Ringkasan
Artikel ini membahas dua pendekatan berbeda yang tersedia untuk menghapus baris duplikat dari tabel SQL yang seringkali menjadi sulit seiring berjalannya waktu seiring bertambahnya data jika tidak dilakukan tepat waktu.
Kehadiran baris duplikat adalah masalah umum yang dihadapi pengembang dan penguji SQL dari waktu ke waktu, namun, baris duplikat ini termasuk dalam beberapa kategori berbeda yang akan kita bahas dalam artikel ini.
Artikel ini berfokus pada skenario tertentu, ketika data dimasukkan ke dalam tabel database, mengarah ke pengenalan catatan duplikat dan kemudian kita akan melihat lebih dekat metode untuk menghapus duplikat dan akhirnya menghapus duplikat menggunakan metode ini.
Menyiapkan Contoh Data
Sebelum kita mulai menjelajahi berbagai opsi yang tersedia untuk menghapus duplikat, ada baiknya pada titik ini untuk menyiapkan database sampel yang akan membantu kita memahami situasi ketika data duplikat masuk ke dalam sistem dan pendekatan yang digunakan untuk menghapusnya .
Menyiapkan Contoh Database (UniversityV2)
Mulailah dengan membuat database yang sangat sederhana yang hanya terdiri dari Siswa tabel di awal.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Mengisi Tabel Siswa
Mari kita hanya menambahkan dua catatan ke tabel Siswa:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Pemeriksaan Data
Lihat tabel yang berisi dua record berbeda saat ini:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
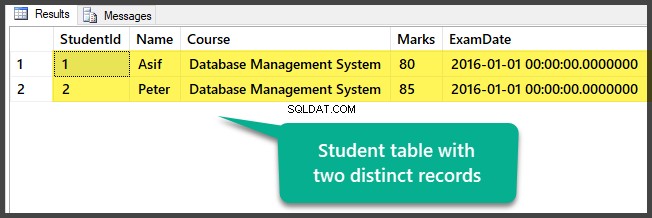
Anda telah berhasil menyiapkan data sampel dengan menyiapkan database dengan satu tabel dan dua record (berbeda) yang berbeda.
Sekarang kita akan membahas beberapa skenario potensial di mana duplikat diperkenalkan dan dihapus mulai dari situasi yang sederhana hingga yang sedikit rumit.
Kasus 01:Menambah dan Menghapus Duplikat
Sekarang kita akan memperkenalkan baris duplikat di tabel Siswa.
Prasyarat
Dalam hal ini, sebuah tabel dikatakan memiliki record duplikat jika Nama student siswa , Kursus , Tanda , dan Tanggal Ujian bertepatan di lebih dari satu catatan meskipun Nomor Siswa berbeda.
Jadi, kami berasumsi bahwa tidak ada dua siswa yang memiliki nama, mata kuliah, nilai, dan tanggal ujian yang sama.
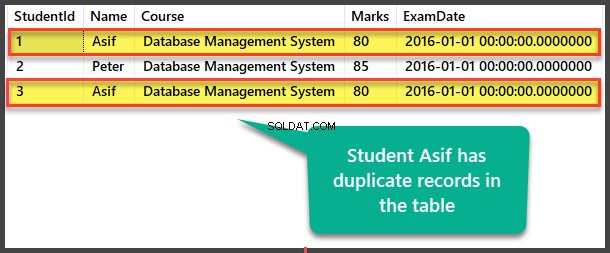
Menambahkan Duplikat Data Asif Mahasiswa
Mari kita dengan sengaja menyisipkan catatan duplikat untuk Mahasiswa:Asif kepada Siswa tabel sebagai berikut:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Melihat Duplikat Data Siswa
Lihat Siswa tabel untuk melihat catatan duplikat:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Menemukan Duplikat dengan Metode Referensi Sendiri
Bagaimana jika ada ribuan record dalam tabel ini, maka melihat tabel tidak akan banyak membantu.
Dalam metode referensi mandiri, kami mengambil dua referensi ke tabel yang sama dan menggabungkannya menggunakan pemetaan kolom demi kolom dengan pengecualian ID yang dibuat kurang dari atau lebih besar dari yang lain.
Mari kita lihat metode referensi diri untuk menemukan duplikat yang terlihat seperti ini:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
Output dari skrip di atas hanya menunjukkan kepada kita catatan duplikat:

Menemukan Duplikat dengan Metode Referensi-Self-2
Cara lain untuk menemukan duplikat menggunakan referensi diri adalah dengan menggunakan INNER JOIN sebagai berikut:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Menghapus Duplikat dengan Metode Referensi Sendiri
Kami dapat menghapus duplikat menggunakan metode yang sama yang kami gunakan untuk menemukan duplikat dengan pengecualian menggunakan DELETE sesuai dengan sintaksnya sebagai berikut:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
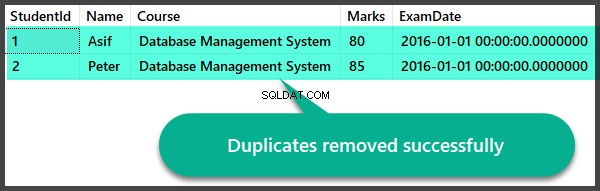
Pemeriksaan Data setelah Penghapusan Duplikat
Mari kita cepat memeriksa catatan setelah kita menghapus duplikatnya:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Membuat Tampilan Duplikat dan Menghapus Prosedur Tersimpan Duplikat
Sekarang setelah kita mengetahui bahwa skrip kita berhasil menemukan dan menghapus baris duplikat dalam SQL, lebih baik mengubahnya menjadi tampilan dan prosedur tersimpan untuk kemudahan penggunaan:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
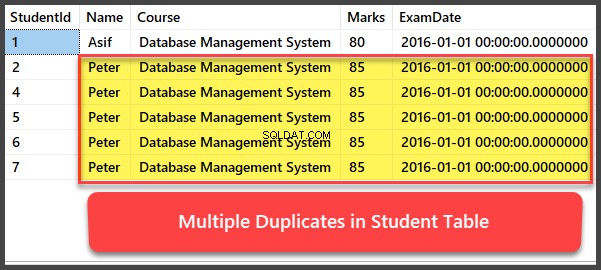
Menambahkan dan Melihat Beberapa Rekaman Duplikat
Sekarang mari kita tambahkan empat catatan lagi ke Siswa tabel dan semua catatan adalah duplikat sedemikian rupa sehingga memiliki nama, mata kuliah, nilai, dan tanggal ujian yang sama:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Menghapus Duplikat dengan menggunakan Prosedur UspRemoveDuplicates
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
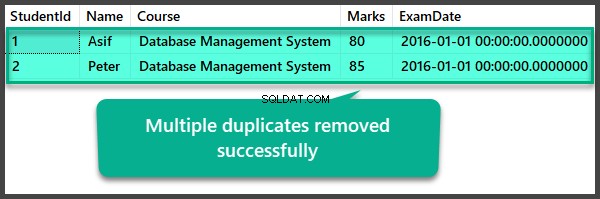
Pemeriksaan Data setelah Penghapusan Beberapa Duplikat
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Kasus 02:Menambah dan Menghapus Duplikat dengan ID yang Sama
Sejauh ini, kami telah mengidentifikasi rekaman duplikat yang memiliki ID berbeda tetapi bagaimana jika ID tersebut sama.
Misalnya, pikirkan skenario di mana tabel baru saja diimpor dari teks atau file Excel yang tidak memiliki kunci utama.
Prasyarat
Dalam hal ini, sebuah tabel dikatakan memiliki record duplikat jika semua nilai kolomnya sama persis termasuk beberapa kolom ID dan primary key tidak ada sehingga memudahkan untuk memasukkan record duplikat.
Buat Tabel Kursus tanpa Kunci Utama
Untuk mereproduksi skenario di mana catatan duplikat tanpa adanya kunci utama masuk ke dalam tabel, mari kita buat Kursus baru terlebih dahulu tabel tanpa kunci utama dalam database University2 sebagai berikut:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
Mengisi Tabel Kursus
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Pemeriksaan Data
Lihat Kursus tabel:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
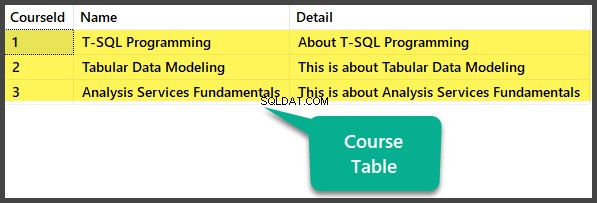
Menambahkan Data Duplikat di Tabel Kursus
Sekarang masukkan duplikat ke dalam Kursus tabel:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Melihat Duplikat Data Kursus
Pilih semua kolom untuk melihat tabel:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

Menemukan Duplikat dengan Metode Agregat
Kita dapat menemukan duplikat yang tepat dengan menggunakan metode agregat dengan mengelompokkan semua kolom dengan total lebih dari satu setelah memilih semua kolom bersama dengan menghitung semua baris menggunakan fungsi count(*) agregat:
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Ini dapat diterapkan sebagai berikut:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
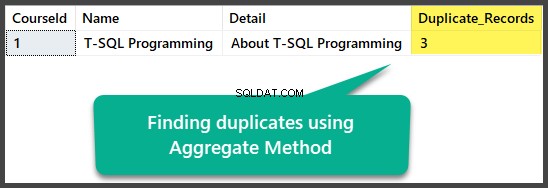
Menghapus Duplikat dengan Metode Agregat
Mari kita hapus duplikat menggunakan Metode Agregat sebagai berikut:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Pemeriksaan Data
GUNAKAN UniversitasV2
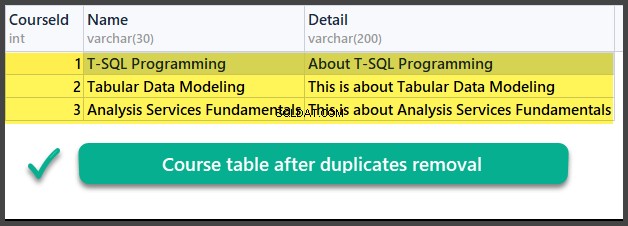
Jadi, kita telah berhasil mempelajari cara menghapus duplikat dari tabel database menggunakan dua metode berbeda berdasarkan dua skenario berbeda.
Hal yang Dapat Dilakukan
Sekarang Anda dapat dengan mudah mengidentifikasi dan membebaskan tabel database dari nilai duplikat.
1. Coba buat UspRemoveDuplicatesByAggregate prosedur tersimpan berdasarkan metode yang disebutkan di atas dan hapus duplikat dengan memanggil prosedur tersimpan
2. Coba ubah prosedur tersimpan yang dibuat di atas (UspRemoveDuplicatesByAggregates) dan terapkan kiat Pembersihan yang disebutkan dalam artikel ini.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Dapatkah Anda yakin bahwa UspRemoveDuplicatesByAggregate prosedur tersimpan dapat dijalankan sebanyak mungkin, bahkan setelah menghapus duplikat, untuk menunjukkan bahwa prosedur tetap konsisten?
4. Silakan lihat artikel saya sebelumnya Langsung ke Mulai Test-Driven Database Development (TDDD) – Bagian 1 dan coba masukkan duplikat ke dalam tabel database SQLDevBlog, setelah itu coba hapus duplikat menggunakan kedua metode yang disebutkan dalam tip ini.
5. Coba buat database sampel lain EmployeesSample merujuk ke artikel saya sebelumnya Seni Mengisolasi Dependensi dan Data dalam Pengujian Unit Basis Data dan menyisipkan duplikat ke dalam tabel dan mencoba menghapusnya menggunakan kedua metode yang Anda pelajari dari tip ini.
Alat yang berguna:
dbForge Data Bandingkan untuk SQL Server – alat perbandingan SQL yang kuat yang mampu bekerja dengan data besar.