Bertanggung jawab atas kinerja SQL Server bisa menjadi tugas yang menakutkan. Ada banyak area yang harus kita pantau dan pahami. Kami juga diharapkan dapat tetap berada di atas semua metrik tersebut dan mengetahui apa yang terjadi di server kami setiap saat. Saya suka bertanya kepada DBA apa hal pertama yang mereka pikirkan ketika mereka mendengar ungkapan "menyetel SQL Server;" tanggapan luar biasa yang saya dapatkan adalah "penyetelan kueri." Saya setuju bahwa penyetelan kueri sangat penting dan merupakan tugas tanpa akhir yang kita hadapi karena beban kerja terus berubah.
Namun ada banyak aspek lain yang perlu dipertimbangkan ketika memikirkan kinerja SQL Server. Ada banyak contoh, OS, dan pengaturan tingkat basis data yang perlu diubah dari default. Menjadi konsultan memungkinkan saya untuk bekerja di berbagai lini bisnis dan mendapatkan paparan terhadap segala macam masalah kinerja. Ketika bekerja dengan klien baru, saya mencoba untuk selalu melakukan audit kesehatan server untuk mengetahui apa yang saya hadapi. Saat melakukan audit ini, salah satu hal yang saya temukan berulang kali adalah latensi baca dan tulis yang berlebihan pada disk tempat data SQL Server dan file log berada.
Latensi Baca/Tulis
Untuk melihat latensi disk Anda di SQL Server, Anda dapat dengan cepat dan mudah menanyakan sys.dm_io_virtual_file_stats DMV . DMV ini menerima dua parameter:database_id dan file_id . Yang luar biasa adalah Anda dapat melewati NULL baik sebagai nilai dan mengembalikan latensi untuk semua file untuk semua database. Kolom keluaran meliputi:
- database_id
- id_file
- sampel_ms
- jumlah_pembacaan
- jumlah_byte_baca
- io_stall_read_ms
- jumlah_penulisan
- jumlah_byte_tertulis
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
Seperti yang Anda lihat dari daftar kolom, ada informasi yang sangat berguna yang diambil oleh DMV ini, namun hanya menjalankan SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); tidak banyak membantu kecuali Anda telah menghafal database_ids Anda dan dapat melakukan beberapa matematika di kepala Anda.
Ketika saya menanyakan statistik file, saya menggunakan kueri dari posting blog Paul Randal, "Cara memeriksa latensi subsistem IO dari dalam SQL Server." Skrip ini membuat nama kolom lebih mudah dibaca, termasuk drive tempat file berada, nama database, dan jalur ke file.
Dengan menanyakan DMV ini, Anda dapat dengan mudah mengetahui di mana hot spot I/O untuk file Anda. Anda dapat melihat di mana latensi tulis dan baca tertinggi berada dan basis data mana yang menjadi penyebabnya. Mengetahui hal ini akan memungkinkan Anda untuk mulai melihat peluang penyetelan untuk database spesifik tersebut. Ini dapat mencakup penyetelan indeks, memeriksa untuk melihat apakah kumpulan buffer berada di bawah tekanan memori, mungkin memindahkan database ke bagian yang lebih cepat dari subsistem I/O, atau mungkin mempartisi database dan menyebarkan filegroup di seluruh LUN lain.
Jadi Anda menjalankan kueri dan mengembalikan banyak nilai dalam ms untuk latensi – nilai mana yang baik-baik saja, dan mana yang buruk?
Nilai apa yang baik atau buruk?
Jika Anda menanyakan SQLskills, kami akan memberi tahu Anda sesuatu seperti:
- Luar biasa:<1ms
- Sangat bagus:<5ms
- Bagus:5 – 10md
- Buruk:10 – 20 md
- Buruk:20 – 100 md
- Sangat buruk:100 – 500 md
- OMG!:> 500 md
Jika Anda melakukan pencarian Bing, Anda akan menemukan artikel dari Microsoft yang membuat rekomendasi serupa dengan:
- Bagus:<10 md
- Oke:10 – 20 md
- Buruk:20 – 50 md
- Sangat buruk:> 50 md
Seperti yang Anda lihat, ada beberapa variasi kecil dalam angka, tetapi konsensusnya adalah bahwa apa pun yang lebih dari 20 md dapat dianggap merepotkan. Dengan itu, latensi tulis rata-rata Anda mungkin 20 ms dan itu 100% dapat diterima untuk organisasi Anda dan tidak apa-apa. Anda perlu mengetahui latensi I/O umum untuk sistem Anda sehingga, ketika keadaan menjadi buruk, Anda tahu apa itu normal.
Latensi Baca/Tulis Saya Buruk, Apa Yang Harus Saya Lakukan?
Jika Anda menemukan bahwa latensi baca dan tulis buruk di server Anda, ada beberapa tempat di mana Anda dapat mulai mencari masalah. Ini bukan daftar lengkap tetapi beberapa panduan untuk memulai.
- Analisis beban kerja Anda. Apakah strategi pengindeksan Anda benar? Tidak memiliki indeks yang tepat akan menyebabkan lebih banyak data yang dibaca dari disk. Memindai alih-alih mencari.
- Apakah statistik Anda mutakhir? Statistik yang buruk dapat membuat pilihan yang buruk untuk rencana eksekusi.
- Apakah Anda memiliki masalah sniffing parameter yang menyebabkan rencana eksekusi buruk?
- Apakah kumpulan buffer di bawah tekanan memori, misalnya dari cache paket yang membengkak?
- Ada masalah jaringan? Apakah fabric SAN Anda bekerja dengan benar? Minta teknisi penyimpanan Anda memvalidasi jalur dan jaringan.
- Pindahkan hot spot ke array penyimpanan yang berbeda. Dalam beberapa kasus mungkin satu database atau hanya beberapa database yang menyebabkan semua masalah. Mengisolasinya ke kumpulan disk yang berbeda, atau disk kelas atas yang lebih cepat seperti SSD mungkin merupakan solusi logis terbaik.
- Dapatkah Anda mempartisi database untuk memindahkan tabel yang bermasalah ke disk yang berbeda untuk menyebarkan beban?
Statistik Tunggu
Sama seperti memantau statistik file Anda, memantau statistik tunggu Anda dapat memberi tahu Anda banyak hal tentang kemacetan di lingkungan Anda. Kami beruntung memiliki DMV keren lainnya (sys.dm_os_wait_stats ) bahwa kami dapat meminta yang akan menarik semua informasi tunggu yang tersedia yang dikumpulkan sejak restart terakhir atau sejak terakhir kali menunggu direset; ada menunggu terkait dengan kinerja disk juga. DMV ini akan mengembalikan informasi penting termasuk:
- tipe_tunggu
- menunggu_tugas_hitung
- tunggu_waktu_md
- max_wait_time_ms
- signal_wait_time_ms
Menanyakan DMV ini pada mesin SQL Server 2014 saya menghasilkan 771 tipe tunggu. SQL Server selalu menunggu sesuatu, tetapi ada banyak waktu menunggu yang tidak perlu kita khawatirkan. Untuk alasan ini, saya menggunakan pertanyaan lain dari Paul Randal; posting blognya, "Statistik Tunggu, atau tolong beri tahu saya di mana itu sakit," memiliki skrip luar biasa yang mengecualikan banyak menunggu yang tidak terlalu kami pedulikan. Paul juga mencantumkan banyak masalah umum menunggu serta menawarkan panduan untuk menunggu umum.
Mengapa statistik menunggu itu penting?
Memantau waktu tunggu yang tinggi untuk peristiwa tertentu akan memberi tahu Anda saat ada masalah yang terjadi. Anda memerlukan dasar untuk mengetahui apa yang normal dan kapan hal-hal melebihi ambang batas atau tingkat rasa sakit. Jika Anda memiliki PAGEIOLATCH_XX yang sangat tinggi maka Anda tahu SQL Server harus menunggu halaman data dibaca dari disk. Ini bisa berupa disk, memori, perubahan beban kerja, atau sejumlah masalah lainnya.
Seorang klien baru-baru ini yang bekerja dengan saya melihat beberapa perilaku yang sangat tidak biasa. Ketika saya terhubung ke server database dan dapat mengamati server di bawah beban kerja, saya segera mulai memeriksa statistik file, statistik tunggu, penggunaan memori, penggunaan tempdb, dll. Satu hal yang langsung menonjol adalah WRITELOG menjadi penantian yang paling umum. Saya tahu penantian ini ada hubungannya dengan log flush ke disk dan mengingatkan saya pada seri Paul tentang Trimming the Transaction Log Fat. WRITELOG tinggi menunggu biasanya dapat diidentifikasi dengan latensi penulisan tinggi untuk file log transaksi. Jadi saya kemudian menggunakan skrip statistik file saya untuk meninjau latensi baca dan tulis pada disk. Saya kemudian dapat melihat latensi tulis yang tinggi pada file data tetapi tidak pada file log saya. Dalam melihat WRITELOG itu menunggu tinggi tetapi waktu menunggu di ms sangat rendah. Namun sesuatu di pos kedua seri Paul masih ada di kepala saya. Saya harus melihat pengaturan pertumbuhan otomatis untuk database hanya untuk mengesampingkan "Kematian dengan seribu pemotongan". Dalam melihat properti database dari database saya melihat bahwa file data diatur untuk tumbuh secara otomatis sebesar 1MB dan log transaksi diatur untuk tumbuh secara otomatis sebesar 10%. Kedua file memiliki hampir 0 ruang yang tidak terpakai. Saya berbagi dengan klien apa yang saya temukan dan bagaimana ini membunuh kinerja mereka. Kami dengan cepat membuat perubahan yang sesuai dan pengujian berjalan maju, omong-omong jauh lebih baik. Sayangnya ini bukan satu-satunya saat saya mengalami masalah yang tepat ini. Di lain waktu, database berukuran 66GB, dengan pertumbuhan 1MB.
Mengambil data Anda
Banyak profesional data telah menciptakan proses untuk menangkap statistik file dan menunggu secara teratur untuk analisis. Karena statistik tunggu bersifat kumulatif, Anda ingin menangkapnya dan membandingkan delta antara waktu yang berbeda dalam sehari atau sebelum dan setelah proses tertentu berjalan. Ini tidak terlalu rumit dan ada banyak posting blog yang tersedia di mana orang-orang berbagi bagaimana mereka mencapai ini. Bagian yang penting adalah mengukur data ini sehingga Anda dapat memantaunya. Bagaimana Anda tahu hari ini bahwa segala sesuatunya lebih baik atau lebih buruk di server database Anda kecuali Anda mengetahui data dari kemarin?
Bagaimana SQL Sentry dapat membantu?
Saya senang Anda bertanya! SQL Sentry Performance Advisor menghadirkan latensi dan menunggu di depan dan di tengah dasbor. Setiap anomali mudah dikenali; Anda dapat beralih ke mode historis dan melihat tren sebelumnya dan membandingkannya dengan periode sebelumnya juga. Ini terbukti sangat berharga ketika menganalisis "apa yang terjadi?" momen. Semua orang mendapat panggilan itu, “Kemarin sekitar pukul 15:00 sistem sepertinya membeku, dapatkah Anda memberi tahu kami apa yang terjadi?” Um, tentu, biarkan aku membuka Profiler dan kembali ke masa lalu. Jika Anda memiliki alat pemantauan seperti Performance Advisor, Anda akan memiliki informasi historis itu di ujung jari Anda.
Selain bagan dan grafik di dasbor, Anda memiliki kemampuan untuk menggunakan peringatan bawaan untuk kondisi seperti Tunggu Disk Tinggi, Hitungan VLF Tinggi, CPU Tinggi, Harapan Hidup Halaman Rendah, dan banyak lagi. Anda juga memiliki kemampuan untuk membuat kondisi kustom Anda sendiri, dan Anda dapat belajar dari contoh di situs SQL Sentry atau melalui Condition Exchange (Aaron Bertrand telah membuat blog tentang ini). Saya menyentuh sisi peringatan ini di artikel terakhir saya di SQL Server Agent Alerts.
Pada tab Disk Space dari Performance Advisor, sangat mudah untuk melihat hal-hal seperti pengaturan pertumbuhan otomatis dan jumlah VLF yang tinggi. Anda harus tahu, tetapi jika tidak, pertumbuhan otomatis sebesar 1MB atau 10% bukanlah pengaturan terbaik. Jika Anda melihat nilai-nilai ini (Penasihat Kinerja menyorotinya untuk Anda), Anda dapat dengan cepat membuat catatan dan menjadwalkan waktu untuk melakukan penyesuaian yang tepat. Saya suka bagaimana ini menampilkan Total VLF juga; terlalu banyak VLF bisa sangat bermasalah. Anda harus membaca posting Kimberly “VLF Log Transaksi – terlalu banyak atau terlalu sedikit?” jika Anda belum melakukannya.
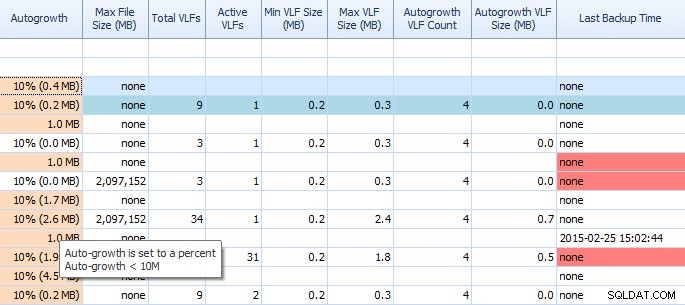 Kisi sebagian pada tab Ruang Disk Performance Advisor
Kisi sebagian pada tab Ruang Disk Performance Advisor
Cara lain yang dapat membantu Performance Advisor adalah melalui modul Disk Activity yang dipatenkan. Di sini Anda dapat melihat bahwa tempdb pada F:mengalami latensi tulis yang substansial; Anda dapat mengetahuinya dengan garis merah tebal di bawah grafik disk. Anda mungkin juga memperhatikan bahwa F:adalah satu-satunya huruf drive yang disknya diwakili dengan warna merah; ini adalah isyarat visual bahwa drive memiliki partisi yang tidak sejajar, yang dapat menyebabkan masalah I/O.
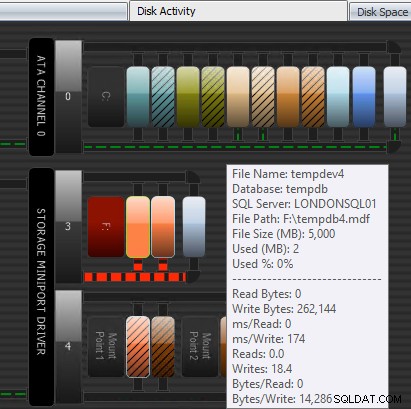 Modul Aktivitas Disk Penasihat Kinerja
Modul Aktivitas Disk Penasihat Kinerja
Dan Anda dapat menghubungkan informasi ini dalam kisi-kisi di bawah – masalah juga disorot dalam kisi-kisi di sana, dan lihatlah ms/Write kolom:
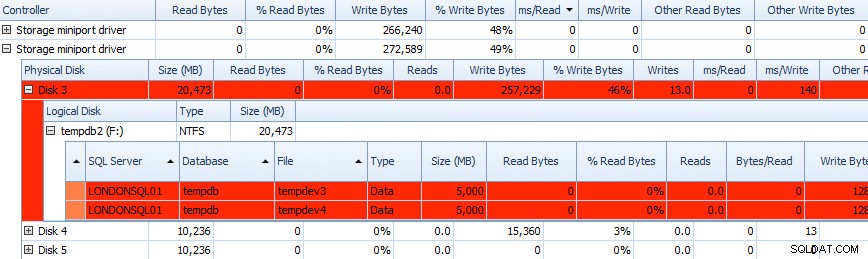 Kisi sebagian dari data Aktivitas Disk Performance Advisor
Kisi sebagian dari data Aktivitas Disk Performance Advisor
Anda juga dapat melihat informasi ini secara surut; jika seseorang mengeluh tentang hambatan disk yang dirasakan kemarin sore atau Selasa lalu, Anda dapat kembali menggunakan pemilih tanggal di bilah alat dan melihat rata-rata throughput dan latensi untuk rentang apa pun. Untuk informasi lebih lanjut tentang modul Aktivitas Disk, lihat Panduan Pengguna.
Performance Advisor juga memiliki banyak laporan bawaan di bawah kategori Performance, Blocking, Top SQL, Disk/File Space, dan Deadlock. Gambar di bawah menunjukkan cara membuka laporan Disk/File Space. Memiliki laporan hanya dengan beberapa klik mouse sangat berharga untuk dapat segera menggali dan melihat apa yang (atau sedang) terjadi di server Anda.
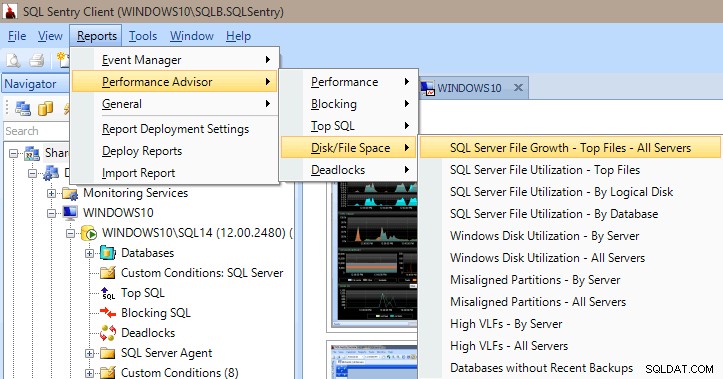 Laporan Penasihat Kinerja
Laporan Penasihat Kinerja
Ringkasan
Takeaway penting dari posting ini adalah untuk mengetahui metrik kinerja Anda. Pernyataan umum di antara para profesional data adalah bahwa disk adalah hambatan #1 kami. Mengetahui statistik file server Anda akan sangat membantu dalam memahami poin-poin masalah di server Anda. Sehubungan dengan statistik file, statistik tunggu Anda juga merupakan tempat yang bagus untuk dilihat. Banyak orang, termasuk saya, mulai dari sana. Memiliki alat seperti SQL Sentry Performance Advisor dapat secara drastis membantu Anda memecahkan masalah dan menemukan masalah kinerja sebelum menjadi terlalu bermasalah; namun, jika Anda tidak memiliki alat seperti itu, pelajari sys.dm_os_wait_stats dan sys.dm_io_virtual_file_stats akan melayani Anda dengan baik untuk mulai menyetel server Anda.