Di Bagian 1 dan Bagian 2 dari seri ini, saya membahas aspek logis, atau konseptual, dari ekspresi tabel bernama secara umum, dan tabel turunan secara khusus. Bulan ini dan berikutnya saya akan membahas aspek pemrosesan fisik dari tabel turunan. Ingat dari Bagian 1 tentang independensi data fisik prinsip teori relasional. Model relasional dan bahasa kueri standar yang didasarkan padanya seharusnya hanya menangani aspek konseptual data dan meninggalkan detail implementasi fisik seperti penyimpanan, pengoptimalan, akses, dan pemrosesan data ke platform basis data (implementasi ). Tidak seperti perlakuan konseptual data yang didasarkan pada model matematika dan bahasa standar, dan karenanya sangat mirip dalam berbagai sistem manajemen basis data relasional di luar sana, perlakuan fisik data tidak didasarkan pada standar apa pun, dan karenanya cenderung menjadi sangat spesifik platform. Dalam liputan saya tentang perawatan fisik ekspresi tabel bernama dalam seri, saya fokus pada perawatan di Microsoft SQL Server dan Azure SQL Database. Perlakuan fisik di platform database lain bisa sangat berbeda.
Ingatlah bahwa apa yang memicu rangkaian ini adalah beberapa kebingungan yang ada di komunitas SQL Server seputar ekspresi tabel bernama. Baik dari segi terminologi maupun dari segi optimasi. Saya membahas beberapa pertimbangan terminologi dalam dua bagian pertama dari seri ini, dan akan membahas lebih lanjut di artikel mendatang ketika membahas CTE, tampilan, dan TVF sebaris. Mengenai pengoptimalan ekspresi tabel bernama, ada kebingungan di sekitar item berikut (saya menyebutkan tabel turunan di sini karena itulah fokus artikel ini):
- Kegigihan: Apakah tabel turunan bertahan di mana saja? Apakah itu bertahan di disk, dan bagaimana SQL Server menangani memori untuk itu?
- Proyeksi kolom: Bagaimana cara kerja pencocokan indeks dengan tabel turunan? Misalnya, jika tabel turunan memproyeksikan subset kolom tertentu dari beberapa tabel yang mendasarinya, dan kueri terluar memproyeksikan subset kolom dari tabel turunan, apakah SQL Server cukup pintar untuk mengetahui pengindeksan optimal berdasarkan subset akhir kolom yang sebenarnya dibutuhkan? Dan bagaimana dengan izin; apakah pengguna memerlukan izin untuk semua kolom yang direferensikan dalam kueri dalam, atau hanya ke kolom terakhir yang benar-benar dibutuhkan?
- Beberapa referensi ke alias kolom: Jika tabel turunan memiliki kolom hasil yang didasarkan pada perhitungan nondeterministik, misalnya, panggilan ke fungsi SYSDATETIME, dan kueri luar memiliki banyak referensi ke kolom itu, apakah perhitungan akan dilakukan hanya sekali, atau secara terpisah untuk setiap referensi luar ?
- Melepaskan/substitusi/menyejajarkan: Apakah SQL Server menghapus, atau sebaris, kueri tabel turunan? Artinya, apakah SQL Server melakukan proses substitusi yang mengubah kode bersarang asli menjadi satu kueri yang langsung bertentangan dengan tabel dasar? Dan jika demikian, apakah ada cara untuk menginstruksikan SQL Server untuk menghindari proses yang tidak bersarang ini?
Ini semua adalah pertanyaan penting dan jawaban atas pertanyaan ini memiliki implikasi kinerja yang signifikan, jadi ada baiknya untuk memiliki pemahaman yang jelas tentang bagaimana item ini ditangani di SQL Server. Bulan ini saya akan membahas tiga item pertama. Ada cukup banyak hal untuk dikatakan tentang item keempat, jadi saya akan mendedikasikan artikel terpisah untuk itu bulan depan (Bagian 4).
Dalam contoh saya, saya akan menggunakan database sampel yang disebut TSQLV5. Anda dapat menemukan skrip yang membuat dan mengisi TSQLV5 di sini, dan diagram ER-nya di sini.
Kegigihan
Beberapa orang secara intuitif berasumsi bahwa SQL Server mempertahankan hasil dari bagian ekspresi tabel dari tabel turunan (hasil kueri dalam) dalam tabel kerja. Pada tanggal penulisan ini bukan itu masalahnya; namun, karena pertimbangan persistensi adalah pilihan vendor, Microsoft dapat memutuskan untuk mengubahnya di masa mendatang. Memang, SQL Server mampu mempertahankan hasil kueri perantara di meja kerja (biasanya dalam tempdb) sebagai bagian dari pemrosesan kueri. Jika memilih untuk melakukannya, Anda melihat beberapa bentuk operator spool dalam rencana (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). Namun, pilihan SQL Server apakah akan menggulung sesuatu di meja kerja atau tidak saat ini tidak ada hubungannya dengan penggunaan ekspresi tabel bernama dalam kueri. SQL Server terkadang mengumpulkan hasil antara untuk alasan kinerja, seperti menghindari pekerjaan berulang (meskipun saat ini tidak terkait dengan penggunaan ekspresi tabel bernama), dan terkadang karena alasan lain, seperti perlindungan Halloween.
Seperti yang disebutkan, bulan depan saya akan membahas detail unnesting tabel turunan. Untuk saat ini, cukup untuk mengatakan bahwa SQL Server biasanya menerapkan proses unnesting/inlining ke tabel turunan, di mana ia menggantikan kueri bersarang dengan kueri terhadap tabel dasar yang mendasarinya. Yah, saya terlalu menyederhanakan sedikit. Ini tidak seperti SQL Server secara harfiah mengubah string kueri T-SQL asli dengan tabel turunan menjadi string kueri baru tanpa itu; alih-alih SQL Server menerapkan transformasi ke pohon logika internal operator, dan hasilnya adalah tabel turunan secara efektif biasanya tidak bersarang. Saat Anda melihat rencana eksekusi untuk kueri yang melibatkan tabel turunan, Anda tidak melihat penyebutan itu karena untuk sebagian besar tujuan pengoptimalan, tabel tersebut tidak ada. Anda melihat akses ke struktur fisik yang menyimpan data untuk tabel dasar yang mendasarinya (heap, indeks B-tree rowstore dan indeks columnstore untuk tabel berbasis disk dan indeks tree dan hash untuk tabel yang dioptimalkan memori).
Ada kasus yang mencegah SQL Server dari unnesting tabel turunan, tetapi bahkan dalam kasus tersebut SQL Server tidak mempertahankan hasil ekspresi tabel di meja kerja. Saya akan memberikan detailnya beserta contohnya bulan depan.
Karena SQL Server tidak mempertahankan tabel turunan, melainkan berinteraksi langsung dengan struktur fisik yang menyimpan data untuk tabel dasar yang mendasarinya, pertanyaan tentang bagaimana memori ditangani untuk tabel turunan diperdebatkan. Jika tabel dasar yang mendasarinya adalah tabel berbasis disk, halaman yang relevan perlu diproses di kumpulan buffer. Jika tabel yang mendasarinya adalah tabel yang dioptimalkan memori, baris dalam memori yang relevan perlu diproses. Tapi itu tidak berbeda dengan saat Anda mengkueri tabel yang mendasarinya secara langsung tanpa menggunakan tabel turunan. Jadi tidak ada yang istimewa di sini. Saat Anda menggunakan tabel turunan, SQL Server tidak perlu menerapkan pertimbangan memori khusus untuk itu. Untuk sebagian besar tujuan pengoptimalan kueri, hal tersebut tidak ada.
Jika Anda memiliki kasus di mana Anda perlu mempertahankan beberapa hasil langkah perantara di meja kerja, Anda harus menggunakan tabel sementara atau variabel tabel—bukan ekspresi tabel bernama.
Proyeksi kolom dan kata pada SELECT *
Proyeksi adalah salah satu operator asli aljabar relasional. Misalkan Anda memiliki relasi R1 dengan atribut x, y dan z. Proyeksi R1 pada beberapa subset atributnya, misalnya x dan z, adalah relasi baru R2, yang headingnya adalah subset dari atribut yang diproyeksikan dari R1 (x dan z dalam kasus kami), dan yang tubuhnya adalah set tupel dibentuk dari kombinasi asli nilai atribut yang diproyeksikan dari tupel R1.
Ingatlah bahwa tubuh relasi—menjadi kumpulan tupel—menurut definisi tidak memiliki duplikat. Jadi tak perlu dikatakan bahwa tupel relasi hasil adalah kombinasi berbeda dari nilai atribut yang diproyeksikan dari relasi aslinya. Namun, ingat bahwa isi tabel dalam SQL adalah kumpulan baris dan bukan kumpulan, dan biasanya, SQL tidak akan menghilangkan baris duplikat kecuali Anda memerintahkannya. Diberikan tabel R1 dengan kolom x, y dan z, kueri berikut berpotensi mengembalikan baris duplikat, dan oleh karena itu tidak mengikuti semantik operator proyeksi aljabar relasional untuk mengembalikan satu set:
PILIH x, zFROM R1;
Dengan menambahkan klausa DISTINCT, Anda menghilangkan baris duplikat, dan lebih dekat mengikuti semantik proyeksi relasional:
PILIH DISTINCT x, zFROM R1;
Tentu saja, ada beberapa kasus di mana Anda mengetahui bahwa hasil kueri Anda memiliki baris yang berbeda tanpa memerlukan klausa DISTINCT, misalnya, ketika subkumpulan kolom yang Anda kembalikan menyertakan kunci dari tabel kueri. Misalnya, jika x adalah kunci dalam R1, dua kueri di atas secara logika ekuivalen.
Bagaimanapun, ingatlah pertanyaan yang saya sebutkan sebelumnya seputar pengoptimalan kueri yang melibatkan tabel turunan dan proyeksi kolom. Bagaimana cara kerja pencocokan indeks? Jika tabel turunan memproyeksikan subset kolom tertentu dari beberapa tabel yang mendasarinya, dan kueri terluar memproyeksikan subset kolom dari tabel turunan, apakah SQL Server cukup pintar untuk mengetahui pengindeksan optimal berdasarkan subset akhir kolom yang sebenarnya diperlukan? Dan bagaimana dengan izin; apakah pengguna memerlukan izin untuk semua kolom yang direferensikan dalam kueri dalam, atau hanya ke kolom terakhir yang benar-benar dibutuhkan? Juga, anggaplah kueri ekspresi tabel mendefinisikan kolom hasil yang didasarkan pada perhitungan, tetapi kueri luar tidak memproyeksikan kolom itu. Apakah perhitungannya dievaluasi sama sekali?
Dimulai dengan pertanyaan terakhir, mari kita coba. Pertimbangkan kueri berikut:
GUNAKAN TSQLV5;GO SELECT custid, city, 1/0 AS div0errorFROM Sales.Customers;
Seperti yang Anda harapkan, kueri ini gagal dengan kesalahan pembagian dengan nol:
Msg 8134, Level 16, State 1Ditemukan kesalahan pembagian dengan nol.
Selanjutnya, tentukan tabel turunan yang disebut D berdasarkan kueri di atas, dan di kueri luar, proyek D hanya pada custid dan kota, seperti:
SELECT custid, cityFROM ( SELECT custid, city, 1/0 AS div0error FROM Sales.Customers ) AS D;
Seperti yang disebutkan, SQL Server biasanya menerapkan unnesting/substitusi, dan karena tidak ada dalam kueri ini yang menghambat unnesting (lebih lanjut tentang ini bulan depan), kueri di atas setara dengan kueri berikut:
PILIH custid, kotaFROM Sales.Customers;
Sekali lagi, saya terlalu menyederhanakan sedikit di sini. Kenyataannya sedikit lebih kompleks daripada dua pertanyaan ini yang dianggap benar-benar identik, tetapi saya akan membahas kerumitan itu bulan depan. Intinya, ekspresi 1/0 bahkan tidak muncul dalam rencana eksekusi kueri, dan tidak dievaluasi sama sekali, sehingga kueri di atas berhasil dijalankan tanpa kesalahan.
Namun, ekspresi tabel harus valid. Misalnya, pertimbangkan kueri berikut:
SELECT countryFROM ( SELECT * FROM Sales.Customers GROUP BY country ) AS D;
Meskipun kueri luar hanya memproyeksikan kolom dari kumpulan pengelompokan kueri dalam, kueri dalam tidak valid karena mencoba mengembalikan kolom yang bukan merupakan bagian dari kumpulan pengelompokan atau berisi fungsi agregat. Kueri ini gagal dengan kesalahan berikut:
Msg 8120, Level 16, State 1Kolom 'Sales.Customers.custid' tidak valid dalam daftar pilih karena tidak terdapat dalam fungsi agregat atau klausa GROUP BY.
Selanjutnya, mari kita selesaikan pertanyaan pencocokan indeks. Jika kueri luar hanya memproyeksikan subset kolom dari tabel turunan, apakah SQL Server akan cukup pintar untuk melakukan pencocokan indeks hanya berdasarkan kolom yang dikembalikan (dan tentu saja kolom lain yang memainkan peran bermakna sebaliknya, seperti pemfilteran, pengelompokan dan sebagainya)? Tetapi sebelum kami menjawab pertanyaan ini, Anda mungkin bertanya-tanya mengapa kami mempermasalahkannya. Mengapa Anda memiliki kolom pengembalian kueri dalam yang tidak diperlukan kueri luar?
Jawabannya sederhana, untuk mempersingkat kode dengan meminta kueri dalam menggunakan SELECT *. Kita semua tahu bahwa menggunakan SELECT * adalah praktik yang buruk, tetapi itulah yang terjadi terutama ketika digunakan dalam kueri terluar. Bagaimana jika Anda menanyakan tabel dengan heading tertentu, dan kemudian heading tersebut diubah? Aplikasi bisa berakhir dengan bug. Bahkan jika Anda tidak berakhir dengan bug, Anda dapat menghasilkan lalu lintas jaringan yang tidak perlu dengan mengembalikan kolom yang sebenarnya tidak dibutuhkan aplikasi. Plus, Anda menggunakan pengindeksan kurang optimal dalam kasus seperti itu karena Anda mengurangi peluang untuk mencocokkan indeks penutup yang didasarkan pada kolom yang benar-benar dibutuhkan.
Yang mengatakan, saya sebenarnya merasa cukup nyaman menggunakan SELECT * dalam ekspresi tabel, mengetahui bahwa saya tetap akan memproyeksikan hanya kolom yang benar-benar dibutuhkan dalam kueri terluar. Dari sudut pandang logis, itu cukup aman dengan beberapa peringatan kecil yang akan segera saya bahas. Itu selama pencocokan indeks dilakukan secara optimal dalam kasus seperti itu, dan kabar baiknya adalah.
Untuk mendemonstrasikan ini, misalkan Anda perlu membuat kueri tabel Sales.Orders, mengembalikan tiga pesanan terbaru untuk setiap pelanggan. Anda berencana untuk menentukan tabel turunan yang disebut D berdasarkan kueri yang menghitung nomor baris (jumlah kolom hasil) yang dipartisi oleh custid dan diurutkan berdasarkan orderdate DESC, orderid DESC. Kueri luar akan memfilter dari D (pembatasan relasional ) hanya baris di mana rownum kurang dari atau sama dengan 3, dan memproyeksikan D pada custid, orderdate, orderid, dan rownum. Sekarang, Sales.Orders memiliki lebih banyak kolom daripada yang perlu Anda proyeksikan, tetapi untuk singkatnya, Anda ingin kueri dalam menggunakan SELECT *, ditambah penghitungan nomor baris. Itu aman dan akan ditangani secara optimal dalam hal pencocokan indeks.
Gunakan kode berikut untuk membuat indeks penutup yang optimal untuk mendukung kueri Anda:
BUAT INDEX idx_custid_odD_oidD PADA Penjualan.Pesanan(custid, orderdate DESC, orderid DESC);
Inilah kueri yang mengarsipkan tugas yang ada (kami akan menyebutnya Kueri 1):
SELECT custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Perhatikan SELECT * kueri dalam, dan daftar kolom eksplisit kueri luar.
Rencana untuk kueri ini, seperti yang dirender oleh SentryOne Plan Explorer, ditunjukkan pada Gambar 1.
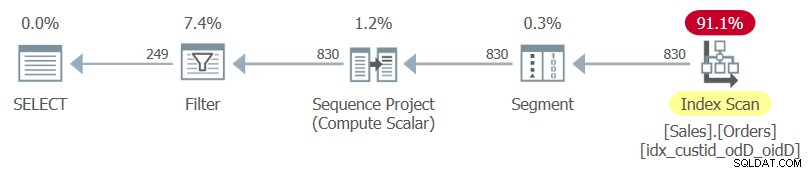 Gambar 1:Rencana untuk Kueri 1
Gambar 1:Rencana untuk Kueri 1
Perhatikan bahwa satu-satunya indeks yang digunakan dalam rencana ini adalah indeks penutup optimal yang baru saja Anda buat.
Jika Anda hanya menyorot kueri dalam dan memeriksa rencana eksekusinya, Anda akan melihat indeks berkerumun tabel yang digunakan diikuti dengan operasi pengurutan.
Jadi itu kabar baik.
Adapun izin, itu cerita yang berbeda. Berbeda dengan pencocokan indeks, di mana Anda tidak memerlukan indeks untuk menyertakan kolom yang direferensikan oleh kueri dalam selama pada akhirnya tidak diperlukan, Anda harus memiliki izin ke semua kolom yang direferensikan.
Untuk mendemonstrasikan hal ini, gunakan kode berikut untuk membuat pengguna yang disebut user1 dan tetapkan beberapa izin (izin PILIH pada semua kolom dari Penjualan.Pelanggan, dan hanya pada tiga kolom dari Penjualan.Pesanan yang pada akhirnya relevan dalam kueri di atas):
BUAT PENGGUNA pengguna1 TANPA LOGIN; HIBAH SHOWPLAN KEPADA pengguna1; HIBAH PILIH PADA Penjualan.Pelanggan UNTUK pengguna1; HIBAH PILIH PADA Penjualan.Pesanan(custid, orderdate, orderid) KEPADA pengguna1;
Jalankan kode berikut untuk menyamar sebagai pengguna1:
JALANKAN SEBAGAI PENGGUNA ='user1';
Coba pilih semua kolom dari Sales.Orders:
PILIH * DARI Penjualan.Pesanan;
Seperti yang diharapkan, Anda mendapatkan kesalahan berikut karena kurangnya izin pada beberapa kolom:
Msg 230, Level 14, State 1Izin SELECT ditolak pada kolom 'empid' dari objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230 , Level 14, State 1
Izin SELECT ditolak pada kolom 'requireddate' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'shippeddate' objek 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, Status 1
Izin SELECT ditolak pada kolom 'shipperid' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'freight' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'shipname' dari objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'shipaddress' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'shipcity' dari objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
The SELECT izin ditolak pada kolom 'shipregion' dari objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT tadinya ditolak pada kolom 'shippostalcode' objek 'Pesanan', database 'TSQLV5', skema 'Penjualan'.
Msg 230, Level 14, Status 1
Izin SELECT ditolak pada kolom 'shipcountry' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Coba kueri berikut, proyeksikan, dan interaksi hanya dengan kolom yang izinnya dimiliki pengguna1:
SELECT custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Namun, Anda mendapatkan kesalahan izin kolom karena kurangnya izin pada beberapa kolom yang dirujuk oleh kueri dalam melalui SELECT *:
Msg 230, Level 14, State 1Izin SELECT ditolak pada kolom 'empid' dari objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230 , Level 14, State 1
Izin SELECT ditolak pada kolom 'requireddate' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'shippeddate' objek 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, Status 1
Izin SELECT ditolak pada kolom 'shipperid' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'freight' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'shipname' dari objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'shipaddress' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT ditolak pada kolom 'shipcity' dari objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
The SELECT izin ditolak pada kolom 'shipregion' dari objek 'Orders', database 'TSQLV5', skema 'Sales'.
Msg 230, Level 14, State 1
Izin SELECT tadinya ditolak pada kolom 'shippostalcode' objek 'Pesanan', database 'TSQLV5', skema 'Penjualan'.
Msg 230, Level 14, Status 1
Izin SELECT ditolak pada kolom 'shipcountry' objek 'Orders', database 'TSQLV5', skema 'Sales'.
Jika memang di perusahaan Anda itu adalah praktik untuk menetapkan izin pengguna hanya pada kolom yang relevan yang mereka perlukan untuk berinteraksi, masuk akal untuk menggunakan kode yang sedikit lebih panjang, dan secara eksplisit tentang daftar kolom di kueri dalam dan luar, seperti ini:
SELECT custid, orderdate, orderid, rownumFROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) SEBAGAI DWHERE rownum <=3;Kali ini, kueri berjalan tanpa kesalahan.
Variasi lain yang mengharuskan pengguna untuk memiliki izin hanya pada kolom yang relevan adalah secara eksplisit tentang nama kolom dalam daftar SELECT kueri dalam, dan gunakan SELECT * di kueri luar, seperti:
SELECT *FROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;Kueri ini juga berjalan tanpa kesalahan. Namun, saya melihat versi ini sebagai salah satu yang rentan terhadap bug dalam kasus nanti beberapa perubahan dibuat di beberapa tingkat dalam bersarang. Seperti yang disebutkan sebelumnya, bagi saya, praktik terbaik adalah secara eksplisit tentang daftar kolom di kueri terluar. Jadi selama Anda tidak memiliki kekhawatiran tentang kurangnya izin pada beberapa kolom, saya merasa nyaman dengan SELECT * di kueri dalam, tetapi daftar kolom eksplisit di kueri terluar. Jika menerapkan izin kolom tertentu adalah praktik umum di perusahaan, maka sebaiknya jelaskan secara eksplisit tentang nama kolom di semua tingkat penimbunan. Perlu diingat, menjadi eksplisit tentang nama kolom di semua tingkat penyarangan sebenarnya wajib jika kueri Anda digunakan dalam objek terikat skema, karena pengikatan skema melarang penggunaan SELECT * di mana pun dalam kueri.
Pada titik ini, jalankan kode berikut untuk menghapus indeks yang Anda buat sebelumnya di Sales.Orders:
JAUHKAN INDEKS JIKA ADA idx_custid_odD_oidD PADA Penjualan.Pesanan;Ada kasus lain dengan dilema serupa mengenai legitimasi penggunaan SELECT *; dalam kueri dalam dari predikat EXISTS.
Pertimbangkan kueri berikut (kami akan menyebutnya Kueri 2):
PILIH custidFROM Sales.Customers AS CWHERE EXISTS (PILIH * FROM Sales.Orders AS O WHERE O.custid =C.custid);Rencana untuk kueri ini ditunjukkan pada Gambar 2.
Gambar 2:Rencana untuk Kueri 2
Saat menerapkan pencocokan indeks, pengoptimal memperkirakan bahwa indeks idx_nc_custid adalah indeks penutup di Sales.Orders karena berisi kolom custid—satu-satunya kolom relevan yang benar dalam kueri ini. Itu terlepas dari fakta bahwa indeks ini tidak berisi kolom lain selain custid, dan bahwa kueri dalam di predikat EXISTS mengatakan SELECT *. Sejauh ini, perilaku tersebut tampaknya mirip dengan penggunaan SELECT * dalam tabel turunan.
Yang berbeda dengan kueri ini adalah kueri ini berjalan tanpa kesalahan, meskipun faktanya pengguna1 tidak memiliki izin pada beberapa kolom dari Sales.Orders. Ada argumen untuk membenarkan tidak memerlukan izin pada semua kolom di sini. Lagi pula, predikat EXISTS hanya perlu memeriksa keberadaan baris yang cocok, sehingga daftar SELECT kueri dalam benar-benar tidak berarti. Mungkin akan lebih baik jika SQL tidak memerlukan daftar SELECT sama sekali dalam kasus seperti itu, tetapi kapal itu sudah berlayar. Kabar baiknya adalah bahwa daftar SELECT secara efektif diabaikan—baik dalam hal pencocokan indeks dan dalam hal izin yang diperlukan.
Tampaknya juga ada perbedaan lain antara tabel turunan dan EXISTS saat menggunakan SELECT * dalam kueri dalam. Ingat pertanyaan ini dari artikel sebelumnya:
SELECT countryFROM ( SELECT * FROM Sales.Customers GROUP BY country ) AS D;Jika Anda ingat, kode ini menghasilkan kesalahan karena kueri dalam tidak valid.
Coba kueri dalam yang sama, hanya kali ini dalam predikat EXISTS (kami akan menyebutnya Pernyataan 3):
JIKA ADA ( PILIH * DARI Penjualan.Pelanggan KELOMPOK BERDASARKAN negara ) CETAK 'Ini berfungsi! Terima kasih Dmitri Korotkevitch atas tipnya!';Anehnya, SQL Server menganggap kode ini valid, dan berhasil dijalankan. Rencana untuk kode ini ditunjukkan pada Gambar 3.
Gambar 3:Rencana untuk Pernyataan 3
Paket ini identik dengan paket yang akan Anda dapatkan jika inner query hanya SELECT * FROM Sales.Customers (tanpa GROUP BY). Lagi pula, Anda memeriksa keberadaan grup, dan jika ada baris, tentu saja ada grup. Bagaimanapun, saya pikir fakta bahwa SQL Server menganggap kueri ini valid adalah bug. Tentunya, kode SQL harus valid! Tetapi saya dapat melihat mengapa beberapa orang dapat berargumen bahwa daftar SELECT dalam kueri EXISTS seharusnya diabaikan. Bagaimanapun, rencana tersebut menggunakan semi join kiri yang diperiksa, yang tidak perlu mengembalikan kolom apa pun, melainkan hanya memeriksa tabel untuk memeriksa keberadaan baris apa pun. Indeks pada Pelanggan dapat berupa indeks apa pun.
Pada titik ini Anda dapat menjalankan kode berikut untuk berhenti meniru identitas pengguna1 dan menghapusnya:
KEMBALIKAN; HENTIKAN PENGGUNA JIKA ADA user1;Kembali ke fakta bahwa saya menemukan praktik yang nyaman untuk menggunakan SELECT * di tingkat dalam bersarang, semakin banyak level yang Anda miliki, semakin banyak praktik ini mempersingkat dan menyederhanakan kode Anda. Berikut ini contoh dengan dua level bersarang:
SELECT orderid, orderyear, custid, empid, shipperidFROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear FROM ( SELECT *, YEAR(orderdate) AS orderyear FROM Sales.Orders ) AS D1 ) AS D2WHERE orderdate =akhir tahun;Ada kasus di mana praktik ini tidak dapat digunakan. Misalnya, ketika kueri dalam menggabungkan tabel dengan nama kolom yang sama, seperti dalam contoh berikut:
SELECT custid, companyname, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders SEBAGAI O ON C.custid =O.custid ) SEBAGAI DWHERE rownum <=3;Baik Penjualan.Pelanggan dan Penjualan.Pesanan memiliki kolom yang disebut custid. Anda menggunakan ekspresi tabel yang didasarkan pada gabungan antara dua tabel untuk menentukan tabel turunan D. Ingatlah bahwa judul tabel adalah kumpulan kolom, dan sebagai kumpulan, Anda tidak dapat memiliki nama kolom duplikat. Oleh karena itu, kueri ini gagal dengan kesalahan berikut:
Msg 8156, Level 16, State 1
Kolom 'custid' ditentukan beberapa kali untuk 'D'.Di sini, Anda harus eksplisit tentang nama kolom dalam kueri dalam, dan pastikan Anda mengembalikan custid hanya dari salah satu tabel, atau menetapkan nama kolom unik ke kolom hasil jika Anda ingin mengembalikan keduanya. Lebih sering Anda akan menggunakan pendekatan sebelumnya, seperti:
PILIH custid, companyname, orderdate, orderid, rownumFROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O. orderid DESC) AS rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Sekali lagi, Anda bisa eksplisit dengan nama kolom di kueri dalam dan menggunakan SELECT * di kueri luar, seperti:
SELECT *FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum FROM Sales .Pelanggan SEBAGAI C LEFT OUTER JOIN Sales.Pesanan SEBAGAI O PADA C.custid =O.custid ) SEBAGAI DWHERE rownum <=3;Tetapi seperti yang saya sebutkan sebelumnya, saya menganggapnya sebagai praktik yang buruk untuk tidak secara eksplisit menyebutkan nama kolom di kueri terluar.
Beberapa referensi ke alias kolom
Mari kita lanjutkan ke item berikutnya—beberapa referensi ke kolom tabel turunan. Jika tabel turunan memiliki kolom hasil yang didasarkan pada komputasi nondeterministik, dan kueri luar memiliki banyak referensi ke kolom tersebut, apakah komputasi akan dievaluasi hanya sekali atau secara terpisah untuk setiap referensi?
Mari kita mulai dengan fakta bahwa banyak referensi ke fungsi nondeterministik yang sama dalam kueri seharusnya dievaluasi secara independen. Pertimbangkan kueri berikut sebagai contoh:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;Kode ini menghasilkan output berikut yang menunjukkan dua GUID yang berbeda:
mynewid1 mynewid2------------------------------------------------ ---------------------------7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406Sebaliknya, jika Anda memiliki tabel turunan dengan kolom yang didasarkan pada komputasi nondeterministik, dan kueri luar memiliki banyak referensi ke kolom tersebut, penghitungan seharusnya dievaluasi hanya sekali. Pertimbangkan kueri berikut (kami akan menyebutnya Kueri 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2FROM ( SELECT NEWID() AS mynewid ) AS D;Rencana untuk kueri ini ditunjukkan pada Gambar 4.
Gambar 4:Rencana untuk Kueri 4
Perhatikan bahwa hanya ada satu pemanggilan fungsi NEWID dalam rencana. Dengan demikian, output menunjukkan GUID yang sama dua kali:
mynewid1 mynewid2------------------------------------------------ ---------------------------296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74AJadi, dua kueri di atas tidak setara secara logis, dan ada kasus di mana inlining/substitusi tidak terjadi.
Dengan beberapa fungsi nondeterministik, agak sulit untuk menunjukkan bahwa banyak pemanggilan dalam kueri ditangani secara terpisah. Ambil fungsi SYSDATETIME sebagai contoh. Ini memiliki presisi 100 nanodetik. Berapa peluang kueri seperti berikut ini benar-benar menampilkan dua nilai yang berbeda?
PILIH SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;Jika Anda bosan, Anda bisa menekan F5 berulang kali hingga itu terjadi. Jika Anda memiliki hal-hal yang lebih penting untuk dilakukan dengan waktu Anda, Anda mungkin lebih suka menjalankan loop, seperti:
MENNYATAKAN @i SEBAGAI INT =1; SAAT ADA( SELECT * FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D WHERE mydt1 =mydt2 ) SET @i +=1; CETAK @i;Misalnya, ketika saya menjalankan kode ini, saya mendapatkan 1971.
Jika Anda ingin memastikan bahwa fungsi nondeterministik dipanggil hanya sekali, dan mengandalkan nilai yang sama dalam beberapa referensi kueri, pastikan Anda mendefinisikan ekspresi tabel dengan kolom berdasarkan pemanggilan fungsi, dan memiliki beberapa referensi ke kolom tersebut dari kueri luar, seperti itu (kami akan menyebutnya Kueri 5):
SELECT mydt AS mydt1, mydt AS mydt1FROM ( SELECT SYSDATETIME() AS mydt ) AS D;Rencana untuk kueri ini ditunjukkan pada Gambar 5.
Gambar 5:Rencana untuk Kueri 5
Perhatikan dalam rencana bahwa fungsi tersebut dipanggil hanya sekali.
Sekarang ini bisa menjadi latihan yang sangat menarik pada pasien untuk menekan F5 berulang kali sampai Anda mendapatkan dua nilai yang berbeda. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT =1; WHILE EXISTS ( SELECT * FROM (SELECT mydt AS mydt1, mydt AS mydt2 FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2 WHERE mydt1 =mydt2 ) SET @i +=1; PRINT @i;You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT CASE WHEN RAND() <0.5 THEN STR(RAND(), 5, 3) + ' is less than half.' ELSE STR(RAND(), 5, 3) + ' is at least half.' END;Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT CASE WHEN rnd <0.5 THEN STR(rnd, 5, 3) + ' is less than half.' ELSE STR(rnd, 5, 3) + ' is at least half.' ENDFROM ( SELECT RAND() AS rnd ) AS D;Ringkasan
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.



