Ini adalah seri ketiga dari lima bagian yang mempelajari secara mendalam cara rencana paralel mode baris SQL Server mulai dijalankan. Bagian 1 menginisialisasi konteks eksekusi nol untuk tugas induk, dan bagian 2 membuat pohon pemindaian kueri. Kami sekarang siap untuk memulai pemindaian kueri, melakukan beberapa fase awal pemrosesan, dan mulai tugas paralel tambahan pertama.
Memulai Pemindaian Kueri
Ingatlah bahwa hanya tugas induk ada sekarang, dan pertukaran (operator paralelisme) hanya memiliki sisi konsumen. Namun, ini cukup untuk memulai eksekusi kueri, di utas pekerja tugas induk. Pemroses kueri memulai eksekusi dengan memulai proses pemindaian kueri melalui panggilan ke CQueryScan::StartupQuery . Pengingat rencana (klik untuk memperbesar):
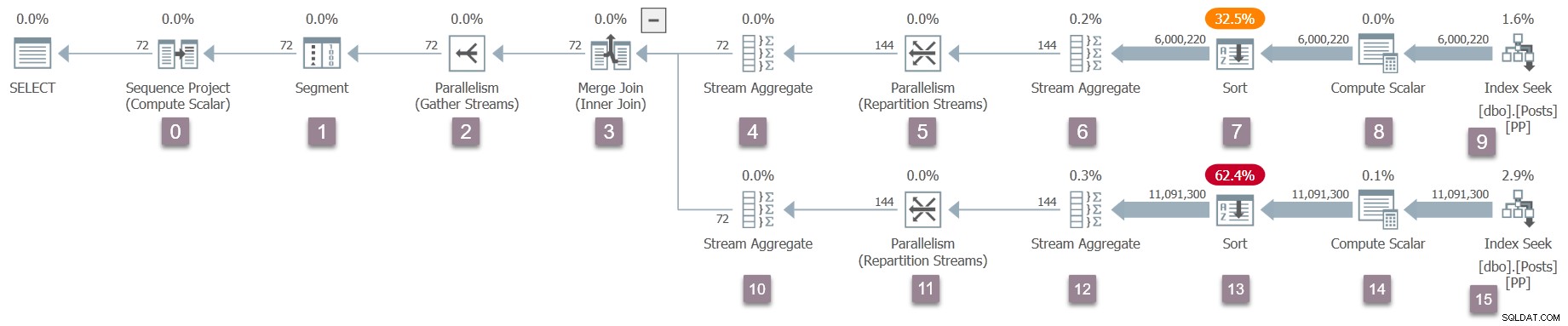
Ini adalah poin pertama dalam proses sejauh ini bahwa rencana eksekusi dalam penerbangan tersedia (SQL Server 2016 SP1 dan seterusnya) di sys.dm_exec_query_statistics_xml . Tidak ada yang menarik untuk dilihat dalam rencana seperti itu pada saat ini, karena semua penghitung sementara adalah nol, tetapi rencana tersebut setidaknya tersedia . Tidak ada petunjuk bahwa tugas paralel belum dibuat, atau bahwa pertukaran tidak memiliki sisi produsen. Rencananya terlihat 'normal' dalam segala hal.
Cabang Rencana Paralel
Karena ini adalah denah paralel, akan berguna untuk menunjukkannya dipecah menjadi cabang-cabang. Ini diarsir di bawah, dan diberi label sebagai cabang A sampai D:
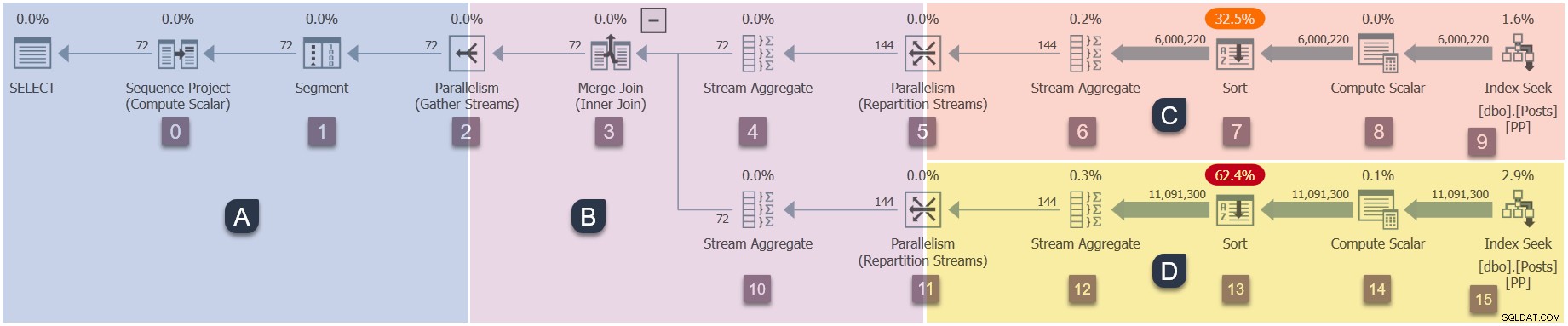
Cabang A dikaitkan dengan tugas induk, berjalan di utas pekerja yang disediakan oleh sesi. Pekerja paralel tambahan akan mulai menjalankan tugas paralel tambahan terdapat pada cabang B, C, dan D. Cabang-cabang tersebut sejajar, sehingga akan ada tugas dan pekerja tambahan DOP di masing-masing cabang.
Contoh kueri kami berjalan pada DOP 2, jadi cabang B akan mendapatkan dua tugas tambahan. Hal yang sama berlaku untuk cabang C dan cabang D, memberikan total enam tugas tambahan. Setiap tugas akan berjalan di thread pekerjanya sendiri dalam konteks eksekusinya sendiri.
Dua penjadwal (S1 dan S2 ) ditugaskan ke kueri ini untuk menjalankan pekerja paralel tambahan. Setiap pekerja tambahan akan berjalan di salah satu dari dua penjadwal tersebut. Pekerja induk dapat berjalan pada penjadwal yang berbeda, sehingga kueri DOP 2 kami dapat menggunakan maksimum tiga inti prosesor kapan saja.
Untuk meringkas, rencana kami pada akhirnya akan memiliki:
- Cabang A (orang tua)
- Tugas orang tua.
- Utas pekerja induk.
- Konteks eksekusi nol.
- Penjadwal tunggal apa pun yang tersedia untuk kueri.
- Cabang B (tambahan)
- Dua tugas tambahan.
- Sebuah thread pekerja tambahan terikat pada setiap tugas baru.
- Dua konteks eksekusi baru, satu untuk setiap tugas baru.
- Satu utas pekerja berjalan pada penjadwal S1 . Yang lain berjalan pada penjadwal S2 .
- Cabang C (tambahan)
- Dua tugas tambahan.
- Sebuah thread pekerja tambahan terikat pada setiap tugas baru.
- Dua konteks eksekusi baru, satu untuk setiap tugas baru.
- Satu utas pekerja berjalan pada penjadwal S1 . Yang lain berjalan pada penjadwal S2 .
- Cabang D (tambahan)
- Dua tugas tambahan.
- Sebuah thread pekerja tambahan terikat pada setiap tugas baru.
- Dua konteks eksekusi baru, satu untuk setiap tugas baru.
- Satu utas pekerja berjalan pada penjadwal S1 . Yang lain berjalan pada penjadwal S2 .
Pertanyaannya adalah bagaimana semua tugas tambahan, pekerja, dan konteks eksekusi ini dibuat, dan kapan mereka mulai berjalan.
Awal Urutan
Urutan di mana tugas tambahan mulai jalankan untuk rencana khusus ini adalah:
- Cabang A (tugas induk).
- Cabang C (tugas paralel tambahan).
- Cabang D (tugas paralel tambahan).
- Cabang B (tugas paralel tambahan).
Itu mungkin bukan pesanan awal yang Anda harapkan.
Mungkin ada penundaan yang signifikan antara masing-masing langkah ini, untuk alasan yang akan kita jelajahi segera. Poin kunci pada tahap ini adalah bahwa tugas tambahan, pekerja, dan konteks eksekusi tidak semua dibuat sekaligus, dan mereka tidak semua mulai dieksekusi pada saat yang sama.
SQL Server dapat dirancang untuk memulai semua bit paralel ekstra sekaligus. Itu mungkin mudah dipahami, tetapi secara umum tidak akan sangat efisien. Ini akan memaksimalkan jumlah utas tambahan dan sumber daya lain yang digunakan oleh kueri, dan menghasilkan banyak waktu tunggu paralel yang tidak perlu.
Dengan desain yang digunakan oleh SQL Server, paket paralel akan sering menggunakan total pekerja lebih sedikit daripada (DOP dikalikan dengan jumlah total cabang). Hal ini dicapai dengan mengenali bahwa beberapa cabang dapat berjalan sampai selesai sebelum beberapa cabang lain perlu dimulai. Ini dapat memungkinkan penggunaan kembali utas dalam kueri yang sama, dan umumnya mengurangi konsumsi sumber daya secara keseluruhan.
Sekarang mari kita beralih ke detail tentang bagaimana paket paralel kita dimulai.
Membuka Cabang A
Pemindaian kueri mulai dijalankan dengan tugas induk yang memanggil Open() pada iterator di akar pohon. Ini adalah awal dari urutan eksekusi:
- Cabang A (tugas induk).
- Cabang C (tugas paralel tambahan).
- Cabang D (tugas paralel tambahan).
- Cabang B (tugas paralel tambahan).
Kami menjalankan kueri ini dengan paket 'aktual' yang diminta, jadi iterator root tidak operator proyek urutan pada simpul 0. Sebaliknya, ini adalah profiling iterator invisible yang tidak terlihat yang mencatat metrik waktu proses dalam paket mode baris.
Ilustrasi di bawah menunjukkan iterator pemindaian kueri di Cabang A dari rencana, dengan posisi iterator pembuatan profil tak terlihat yang diwakili oleh ikon 'kacamata'.
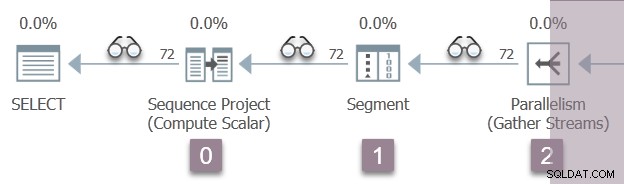
Eksekusi dimulai dengan panggilan untuk membuka profiler pertama, CQScanProfileNew::Open . Ini menetapkan waktu buka untuk operator proyek urutan anak melalui API Penghitung Kinerja Kueri sistem operasi.
Kita bisa melihat nomor ini di sys.dm_exec_query_profiles :
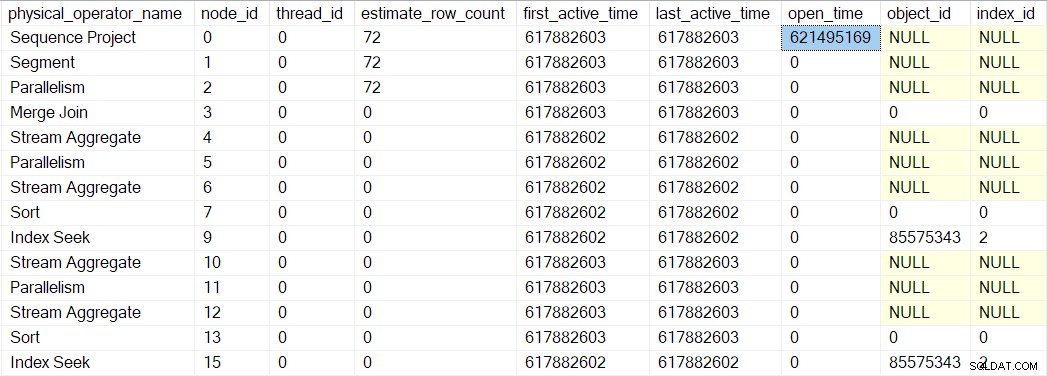
Entri di sana mungkin mencantumkan nama operator, tetapi datanya berasal dari profiler di atas operator, bukan operator itu sendiri.
Seperti yang terjadi, proyek urutan (CQScanSeqProjectNew ) tidak perlu melakukan pekerjaan apa pun saat dibuka , jadi sebenarnya tidak memiliki Open() metode. Profiler di atas proyek urutan adalah dipanggil, jadi waktu buka untuk proyek urutan dicatat dalam DMV.
Open profil profiler metode tidak memanggil Open pada proyek urutan (karena tidak memilikinya). Sebaliknya ia memanggil Open pada profiler untuk iterator berikutnya secara berurutan. Ini adalah segmen iterator di node 1. Itu menetapkan waktu buka untuk segmen, seperti yang dilakukan profiler sebelumnya untuk proyek urutan:
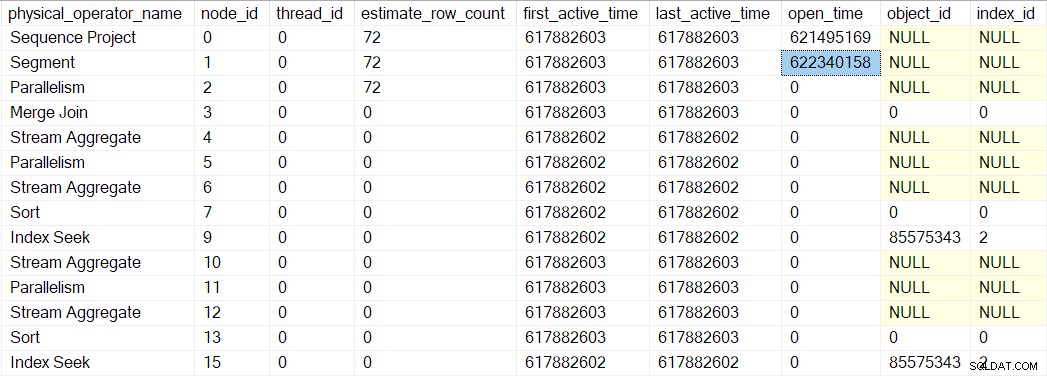
Sebuah iterator segmen melakukannya ada hal yang harus dilakukan saat dibuka, jadi panggilan berikutnya adalah CQScanSegmentNew::Open . Setelah segmen melakukan apa yang diperlukan, segmen akan memanggil profiler untuk iterator berikutnya secara berurutan — konsumen sisi kumpulkan pertukaran aliran di simpul 2:
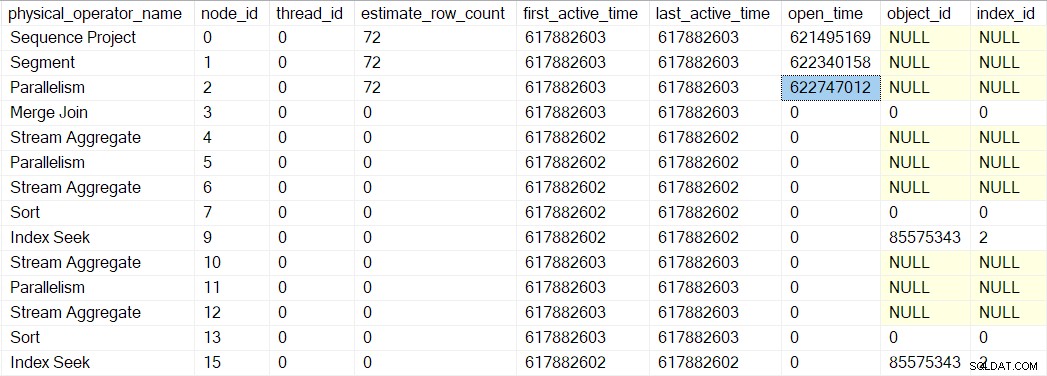
Panggilan berikutnya ke bawah pohon pemindaian kueri dalam proses pembukaan adalah CQScanExchangeNew::Open , di situlah segalanya mulai menjadi lebih menarik.
Membuka pertukaran aliran berkumpul
Meminta sisi konsumen bursa untuk membuka:
- Membuka transaksi lokal (bersarang paralel) (
CXTransLocal::Open). Setiap proses membutuhkan transaksi yang mengandung, dan tugas paralel tambahan tidak terkecuali. Mereka tidak dapat membagikan transaksi induk (basis) secara langsung, jadi transaksi bersarang digunakan. Saat tugas paralel perlu mengakses transaksi dasar, tugas tersebut akan disinkronkan pada gerendel, dan mungkin menemukanNESTING_TRANSACTION_READONLYatauNESTING_TRANSACTION_FULLmenunggu. - Mendaftarkan thread pekerja saat ini dengan port pertukaran (
CXPort::Register). - Menyinkronkan dengan utas lain di sisi konsumen pertukaran (
sqlmin!CXTransLocal::Synchronize). Tidak ada rangkaian pesan lain di sisi konsumen dari aliran pengumpulan, jadi pada dasarnya ini adalah larangan pada kesempatan ini.
Pemrosesan “Fase Awal”
Tugas induk sekarang telah mencapai tepi Cabang A. Langkah selanjutnya adalah khusus ke paket paralel mode baris:Tugas induk melanjutkan eksekusi dengan memanggil CQScanExchangeNew::EarlyPhases pada iterator pertukaran aliran berkumpul di node 2. Ini adalah metode iterator tambahan di luar Open biasa , GetRow , dan Close metode yang banyak dari Anda akan terbiasa. EarlyPhases hanya dipanggil dalam rencana paralel mode baris.
Saya ingin memperjelas sesuatu pada saat ini:Sisi produsen dari pertukaran aliran berkumpul di simpul 2 tidak belum dibuat, dan tidak tugas paralel tambahan telah dibuat. Kami masih mengeksekusi kode untuk tugas induk, menggunakan satu-satunya utas yang berjalan saat ini.
Tidak semua iterator mengimplementasikan EarlyPhases , karena tidak semua dari mereka memiliki sesuatu yang istimewa untuk dilakukan pada saat ini dalam rencana paralel mode baris. Ini analog dengan proyek urutan yang tidak mengimplementasikan Open metode karena tidak ada hubungannya pada waktu itu. Iterator utama dengan EarlyPhases caranya adalah:
CQScanConcatNew(penggabungan).CQScanMergeJoinNew(gabung gabung).CQScanSwitchNew(beralih).CQScanExchangeNew(paralelisme).CQScanNew(akses rowset, misalnya memindai dan mencari).CQScanProfileNew(profiler tak terlihat).CQScanLightProfileNew(profiler ringan tak terlihat).
Fase awal Cabang B
Tugas induk lanjutkan dengan memanggil EarlyPhases pada operator anak di luar pertukaran aliran berkumpul di node 2. Tugas yang bergerak melewati batas cabang mungkin tampak tidak biasa, tetapi ingat konteks eksekusi nol berisi seluruh rencana serial, dengan pertukaran disertakan. Pemrosesan fase awal adalah tentang menginisialisasi paralelisme, sehingga tidak dihitung sebagai eksekusi per se .
Untuk membantu Anda melacak, gambar di bawah ini menunjukkan iterator di Cabang B dari rencana:
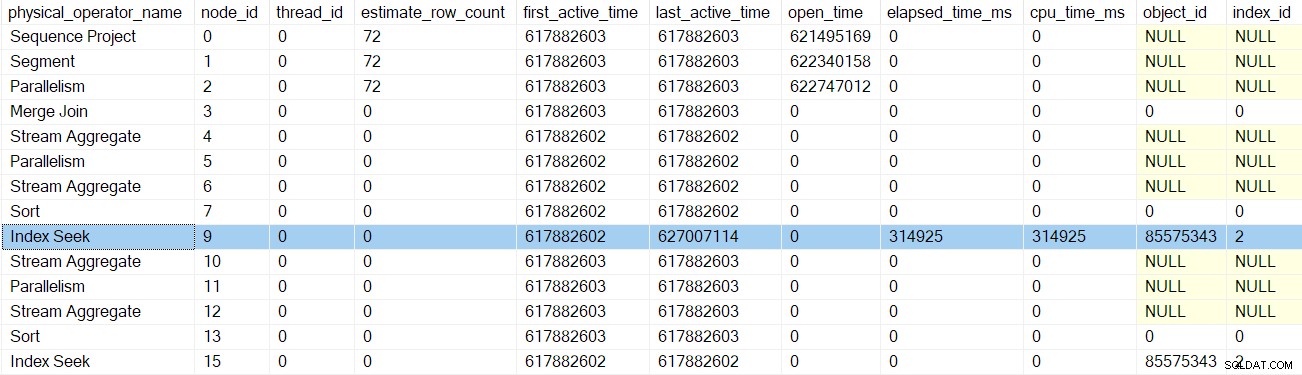
Ingat, kita masih dalam konteks eksekusi nol, jadi saya hanya menyebut ini sebagai Cabang B untuk kenyamanan. Kami belum memulai belum ada eksekusi paralel.
Urutan pemanggilan kode fase awal di Cabang B adalah:
CQScanProfileNew::EarlyPhasesuntuk profiler di atas simpul 3.CQScanMergeJoinNew::EarlyPhasesdi simpul 3 gabung gabung .CQScanProfileNew::EarlyPhasesuntuk profiler di atas simpul 4. Simpul 4 agregasi aliran sendiri tidak memiliki metode fase awal.CQScanProfileNew::EarlyPhasespada profiler di atas simpul 5.CQScanExchangeNew::EarlyPhasesuntuk aliran partisi ulang pertukaran di simpul 5.
Perhatikan bahwa kami hanya memproses input luar (atas) ke gabungan gabungan pada tahap ini. Ini hanya urutan iteratif eksekusi mode baris normal. Ini tidak khusus untuk rencana paralel.
Fase awal Cabang C
Pemrosesan fase awal berlanjut dengan iterator di Cabang C:

Urutan panggilan di sini adalah:
CQScanProfileNew::EarlyPhasesuntuk profiler di atas simpul 6.CQScanProfileNew::EarlyPhasesuntuk profiler di atas simpul 7.CQScanProfileNew::EarlyPhasespada profiler di atas simpul 9.CQScanNew::EarlyPhasesuntuk pencarian indeks pada simpul 9.
Tidak ada EarlyPhases metode pada agregat aliran atau sortir. Pekerjaan yang dilakukan oleh skalar komputasi pada simpul 8 ditangguhkan (untuk diurutkan), sehingga tidak muncul di pohon pemindaian kueri, dan tidak memiliki profiler terkait.
Tentang pengaturan waktu profiler
Tugas induk pemrosesan fase awal dimulai pada pertukaran aliran berkumpul di node 2. Itu menuruni pohon pemindaian kueri, mengikuti input luar (atas) ke gabung gabungan, sampai ke pencarian indeks di node 9. Sepanjang jalan, tugas induk telah dipanggil EarlyPhases metode pada setiap iterator yang mendukungnya.
Sejauh ini tidak ada aktivitas fase awal yang diperbarui setiap saat dalam pembuatan profil DMV. Secara khusus, tidak ada iterator yang disentuh oleh pemrosesan fase awal yang memiliki 'waktu buka' yang ditetapkan. Ini masuk akal, karena pemrosesan fase awal hanya menyiapkan eksekusi paralel — operator ini akan dibuka untuk dieksekusi nanti.
Pencarian indeks pada simpul 9 adalah simpul daun – tidak memiliki anak. Tugas induk sekarang mulai kembali dari EarlyPhases yang disarangkan panggilan, naik pohon pemindaian kueri kembali ke pertukaran aliran pengumpulan.
Setiap profiler memanggil Penghitung Kinerja Kueri API saat masuk ke EarlyPhases metode, dan mereka menyebutnya lagi di jalan keluar. Selisih antara dua angka menunjukkan waktu yang berlalu untuk iterator dan semua anaknya (karena pemanggilan metode bersarang).
Setelah profiler untuk pencarian indeks kembali, DMV profiler menunjukkan waktu yang telah berlalu dan CPU untuk pencarian indeks saja, serta terakhir aktif . yang diperbarui waktu. Perhatikan juga bahwa informasi ini dicatat berdasarkan tugas induk (satu-satunya pilihan saat ini):
Tak satu pun dari iterator sebelumnya yang disentuh oleh panggilan fase awal telah melewati waktu, atau memperbarui waktu aktif terakhir. Angka-angka ini hanya diperbarui ketika kita naik ke pohon.
Setelah fase awal profiler berikutnya, panggilan kembali, sort waktu diperbarui:
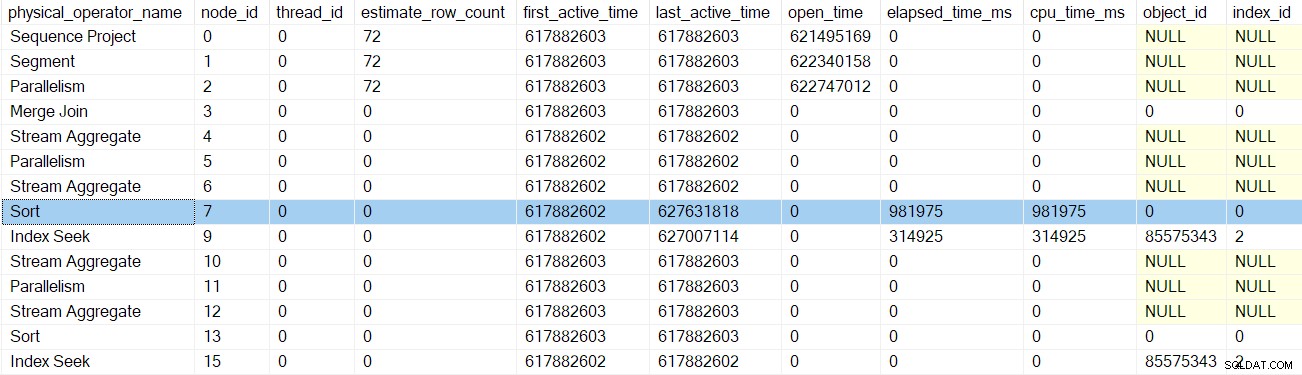
Pengembalian berikutnya membawa kita melewati profiler untuk agregat aliran di simpul 6:
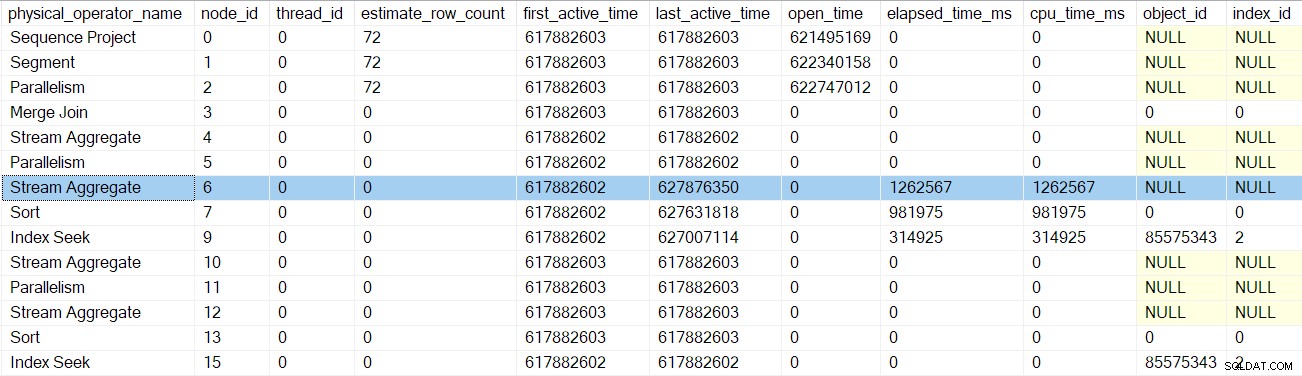
Kembali dari profiler ini membawa kita kembali ke EarlyPhases panggil di aliran partisi ulang pertukaran di simpul 5 . Ingatlah bahwa ini bukan tempat urutan panggilan fase awal dimulai — itu adalah pertukaran aliran berkumpul di node 2.
Tugas Paralel Cabang C Diantrekan
Selain memperbarui data pembuatan profil, panggilan fase awal sebelumnya tampaknya tidak terlalu berpengaruh. Itu semua berubah dengan aliran partisi ulang pertukaran di simpul 5.
Saya akan menjelaskan Cabang C dengan cukup detail untuk memperkenalkan sejumlah konsep penting, yang juga akan berlaku untuk cabang paralel lainnya. Menutupi dasar ini sekali sekarang berarti diskusi cabang nanti bisa lebih ringkas.
Setelah menyelesaikan pemrosesan fase awal bersarang untuk subpohonnya (hingga pencarian indeks di node 9), pertukaran dapat memulai pekerjaan fase awalnya sendiri. Ini dimulai sama dengan pembukaan pertukaran aliran berkumpul di simpul 2:
CXTransLocal::Open(membuka sub-transaksi paralel lokal).CXPort::Register(mendaftar dengan port pertukaran).
Langkah selanjutnya berbeda karena cabang C berisi pemblokiran fully sepenuhnya iterator (pengurutan pada node 7). Pemrosesan fase awal pada aliran partisi ulang node 5 melakukan hal berikut:
- Panggilan
CQScanExchangeNew::StartAllProducers. Ini adalah pertama kalinya kami menemukan sesuatu yang merujuk pada sisi produsen dari pertukaran. Node 5 adalah pertukaran pertama dalam rencana ini untuk menciptakan sisi produsennya. - Memperoleh mutex jadi tidak ada utas lain yang dapat mengantrekan tugas secara bersamaan.
- Memulai transaksi bertingkat paralel untuk tugas produser (
CXPort::StartNestedTransactionsdanReadOnlyXactImp::BeginParallelNestedXact). - Mendaftarkan sub-transaksi dengan objek pemindaian kueri induk (
CQueryScan::AddSubXact). - Membuat deskriptor produser (
CQScanExchangeNew::PxproddescCreate). - Membuat konteks eksekusi produsen baru (
CExecContext) diturunkan dari konteks eksekusi nol. - Memperbarui peta iterator rencana yang ditautkan.
- Menetapkan DOP untuk konteks baru (
CQueryExecContext::SetDop) sehingga semua tugas mengetahui pengaturan DOP secara keseluruhan. - Menginisialisasi cache parameter (
CQueryExecContext::InitParamCache). - Menghubungkan transaksi bertingkat paralel ke transaksi dasar (
CExecContext::SetBaseXact). - Mengantrekan sub-proses baru untuk dieksekusi (
SubprocessMgr::EnqueueMultipleSubprocesses). - Membuat tugas paralel baru tugas melalui
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
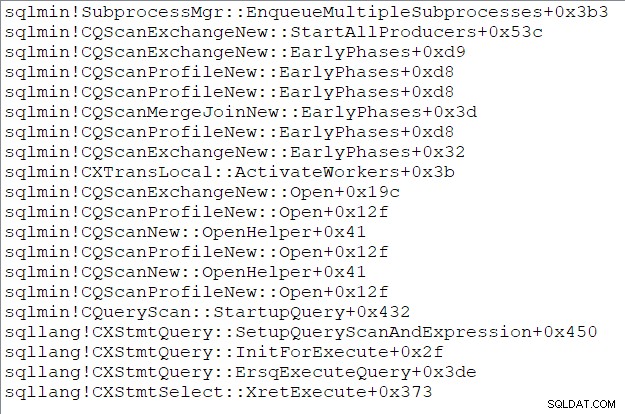
Tumpukan panggilan tugas induk (bagi Anda yang menyukai hal-hal ini) pada saat ini adalah:
Akhir Bagian Ketiga
Kami sekarang telah membuat sisi produsen dari pertukaran aliran partisi ulang di node 5, membuat tugas paralel tambahan untuk menjalankan Cabang C, dan menautkan semuanya kembali ke induk struktur sesuai kebutuhan. Cabang C adalah yang pertama cabang untuk memulai tugas paralel apa pun. Bagian terakhir dari seri ini akan melihat pembukaan cabang C secara detail, dan memulai tugas paralel yang tersisa.