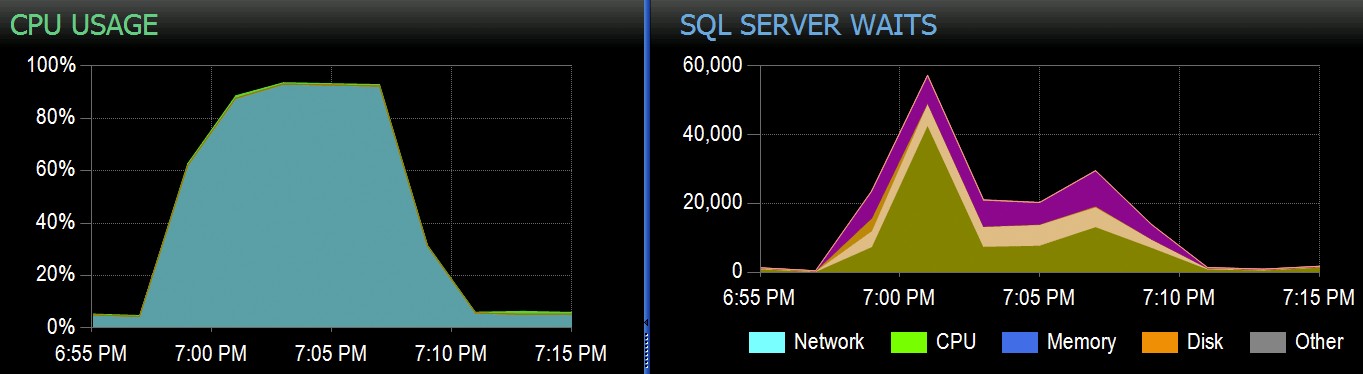
Di Stack Overflow, kami memiliki beberapa tabel yang menggunakan indeks penyimpanan kolom berkerumun, dan ini berfungsi dengan baik untuk sebagian besar beban kerja kami. Tetapi kami baru-baru ini menemukan situasi di mana "badai sempurna" — beberapa proses yang semuanya mencoba untuk menghapus dari CCI yang sama — akan membanjiri CPU karena semuanya berjalan paralel dan berjuang untuk menyelesaikan operasinya. Berikut tampilannya di SolarWinds SQL Sentry:
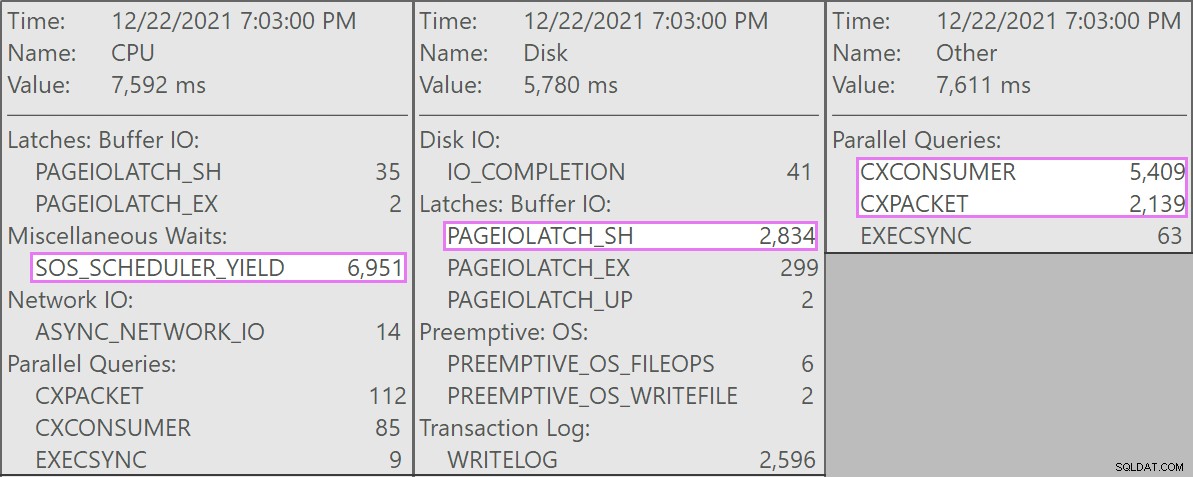
Dan inilah penantian menarik yang terkait dengan pertanyaan ini:
Kueri yang bersaing semuanya berbentuk ini:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
Rencananya terlihat seperti ini:

Dan peringatan pada pemindaian memberi tahu kami tentang beberapa I/O sisa yang cukup ekstrem:

Tabel memiliki 1,9 miliar baris tetapi hanya 32GB (terima kasih, penyimpanan kolom!). Namun, penghapusan satu baris ini akan memakan waktu masing-masing 10 – 15 detik, dengan sebagian besar waktu ini dihabiskan untuk SOS_SCHEDULER_YIELD .
Untungnya, karena dalam skenario ini operasi penghapusan bisa jadi tidak sinkron, kami dapat menyelesaikan masalah dengan dua perubahan (meskipun saya terlalu menyederhanakannya di sini):
- Kami membatasi
MAXDOPdi tingkat basis data sehingga penghapusan ini tidak dapat dilakukan secara paralel - Kami meningkatkan serialisasi proses yang berasal dari aplikasi (pada dasarnya, kami mengantrekan penghapusan melalui satu operator)
Sebagai DBA, kita dapat dengan mudah mengontrol MAXDOP , kecuali jika diganti di tingkat kueri (lubang kelinci lain untuk hari lain). Kami tidak serta merta dapat mengontrol aplikasi sejauh ini, terutama jika itu didistribusikan atau bukan milik kami. Bagaimana kita bisa membuat serial penulisan dalam kasus ini tanpa mengubah logika aplikasi secara drastis?
Pengaturan Mock
Saya tidak akan mencoba membuat tabel dua miliar baris secara lokal — apalagi tabel persisnya — tetapi kita dapat memperkirakan sesuatu dalam skala yang lebih kecil dan mencoba mereproduksi masalah yang sama.
Anggap saja ini SuggestedEdits tabel (pada kenyataannya, tidak). Tetapi ini adalah contoh yang mudah digunakan karena kami dapat menarik skema dari Stack Exchange Data Explorer. Dengan menggunakan ini sebagai dasar, kita dapat membuat tabel yang setara (dengan beberapa perubahan kecil untuk membuatnya lebih mudah untuk diisi) dan melemparkan indeks penyimpanan kolom berkerumun di atasnya:
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Untuk mengisinya dengan 100 juta baris, kita dapat melakukan cross join sys.all_objects dan sys.all_columns lima kali (di sistem saya, ini akan menghasilkan 2,68 juta baris setiap kali, tetapi YMMV):
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
Kemudian, kita dapat memeriksa spasi:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
Ini hanya 1,3 GB, tapi ini sudah cukup:

Meniru Penghapusan Clustered Columnstore Kami
Berikut ini kueri sederhana yang kira-kira cocok dengan apa yang dilakukan aplikasi kami dengan tabel:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
Namun, rencananya tidak terlalu cocok:
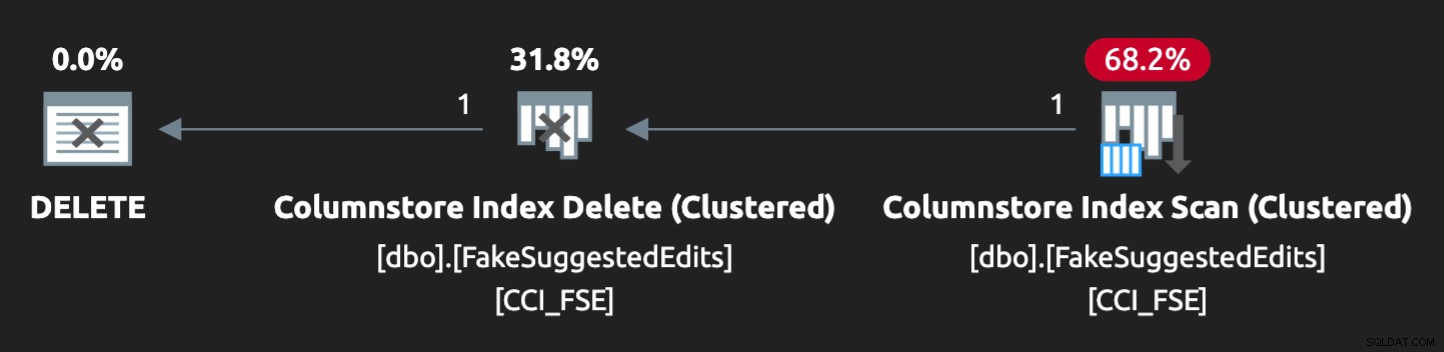
Untuk membuatnya paralel dan menghasilkan pertentangan serupa di laptop saya yang kecil, saya harus sedikit memaksa pengoptimal dengan petunjuk ini:
OPTION (QUERYTRACEON 8649);
Sekarang, sepertinya benar:

Mereproduksi Masalah
Kemudian, kita dapat membuat lonjakan aktivitas penghapusan bersamaan menggunakan SqlStressCmd untuk menghapus 1.000 baris acak menggunakan 16 dan 32 utas:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
Kita dapat mengamati tekanan yang ditimbulkan pada CPU:
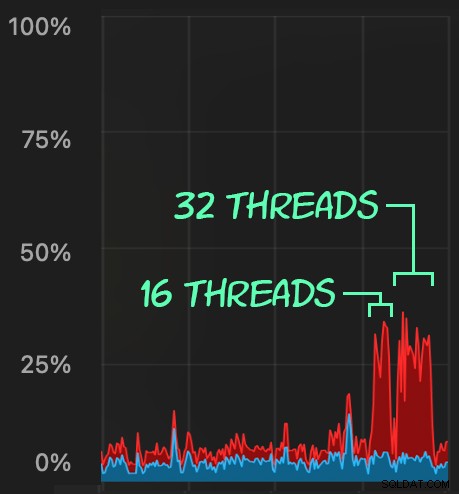
Ketegangan pada CPU berlangsung sepanjang batch masing-masing sekitar 64 dan 130 detik:
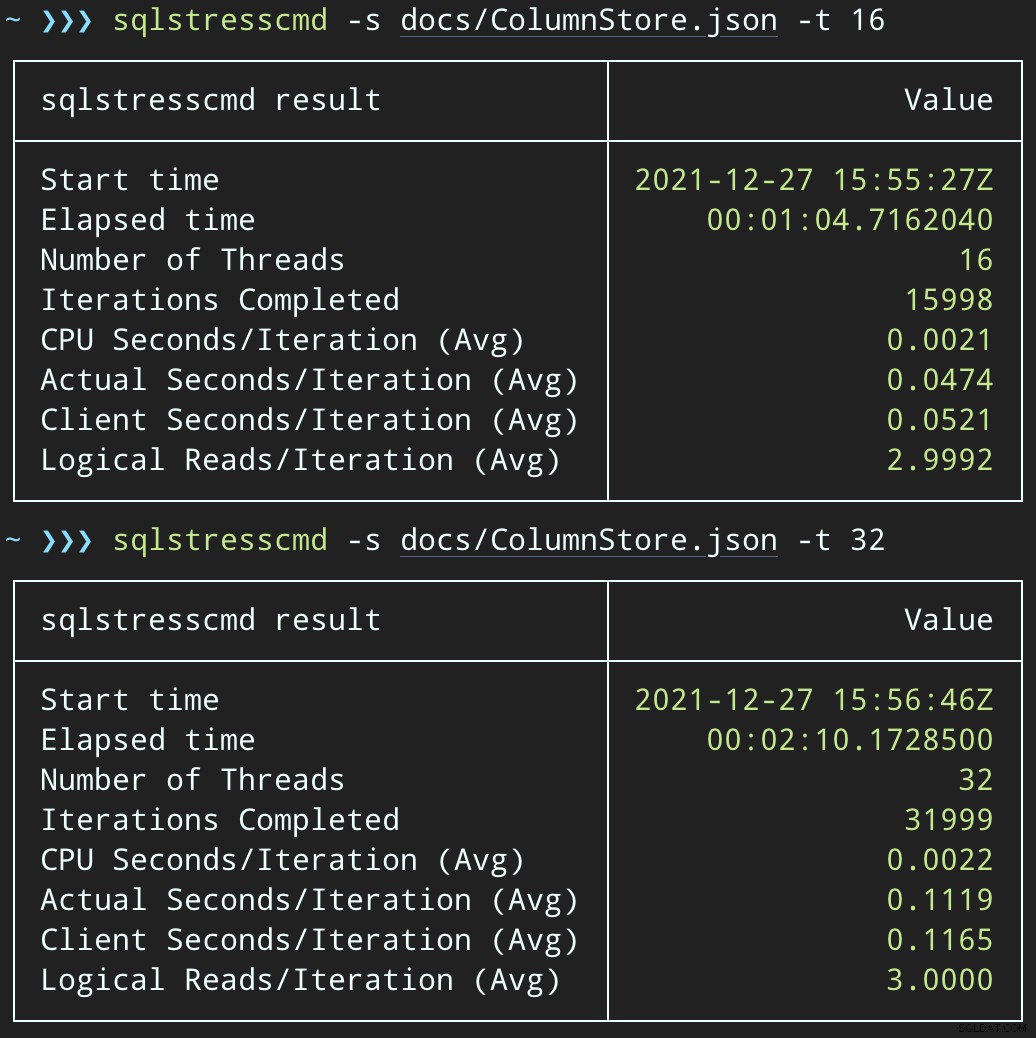
Catatan:Keluaran dari SQLQueryStress terkadang sedikit kurang baik pada iterasi, tetapi saya telah mengonfirmasi bahwa pekerjaan yang Anda minta diselesaikan dengan tepat.
Penanganan Potensial:Antrian Penghapusan
Awalnya, saya berpikir untuk memperkenalkan tabel antrian di database, yang bisa kita gunakan untuk menghapus aktivitas penghapusan:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Yang kita butuhkan hanyalah pemicu BUKAN untuk mencegat penghapusan jahat ini yang berasal dari aplikasi dan menempatkannya pada antrian untuk pemrosesan latar belakang. Sayangnya, Anda tidak dapat membuat pemicu pada tabel dengan indeks penyimpanan kolom tergugus:
Pesan 35358, Level 16, Status 1BUAT PEMICU pada tabel 'dbo.FakeSuggestedEdits' gagal karena Anda tidak dapat membuat pemicu pada tabel dengan indeks penyimpanan kolom tergugus. Pertimbangkan untuk menerapkan logika pemicu dengan cara lain, atau jika Anda harus menggunakan pemicu, gunakan heap atau indeks B-tree sebagai gantinya.
Kita memerlukan sedikit perubahan pada kode aplikasi, sehingga memanggil prosedur tersimpan untuk menangani penghapusan:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
Ini bukan keadaan permanen; ini hanya untuk menjaga perilaku tetap sama saat hanya mengubah satu hal di aplikasi. Setelah aplikasi diubah dan berhasil memanggil prosedur tersimpan ini alih-alih mengirimkan kueri penghapusan ad hoc, prosedur tersimpan dapat berubah:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
Menguji Dampak Antrian
Sekarang, jika kita mengubah SqlQueryStress untuk memanggil prosedur tersimpan sebagai gantinya:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
Dan kirimkan kumpulan yang serupa (menempatkan 16 ribu atau 32 ribu baris pada antrean):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
Dampak CPU sedikit lebih tinggi:
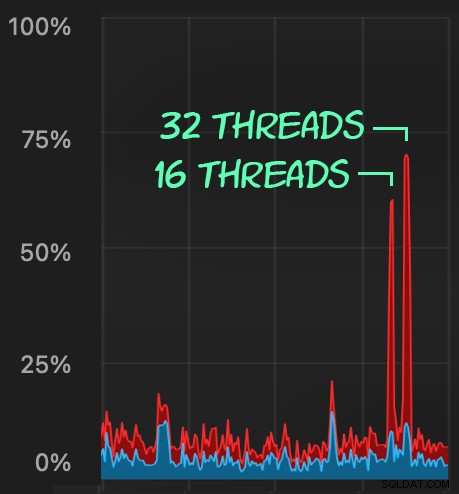
Namun beban kerja selesai jauh lebih cepat — masing-masing 16 dan 23 detik:
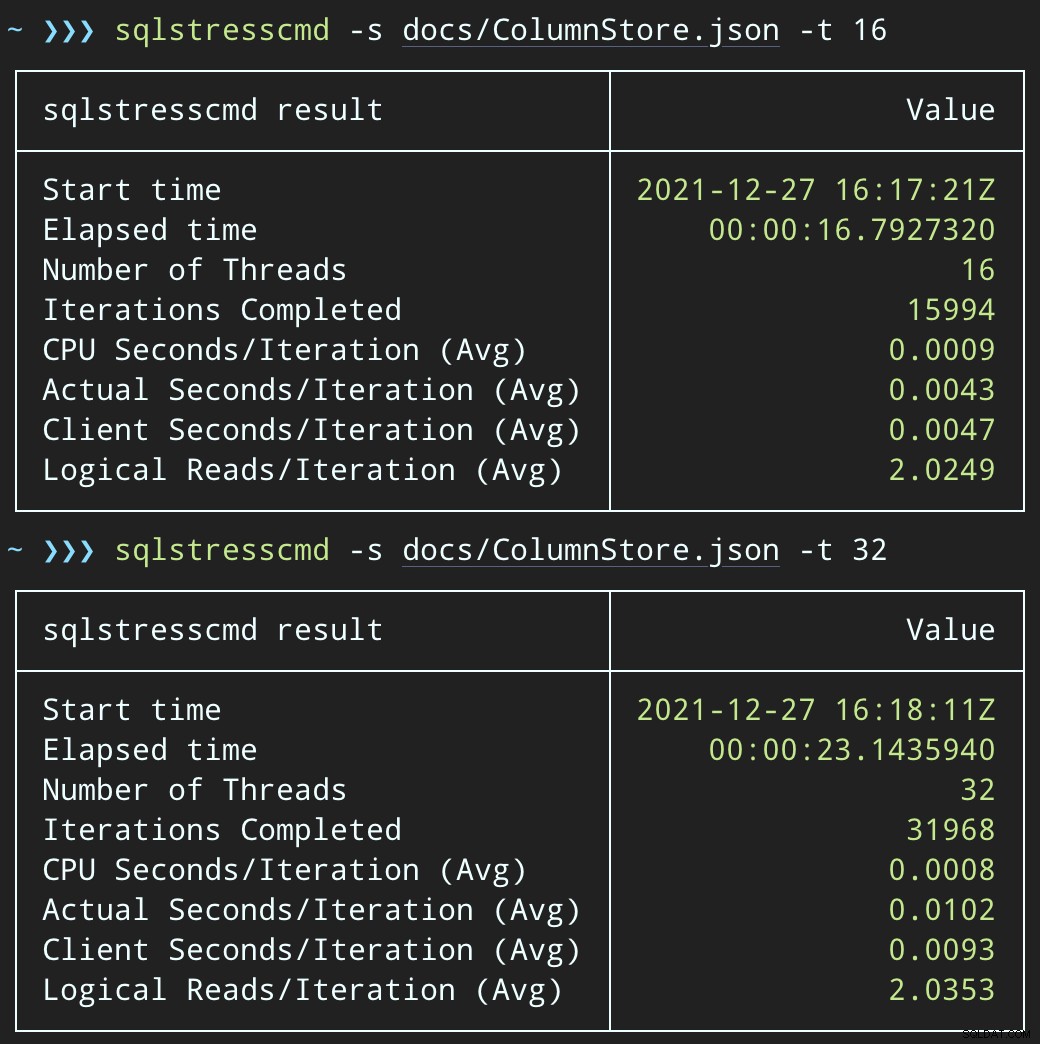
Ini adalah pengurangan yang signifikan dalam rasa sakit yang akan dirasakan aplikasi saat mereka memasuki periode konkurensi tinggi.
Kami Masih Harus Melakukan Penghapusan, Meskipun
Kami masih harus memproses penghapusan tersebut di latar belakang, tetapi kami sekarang dapat memperkenalkan batching dan memiliki kontrol penuh atas laju dan penundaan yang ingin kami masukkan di antara operasi. Berikut adalah struktur paling dasar dari prosedur tersimpan untuk memproses antrian (diakui tanpa kontrol transaksional sepenuhnya, penanganan kesalahan, atau pembersihan tabel antrian):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
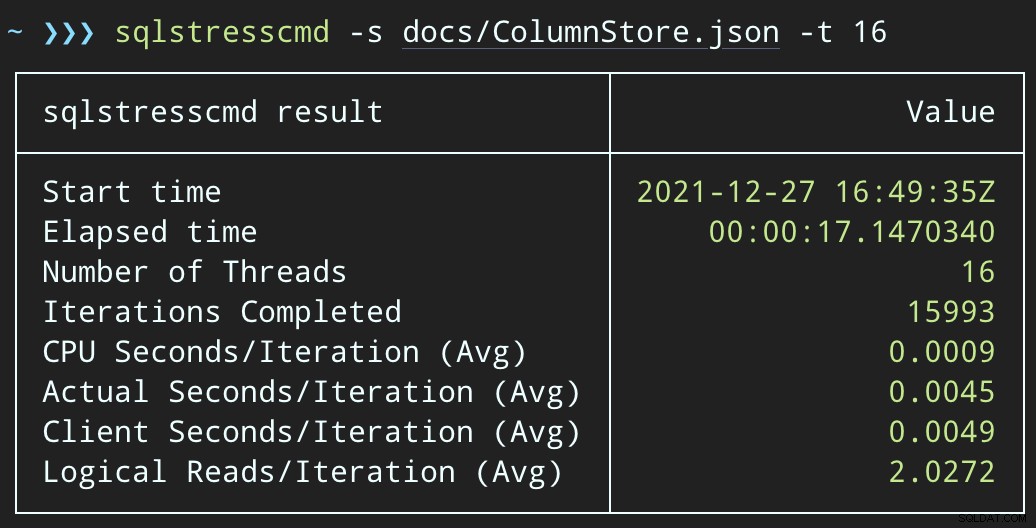
END Sekarang, menghapus baris akan memakan waktu lebih lama — rata-rata untuk 10.000 baris adalah 223 detik, ~100 di antaranya adalah penundaan yang disengaja. Tapi tidak ada pengguna yang menunggu, jadi siapa yang peduli? Profil CPU hampir nol, dan aplikasi dapat terus menambahkan item pada antrean secara bersamaan seperti yang diinginkan, dengan hampir nol konflik dengan pekerjaan latar belakang. Saat memproses 10.000 baris, saya menambahkan 16 ribu baris lagi ke antrean, dan menggunakan CPU yang sama seperti sebelumnya — hanya membutuhkan waktu satu detik lebih lama daripada saat pekerjaan tidak berjalan:
Dan rencananya sekarang terlihat seperti ini, dengan perkiraan / baris aktual yang jauh lebih baik:
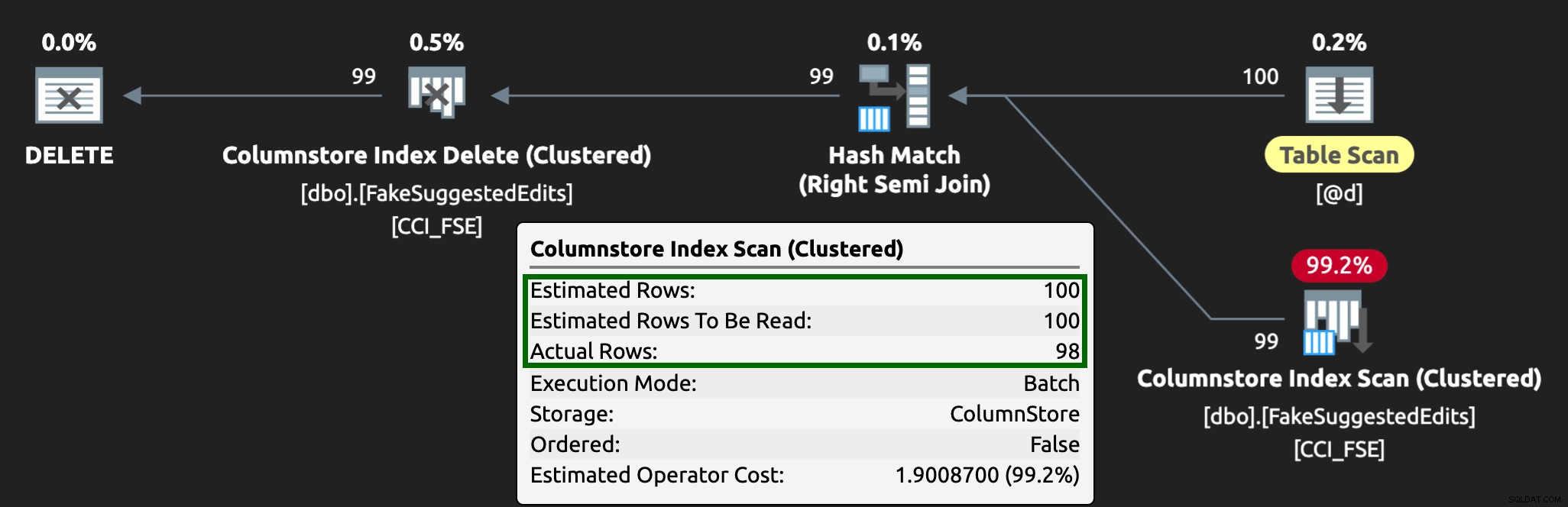
Saya dapat melihat pendekatan tabel antrian ini sebagai cara yang efektif untuk menangani konkurensi DML yang tinggi, tetapi ini membutuhkan setidaknya sedikit fleksibilitas dengan aplikasi yang mengirimkan DML — ini adalah salah satu alasan saya sangat suka aplikasi memanggil prosedur tersimpan, karena mereka memberi kami lebih banyak kontrol lebih dekat ke data.
Opsi Lain
Jika Anda tidak memiliki kemampuan untuk mengubah kueri penghapusan yang berasal dari aplikasi — atau, jika Anda tidak dapat menunda penghapusan ke proses latar belakang — Anda dapat mempertimbangkan opsi lain untuk mengurangi dampak penghapusan:
- Indeks nonclustered pada kolom predikat untuk mendukung pencarian titik (kita dapat melakukan ini secara terpisah tanpa mengubah aplikasi)
- Hanya menggunakan penghapusan lunak (masih memerlukan perubahan pada aplikasi)
Akan menarik untuk melihat apakah opsi ini menawarkan manfaat yang serupa, tetapi saya akan menyimpannya untuk postingan mendatang.