Penulis Tamu :Michael J Swart (@MJSwart)
Saya menghabiskan banyak waktu menerjemahkan persyaratan perangkat lunak ke dalam skema dan kueri. Persyaratan ini terkadang mudah diterapkan tetapi seringkali sulit. Saya ingin berbicara tentang pilihan desain UI yang mengarah pada pola akses data yang canggung untuk diterapkan menggunakan SQL Server.
Urutkan Berdasarkan Kolom
Sort-By-Column adalah pola yang begitu akrab sehingga kita dapat menerima begitu saja. Setiap kali kita berinteraksi dengan perangkat lunak yang menampilkan tabel, kita dapat mengharapkan kolom dapat diurutkan seperti ini:
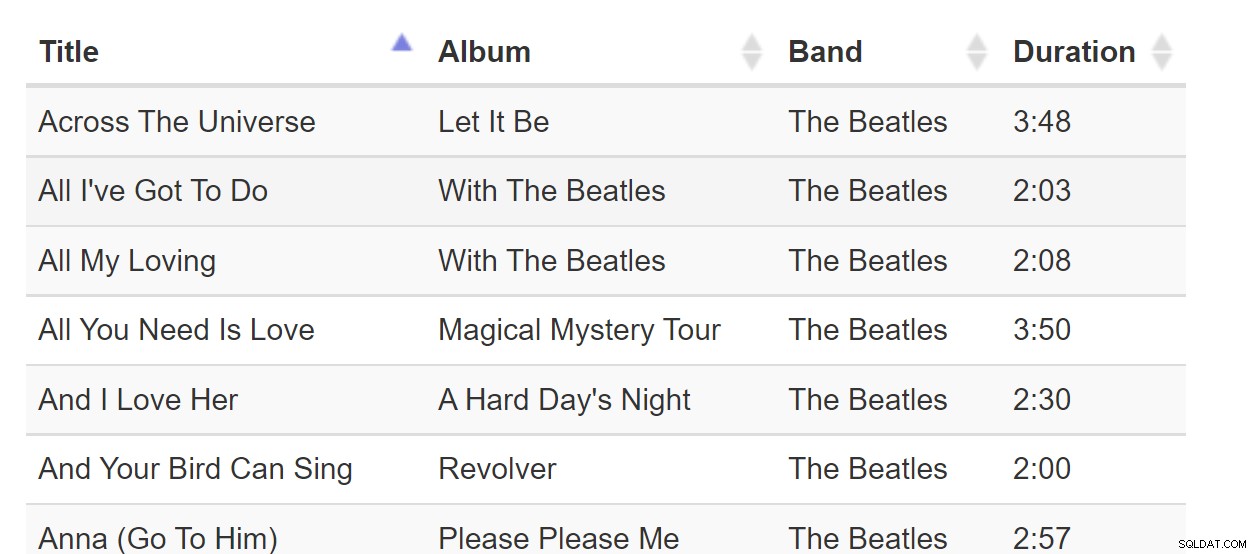
Sort-By-Colunn adalah pola yang bagus ketika semua data bisa muat di browser. Tetapi jika kumpulan data berukuran miliaran baris, ini bisa menjadi canggung bahkan jika halaman web hanya membutuhkan satu halaman data. Pertimbangkan daftar lagu ini:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); Dan pertimbangkan empat kueri berikut yang diurutkan berdasarkan setiap kolom:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
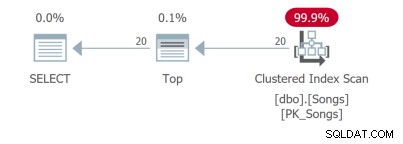
Bahkan untuk kueri sesederhana ini, ada rencana kueri yang berbeda. Dua kueri pertama menggunakan indeks penutup:
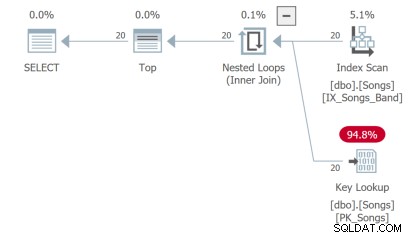
Kueri ketiga perlu melakukan pencarian kunci yang tidak ideal:
Tetapi yang terburuk adalah kueri keempat yang perlu memindai seluruh tabel dan melakukan pengurutan untuk mengembalikan 20 baris pertama:
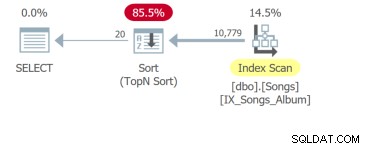
Intinya adalah bahwa meskipun satu-satunya perbedaan adalah klausa ORDER BY, kueri tersebut harus dianalisis secara terpisah. Unit dasar penyetelan SQL adalah kueri. Jadi, jika Anda menunjukkan kepada saya persyaratan UI dengan sepuluh kolom yang dapat diurutkan, saya akan menunjukkan kepada Anda sepuluh kueri untuk dianalisis.
Kapan ini menjadi canggung?
Fitur Sort-By-Column adalah pola UI yang bagus, tetapi bisa menjadi canggung jika data berasal dari tabel besar yang berkembang dengan banyak kolom. Mungkin tergoda untuk membuat indeks penutup di setiap kolom, tetapi itu memiliki pengorbanan lain. Indeks Columnstore dapat membantu dalam beberapa keadaan, tetapi itu menimbulkan tingkat kecanggungan lain. Tidak selalu ada alternatif yang mudah.
Hasil Berhalaman
Menggunakan hasil halaman adalah cara yang baik untuk tidak membanjiri pengguna dengan terlalu banyak informasi sekaligus. Ini juga merupakan cara yang baik untuk tidak membanjiri server database ... biasanya.
Pertimbangkan desain ini:

Data di balik contoh ini memerlukan penghitungan dan pemrosesan seluruh kumpulan data untuk melaporkan jumlah hasil. Kueri untuk contoh ini mungkin menggunakan sintaks seperti ini:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Sintaksnya nyaman, dan kueri hanya menghasilkan 25 baris. Tapi hanya karena set hasilnya kecil, bukan berarti murah. Seperti yang kita lihat pada pola Sort-By-Column, operator TOP hanya murah jika tidak perlu mengurutkan banyak data terlebih dahulu.
Permintaan Laman Asinkron
Saat pengguna menavigasi dari satu halaman hasil ke halaman berikutnya, permintaan web yang terlibat dapat dipisahkan oleh detik atau menit. Ini mengarah pada masalah yang sangat mirip dengan jebakan yang terlihat saat menggunakan NOLOCK. Misalnya:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Saat baris ditambahkan di antara dua permintaan, pengguna mungkin melihat baris yang sama dua kali. Dan jika satu baris dihapus, pengguna mungkin melewatkan satu baris saat mereka menavigasi halaman. Pola Paged-Results ini setara dengan "Beri saya baris 26-50". Ketika pertanyaan sebenarnya adalah "Beri saya 25 baris berikutnya". Perbedaannya tidak kentara.
Pola Lebih Baik
Dengan Paged-Results, "OFFSET @N ROWS" itu bisa memakan waktu lebih lama dan lebih lama saat @N tumbuh. Alih-alih, pertimbangkan tombol Muat-Lainnya atau Pengguliran Tak Terbatas. Dengan paging Load-More, setidaknya ada peluang untuk menggunakan indeks secara efisien. Kueri akan terlihat seperti:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Itu masih mengalami beberapa jebakan permintaan halaman asinkron, tetapi karena bookmark, pengguna akan melanjutkan dari tempat terakhir mereka tinggalkan.
Mencari Teks Untuk Substring
Pencarian ada di mana-mana di internet. Tapi solusi apa yang harus digunakan di bagian belakang? Saya ingin memperingatkan agar tidak mencari substring menggunakan filter LIKE SQL Server dengan wildcard seperti ini:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Ini dapat menyebabkan hasil yang canggung seperti ini:
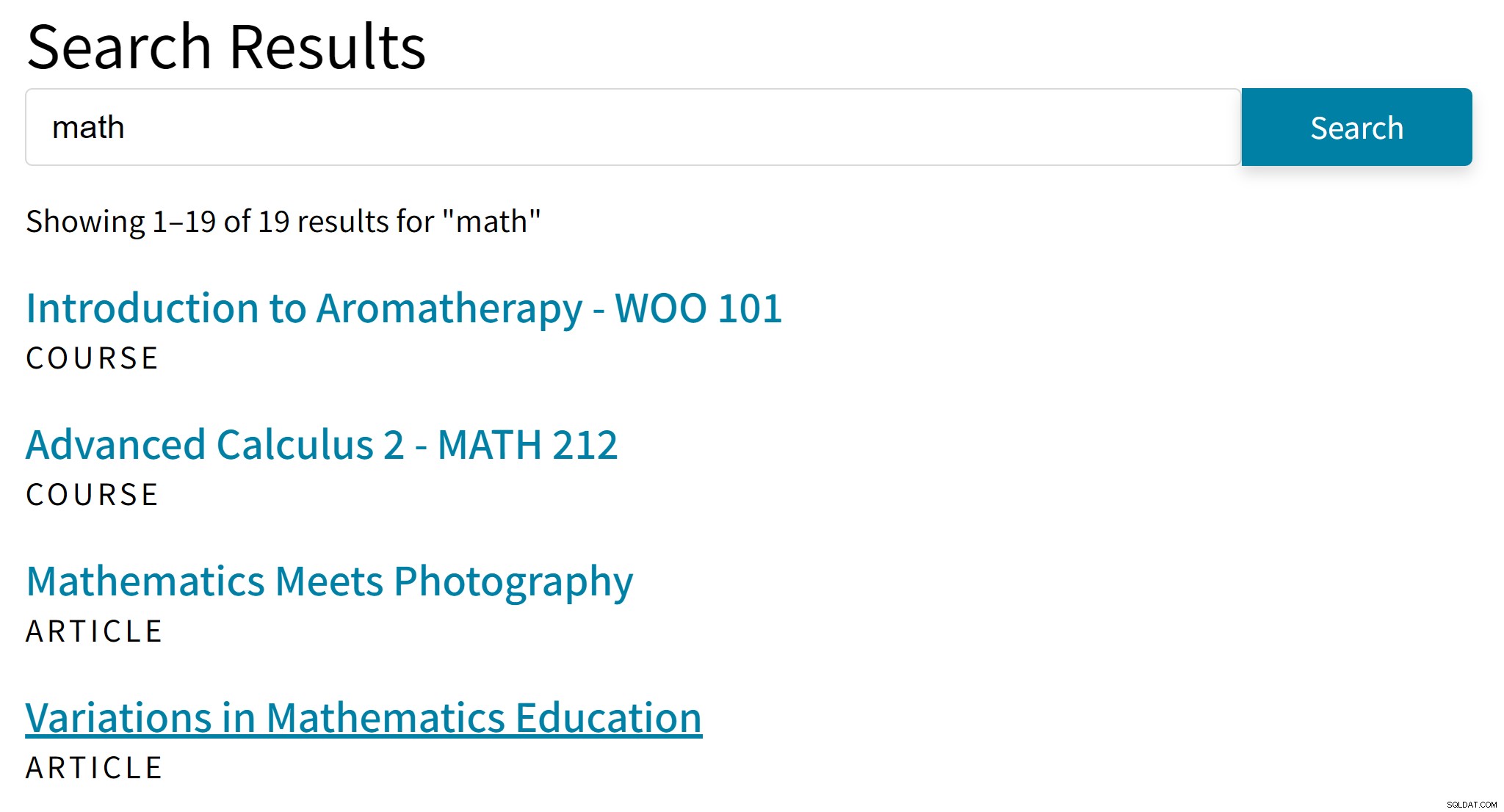
"Aromaterapi" mungkin bukan hit yang bagus untuk istilah pencarian "matematika." Sementara itu, hasil pencarian tidak menemukan artikel yang hanya menyebutkan Aljabar atau Trigonometri.
Ini juga bisa sangat sulit untuk dilakukan secara efisien menggunakan SQL Server. Tidak ada indeks langsung yang mendukung pencarian semacam ini. Paul White memberikan satu solusi rumit dengan Trigram Wildcard String Search di SQL Server. Ada juga kesulitan yang dapat terjadi dengan collation dan Unicode. Ini bisa menjadi solusi mahal untuk pengalaman pengguna yang tidak terlalu bagus.
Apa yang Harus Digunakan Sebagai gantinya
Pencarian Teks Lengkap SQL Server sepertinya bisa membantu, tapi saya pribadi tidak pernah menggunakannya. Dalam praktiknya, saya hanya melihat keberhasilan dalam solusi di luar SQL Server (mis. Elasticsearch).
Kesimpulan
Dalam pengalaman saya, saya telah menemukan bahwa perancang perangkat lunak seringkali sangat menerima umpan balik bahwa desain mereka terkadang canggung untuk diterapkan. Ketika tidak, saya merasa berguna untuk menyoroti jebakan, biaya, dan waktu pengiriman. Umpan balik semacam itu diperlukan untuk membantu membangun solusi yang skalabel dan dapat dipelihara.
Tentang Penulis
 Michael J Swart adalah profesional database dan blogger yang bersemangat yang berfokus pada pengembangan database dan arsitektur perangkat lunak. Dia senang berbicara tentang apa pun yang terkait dengan data, berkontribusi pada proyek komunitas. Michael blog sebagai "Database Whisperer" di michaeljswart.com.
Michael J Swart adalah profesional database dan blogger yang bersemangat yang berfokus pada pengembangan database dan arsitektur perangkat lunak. Dia senang berbicara tentang apa pun yang terkait dengan data, berkontribusi pada proyek komunitas. Michael blog sebagai "Database Whisperer" di michaeljswart.com.