Di Bagian 5 dari seri ekspresi tabel saya, saya memberikan solusi berikut untuk menghasilkan serangkaian angka menggunakan CTE, konstruktor nilai tabel, dan gabungan silang:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Ada banyak kasus penggunaan praktis untuk alat semacam itu, termasuk menghasilkan serangkaian nilai tanggal dan waktu, membuat data sampel, dan banyak lagi. Menyadari kebutuhan umum, beberapa platform menyediakan alat bawaan, seperti fungsi generate_series PostgreSQL. Pada saat penulisan, T-SQL tidak menyediakan alat bawaan seperti itu, tetapi orang selalu dapat berharap dan memilih alat seperti itu untuk ditambahkan di masa mendatang.
Dalam komentar di artikel saya, Marcos Kirchner menyebutkan bahwa dia menguji solusi saya dengan berbagai kardinalitas konstruktor nilai tabel, dan mendapatkan waktu eksekusi yang berbeda untuk kardinalitas yang berbeda.
 Saya selalu menggunakan solusi saya dengan kardinalitas konstruktor nilai tabel dasar 2, tetapi komentar Marcos membuat saya berpikir. Alat ini sangat berguna sehingga kita sebagai komunitas harus bergabung untuk mencoba dan membuat versi tercepat yang kita bisa. Menguji kardinalitas tabel dasar yang berbeda hanyalah satu dimensi untuk dicoba. Mungkin ada banyak lainnya. Saya akan mempresentasikan tes kinerja yang telah saya lakukan dengan solusi saya. Saya terutama bereksperimen dengan kardinalitas konstruktor nilai tabel yang berbeda, dengan pemrosesan serial versus paralel, dan dengan mode baris versus pemrosesan mode batch. Namun, bisa jadi solusi yang sama sekali berbeda bahkan lebih cepat dari versi terbaik saya. Jadi, tantangannya adalah! Saya memanggil semua jedi, padawan, penyihir dan murid sama-sama. Apa solusi berkinerja terbaik yang dapat Anda bayangkan? Apakah Anda memilikinya dalam diri Anda untuk mengalahkan solusi tercepat yang diposting sejauh ini? Jika demikian, bagikan milik Anda sebagai komentar untuk artikel ini, dan jangan ragu untuk meningkatkan solusi apa pun yang diposting oleh orang lain.
Saya selalu menggunakan solusi saya dengan kardinalitas konstruktor nilai tabel dasar 2, tetapi komentar Marcos membuat saya berpikir. Alat ini sangat berguna sehingga kita sebagai komunitas harus bergabung untuk mencoba dan membuat versi tercepat yang kita bisa. Menguji kardinalitas tabel dasar yang berbeda hanyalah satu dimensi untuk dicoba. Mungkin ada banyak lainnya. Saya akan mempresentasikan tes kinerja yang telah saya lakukan dengan solusi saya. Saya terutama bereksperimen dengan kardinalitas konstruktor nilai tabel yang berbeda, dengan pemrosesan serial versus paralel, dan dengan mode baris versus pemrosesan mode batch. Namun, bisa jadi solusi yang sama sekali berbeda bahkan lebih cepat dari versi terbaik saya. Jadi, tantangannya adalah! Saya memanggil semua jedi, padawan, penyihir dan murid sama-sama. Apa solusi berkinerja terbaik yang dapat Anda bayangkan? Apakah Anda memilikinya dalam diri Anda untuk mengalahkan solusi tercepat yang diposting sejauh ini? Jika demikian, bagikan milik Anda sebagai komentar untuk artikel ini, dan jangan ragu untuk meningkatkan solusi apa pun yang diposting oleh orang lain.
Persyaratan:
- Terapkan solusi Anda sebagai inline table-valued function (iTVF) bernama dbo.GetNumsYourName dengan parameter @low AS BIGINT dan @high AS BIGINT. Sebagai contoh, lihat yang saya kirimkan di akhir artikel ini.
- Anda dapat membuat tabel pendukung di database pengguna jika diperlukan.
- Anda dapat menambahkan petunjuk sesuai kebutuhan.
- Seperti yang disebutkan, solusinya harus mendukung pembatas tipe BIGINT, tetapi Anda dapat mengasumsikan kardinalitas deret maksimum 4.294.967.296.
- Untuk mengevaluasi kinerja solusi Anda dan membandingkannya dengan yang lain, saya akan mengujinya dengan rentang 1 hingga 100.000.000, dengan hasil Buang setelah eksekusi diaktifkan di SSMS.
Semoga berhasil untuk kita semua! Semoga komunitas terbaik menang.;)
Perbedaan kardinalitas untuk konstruktor nilai tabel dasar
Saya bereksperimen dengan berbagai kardinalitas CTE dasar, dimulai dengan 2 dan maju dalam skala logaritmik, mengkuadratkan kardinalitas sebelumnya di setiap langkah:2, 4, 16 dan 256.
Sebelum Anda mulai bereksperimen dengan kardinalitas dasar yang berbeda, akan sangat membantu jika memiliki formula yang memberikan kardinalitas dasar dan kardinalitas rentang maksimum yang akan memberi tahu Anda berapa banyak level CTE yang Anda butuhkan. Sebagai langkah awal, lebih mudah untuk terlebih dahulu membuat formula yang diberikan kardinalitas dasar dan jumlah level CTE, menghitung berapa kardinalitas rentang resultan maksimum. Berikut rumus yang diungkapkan dalam T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
Dengan nilai input sampel di atas, ekspresi ini menghasilkan kardinalitas rentang maksimum 4.294.967.296.
Kemudian, rumus kebalikan untuk menghitung jumlah level CTE yang dibutuhkan melibatkan dua fungsi log bersarang, seperti:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
Dengan nilai input sampel di atas, ekspresi ini menghasilkan 5. Perhatikan bahwa angka ini adalah tambahan untuk CTE dasar yang memiliki konstruktor nilai tabel, yang saya beri nama L0 (untuk level 0) dalam solusi saya.
Jangan tanya saya bagaimana saya mendapatkan formula ini. Cerita yang saya pegang adalah bahwa Gandalf mengucapkannya kepada saya dalam bahasa Peri dalam mimpi saya.
Mari kita lanjutkan ke pengujian kinerja. Pastikan Anda mengaktifkan Buang hasil setelah eksekusi dalam dialog Opsi Kueri SSMS Anda di bawah Kisi, Hasil. Gunakan kode berikut untuk menjalankan tes dengan kardinalitas CTE dasar 2 (membutuhkan 5 level tambahan CTE):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Saya mendapatkan rencana yang ditunjukkan pada Gambar 1 untuk eksekusi ini.
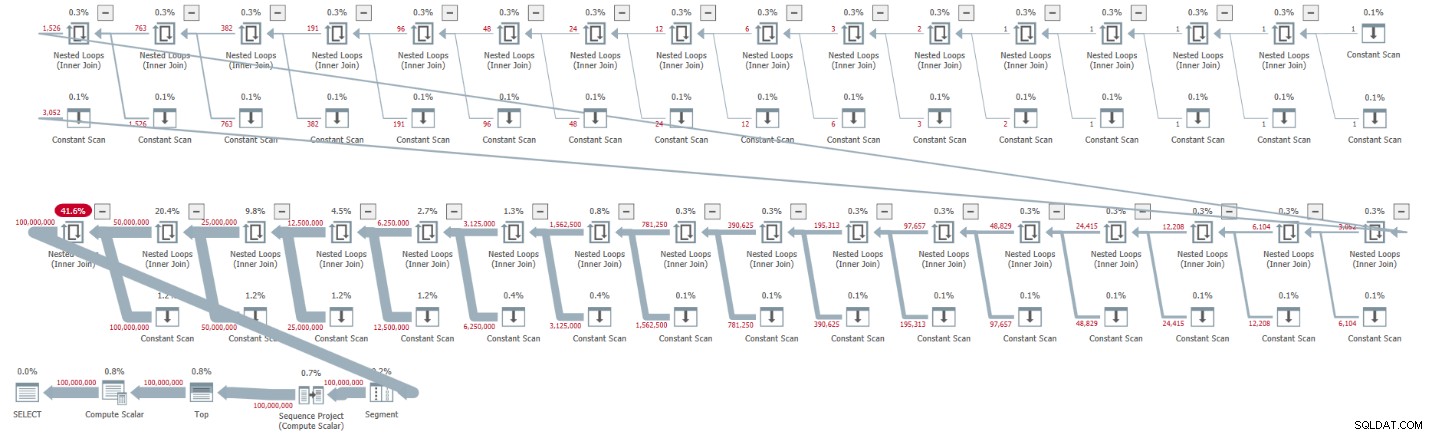 Gambar 1:Rencanakan kardinalitas CTE dasar 2
Gambar 1:Rencanakan kardinalitas CTE dasar 2
Paketnya serial, dan semua operator dalam paket menggunakan pemrosesan mode baris secara default. Jika Anda mendapatkan paket paralel secara default, mis., saat merangkum solusi dalam iTVF dan menggunakan rentang yang besar, untuk saat ini paksa paket serial dengan petunjuk MAXDOP 1.
Amati bagaimana pembongkaran CTE menghasilkan 32 instance operator Pemindaian Konstan, masing-masing mewakili tabel dengan dua baris.
Saya mendapatkan statistik kinerja berikut untuk eksekusi ini:
CPU time = 30188 ms, elapsed time = 32844 ms.
Gunakan kode berikut untuk menguji solusi dengan kardinalitas CTE dasar 4, yang menurut rumus kami memerlukan empat tingkat CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Saya mendapatkan rencana yang ditunjukkan pada Gambar 2 untuk eksekusi ini.
 Gambar 2:Rencanakan kardinalitas CTE dasar 4
Gambar 2:Rencanakan kardinalitas CTE dasar 4
Pembongkaran CTE menghasilkan 16 operator Pemindaian Konstan, masing-masing mewakili tabel 4 baris.
Saya mendapatkan statistik kinerja berikut untuk eksekusi ini:
CPU time = 23781 ms, elapsed time = 25435 ms.
Ini adalah peningkatan yang layak sebesar 22,5 persen dari solusi sebelumnya.
Memeriksa statistik menunggu yang dilaporkan untuk kueri, jenis menunggu yang dominan adalah SOS_SCHEDULER_YIELD. Memang, jumlah menunggu secara aneh turun 22,8 persen dibandingkan dengan solusi pertama (hitungan tunggu 15.280 berbanding 19.800).
Gunakan kode berikut untuk menguji solusi dengan kardinalitas CTE dasar 16, yang menurut rumus kami memerlukan tiga tingkat CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Saya mendapatkan rencana yang ditunjukkan pada Gambar 3 untuk eksekusi ini.
 Gambar 3:Rencanakan kardinalitas CTE dasar 16
Gambar 3:Rencanakan kardinalitas CTE dasar 16
Kali ini pembongkaran CTE menghasilkan 8 operator Pemindaian Konstan, masing-masing mewakili tabel dengan 16 baris.
Saya mendapatkan statistik kinerja berikut untuk eksekusi ini:
CPU time = 22968 ms, elapsed time = 24409 ms.
Solusi ini semakin mengurangi waktu yang telah berlalu, meskipun hanya dengan beberapa persen tambahan, sebesar pengurangan 25,7 persen dibandingkan dengan solusi pertama. Sekali lagi, jumlah tunggu dari jenis tunggu SOS_SCHEDULER_YIELD terus menurun (12.938).
Memajukan skala logaritmik kami, pengujian berikutnya melibatkan kardinalitas CTE dasar 256. Ini panjang dan jelek, tetapi cobalah:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Saya mendapatkan rencana yang ditunjukkan pada Gambar 4 untuk eksekusi ini.
 Gambar 4:Rencanakan kardinalitas CTE dasar 256
Gambar 4:Rencanakan kardinalitas CTE dasar 256
Kali ini pembongkaran CTE hanya menghasilkan empat operator Pemindaian Konstan, masing-masing dengan 256 baris.
Saya mendapatkan nomor kinerja berikut untuk eksekusi ini:
CPU time = 23516 ms, elapsed time = 25529 ms.
Kali ini sepertinya kinerjanya sedikit menurun dibandingkan dengan solusi sebelumnya dengan kardinalitas CTE dasar 16. Memang, jumlah tunggu dari tipe tunggu SOS_SCHEDULER_YIELD sedikit meningkat menjadi 13.176. Jadi, sepertinya kami menemukan nomor emas kami—16!
Paket paralel versus paket serial
Saya bereksperimen dengan memaksa rencana paralel menggunakan petunjuk ENABLE_PARALLEL_PLAN_PREFERENCE, tetapi akhirnya merusak kinerja. Faktanya, ketika menerapkan solusi sebagai iTVF, saya mendapatkan paket paralel di mesin saya secara default untuk rentang yang besar, dan harus memaksakan paket serial dengan petunjuk MAXDOP 1 untuk mendapatkan kinerja yang optimal.
Pemrosesan batch
Sumber daya utama yang digunakan dalam rencana untuk solusi saya adalah CPU. Mengingat bahwa pemrosesan batch adalah tentang meningkatkan efisiensi CPU, terutama ketika berhadapan dengan sejumlah besar baris, ada baiknya mencoba opsi ini. Aktivitas utama di sini yang dapat mengambil manfaat dari pemrosesan batch adalah perhitungan nomor baris. Saya menguji solusi saya dalam edisi SQL Server 2019 Enterprise. SQL Server memilih pemrosesan mode baris untuk semua solusi yang ditampilkan sebelumnya secara default. Rupanya, solusi ini tidak lulus heuristik yang diperlukan untuk mengaktifkan mode batch di rowstore. Ada beberapa cara agar SQL Server menggunakan pemrosesan batch di sini.
Opsi 1 adalah melibatkan tabel dengan indeks penyimpanan kolom dalam solusi. Anda dapat mencapai ini dengan membuat tabel dummy dengan indeks columnstore dan memperkenalkan dummy left join di kueri terluar antara Nums CTE kami dan tabel itu. Berikut definisi tabel dummy:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Kemudian revisi kueri luar terhadap Nums untuk menggunakan FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Berikut ini contoh dengan kardinalitas CTE dasar 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Saya mendapatkan rencana yang ditunjukkan pada Gambar 5 untuk eksekusi ini.
 Gambar 5:Rencanakan dengan pemrosesan batch
Gambar 5:Rencanakan dengan pemrosesan batch
Amati penggunaan operator Agregat Jendela mode batch untuk menghitung nomor baris. Perhatikan juga bahwa rencana tersebut tidak melibatkan tabel dummy. Pengoptimal mengoptimalkannya.
Keuntungan dari opsi 1 adalah ia bekerja di semua edisi SQL Server dan relevan di SQL Server 2016 atau yang lebih baru, karena operator Agregat Jendela mode batch diperkenalkan di SQL Server 2016. Kelemahannya adalah kebutuhan untuk membuat tabel dummy dan menyertakan dalam solusinya.
Opsi 2 untuk mendapatkan pemrosesan batch untuk solusi kami, asalkan Anda menggunakan edisi SQL Server 2019 Enterprise, adalah dengan menggunakan petunjuk penjelasan mandiri yang tidak berdokumen OVERRIDE_BATCH_MODE_HEURISTICS (detail dalam artikel Dmitry Pilugin), seperti ini:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); Keuntungan dari opsi 2 adalah Anda tidak perlu membuat tabel dummy dan melibatkannya dalam solusi Anda. Kelemahannya adalah Anda perlu menggunakan edisi Enterprise, gunakan minimal SQL Server 2019 di mana mode batch pada rowstore diperkenalkan, dan solusinya melibatkan penggunaan petunjuk yang tidak terdokumentasi. Untuk alasan ini, saya lebih suka opsi 1.
Berikut adalah angka performa yang saya dapatkan untuk berbagai kardinalitas CTE dasar:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
Gambar 6 memiliki perbandingan kinerja antara solusi yang berbeda:
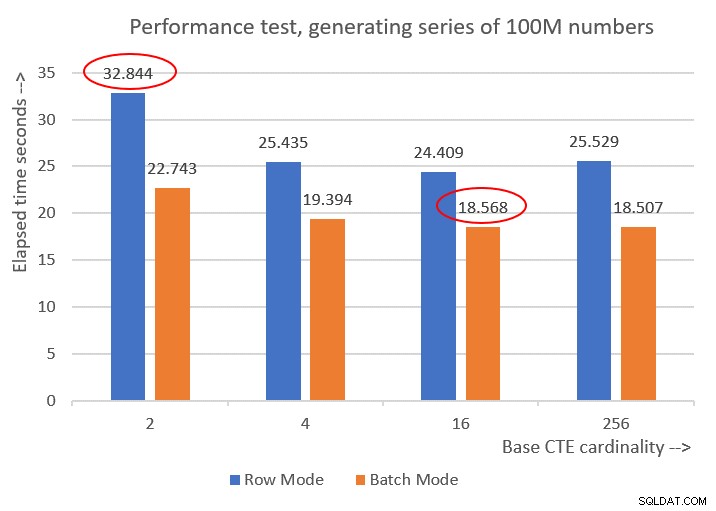 Gambar 6:Perbandingan kinerja
Gambar 6:Perbandingan kinerja
Anda dapat mengamati peningkatan kinerja yang layak sebesar 20-30 persen dibandingkan rekan mode baris.
Anehnya, dengan pemrosesan mode batch, solusi dengan kardinalitas CTE dasar 256 melakukan yang terbaik. Namun, ini hanya sedikit lebih cepat daripada solusi dengan kardinalitas CTE dasar 16. Perbedaannya sangat kecil, dan yang terakhir memiliki keuntungan yang jelas dalam hal singkatnya kode, sehingga saya akan tetap menggunakan 16.
Jadi, upaya penyetelan saya akhirnya menghasilkan peningkatan 43,5 persen dari solusi asli dengan kardinalitas dasar 2 menggunakan pemrosesan mode baris.
Tantangannya aktif!
Saya mengajukan dua solusi sebagai kontribusi komunitas saya untuk tantangan ini. Jika Anda menjalankan SQL Server 2016 atau yang lebih baru, dan dapat membuat tabel di database pengguna, buat tabel dummy berikut:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Dan gunakan definisi iTVF berikut:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Gunakan kode berikut untuk mengujinya (pastikan hasil Buang setelah eksekusi dicentang):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Kode ini selesai dalam 18 detik di mesin saya.
Jika karena alasan apa pun Anda tidak dapat memenuhi persyaratan solusi pemrosesan batch, saya mengirimkan definisi fungsi berikut sebagai solusi kedua saya:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Gunakan kode berikut untuk mengujinya:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Kode ini selesai dalam 24 detik di mesin saya.
Giliranmu!