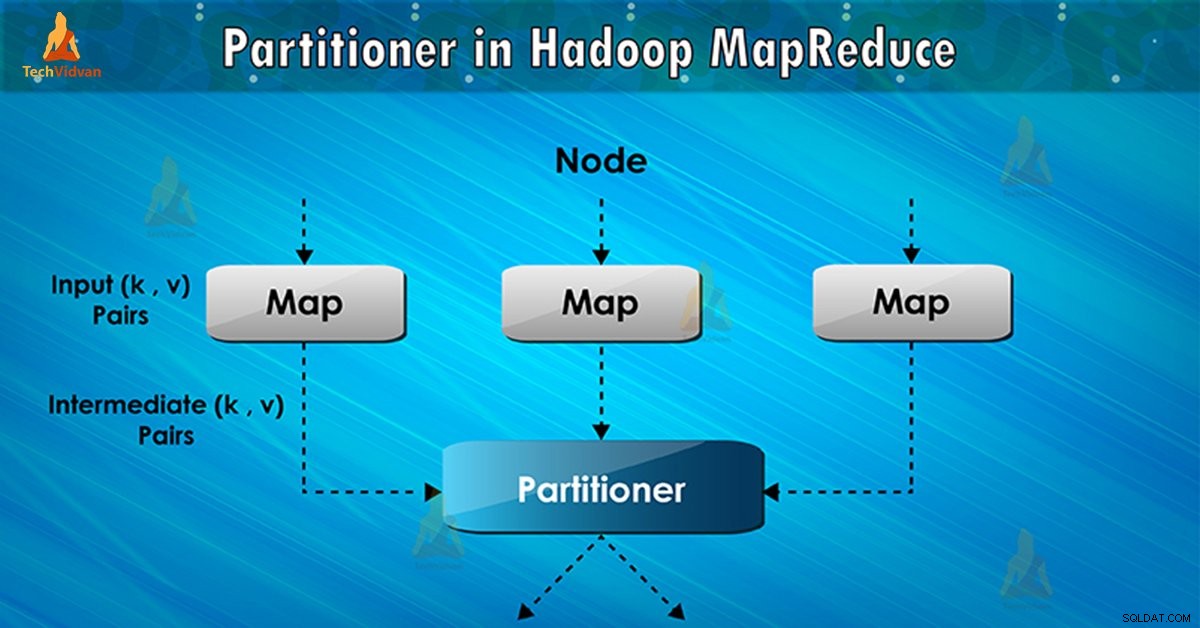
Apa itu Partisi Hadoop?
Partitioner dalam eksekusi tugas MapReduce mengontrol partisi kunci output peta perantara. Dengan bantuan fungsi hash, kunci (atau subset dari kunci) mendapatkan partisi. Jumlah total partisi sama dengan jumlah tugas pengurangan.
Berdasarkan nilai kunci , partisi kerangka kerja, masing-masing mapper keluaran. Catatan yang memiliki nilai kunci yang sama masuk ke partisi yang sama (dalam setiap pembuat peta). Kemudian setiap partisi dikirim ke peredam .
Kelas partisi memutuskan partisi mana yang akan digunakan pasangan (kunci, nilai) tertentu. Fase partisi dalam aliran data MapReduce terjadi setelah fase peta dan sebelum fase reduksi.
Kebutuhan MapReduce Partitioner di Hadoop
Dalam eksekusi tugas MapReduce, dibutuhkan set data input dan menghasilkan daftar pasangan nilai kunci. Pasangan nilai kunci ini adalah hasil dari fase peta. Di mana data input dibagi dan setiap tugas memproses pemisahan dan setiap peta, menampilkan daftar pasangan nilai kunci.
Kemudian, framework mengirimkan output peta untuk mengurangi tugas. Mengurangi proses fungsi pengurangan yang ditentukan pengguna pada output peta. Sebelum fase reduksi, partisi output peta dilakukan berdasarkan kunci.
Partisi Hadoop menetapkan bahwa semua nilai untuk setiap kunci dikelompokkan bersama. Itu juga memastikan bahwa semua nilai dari satu kunci masuk ke peredam yang sama. Hal ini memungkinkan pemerataan output peta melalui peredam.
Partisi dalam tugas MapReduce mengarahkan ulang output mapper ke peredam dengan menentukan peredam mana yang menangani kunci tertentu.
Partisi Default Hadoop
Pembagi Hash adalah Partisi default. Ini menghitung nilai hash untuk kunci. Itu juga menetapkan partisi berdasarkan hasil ini.
Berapa Partisi di Hadoop?
Jumlah Partisi tergantung pada jumlah reduksi. Hadoop Partitioner membagi data sesuai dengan jumlah reduksi. Ini disetel oleh JobConf.setNumReduceTasks() metode.
Jadi peredam tunggal memproses data dari partisi tunggal. Hal penting yang harus diperhatikan adalah bahwa framework membuat partisi hanya jika ada banyak reduksi.
Partisi Buruk di Hadoop MapReduce
Jika dalam input data di pekerjaan MapReduce satu kunci muncul lebih banyak daripada kunci lainnya. Dalam hal demikian, untuk mengirim data ke partisi kita menggunakan dua mekanisme yaitu sebagai berikut:
- Kunci yang muncul lebih sering akan dikirim ke satu partisi.
- Semua kunci lainnya akan dikirim ke partisi berdasarkan kode hash() mereka .
Jika hashCode() metode tidak mendistribusikan data kunci lainnya melalui rentang partisi. Maka data tidak akan dikirim ke reduksi.
Partisi data yang buruk berarti bahwa beberapa reduksi akan memiliki lebih banyak input data dibandingkan dengan yang lain. Mereka akan memiliki lebih banyak pekerjaan yang harus dilakukan daripada reduksi lainnya. Dengan demikian, seluruh pekerjaan harus menunggu satu peredam menyelesaikan porsi beban ekstra besar.
Bagaimana cara mengatasi partisi yang buruk di MapReduce?
Untuk mengatasi pemartisi yang buruk di Hadoop MapReduce, kita dapat membuat pempartisi Kustom. Hal ini memungkinkan berbagi beban kerja di berbagai reduksi.
Kesimpulan
Kesimpulannya, Partitioner memungkinkan distribusi seragam dari output peta melalui peredam. Di MapReducer Partitioner, partisi output peta dilakukan berdasarkan kunci dan nilai.
Oleh karena itu, kami telah membahas gambaran lengkap Partitioner di blog ini. Semoga Anda menyukainya. Jika ada keraguan di benak Anda tentang Hadoop Partitioner, jangan lupa untuk berbagi dengan kami.



