Recovery Time Objective (RTO) adalah periode waktu di mana layanan harus dipulihkan untuk menghindari konsekuensi yang tidak dapat diterima. Dengan menghitung berapa lama waktu yang dibutuhkan untuk pulih dari kegagalan database, kita dapat mengetahui tingkat persiapan yang diperlukan. Jika RTO hanya beberapa menit, maka investasi yang signifikan dalam failover diperlukan. RTO 36 jam membutuhkan investasi yang jauh lebih rendah. Di sinilah otomatisasi failover masuk.
Di blog kami sebelumnya, kami telah membahas failover untuk MongoDB, MySQL/MariaDB/Percona, PostgreSQL atau TimeScaleDB. Singkatnya, "Kegagalan " adalah kemampuan sistem untuk terus berfungsi bahkan jika beberapa kegagalan terjadi. Ini menunjukkan bahwa fungsi sistem diasumsikan oleh komponen sekunder jika komponen utama gagal. Failover adalah bagian alami dari sistem ketersediaan tinggi, dan dalam beberapa kasus , bahkan harus otomatis. Kegagalan manual memakan waktu terlalu lama, tetapi ada kasus di mana otomatisasi tidak akan bekerja dengan baik - misalnya dalam kasus otak terbelah di mana replikasi database rusak dan dua 'bagian' terus menerima pembaruan, secara efektif menyebabkan kumpulan data yang berbeda dan inkonsistensi.
Kami sebelumnya menulis tentang prinsip panduan di balik prosedur failover otomatis ClusterControl. Jika memungkinkan, failover otomatis memberikan efisiensi karena memungkinkan pemulihan cepat dari kegagalan. Di blog ini, kita akan melihat cara mencapai failover otomatis dalam pengaturan replikasi master-slave (atau primary-standby) menggunakan ClusterControl.
Persyaratan Tumpukan Teknologi
Tumpukan dapat dirakit dari komponen Perangkat Lunak Sumber Terbuka, dan ada sejumlah opsi yang tersedia - beberapa lebih sesuai daripada yang lain tergantung pada karakteristik failover dan juga tingkat keahlian yang tersedia untuk mengelola dan memelihara solusi. Perangkat keras dan jaringan juga merupakan aspek penting.
Perangkat Lunak
Ada banyak opsi yang tersedia di ekosistem open source yang dapat Anda gunakan untuk menerapkan failover. Untuk MySQL, Anda dapat memanfaatkan MHA, MMM, Maxscale/MRM, mysqlfailover, atau Orchestrator. Blog sebelumnya ini membandingkan MaxScale ke MHA dengan Maxscale/MRM. PostgreSQL memiliki repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II, atau stolon. Opsi ketersediaan tinggi yang berbeda ini telah dibahas sebelumnya. MongoDB memiliki set replika dengan dukungan untuk failover otomatis.
ClusterControl menyediakan fungsionalitas failover otomatis untuk MySQL, MariaDB, PostgreSQL, dan MongoDB, yang akan kita bahas lebih lanjut. Perlu diperhatikan bahwa ia juga memiliki fungsi untuk memulihkan node atau cluster yang rusak secara otomatis.
Perangkat Keras
Failover otomatis biasanya dilakukan oleh server daemon terpisah yang diatur pada perangkat kerasnya sendiri - terpisah dari node database. Ini memantau status database, dan menggunakan informasi untuk membuat keputusan tentang bagaimana bereaksi jika terjadi kegagalan.
Server komoditas dapat bekerja dengan baik, kecuali jika server memantau sejumlah besar instance. Biasanya, pemeriksaan sistem dan analisis kesehatan ringan dalam hal pemrosesan. Namun, jika Anda memiliki banyak node untuk diperiksa, CPU dan memori yang besar adalah suatu keharusan terutama ketika pemeriksaan harus diantrekan saat mencoba melakukan ping dan mengumpulkan informasi dari server. Node yang dipantau dan diawasi terkadang terhenti karena masalah jaringan, beban tinggi, atau pada kasus yang lebih buruk, node mungkin mati karena kegagalan perangkat keras atau kerusakan host VM. Jadi server yang menjalankan pemeriksaan kesehatan dan sistem harus mampu menahan gangguan seperti itu, karena kemungkinan pemrosesan antrian dapat meningkat karena respons terhadap setiap node yang dipantau dapat memakan waktu hingga diverifikasi bahwa itu tidak lagi tersedia atau batas waktu telah telah tercapai.
Untuk lingkungan berbasis cloud, ada layanan yang menawarkan failover otomatis. Misalnya, Amazon RDS menggunakan DRBD untuk mereplikasi penyimpanan ke node siaga. Atau jika Anda menyimpan volume Anda di EBS, ini direplikasi di beberapa zona.
Jaringan
Perangkat lunak failover otomatis sering bergantung pada agen yang diatur pada node database. Agen mengumpulkan informasi secara lokal dari instance database dan mengirimkannya ke server, kapan pun diminta.
Dalam hal persyaratan jaringan, pastikan Anda memiliki bandwidth yang baik dan koneksi jaringan yang stabil. Pemeriksaan harus sering dilakukan, dan detak jantung yang terlewat karena jaringan yang tidak stabil dapat menyebabkan perangkat lunak failover (salah) menyimpulkan bahwa sebuah node sedang down.
ClusterControl tidak memerlukan agen apa pun yang diinstal pada node database, karena akan melakukan SSH ke setiap node database secara berkala dan melakukan sejumlah pemeriksaan.
Failover Otomatis dengan ClusterControl
ClusterControl menawarkan kemampuan untuk melakukan failover manual dan otomatis. Mari kita lihat bagaimana ini bisa dilakukan.
Failover di ClusterControl dapat dikonfigurasi menjadi otomatis atau tidak. Jika Anda lebih suka menangani failover secara manual, Anda dapat menonaktifkan pemulihan cluster otomatis. Saat melakukan failover manual, Anda dapat pergi ke Cluster → Topology di ClusterControl. Lihat tangkapan layar di bawah ini:
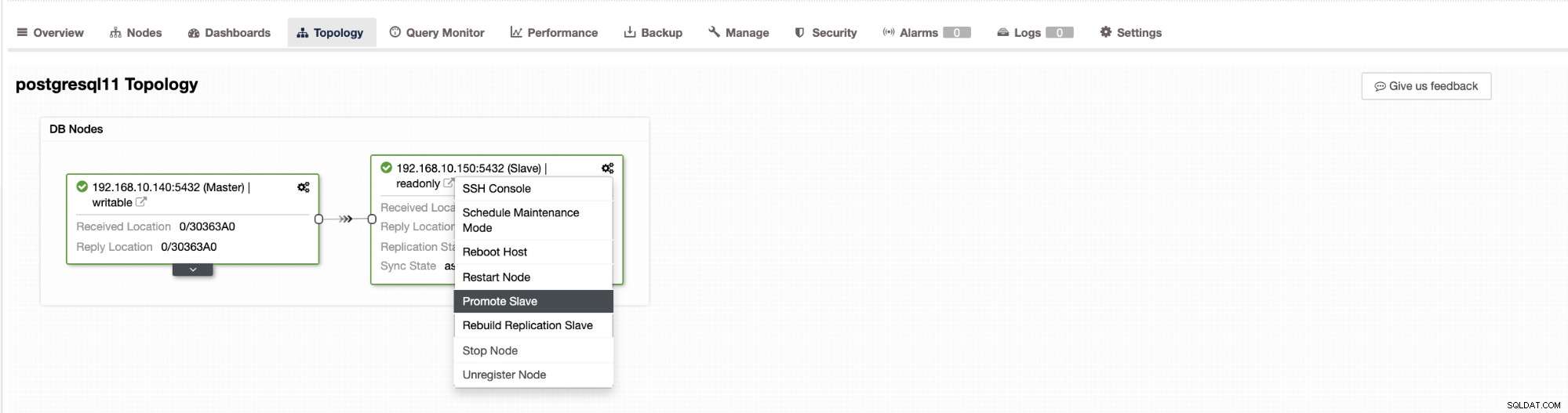
Secara default, pemulihan cluster diaktifkan dan failover otomatis digunakan. Setelah Anda membuat perubahan di UI, konfigurasi runtime akan berubah. Jika Anda ingin pengaturan bertahan dari restart controller, maka pastikan Anda juga membuat perubahan dalam konfigurasi cmon, yaitu /etc/cmon.d/cmon_

Di server MySQL/MariaDB/Percona, failover otomatis dimulai oleh ClusterControl ketika mendeteksi bahwa tidak ada host dengan read_only bendera dinonaktifkan. Itu bisa terjadi karena master (yang memiliki read_only set ke 0) tidak tersedia atau dapat dipicu oleh pengguna atau perangkat lunak eksternal yang mengubah tanda ini pada master. Jika Anda melakukan perubahan manual ke node basis data atau memiliki perangkat lunak yang mungkin mengutak-atik pengaturan read_only, maka Anda harus menonaktifkan failover otomatis. Failover otomatis ClusterControl hanya dicoba sekali, oleh karena itu, failover yang gagal tidak akan diikuti lagi oleh failover berikutnya - tidak sampai cmon di-restart.
Untuk PostgreSQL, ClusterControl akan memilih budak yang paling canggih, menggunakan untuk tujuan ini pg_current_xlog_location (PostgreSQL 9+) atau pg_current_wal_lsn (PostgreSQL 10+) tergantung pada versi database kami. ClusterControl juga melakukan beberapa pemeriksaan atas proses failover, untuk menghindari beberapa kesalahan umum. Salah satu contohnya adalah jika kita berhasil memulihkan master lama kita yang gagal, itu akan "tidak " akan diperkenalkan kembali secara otomatis ke cluster, baik sebagai master maupun sebagai budak. Kita perlu melakukannya secara manual. Hal ini akan menghindari kemungkinan kehilangan data atau inkonsistensi jika slave kita (yang kita promosikan) tertunda pada saat itu. kegagalan. Kami mungkin juga ingin menganalisis masalah secara mendetail sebelum memasukkannya kembali ke penyiapan replikasi, jadi kami ingin menyimpan informasi diagnostik.
Juga, jika failover gagal, tidak ada upaya lebih lanjut yang dilakukan (ini berlaku untuk cluster berbasis PostgreSQL dan MySQL), intervensi manual diperlukan untuk menganalisis masalah dan melakukan tindakan yang sesuai. Ini untuk menghindari situasi di mana ClusterControl, yang menangani failover otomatis, mencoba mempromosikan slave berikutnya dan berikutnya. Mungkin ada masalah, dan kami tidak ingin memperburuk keadaan dengan mencoba beberapa kali failover.
ClusterControl menawarkan daftar putih dan daftar hitam sekumpulan server yang ingin Anda ikuti dalam failover, atau kecualikan sebagai kandidat.
Untuk cluster tipe MySQL, ClusterControl membuat daftar budak yang dapat dipromosikan menjadi master. Sebagian besar waktu, itu akan berisi semua budak di topologi tetapi pengguna memiliki beberapa kontrol tambahan atasnya. Ada dua variabel yang dapat Anda atur dalam konfigurasi cmon:
replication_failover_whitelistdan
replication_failover_blacklistUntuk variabel konfigurasi replica_failover_whitelist, berisi daftar IP atau nama host dari slave yang harus digunakan sebagai calon master potensial. Jika variabel ini disetel, hanya host tersebut yang akan dipertimbangkan. Untuk variabel replica_failover_blacklist, berisi daftar host yang tidak akan pernah dianggap sebagai kandidat master. Anda dapat menggunakannya untuk membuat daftar budak yang digunakan untuk pencadangan atau kueri analitis. Jika perangkat kerasnya bervariasi antar slave, Anda mungkin ingin meletakkan di sini slave yang menggunakan perangkat keras yang lebih lambat.
replikasi_failover_whitelist didahulukan, artinya daftar replikasi_failover_blacklist akan diabaikan jika daftar replikasi_failover_whitelist disetel.
Setelah daftar budak yang dapat dipromosikan menjadi master sudah siap, ClusterControl mulai membandingkan status mereka, mencari budak terbaru. Di sini, penanganan setup berbasis MariaDB dan MySQL berbeda. Untuk pengaturan MariaDB, ClusterControl memilih slave yang memiliki jeda replikasi terendah dari semua slave yang tersedia. Untuk pengaturan MySQL, ClusterControl mengambil budak seperti itu juga tetapi kemudian memeriksa transaksi tambahan yang hilang yang dapat dieksekusi pada beberapa budak yang tersisa. Jika transaksi seperti itu ditemukan, ClusterControl menggunakan slave kandidat master dari host tersebut untuk mengambil semua transaksi yang hilang. Anda dapat melewati proses ini dan cukup gunakan slave yang paling canggih dengan menyetel variabel Replication_skip_apply_missing_txs di konfigurasi CMON Anda:
misalnya
replication_skip_apply_missing_txs=1Periksa dokumentasi kami di sini untuk informasi lebih lanjut dengan variabel.
Peringatan adalah bahwa Anda hanya harus mengatur ini jika Anda tahu apa yang Anda lakukan, karena mungkin ada transaksi yang salah. Ini mungkin menyebabkan replikasi rusak, serta inkonsistensi data di seluruh cluster. Jika transaksi yang salah terjadi di masa lalu, mungkin tidak lagi tersedia di log biner. Dalam hal ini, replikasi akan terputus karena budak tidak akan dapat mengambil data yang hilang. Oleh karena itu, ClusterControl, secara default, memeriksa transaksi yang salah sebelum mempromosikan kandidat master untuk menjadi master. Jika masalah tersebut terdeteksi, sakelar master dibatalkan dan ClusterControl memungkinkan pengguna memperbaiki masalah secara manual.
Jika Anda ingin 100% yakin bahwa ClusterControl akan mempromosikan master baru meskipun beberapa masalah terdeteksi, Anda dapat melakukannya dengan menggunakan variabel replica_stop_on_error. Lihat di bawah:
misalnya
replication_stop_on_error=0Setel variabel ini di file konfigurasi cmon Anda. Seperti disebutkan sebelumnya, ini dapat menyebabkan masalah dengan replikasi karena budak mungkin mulai meminta peristiwa log biner yang tidak tersedia lagi. Untuk menangani kasus seperti itu, kami menambahkan dukungan eksperimental untuk pembangunan kembali budak. Jika Anda mengatur variabel
replication_auto_rebuild_slave=1dalam konfigurasi cmon dan jika budak Anda ditandai dengan kesalahan berikut di MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl akan mencoba membangun kembali budak menggunakan data dari master. Pengaturan seperti itu mungkin tidak selalu tepat karena proses pembangunan kembali akan menyebabkan peningkatan beban pada master. Mungkin juga kumpulan data Anda sangat besar dan pembangunan kembali reguler bukanlah opsi - itulah sebabnya perilaku ini dinonaktifkan secara default.
Setelah kami memastikan bahwa tidak ada transaksi yang salah dan kami siap melakukannya, masih ada satu masalah lagi yang harus kami tangani - mungkin saja semua budak tertinggal di belakang master.
Seperti yang mungkin Anda ketahui, replikasi di MySQL bekerja dengan cara yang agak sederhana. Toko master menulis dalam log biner. Utas I/O slave terhubung ke master dan menarik setiap peristiwa log biner yang hilang. Kemudian menyimpannya dalam bentuk log relai. Utas SQL menguraikannya dan menerapkan acara. Slave lag adalah kondisi di mana utas SQL (atau utas) tidak dapat mengatasi jumlah peristiwa, dan tidak dapat menerapkannya segera setelah ditarik dari master oleh utas I/O. Situasi seperti itu dapat terjadi apa pun jenis replikasi yang Anda gunakan. Bahkan jika Anda menggunakan replikasi semi-sinkronisasi, itu hanya dapat menjamin bahwa semua peristiwa dari master disimpan di salah satu budak di log relai. Itu tidak mengatakan apa-apa tentang menerapkan peristiwa itu ke budak.
Masalahnya di sini adalah, jika seorang budak dipromosikan menjadi master, log relai akan dihapus. Jika slave tertinggal dan belum menerapkan semua transaksi, data akan hilang - peristiwa yang belum diterapkan dari log relai akan hilang selamanya.
Tidak ada satu cara untuk mengatasi semua situasi ini. ClusterControl memberi pengguna kendali atas bagaimana hal itu harus dilakukan, mempertahankan default yang aman. Itu dilakukan dalam konfigurasi cmon menggunakan pengaturan berikut:
replication_failover_wait_to_apply_timeout=-1Secara default dibutuhkan nilai '-1', yang berarti bahwa failover tidak akan segera terjadi jika kandidat master tertinggal, sehingga diatur untuk menunggu selamanya kecuali kandidat telah menyusul. ClusterControl akan menunggu tanpa batas waktu untuk menerapkan semua transaksi yang hilang dari log relai. Ini aman, tetapi, jika karena alasan tertentu, slave paling mutakhir sangat tertinggal, failover mungkin membutuhkan waktu berjam-jam untuk diselesaikan. Di sisi lain spektrum adalah mengaturnya ke '0' – itu berarti failover terjadi segera, tidak peduli apakah kandidat master tertinggal atau tidak. Anda juga dapat mengambil jalan tengah dan mengaturnya ke beberapa nilai. Ini akan mengatur waktu dalam detik, misalnya 30 detik jadi atur variabel ke,
replication_failover_wait_to_apply_timeout=30Ketika diatur ke> 0, ClusterControl akan menunggu kandidat master untuk menerapkan transaksi yang hilang dari log relai hingga nilainya terpenuhi (yaitu 30 detik dalam contoh). Failover terjadi setelah waktu yang ditentukan atau ketika kandidat master akan mengejar replikasi, mana yang terjadi lebih dulu. Ini mungkin pilihan yang baik jika aplikasi Anda memiliki persyaratan khusus terkait waktu henti dan Anda harus memilih master baru dalam waktu singkat.
Untuk detail selengkapnya tentang cara kerja ClusterControl dengan failover otomatis di PostgreSQL dan MySQL, periksa blog kami sebelumnya yang berjudul "Failover for PostgreSQL Replication 101" dan "Failover otomatis dari Replikasi MySQL - Baru di ClusterControl 1.4".
Kesimpulan
Failover Otomatis adalah fitur yang berharga, terutama untuk bisnis yang memerlukan operasi 24/7 dengan waktu henti yang minimal. Bisnis harus menentukan seberapa banyak kontrol yang diberikan pada proses otomatisasi selama pemadaman yang tidak direncanakan. Solusi ketersediaan tinggi seperti ClusterControl menawarkan tingkat interaksi yang dapat disesuaikan dalam pemrosesan failover. Untuk beberapa organisasi, failover otomatis mungkin bukan pilihan, meskipun interaksi pengguna selama failover dapat memakan waktu dan memengaruhi RTO. Asumsinya adalah terlalu berisiko jika failover otomatis tidak berfungsi dengan benar atau, lebih buruk lagi, mengakibatkan data menjadi kacau dan sebagian hilang (walaupun orang mungkin berpendapat bahwa manusia juga dapat membuat kesalahan fatal yang menyebabkan konsekuensi serupa). Mereka yang lebih memilih untuk tetap mengontrol database mereka dapat memilih untuk melewati failover otomatis dan menggunakan proses manual sebagai gantinya. Proses seperti itu membutuhkan lebih banyak waktu, tetapi memungkinkan admin yang berpengalaman untuk menilai status sistem dan mengambil tindakan korektif berdasarkan apa yang terjadi.