Dalam artikel saya sebelumnya, kami mulai menjelaskan dasar-dasar perintah EXPLAIN dan menganalisis apa yang terjadi di PostgreSQL saat menjalankan kueri.
Saya akan terus menulis tentang dasar-dasar EXPLAIN di PostgreSQL. Informasi tersebut merupakan review singkat dari Understanding EXPLAIN oleh Guillaume Lelarge. Saya sangat merekomendasikan membaca yang asli karena beberapa informasi terlewatkan.
Tembolok
Apa yang terjadi pada level fisik saat menjalankan kueri kita? Mari kita cari tahu. Saya menggunakan server saya di Ubuntu 13.10 dan menggunakan cache disk pada level OS.
Saya menghentikan PostgreSQL, melakukan perubahan pada sistem file, menghapus cache, dan menjalankan PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Saat cache dibersihkan, jalankan kueri dengan opsi BUFFERS
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Kami membaca tabel dengan blok. Cache kosong. Kami harus mengakses 8334 blok untuk membaca seluruh tabel dari disk.
Buffer:pembacaan bersama adalah jumlah blok yang dibaca PostgreSQL dari disk.
Jalankan kueri sebelumnya
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Buffer:hit bersama adalah jumlah blok yang diambil dari cache PostgreSQL.
Dengan setiap kueri, PostgreSQL mengambil lebih banyak data dari cache, dengan demikian, mengisi cache-nya sendiri.
Operasi baca cache lebih cepat daripada operasi baca disk. Anda dapat melihat tren ini dengan melacak nilai Total runtime.
Ukuran penyimpanan cache ditentukan oleh konstanta shared_buffers dalam file postgresql.conf.
DIMANA
Tambahkan kondisi ke kueri
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Tidak ada indeks di atas meja. Saat menjalankan kueri, setiap catatan tabel dipindai secara berurutan (Pemindaian Seq) dan dibandingkan dengan kondisi c1> 500. Jika kondisi terpenuhi, catatan ditambahkan ke hasil. Jika tidak, itu dibuang. Filter menunjukkan perilaku ini, serta peningkatan nilai biaya.
Perkiraan jumlah baris berkurang.
Artikel asli menjelaskan mengapa biaya mengambil nilai ini, dan bagaimana perkiraan jumlah baris dihitung.
Saatnya membuat indeks.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Perkiraan jumlah baris telah berubah. Bagaimana dengan indeks?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Hanya 510 baris lebih dari 1 juta yang difilter. PostgreSQL harus membaca lebih dari 99,9% tabel.
Kami akan memaksa untuk menggunakan indeks dengan menonaktifkan Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Dalam Pemindaian Indeks dan Indeks Cond, indeks foo_c1_idx digunakan sebagai ganti Filter.
Saat memilih seluruh tabel, menggunakan indeks akan meningkatkan biaya dan waktu untuk mengeksekusi kueri.
Aktifkan Pemindaian Seq:
SET enable_seqscan TO on;
Ubah kueri:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
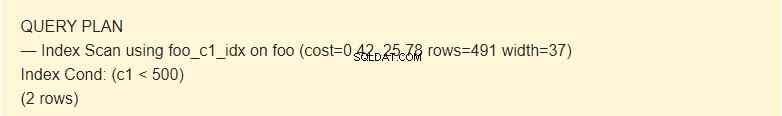
Di sini perencana menggunakan indeks.
Sekarang, mari kita rumitkan nilainya dengan menambahkan bidang teks.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Seperti yang Anda lihat, indeks foo_c1_idx digunakan untuk c1 <500. Untuk melakukan c2 ~~ ‘abcd%’::text, gunakan filter.
Perlu dicatat bahwa format POSIX dari operator LIKE digunakan dalam output hasil. Jika hanya ada kolom teks dalam kondisi:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Pemindaian Seq diterapkan.
Buat indeks dengan c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Indeks tidak diterapkan karena database saya untuk bidang pengujian menggunakan pengkodean UTF-8.
Saat membangun indeks, perlu untuk menentukan kelas operator text_pattern_ops:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Besar! Berhasil!
Pemindaian Indeks Bitmap menggunakan indeks foo_c2_idx1 untuk menentukan catatan yang kita butuhkan. Kemudian, PostgreSQL pergi ke tabel (Bitmap Heap Scan) untuk memastikan bahwa catatan ini benar-benar ada. Perilaku ini mengacu pada versi PostgreSQL.
Jika Anda hanya memilih bidang, tempat indeks dibuat, alih-alih seluruh baris:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Pemindaian Hanya Indeks akan dilakukan lebih cepat, daripada Pemindaian Indeks karena fakta bahwa tidak perlu membaca baris tabel:lebar=4.
Kesimpulan
- Seq Scan membaca seluruh tabel
- Pemindaian Indeks menggunakan indeks untuk pernyataan WHERE dan membaca tabel saat memilih baris
- Pemindaian Indeks Bitmap menggunakan Pemindaian Indeks dan kontrol pemilihan melalui tabel. Efektif untuk sejumlah besar baris.
- Pemindaian Hanya Indeks adalah blok tercepat, yang hanya membaca indeks.
Bacaan lebih lanjut:
Optimasi Kueri di PostgreSQL. JELASKAN Dasar – Bagian 3