Artikel ini adalah bagian kelima dari seri tentang bug, perangkap, dan praktik terbaik T-SQL. Sebelumnya saya membahas determinisme, subquery, join, dan windowing. Bulan ini, saya membahas tentang pivot dan unpivoting. Terima kasih Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man, dan Paul White atas saran Anda!
Dalam contoh saya, saya akan menggunakan database sampel yang disebut TSQLV5. Anda dapat menemukan skrip yang membuat dan mengisi database ini di sini, dan diagram ER-nya di sini.
Pengelompokan implisit dengan PIVOT
Ketika orang ingin melakukan pivot data menggunakan T-SQL, mereka menggunakan solusi standar dengan kueri yang dikelompokkan dan ekspresi CASE, atau operator tabel PIVOT berpemilik. Manfaat utama dari operator PIVOT adalah cenderung menghasilkan kode yang lebih pendek. Namun, operator ini memiliki beberapa kekurangan, di antaranya jebakan desain bawaan yang dapat mengakibatkan bug dalam kode Anda. Di sini saya akan menjelaskan jebakan, potensi bug, dan praktik terbaik yang mencegah bug. Saya juga akan menjelaskan saran untuk menyempurnakan sintaks operator PIVOT dengan cara yang membantu menghindari bug.
Saat Anda memutar data, ada tiga langkah yang terlibat dalam solusi, dengan tiga elemen terkait:
- Grup berdasarkan elemen pengelompokan/pada baris
- Menyebar berdasarkan elemen menyebar/pada cols
- Agregat berdasarkan agregasi/elemen data
Berikut adalah sintaks dari operator PIVOT:
SELECTFROM PIVOT( ( ) UNTUK IN( ) ) SEBAGAI ;
Desain operator PIVOT mengharuskan Anda untuk secara eksplisit menentukan elemen agregasi dan penyebaran, tetapi memungkinkan SQL Server secara implisit mengetahui elemen pengelompokan dengan eliminasi. Kolom mana pun yang muncul di tabel sumber yang disediakan sebagai input ke operator PIVOT, kolom tersebut secara implisit menjadi elemen pengelompokan.
Misalkan misalnya Anda ingin membuat kueri tabel Sales.Orders di database sampel TSQLV5. Anda ingin mengembalikan ID pengirim pada baris, tahun pengiriman pada kolom, dan jumlah pesanan per pengirim dan tahun sebagai agregat.
Banyak orang mengalami kesulitan mencari tahu sintaks operator PIVOT, dan ini sering mengakibatkan pengelompokan data berdasarkan elemen yang tidak diinginkan. Sebagai contoh dengan tugas kita, misalkan Anda tidak menyadari bahwa elemen pengelompokan ditentukan secara implisit, dan Anda membuat kueri berikut:
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) UNTUK tahun pengiriman IN([2017] , [2018], [2019]) ) AS P;
Hanya ada tiga pengirim yang ada dalam data, dengan ID pengirim 1, 2, dan 3. Jadi, Anda hanya akan melihat tiga baris dalam hasil. Namun, keluaran kueri yang sebenarnya menunjukkan lebih banyak baris:
shipperid 2017 2018 2019----------- ----------- ----------- ---------- -3 1 0 01 1 0 02 1 0 01 1 0 02 1 0 02 1 0 02 1 0 03 1 0 02 1 0 03 1 0 0...3 0 1 03 0 1 03 0 1 01 0 1 03 0 1 01 0 1 03 0 1 03 0 1 03 0 1 01 0 1 0...3 0 0 11 0 0 12 0 0 11 0 0 12 0 0 11 0 0 13 0 0 13 0 0 12 0 1 0...(830 baris terpengaruh)
Apa yang terjadi?
Anda dapat menemukan petunjuk yang akan membantu Anda mengetahui bug dalam kode dengan melihat rencana kueri yang ditunjukkan pada Gambar 1.
 Gambar 1:Rencanakan kueri pivot dengan pengelompokan implisit
Gambar 1:Rencanakan kueri pivot dengan pengelompokan implisit
Jangan biarkan penggunaan operator CROSS APPLY dengan klausa VALUES dalam kueri membingungkan Anda. Ini dilakukan hanya untuk menghitung kolom hasil tahun pengiriman berdasarkan kolom tanggal pengiriman sumber, dan ditangani oleh operator Hitung Skalar pertama dalam rencana.
Tabel input ke operator PIVOT berisi semua kolom dari tabel Sales.Orders, ditambah kolom hasil tahun pengiriman. Seperti yang disebutkan, SQL Server menentukan elemen pengelompokan secara implisit dengan eliminasi berdasarkan apa yang tidak Anda tentukan sebagai elemen agregasi (tanggal pengiriman) dan penyebaran (tahun pengiriman). Mungkin Anda secara intuitif mengharapkan kolom shipperid menjadi kolom pengelompokan karena muncul di daftar SELECT, tetapi seperti yang Anda lihat dalam rencana, dalam praktiknya Anda mendapatkan daftar kolom yang lebih panjang, termasuk orderid, yang merupakan kolom kunci utama di tabel sumber. Ini berarti bahwa alih-alih mendapatkan baris per pengirim, Anda mendapatkan baris per pesanan. Karena dalam daftar SELECT Anda hanya menentukan kolom shipperid, [2017], [2018] dan [2019], Anda tidak melihat sisanya, yang menambah kebingungan. Tapi sisanya memang mengambil bagian dalam pengelompokan tersirat.
Apa yang hebat adalah jika sintaks operator PIVOT mendukung klausa di mana Anda dapat secara eksplisit menunjukkan elemen pengelompokan/pada baris. Sesuatu seperti ini:
SELECTFROM PIVOT( ( ) UNTUK IN( ) PADA BARIS ) SEBAGAI ;
Berdasarkan sintaks ini, Anda akan menggunakan kode berikut untuk menangani tugas kita:
SELECT shipperid, [2017], [2018], [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) UNTUK tahun pengiriman IN([2017] , [2018], [2019]) ON ROWS shipperid ) AS P;
Anda dapat menemukan item umpan balik dengan saran untuk meningkatkan sintaks operator PIVOT di sini. Untuk menjadikan peningkatan ini sebagai perubahan yang tidak terputus, klausa ini dapat dibuat opsional, dengan default adalah perilaku yang ada. Ada saran lain untuk meningkatkan sintaks operator PIVOT dengan membuatnya lebih dinamis dan dengan mendukung beberapa agregat.
Sementara itu, ada praktik terbaik yang dapat membantu Anda menghindari bug. Gunakan ekspresi tabel seperti CTE atau tabel turunan di mana Anda hanya memproyeksikan tiga elemen yang Anda perlukan untuk terlibat dalam operasi pivot, lalu gunakan ekspresi tabel sebagai input ke operator PIVOT. Dengan cara ini, Anda sepenuhnya mengontrol elemen pengelompokan. Berikut sintaks umum yang mengikuti praktik terbaik ini:
DENGANAS( SELECT , , FROM )SELECT FROM PIVOT( ( ) UNTUK IN( ) ) SEBAGAI ;
Diterapkan pada tugas kami, Anda menggunakan kode berikut:
DENGAN C AS( SELECT shipperid, YEAR(shippeddate) SEBAGAi tahun pengiriman, tanggal pengiriman FROM Sales.Orders)PILIH shipperid, [2017], [2018], [2019]FROM C PIVOT( COUNT(tanggal pengiriman) UNTUK tahun pengiriman IN([ 2017], [2018], [2019]) ) AS P;
Kali ini Anda hanya mendapatkan tiga baris hasil seperti yang diharapkan:
shipperid 2017 2018 2019----------- ----------- ----------- ---------- -3 51 125 731 36 130 792 56 143 116
Opsi lainnya adalah menggunakan solusi standar lama dan klasik untuk memutar menggunakan kueri yang dikelompokkan dan ekspresi CASE, seperti:
SELECT shipperid, COUNT(CASE WHEN postedyear =2017 THEN 1 END) AS [2017], COUNT(CASE WHEN postedyear =2018 THEN 1 END) AS [2018], COUNT(CASE WHEN postedyear =2019 THEN 1 END) AS [2019]FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) SEBAGAI H(shippedyear)DIMANA tanggal pengiriman BUKAN NULLGROUP OLEH pengirim;
Dengan sintaks ini, ketiga langkah pivot dan elemen terkaitnya harus eksplisit dalam kode. Namun, ketika Anda memiliki banyak nilai penyebaran, sintaks ini cenderung bertele-tele. Dalam kasus seperti itu, orang sering lebih suka menggunakan operator PIVOT.
Penghapusan NULL secara implisit dengan UNPIVOT
Item berikutnya dalam artikel ini lebih merupakan jebakan daripada bug. Ini ada hubungannya dengan operator T-SQL UNPIVOT eksklusif, yang memungkinkan Anda melepaskan data dari status kolom ke status baris.
Saya akan menggunakan tabel bernama CustOrders sebagai sampel data saya. Gunakan kode berikut untuk membuat, mengisi, dan membuat kueri tabel ini untuk menampilkan kontennya:
DROP TABLE JIKA ADA dbo.CustOrders;GO WITH C AS( SELECT custid, YEAR(orderdate) AS orderyearyear, val FROM Sales.OrderValues)SELECT custid, [2017], [2018], [2019]INTO dbo.CustOrdersFROM C PIVOT( SUM(val) FOR orderyeartahun IN([2017], [2018], [2019]) ) AS P; PILIH * DARI dbo.CustOrders;
Kode ini menghasilkan output berikut:
custid 2017 2018 2019------- ---------- ---------- ----------1 NULL 2022.50 2250.502 88.80 799.75 514.403 403.20 5960.78 660.004 1379.00 6406.90 5604.755 4324.40 13849.02 6754.166 NULL 1079.80 2160.007 9986.20 7817.88 730.008 982.00 3026.85 224.009 4074.28 11208.36 6680.6110 1832.80 7630.25 11338.5611 479.40 3179.50 2431.0012 NULL 238.00 1576.8013 100.80 NULL NULL14 1674.22 6516.40 4158.2615 2169.00 1128.00 513.7516 NULL 787.60 931.5017 533.60 420.00 2809.6118 268.80 487.00 860.1019 950.00 4514.35 9296.6920 15568.07 48096.27 41210.65...
Tabel ini menyimpan total nilai pesanan per pelanggan dan tahun. NULL mewakili kasus di mana pelanggan tidak memiliki aktivitas pemesanan di tahun target.
Misalkan Anda ingin unpivot data dari tabel CustOrders, mengembalikan baris per pelanggan dan tahun, dengan kolom hasil yang disebut val memegang nilai pesanan total untuk pelanggan saat ini dan tahun. Setiap tugas unpivoting umumnya melibatkan tiga elemen:
- Nama-nama kolom sumber yang ada yang tidak Anda pilih:[2017], [2018], [2019] dalam kasus kami
- Nama yang Anda tetapkan ke kolom target yang akan menampung nama kolom sumber:orderyear dalam kasus kami
- Nama yang Anda tetapkan ke kolom target yang akan menampung nilai kolom sumber:val dalam kasus kami
Jika Anda memutuskan untuk menggunakan operator UNPIVOT untuk menangani tugas unpivoting, pertama-tama Anda mengetahui tiga elemen di atas, lalu gunakan sintaks berikut:
SELECT, , FROM UNPIVOT( FOR IN( ) ) SEBAGAI ;
Diterapkan pada tugas kami, Anda menggunakan kueri berikut:
PILIH custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Kueri ini menghasilkan keluaran berikut:
custid orderyear val------- ---------- ----------1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 403.203 2018 5960.783 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00...
Melihat data sumber dan hasil kueri, apakah Anda melihat apa yang hilang?
Desain operator UNPIVOT melibatkan eliminasi implisit dari baris hasil yang memiliki NULL di kolom nilai—val dalam kasus kami. Melihat rencana eksekusi untuk kueri ini yang ditunjukkan pada Gambar 2, Anda dapat melihat operator Filter menghapus baris dengan NULL di kolom val (Expr1007 dalam rencana).
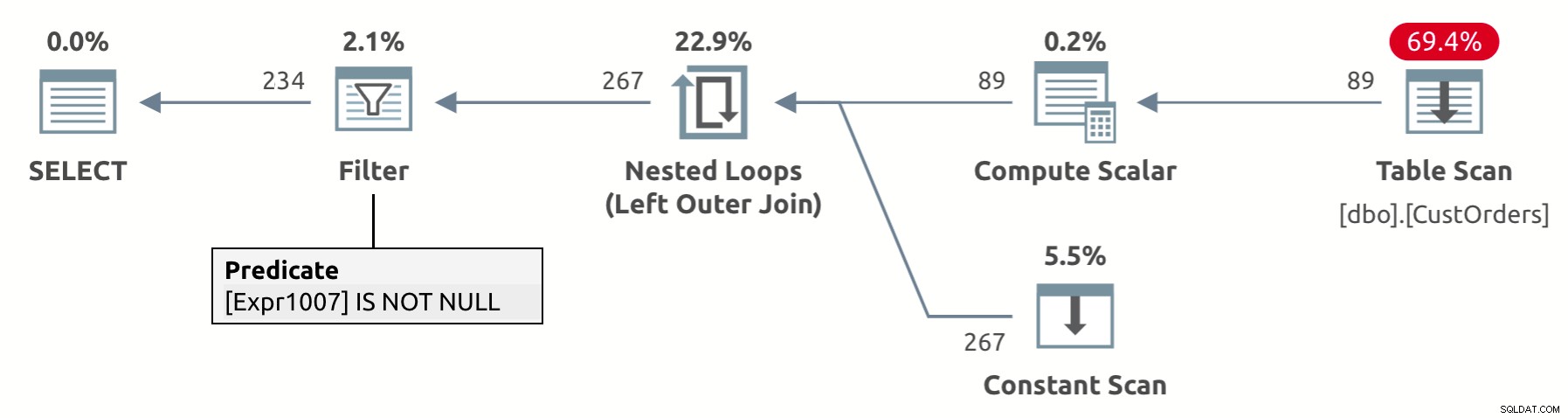 Gambar 2:Rencanakan kueri unpivot dengan penghapusan NULL secara implisit
Gambar 2:Rencanakan kueri unpivot dengan penghapusan NULL secara implisit
Terkadang perilaku ini diinginkan, dalam hal ini Anda tidak perlu melakukan sesuatu yang istimewa. Masalahnya adalah terkadang Anda ingin menyimpan baris dengan NULL. Perangkapnya adalah ketika Anda ingin menyimpan NULL dan Anda bahkan tidak menyadari bahwa operator UNPIVOT dirancang untuk menghapusnya.
Apa yang bisa menjadi hebat adalah jika operator UNPIVOT memiliki klausa opsional yang memungkinkan Anda untuk menentukan apakah Anda ingin menghapus atau menyimpan NULL, dengan yang pertama menjadi default untuk kompatibilitas mundur. Berikut ini contoh tampilan sintaks ini:
SELECT, , FROM UNPIVOT( FOR IN( ) [REMOVE NULLS | KEEP NULLS] ) SEBAGAI ; Jika Anda ingin mempertahankan NULL, berdasarkan sintaks ini Anda akan menggunakan kueri berikut:
PILIH custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;Anda dapat menemukan item umpan balik dengan saran untuk meningkatkan sintaks operator UNPIVOT dengan cara ini di sini.
Sementara itu, jika Anda ingin mempertahankan baris dengan NULL, Anda harus menemukan solusi. Jika Anda bersikeras menggunakan operator UNPIVOT, Anda perlu menerapkan dua langkah. Pada langkah pertama Anda menentukan ekspresi tabel berdasarkan kueri yang menggunakan fungsi ISNULL atau COALESCE untuk mengganti NULL di semua kolom yang tidak dipivot dengan nilai yang biasanya tidak dapat muncul dalam data, misalnya, -1 dalam kasus kami. Pada langkah kedua Anda menggunakan fungsi NULLIF di kueri luar terhadap kolom nilai untuk mengganti -1 kembali dengan NULL. Berikut kode solusi lengkapnya:
DENGAN C AS( SELECT custid, ISNULL([2017], -1.0) AS [2017], ISNULL([2018], -1.0) AS [2018], ISNULL([2019], -1.0) AS [2019 ] FROM dbo.CustOrders)SELECT custid, orderyear, NULLIF(val, -1.0) AS valFROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;Inilah output dari kueri ini yang menunjukkan bahwa baris dengan NULL di kolom val dipertahankan:
custid orderyear val------- ---------- ----------1 2017 NULL1 2018 2022.501 2019 2250.502 2017 88.802 2018 799.752 2019 514.403 2017 403.203 2018 5960.783 2019 660.004 2017 1379.004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2017 NULL6 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00...Pendekatan ini canggung, terutama jika Anda memiliki banyak kolom untuk dibatalkan.
Solusi alternatif menggunakan kombinasi operator APPLY dan klausa VALUES. Anda membuat baris untuk setiap kolom yang tidak dipivot, dengan satu kolom mewakili kolom nama target (orderyear dalam kasus kami), dan kolom lainnya mewakili kolom nilai target (val dalam kasus kami). Anda memberikan tahun konstan untuk kolom nama, dan kolom sumber terkait yang relevan untuk kolom nilai. Berikut kode solusi lengkapnya:
PILIH custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val);Hal yang menyenangkan di sini adalah bahwa kecuali Anda tertarik untuk menghapus baris dengan NULL di kolom val, Anda tidak perlu melakukan sesuatu yang istimewa. Tidak ada langkah implisit di sini yang menghapus baris dengan NULLS. Selain itu, karena alias kolom val dibuat sebagai bagian dari klausa FROM, ini dapat diakses oleh klausa WHERE. Jadi, jika Anda tertarik untuk menghapus NULL, Anda dapat mengungkapkannya secara eksplisit di klausa WHERE dengan berinteraksi langsung dengan alias kolom nilai, seperti:
PILIH custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) SEBAGAI (orderyear, val)WHERE val IS BUKAN NULL;Intinya adalah bahwa sintaks ini memberi Anda kendali apakah Anda ingin menyimpan atau menghapus NULL. Ini lebih fleksibel daripada operator UNPIVOT dengan cara lain, memungkinkan Anda menangani beberapa tindakan tanpa putaran seperti val dan qty. Fokus saya dalam artikel ini adalah perangkap yang melibatkan NULL, jadi saya tidak membahas aspek ini.
Kesimpulan
Desain operator PIVOT dan UNPIVOT terkadang menyebabkan bug dan jebakan dalam kode Anda. Sintaks operator PIVOT tidak memungkinkan Anda secara eksplisit menunjukkan elemen pengelompokan. Jika Anda tidak menyadarinya, Anda dapat berakhir dengan elemen pengelompokan yang tidak diinginkan. Sebagai praktik terbaik, Anda disarankan untuk menggunakan ekspresi tabel sebagai input ke operator PIVOT, dan inilah mengapa secara eksplisit mengontrol apa yang merupakan elemen pengelompokan.
Sintaks operator UNPIVOT tidak mengizinkan Anda mengontrol apakah akan menghapus atau menyimpan baris dengan NULL di kolom nilai hasil. Sebagai solusinya, Anda dapat menggunakan solusi canggung dengan fungsi ISNULL dan NULLIF, atau solusi berdasarkan operator APPLY dan klausa VALUES.
Saya juga menyebutkan dua item umpan balik dengan saran untuk meningkatkan operator PIVOT dan UNPIVOT dengan opsi yang lebih eksplisit untuk mengontrol perilaku operator dan elemennya.