Ketika SQL Server mengoptimalkan kueri, selama fase eksplorasi, ia menghasilkan rencana kandidat dan memilih di antara mereka yang memiliki biaya terendah. Rencana yang dipilih seharusnya memiliki run time terendah di antara rencana yang dieksplorasi. Masalahnya, pengoptimal hanya dapat memilih di antara strategi yang dikodekan ke dalamnya. Misalnya, ketika mengoptimalkan pengelompokan dan agregasi, pada tanggal penulisan ini, pengoptimal hanya dapat memilih antara strategi Stream Aggregate dan Hash Aggregate. Saya membahas strategi yang tersedia di bagian sebelumnya dalam seri ini. Di Bagian 1 saya membahas strategi Stream Agregat yang telah dipesan sebelumnya, di Bagian 2 strategi Sort + Stream Aggregate, di Bagian 3 strategi Hash Aggregate, dan di Bagian 4 pertimbangan paralelisme.
Apa yang saat ini tidak didukung oleh pengoptimal SQL Server adalah penyesuaian dan kecerdasan buatan. Artinya, jika Anda dapat mengetahui strategi yang dalam kondisi tertentu lebih optimal daripada yang didukung oleh pengoptimal, Anda tidak dapat meningkatkan pengoptimal untuk mendukungnya, dan pengoptimal tidak dapat belajar menggunakannya. Namun, yang dapat Anda lakukan adalah menulis ulang kueri menggunakan elemen kueri alternatif yang dapat dioptimalkan dengan strategi yang Anda pikirkan. Di bagian kelima dan terakhir dalam seri ini, saya mendemonstrasikan teknik penyetelan kueri ini menggunakan revisi kueri.
Terima kasih banyak kepada Paul White (@SQL_Kiwi) karena telah membantu beberapa perhitungan biaya yang disajikan dalam artikel ini!
Seperti di bagian sebelumnya dalam seri ini, saya akan menggunakan database sampel PerformanceV3. Gunakan kode berikut untuk menghapus indeks yang tidak diperlukan dari tabel Pesanan:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Strategi pengoptimalan default
Pertimbangkan tugas pengelompokan dan agregasi dasar berikut:
Kembalikan tanggal pesanan maksimum untuk setiap pengirim, karyawan, dan pelanggan.
Untuk kinerja yang optimal, Anda membuat indeks pendukung berikut:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate); CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate); CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
Berikut adalah tiga kueri yang akan Anda gunakan untuk menangani tugas-tugas ini, bersama dengan perkiraan biaya subpohon, serta I/O, CPU, dan statistik waktu yang telah berlalu:
-- Query 1 -- Estimated Subtree Cost: 3.5344 -- logical reads: 2484, CPU time: 281 ms, elapsed time: 279 ms SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid; -- Query 2 -- Estimated Subtree Cost: 3.62798 -- logical reads: 2610, CPU time: 250 ms, elapsed time: 283 ms SELECT empid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY empid; -- Query 3 -- Estimated Subtree Cost: 4.27624 -- logical reads: 3479, CPU time: 406 ms, elapsed time: 506 ms SELECT custid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY custid;
Gambar 1 menunjukkan rencana untuk kueri ini:
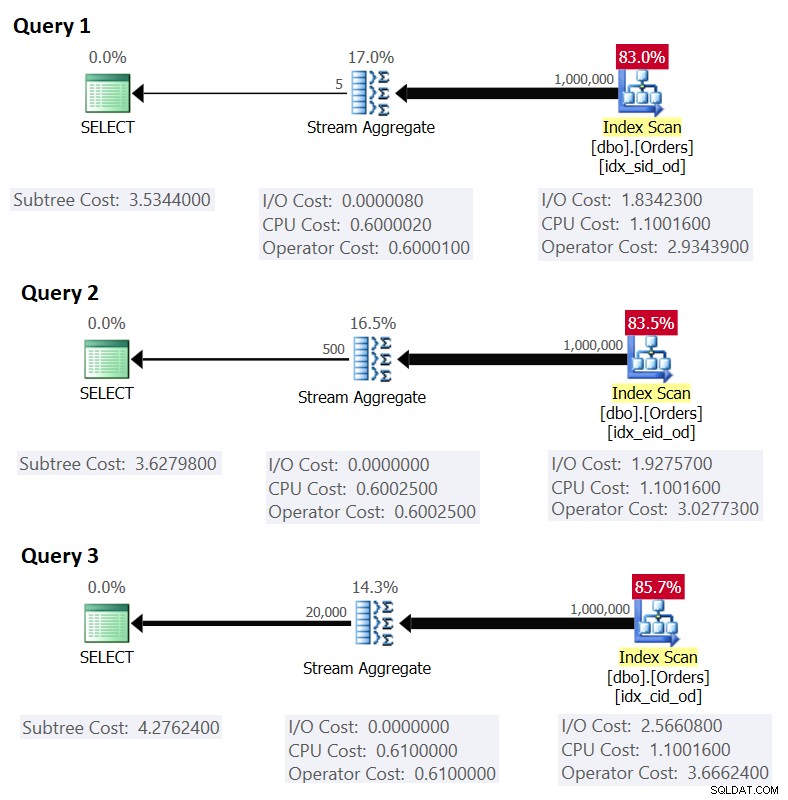 Gambar 1:Rencana untuk kueri yang dikelompokkan
Gambar 1:Rencana untuk kueri yang dikelompokkan
Ingatlah bahwa jika Anda memiliki indeks penutup, dengan pengelompokan set kolom sebagai kolom kunci utama, diikuti oleh kolom agregasi, SQL Server kemungkinan akan memilih rencana yang melakukan pemindaian berurutan dari indeks penutup yang mendukung strategi Stream Agregat . Seperti terlihat dalam rencana pada Gambar 1, operator Pemindaian Indeks bertanggung jawab atas sebagian besar biaya rencana, dan di dalamnya bagian I/O adalah yang paling menonjol.
Sebelum saya menyajikan strategi alternatif dan menjelaskan keadaan di mana itu lebih optimal daripada strategi default, mari kita evaluasi biaya dari strategi yang ada. Karena bagian I/O adalah yang paling dominan dalam menentukan biaya rencana dari strategi default ini, mari kita perkirakan dulu berapa banyak pembacaan halaman logis yang diperlukan. Nanti kami akan perkirakan juga biaya paketnya.
Untuk memperkirakan jumlah pembacaan logis yang diperlukan oleh operator Pemindaian Indeks, Anda perlu mengetahui berapa banyak baris yang Anda miliki dalam tabel, dan berapa banyak baris yang muat dalam sebuah halaman berdasarkan ukuran baris. Setelah Anda memiliki dua operan ini, rumus Anda untuk jumlah halaman yang diperlukan di tingkat daun indeks adalah CEILING(1e0 * @numrows / @rowsperpage). Jika semua yang Anda miliki hanyalah struktur tabel dan tidak ada data sampel yang ada untuk dikerjakan, Anda dapat menggunakan artikel ini untuk memperkirakan jumlah halaman yang akan Anda miliki di tingkat daun indeks pendukung. Jika Anda memiliki data sampel representatif yang baik, meskipun tidak dalam skala yang sama seperti di lingkungan produksi, Anda dapat menghitung jumlah rata-rata baris yang sesuai dengan halaman dengan membuat kueri katalog dan objek manajemen dinamis, seperti:
SELECT I.name, row_count, in_row_data_page_count,
CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage
FROM sys.indexes AS I
INNER JOIN sys.dm_db_partition_stats AS P
ON I.object_id = P.object_id
AND I.index_id = P.index_id
WHERE I.object_id = OBJECT_ID('dbo.Orders')
AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Kueri ini menghasilkan output berikut dalam database sampel kami:
name row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Sekarang setelah Anda memiliki jumlah baris yang sesuai dengan halaman daun indeks, Anda dapat memperkirakan jumlah total halaman daun dalam indeks berdasarkan jumlah baris yang Anda harapkan dari tabel produksi Anda. Ini juga akan menjadi jumlah pembacaan logis yang diharapkan untuk diterapkan oleh operator Pemindaian Indeks. Dalam praktiknya, ada lebih banyak lagi jumlah pembacaan yang dapat dilakukan daripada hanya jumlah halaman di tingkat daun indeks, seperti pembacaan ekstra yang dihasilkan oleh mekanisme baca di depan, tetapi saya akan mengabaikannya untuk menjaga diskusi kita tetap sederhana. .
Misalnya, perkiraan jumlah pembacaan logis untuk Kueri 1 sehubungan dengan jumlah baris yang diharapkan adalah CEILING(1e0 * @numorws / 404). Dengan 1.000.000 baris, jumlah pembacaan logis yang diharapkan adalah 2476. Perbedaan antara 2476 dan jumlah halaman baris yang dilaporkan sebanyak 2473 dapat dikaitkan dengan pembulatan yang saya lakukan saat menghitung jumlah rata-rata baris per halaman.
Mengenai biaya paket, saya menjelaskan cara merekayasa balik biaya operator Agregat Aliran di Bagian 1 dalam seri ini. Dengan cara yang sama, Anda dapat merekayasa balik biaya operator Pemindaian Indeks. Biaya paket adalah jumlah dari biaya operator Index Scan dan Stream Aggregate.
Untuk menghitung biaya operator Pemindaian Indeks, Anda ingin memulai dengan rekayasa balik beberapa konstanta model biaya penting:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Dengan mengetahui konstanta model biaya di atas, Anda dapat melanjutkan untuk merekayasa balik rumus untuk biaya I/O, biaya CPU, dan total biaya operator untuk operator Pemindaian Indeks:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.003125 + (@numpages - 1e0) * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011 Operator cost: 0.002541259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000011
Misalnya, biaya operator Pemindaian Indeks untuk Kueri 1, dengan 2473 halaman dan 1.000.000 baris, adalah:
0.002541259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000011 = 2.93439
Berikut adalah rumus rekayasa terbalik untuk biaya operator Stream Agregat:
0.000008 + @numrows * 0.0000006 + @numgroups * 0.0000005
Sebagai contoh, untuk Kueri 1, kami memiliki 1.000.000 baris dan 5 grup, maka perkiraan biayanya adalah 0,6000105.
Menggabungkan biaya kedua operator, berikut rumus untuk seluruh biaya paket:
0.002549259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Untuk Kueri 1, dengan 2473 halaman, 1.000.000 baris, dan 5 grup, Anda mendapatkan:
0.002549259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5344
Ini cocok dengan apa yang ditunjukkan Gambar 1 sebagai perkiraan biaya untuk Kueri 1.
Jika Anda mengandalkan perkiraan jumlah baris per halaman, rumus Anda akan menjadi:
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Sebagai contoh, untuk Kueri 1, dengan 1.000.000 baris, 404 baris per halaman, dan 5 grup, perkiraan biayanya adalah:
0.002549259259259 + CEILING(1e0 * 1000000 / 404) * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5366
Sebagai latihan, Anda dapat menerapkan angka untuk Kueri 2 (1.000.000 baris, 385 baris per halaman, 500 grup) dan Kueri 3 (1.000.000 baris, 289 baris per halaman, 20.000 grup) dalam rumus kami, dan lihat apakah hasilnya cocok dengan apa Gambar 1 menunjukkan.
Penyetelan kueri dengan penulisan ulang kueri
Strategi Stream Agregat yang telah dipesan sebelumnya untuk menghitung agregat MIN/MAX per grup bergantung pada pemindaian berurutan dari indeks penutup pendukung (atau beberapa aktivitas awal lainnya yang memancarkan baris yang dipesan). Strategi alternatif, dengan adanya indeks penutup pendukung, adalah melakukan pencarian indeks per kelompok. Berikut adalah deskripsi rencana semu berdasarkan strategi untuk kueri yang dikelompokkan berdasarkan grpcol dan menerapkan MAX(aggcol):
set @curgrpcol = grpcol from first row obtained by a scan of the index, ordered forward;
while end of index not reached
begin
set @curagg = aggcol from row obtained by a seek to the last point
where grpcol = @curgrpcol, ordered backward;
emit row (@curgrpcol, @curagg);
set @curgrpcol = grpcol from row to the right of last row for current group;
end; Jika Anda memikirkannya, strategi berbasis pemindaian default optimal ketika kumpulan pengelompokan memiliki kepadatan rendah (jumlah grup yang besar, dengan jumlah baris per grup yang sedikit). Strategi berbasis pencarian optimal ketika kumpulan pengelompokan memiliki kepadatan tinggi (jumlah grup kecil, dengan jumlah baris per grup rata-rata banyak). Gambar 2 mengilustrasikan kedua strategi yang menunjukkan kapan masing-masing optimal.
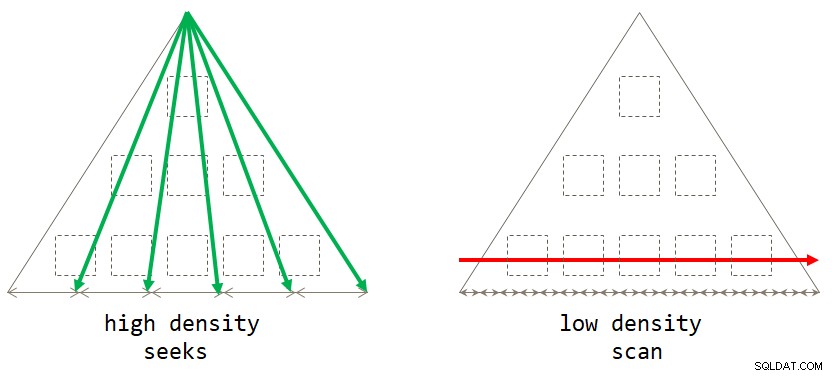 Gambar 2:Strategi optimal berdasarkan pengelompokan set kepadatan
Gambar 2:Strategi optimal berdasarkan pengelompokan set kepadatan
Selama Anda menulis solusi dalam bentuk kueri yang dikelompokkan, saat ini SQL Server hanya akan mempertimbangkan strategi pemindaian. Ini akan bekerja dengan baik untuk Anda ketika kumpulan pengelompokan memiliki kepadatan rendah. Ketika Anda memiliki kepadatan tinggi, untuk mendapatkan strategi pencarian, Anda perlu menerapkan penulisan ulang kueri. Salah satu cara untuk mencapai ini adalah dengan menanyakan tabel yang menampung grup, dan menggunakan subkueri agregat skalar terhadap tabel utama untuk mendapatkan agregat. Misalnya, untuk menghitung tanggal pemesanan maksimum untuk setiap pengirim, Anda akan menggunakan kode berikut:
SELECT shipperid,
( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS maxod
FROM dbo.Shippers AS S; Panduan pengindeksan untuk tabel utama sama dengan panduan untuk mendukung strategi default. Kami sudah memiliki indeks tersebut untuk tiga tugas yang disebutkan di atas. Anda mungkin juga menginginkan indeks pendukung pada kolom kumpulan pengelompokan di tabel yang menampung grup untuk meminimalkan biaya I/O terhadap tabel itu. Gunakan kode berikut untuk membuat indeks pendukung seperti itu untuk tiga tugas kami:
CREATE INDEX idx_sid ON dbo.Shippers(shipperid); CREATE INDEX idx_eid ON dbo.Employees(empid); CREATE INDEX idx_cid ON dbo.Customers(custid);
Satu masalah kecil adalah bahwa solusi berdasarkan subquery bukanlah solusi yang setara dengan logika yang tepat berdasarkan kueri yang dikelompokkan. Jika Anda memiliki grup tanpa kehadiran di tabel utama, yang pertama akan mengembalikan grup dengan NULL sebagai agregat, sedangkan yang terakhir tidak akan mengembalikan grup sama sekali. Cara sederhana untuk mencapai ekuivalen logis yang sebenarnya untuk kueri yang dikelompokkan adalah dengan memanggil subkueri menggunakan operator CROSS APPLY dalam klausa FROM alih-alih menggunakan subkueri skalar dalam klausa SELECT. Ingat bahwa CROSS APPLY tidak akan mengembalikan baris kiri jika kueri yang diterapkan mengembalikan set kosong. Berikut adalah tiga kueri solusi yang menerapkan strategi ini untuk tiga tugas kami, bersama dengan statistik kinerjanya:
-- Query 4
-- Estimated Subtree Cost: 0.0072299
-- logical reads: 2 + 15, CPU time: 0 ms, elapsed time: 43 ms
SELECT S.shipperid, A.orderdate AS maxod
FROM dbo.Shippers AS S
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS A;
-- Query 5
-- Estimated Subtree Cost: 0.089694
-- logical reads: 2 + 1620, CPU time: 0 ms, elapsed time: 148 ms
SELECT E.empid, A.orderdate AS maxod
FROM dbo.Employees AS E
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.empid = E.empid
ORDER BY O.orderdate DESC ) AS A;
-- Query 6
-- Estimated Subtree Cost: 3.5227
-- logical reads: 45 + 63777, CPU time: 171 ms, elapsed time: 306 ms
SELECT C.custid, A.orderdate AS maxod
FROM dbo.Customers AS C
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC ) AS A; Rencana untuk kueri ini ditunjukkan pada Gambar 3.
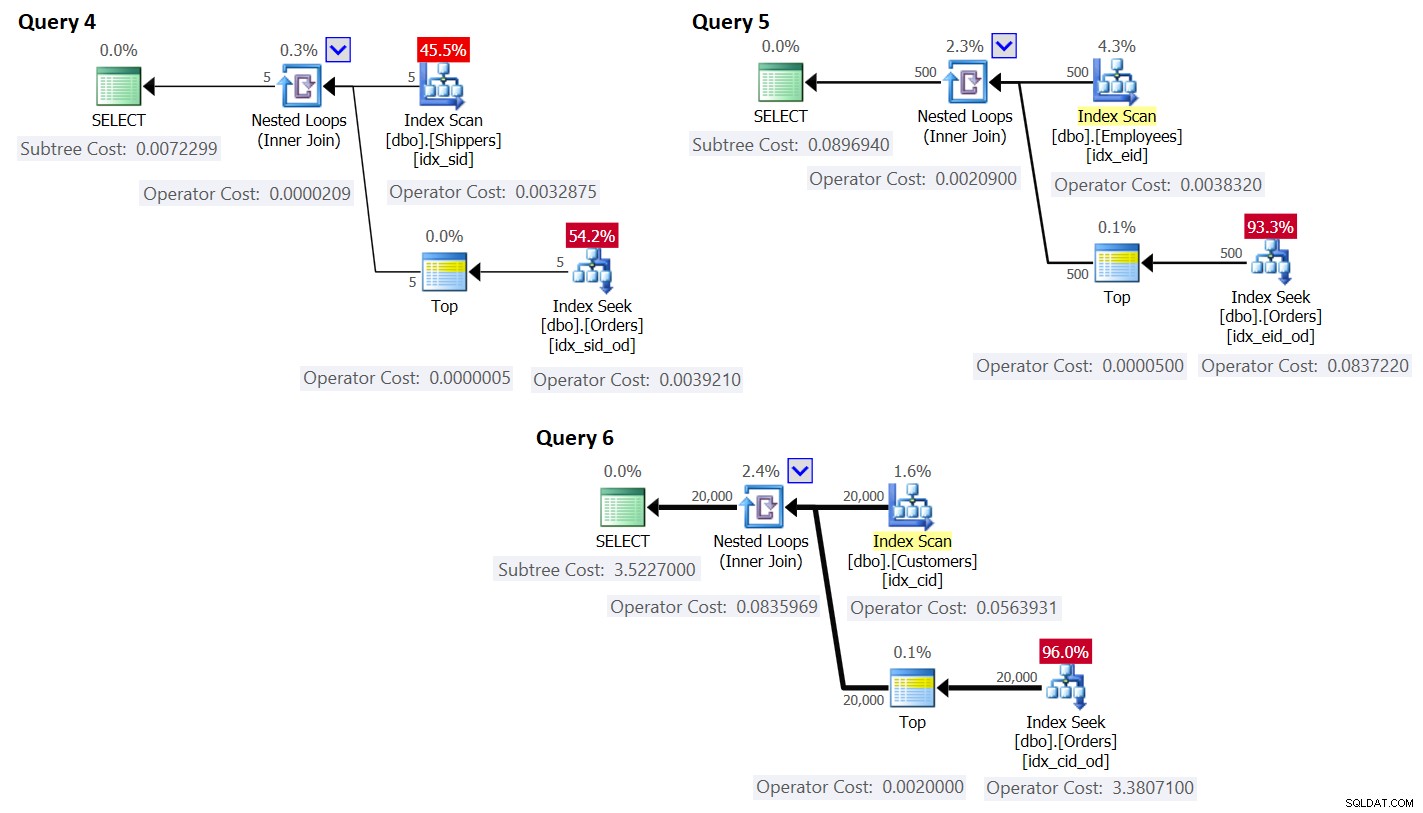 Gambar 3:Rencana untuk kueri dengan penulisan ulang
Gambar 3:Rencana untuk kueri dengan penulisan ulang
Seperti yang Anda lihat, grup diperoleh dengan memindai indeks pada tabel grup, dan agregat diperoleh dengan menerapkan pencarian dalam indeks pada tabel utama. Semakin tinggi kepadatan kumpulan pengelompokan, semakin optimal rencana ini dibandingkan dengan strategi default untuk kueri yang dikelompokkan.
Sama seperti yang kami lakukan sebelumnya untuk strategi pemindaian default, mari perkirakan jumlah pembacaan logis dan rencanakan biaya untuk strategi pencarian. Perkiraan jumlah pembacaan logis adalah jumlah pembacaan untuk satu eksekusi operator Index Scan yang mengambil grup, ditambah pembacaan untuk semua eksekusi operator Index Seek.
Perkiraan jumlah pembacaan logis untuk operator Pemindaian Indeks dapat diabaikan dibandingkan dengan pencarian; tetap saja, ini CEILING(1e0 * @numgroups / @rowsperpage). Ambil Query 4 sebagai contoh; katakanlah indeks idx_sid cocok dengan sekitar 600 baris per halaman daun (jumlah sebenarnya tergantung pada nilai pengirim sebenarnya karena tipe datanya adalah VARCHAR (5)). Dengan 5 grup, semua baris muat dalam satu halaman daun. Jika Anda memiliki 5.000 grup, grup tersebut akan muat dalam 9 halaman.
Perkiraan jumlah pembacaan logis untuk semua eksekusi operator Index Seek adalah @numgroups * @indexdepth. Kedalaman indeks dapat dihitung sebagai:
CEILING(LOG(CEILING(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
Menggunakan Query 4 sebagai contoh, katakan bahwa kita dapat memuat sekitar 404 baris per halaman daun dari indeks idx_sid_od, dan sekitar 352 baris per halaman nonleaf. Sekali lagi, angka aktual akan bergantung pada nilai aktual yang disimpan dalam kolom shipperid karena tipe datanya adalah VARCHAR(5)). Untuk perkiraan, ingatlah bahwa Anda dapat menggunakan perhitungan yang dijelaskan di sini. Dengan tersedianya data sampel representatif yang baik, Anda dapat menggunakan kueri berikut untuk mengetahui jumlah baris yang dapat ditampung dalam halaman daun dan non-daun dari indeks yang diberikan:
SELECT
CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype,
FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage
FROM (SELECT *
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.Orders')
AND name = 'idx_sid_od') AS I
CROSS APPLY sys.dm_db_index_physical_stats
(DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P
WHERE P.index_level <= 1; Saya mendapatkan output berikut:
pagetype rowsperpage -------- ---------------------- leaf 404 nonleaf 352
Dengan angka-angka ini, kedalaman indeks terhadap jumlah baris dalam tabel adalah:
CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1
Dengan 1.000.000 baris dalam tabel, ini menghasilkan kedalaman indeks 3. Pada sekitar 50 juta baris, kedalaman indeks meningkat menjadi 4 level, dan pada sekitar 17,62 miliar baris meningkat menjadi 5 level.
Bagaimanapun, sehubungan dengan jumlah grup dan jumlah baris, dengan asumsi jumlah baris di atas per halaman, rumus berikut menghitung perkiraan jumlah pembacaan logis untuk Kueri 4:
CEILING(1e0 * @numgroups / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)
Misalnya, dengan 5 grup dan 1.000.000 baris, Anda hanya mendapatkan total 16 pembacaan! Ingatlah bahwa strategi berbasis pemindaian default untuk kueri yang dikelompokkan melibatkan pembacaan logis sebanyak CEILING(1e0 * @numrows / @rowsperpage). Menggunakan Kueri 1 sebagai contoh, dan dengan asumsi sekitar 404 baris per halaman daun indeks idx_sid_od, dengan jumlah baris yang sama 1.000.000, Anda mendapatkan sekitar 2.476 bacaan. Tingkatkan jumlah baris dalam tabel dengan faktor 1.000 menjadi 1.000.000.000, tetapi pertahankan jumlah grup tetap. Jumlah pembacaan yang diperlukan dengan strategi pencarian berubah sangat sedikit menjadi 21, sedangkan jumlah pembacaan yang diperlukan dengan strategi pemindaian meningkat secara linier menjadi 2.475.248.
Keindahan dari strategi pencarian adalah bahwa selama jumlah grup kecil dan tetap, ia memiliki penskalaan yang hampir konstan sehubungan dengan jumlah baris dalam tabel. Itu karena jumlah pencarian ditentukan oleh jumlah grup, dan kedalaman indeks berkaitan dengan jumlah baris dalam tabel secara logaritmik di mana basis log adalah jumlah baris yang sesuai dengan halaman nonleaf. Sebaliknya, strategi berbasis pemindaian memiliki penskalaan linier sehubungan dengan jumlah baris yang terlibat.
Gambar 4 menunjukkan jumlah pembacaan yang diperkirakan untuk dua strategi, yang diterapkan oleh Kueri 1 dan Kueri 4, dengan jumlah grup 5 yang tetap, dan jumlah baris yang berbeda di tabel utama.
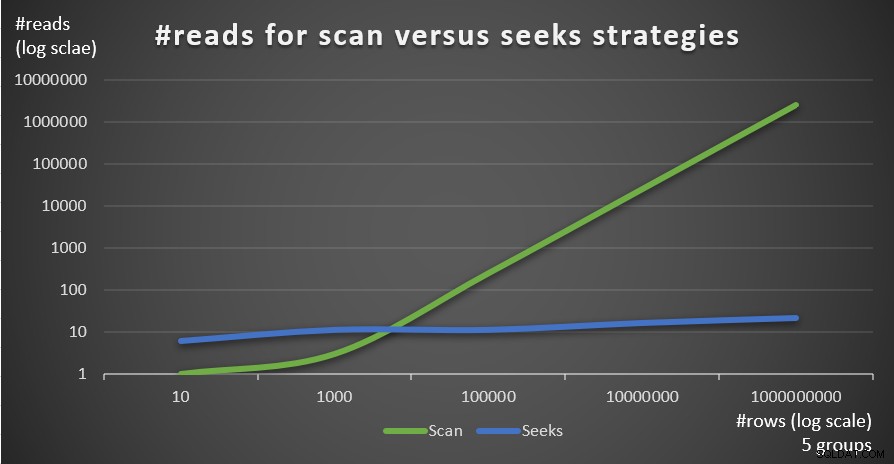 Gambar 4:#reads untuk strategi pemindaian versus pencarian (5 kelompok)
Gambar 4:#reads untuk strategi pemindaian versus pencarian (5 kelompok)
Gambar 5 menunjukkan jumlah pembacaan yang diperkirakan untuk kedua strategi, dengan jumlah baris tetap 1.000.000 di tabel utama, dan jumlah grup yang berbeda.
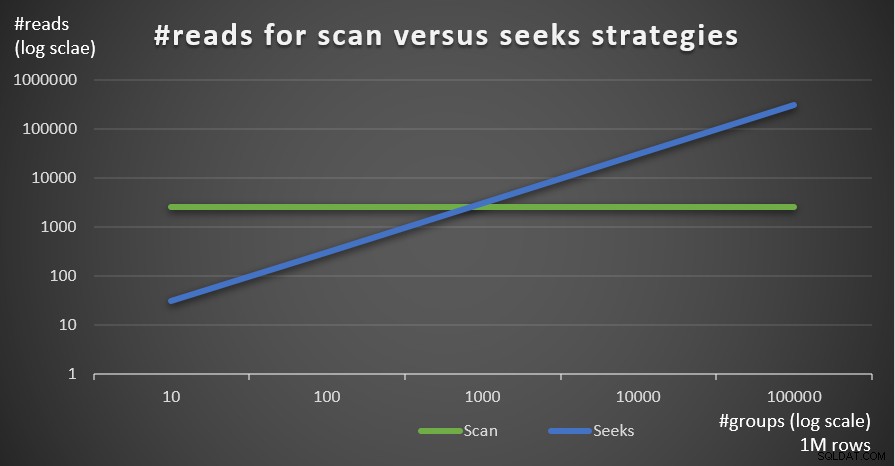 Gambar 5:#reads untuk strategi pemindaian versus pencarian (1 juta baris)
Gambar 5:#reads untuk strategi pemindaian versus pencarian (1 juta baris)
Anda dapat melihat dengan sangat jelas bahwa semakin tinggi kepadatan set pengelompokan (jumlah grup lebih sedikit) dan semakin besar tabel utama, semakin banyak strategi pencarian lebih disukai dalam hal jumlah bacaan. Jika Anda bertanya-tanya tentang pola I/O yang digunakan oleh setiap strategi; tentu saja, operasi pencarian indeks melakukan I/O acak, sedangkan operasi pemindaian indeks melakukan I/O berurutan. Namun, cukup jelas strategi mana yang lebih optimal dalam kasus yang lebih ekstrem.
Untuk biaya paket kueri, sekali lagi, dengan menggunakan paket untuk Kueri 4 pada Gambar 3 sebagai contoh, mari kita uraikan ke masing-masing operator dalam paket.
Rumus rekayasa terbalik untuk biaya operator Pemindaian Indeks adalah:
0.002541259259259 + @numpages * 0.000740740740741 + @numgroups * 0.0000011
Dalam kasus kami, dengan 5 grup, yang semuanya muat dalam satu halaman, biayanya adalah:
0.002541259259259 + 1 * 0.000740740740741 + 5 * 0.0000011 = 0.0032875
Biaya yang ditampilkan dalam paket adalah sama.
Seperti sebelumnya, Anda dapat memperkirakan jumlah halaman dalam indeks tingkat daun berdasarkan perkiraan jumlah baris per halaman menggunakan rumus CEILING(1e0 * @numrows / @rowsperpage), yang dalam kasus kami adalah CEILING(1e0 * @ numgroups / @groupsperpage). Katakanlah indeks idx_sid cocok dengan sekitar 600 baris per halaman daun, dengan 5 grup Anda perlu membaca satu halaman. Bagaimanapun, rumus penetapan biaya untuk operator Pemindaian Indeks kemudian menjadi:
0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011
Rumus penetapan biaya rekayasa terbalik untuk operator Nested Loops adalah:
@executions * 0.00000418
Dalam kasus kami, ini diterjemahkan menjadi:
@numgroups * 0.00000418
Untuk Kueri 4, dengan 5 grup, Anda mendapatkan:
5 * 0.00000418 = 0.0000209
Biaya yang ditampilkan dalam paket adalah sama.
Rumus penetapan biaya rekayasa terbalik untuk operator Top adalah:
@executions * @toprows * 0.00000001
Dalam kasus kami, ini diterjemahkan menjadi:
@numgroups * 1 * 0.00000001
Dengan 5 grup, Anda mendapatkan:
5 * 0.0000001 = 0.0000005
Biaya yang ditampilkan dalam paket adalah sama.
Adapun operator Index Seek, di sini saya mendapat bantuan besar dari Paul White; Terima kasih temanku! Perhitungannya berbeda untuk eksekusi pertama dan rebind (eksekusi non-pertama yang tidak menggunakan kembali hasil eksekusi sebelumnya). Seperti yang kita lakukan dengan operator Pemindaian Indeks, mari kita mulai dengan mengidentifikasi konstanta model biaya:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Untuk satu eksekusi, tanpa penerapan sasaran baris, biaya I/O dan CPU adalah:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.002384259259259 + @numpages * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011
Karena kami menggunakan TOP (1), kami hanya memiliki satu halaman dan satu baris yang terlibat, jadi biayanya adalah:
I/O cost: 0.002384259259259 + 1 * 0.000740740740741 = 0.003125 CPU cost: 0.000157 + 1 * 0.0000011 = 0.0001581
Jadi biaya eksekusi pertama operator Index Seek dalam kasus kami adalah:
@firstexecution = 0.003125 + 0.0001581 = 0.0032831
Untuk biaya rebind, seperti biasa, terdiri dari biaya CPU dan I/O. Sebut saja mereka masing-masing @rebindcpu dan @rebindio. Dengan Query 4, memiliki 5 grup, kami memiliki 4 rebinds (sebut saja @rebinds). Biaya @rebindcpu adalah bagian yang mudah. Rumusnya adalah:
@rebindcpu = @rebinds * (@cpubase + @cpurow)
Dalam kasus kami, ini diterjemahkan menjadi:
@rebindcpu = 4 * (0.000157 + 0.0000011) = 0.0006324
Bagian @rebindio sedikit lebih kompleks. Di sini, rumus penetapan biaya menghitung, secara statistik, jumlah halaman berbeda yang diharapkan yang diharapkan untuk dibaca oleh rebind menggunakan pengambilan sampel dengan penggantian. Kami akan memanggil elemen ini @pswr (untuk halaman berbeda yang diambil sampelnya dengan penggantian). Idenya adalah, kami memiliki @indexdatapages jumlah halaman dalam indeks (dalam kasus kami, 2.473), dan @rebinds jumlah rebinds (dalam kasus kami, 4). Dengan asumsi kita memiliki probabilitas yang sama untuk membaca halaman tertentu dengan setiap rebind, berapa banyak halaman berbeda yang diharapkan untuk kita baca secara total? Ini mirip dengan memiliki tas dengan 2.473 bola, dan empat kali secara membabi buta mengambil bola dari tas dan kemudian mengembalikannya ke tas. Secara statistik, berapa banyak bola berbeda yang diharapkan untuk diambil seluruhnya? Rumus untuk ini, menggunakan operan kami, adalah:
@pswr = @indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))
Dengan nomor kami, Anda mendapatkan:
@pswr = 2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) = 3.99757445099277
Selanjutnya, Anda menghitung jumlah baris dan halaman yang Anda miliki rata-rata per grup:
@grouprows = @cardinality * @density @grouppages = CEILING(@indexdatapages * @density)
Dalam Kueri 4 kami, kardinalitasnya adalah 1.000.000 dan kerapatannya adalah 1/5 =0,2. Jadi, Anda mendapatkan:
@grouprows = 1000000 * 0.2 = 200000 @numpages = CEILING(2473 * 0.2) = 495
Kemudian Anda menghitung biaya I/O tanpa memfilter (sebut saja @io) sebagai:
@io = @randomio + (@seqio * (@grouppages - 1e0))
Dalam kasus kami, Anda mendapatkan:
@io = 0.003125 + (0.000740740740741 * (495 - 1e0)) = 0.369050925926054
Dan terakhir, karena pencarian hanya mengekstrak satu baris di setiap rebind, Anda menghitung @rebindio menggunakan rumus berikut:
@rebindio = (1e0 / @grouprows) * ((@pswr - 1e0) * @io)
Dalam kasus kami, Anda mendapatkan:
@rebindio = (1e0 / 200000) * ((3.99757445099277 - 1e0) * 0.369050925926054) = 0.000005531288
Akhirnya, biaya operator adalah:
Operator cost: @firstexecution + @rebindcpu + @rebindio = 0.0032831 + 0.0006324 + 0.000005531288 = 0.003921031288
Ini sama dengan biaya operator Pencarian Indeks yang ditunjukkan dalam paket untuk Kueri 4.
Anda sekarang dapat menggabungkan biaya semua operator untuk mendapatkan biaya paket kueri yang lengkap. Anda mendapatkan:
Query plan cost: 0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00000418
+ @numgroups * 0.00000001
+ 0.0032831 + (@numgroups - 1e0) * 0.0001581
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Setelah penyederhanaan, Anda mendapatkan rumus biaya lengkap berikut untuk strategi Seeks kami:
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Sebagai contoh, dengan menggunakan T-SQL, berikut adalah perhitungan biaya paket kueri dengan strategi Seeks untuk Kueri 4:
DECLARE
@numrows AS FLOAT = 1000000,
@numgroups AS FLOAT = 5,
@rowsperpage AS FLOAT = 404,
@groupsperpage AS FLOAT = 600;
SELECT
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0)))
AS seeksplancost; Perhitungan ini menghitung biaya 0,0072295 untuk Query 4. Estimasi biaya yang ditunjukkan pada Gambar 3 adalah 0,0072299. Itu cukup dekat! Sebagai latihan, hitung biaya untuk Kueri 5 dan Kueri 6 menggunakan rumus ini dan verifikasi bahwa Anda mendapatkan angka yang mendekati angka yang ditunjukkan pada Gambar 3.
Ingatlah bahwa rumus penetapan biaya untuk strategi berbasis pemindaian default adalah (sebut saja Pindai strategi):
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Menggunakan Kueri 1 sebagai contoh, dan dengan asumsi 1.000.000 baris dalam tabel, 404 baris per halaman, dan 5 grup, perkiraan biaya rencana kueri dari strategi pemindaian adalah 3,5366.
Gambar 6 menunjukkan perkiraan biaya rencana kueri untuk dua strategi, yang diterapkan oleh Kueri 1 (scan) dan Kueri 4 (pencarian), dengan jumlah grup 5 yang tetap, dan jumlah baris yang berbeda di tabel utama.
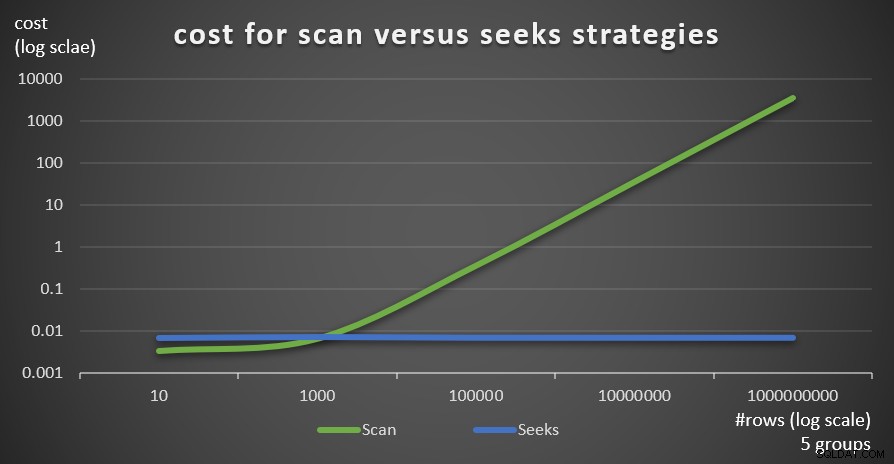 Gambar 6:biaya untuk memindai versus mencari strategi (5 kelompok)
Gambar 6:biaya untuk memindai versus mencari strategi (5 kelompok)
Gambar 7 menunjukkan perkiraan biaya rencana kueri untuk dua strategi, dengan jumlah baris tetap di tabel utama 1.000.000, dan jumlah grup yang berbeda.
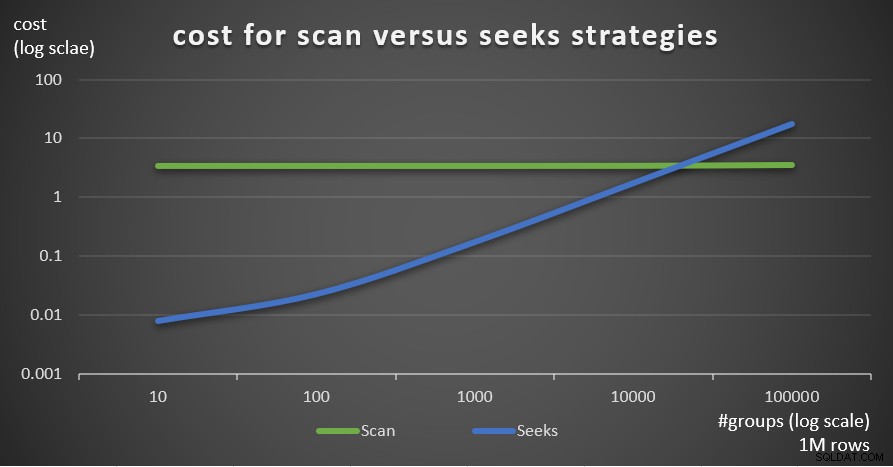 Gambar 7:biaya untuk memindai versus mencari strategi (1 juta baris)
Gambar 7:biaya untuk memindai versus mencari strategi (1 juta baris)
Seperti yang terlihat dari temuan ini, semakin tinggi kepadatan set pengelompokan dan semakin banyak baris di tabel utama, semakin optimal strategi pencarian dibandingkan dengan strategi pemindaian. Jadi, dalam skenario kepadatan tinggi, pastikan Anda mencoba solusi berbasis APPLY. Sementara itu, kami berharap Microsoft akan menambahkan strategi ini sebagai opsi bawaan untuk kueri yang dikelompokkan.
Kesimpulan
Artikel ini menyimpulkan seri lima bagian tentang ambang pengoptimalan kueri untuk kueri yang mengelompokkan dan menggabungkan data. Salah satu tujuan seri ini adalah untuk membahas secara spesifik berbagai algoritme yang dapat digunakan pengoptimal, kondisi di mana setiap algoritme lebih disukai, dan kapan Anda harus campur tangan dengan penulisan ulang kueri Anda sendiri. Tujuan lainnya adalah untuk menjelaskan proses menemukan berbagai pilihan dan membandingkannya. Jelas, proses analisis yang sama dapat diterapkan untuk memfilter, menggabungkan, membuka jendela, dan banyak aspek lain dari pengoptimalan kueri. Mudah-mudahan, Anda sekarang merasa lebih siap untuk menangani penyetelan kueri daripada sebelumnya.