Pengantar
Kumpulan kinerja adalah lazy spools yang ditambahkan oleh pengoptimal untuk mengurangi perkiraan biaya sisi dalam dari perulangan bersarang bergabung . Tersedia dalam tiga jenis:Lazy Table Spool , Kumpulan Indeks Malas , dan Kumpulan Jumlah Baris Malas . Contoh bentuk denah yang menunjukkan spool kinerja tabel malas di bawah ini:
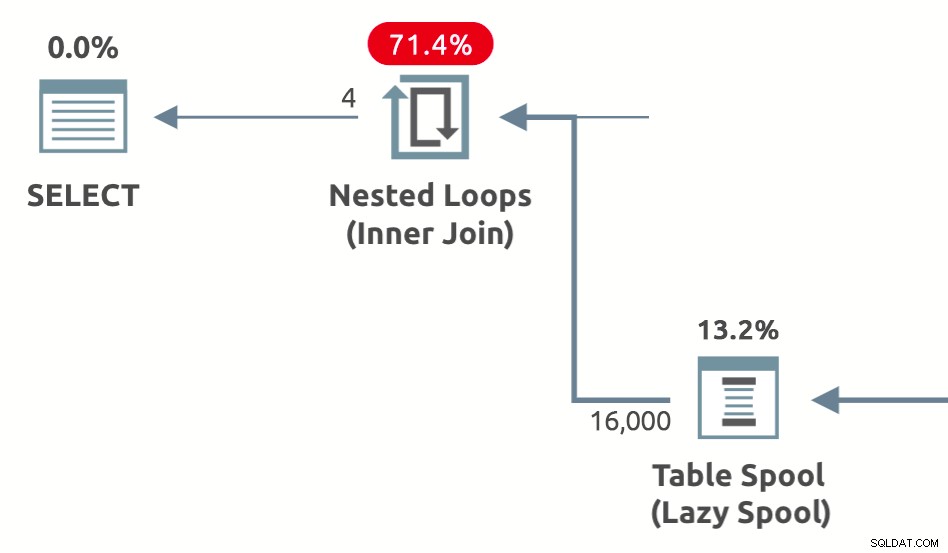
Pertanyaan yang ingin saya jawab dalam artikel ini adalah mengapa, bagaimana, dan kapan pengoptimal kueri memperkenalkan setiap jenis spool kinerja.
Tepat sebelum kita mulai, saya ingin menekankan poin penting:Ada dua tipe berbeda dari nested loop join dalam rencana eksekusi. Saya akan merujuk ke varietas dengan referensi luar sebagai lamar , dan tipe dengan predikat gabung pada operator gabungan itu sendiri sebagai penggabungan loop bersarang . Untuk lebih jelasnya, perbedaan ini adalah tentang operator rencana eksekusi , bukan sintaks kueri T-SQL. Untuk detail lebih lanjut, silakan lihat artikel saya yang tertaut.
Kumpulan Kinerja
Gambar di bawah menunjukkan spool kinerja operator rencana eksekusi seperti yang ditampilkan di Plan Explorer (baris atas) dan SSMS 18.3 (baris bawah):
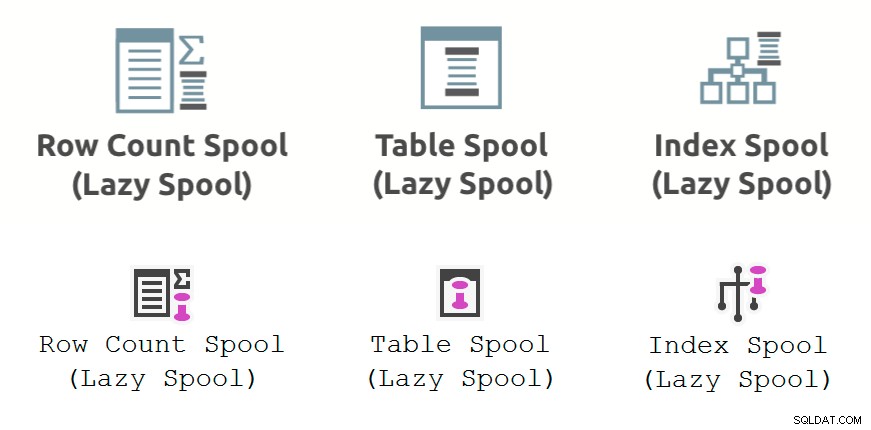
Keterangan umum
Semua spool kinerja malas . Meja kerja spool secara bertahap diisi, satu baris pada satu waktu, saat baris mengalir melalui spool. (Sebaliknya, Eager spool menggunakan semua input dari operator turunannya sebelum mengembalikan baris apa pun ke induknya).
Kumparan kinerja selalu muncul di sisi dalam (input yang lebih rendah dalam rencana eksekusi grafis) dari loop bersarang bergabung atau menerapkan operator. Ide umumnya adalah untuk menyimpan dan memutar ulang hasil, menyimpan eksekusi berulang dari operator sisi dalam jika memungkinkan.
Saat spool dapat memutar ulang hasil yang di-cache, ini dikenal sebagai mundur . Saat spool harus menjalankan operator turunannya untuk mendapatkan data yang benar, rebind terjadi.
Anda mungkin merasa terbantu untuk memikirkan spool rebind sebagai cache miss, dan mundur sebagai hit cache.
Spool Meja Malas
Jenis spool kinerja ini dapat digunakan dengan berlaku dan loop bersarang bergabung .
Terapkan
Sebuah rebind (cache miss) terjadi setiap kali referensi luar perubahan nilai. Kumparan meja malas di-rebind dengan memotong meja kerjanya dan mengisi ulang sepenuhnya dari operator turunannya.
Mundur (cache hit) terjadi ketika sisi dalam dieksekusi dengan sama nilai referensi luar sebagai yang mendahului iterasi lingkaran. Pemutaran ulang memutar ulang hasil yang di-cache dari meja kerja spool, menghemat biaya eksekusi ulang operator paket di bawah spool.
Catatan:Kumparan tabel malas hanya menyimpan hasil cache untuk satu set berlaku referensi luar nilai sekaligus.
Loop Bersarang Bergabung
Kumparan tabel malas diisi satu kali selama iterasi loop pertama. Spool memundurkan isinya untuk setiap iterasi berikutnya dari gabungan. Dengan gabungan loop bersarang, sisi dalam gabungan adalah kumpulan baris statis karena predikat gabungan ada pada gabungan itu sendiri. Oleh karena itu, kumpulan baris sisi dalam statis dapat di-cache dan digunakan kembali beberapa kali melalui spool. Loop bersarang bergabung dengan spool performa tidak pernah di-rebind.
Spool Hitung Baris Malas
Kumparan jumlah baris tidak lebih dari Spul Meja tanpa kolom. Ini menyimpan keberadaan baris, tetapi tidak memproyeksikan data kolom. Selain mencatat keberadaannya, dan menyebutkan bahwa itu bisa menjadi indikasi kesalahan dalam kueri sumber, saya tidak akan berbicara lebih banyak tentang gulungan jumlah baris.
Mulai saat ini, setiap kali Anda melihat “gulungan tabel” dalam teks, harap baca sebagai “gulungan tabel (atau jumlah baris)” karena keduanya sangat mirip.
Spool Indeks Malas
Kumpulan Indeks Malas operator hanya tersedia dengan apply .
Kumparan indeks mempertahankan meja kerja yang tidak terpotong ketika referensi luar nilai berubah. Sebagai gantinya, data baru ditambahkan ke cache yang ada, diindeks oleh nilai referensi luar. Spool indeks malas berbeda dari spool tabel malas karena dapat memutar ulang hasil dari apa saja iterasi loop sebelumnya, bukan hanya yang terbaru.
Langkah selanjutnya dalam memahami kapan spool kinerja muncul dalam rencana eksekusi memerlukan sedikit pemahaman tentang cara kerja pengoptimal.
Latar Belakang Pengoptimal
Sebuah query sumber diubah menjadi representasi pohon logis dengan parsing, aljabar, penyederhanaan, dan normalisasi. Ketika pohon yang dihasilkan tidak memenuhi syarat untuk rencana sepele, pengoptimal berbasis biaya mencari alternatif logis yang dijamin menghasilkan hasil yang sama, tetapi dengan perkiraan biaya yang lebih rendah.
Setelah pengoptimal menghasilkan alternatif potensial, pengoptimal mengimplementasikan masing-masing menggunakan operator fisik yang sesuai, dan menghitung perkiraan biaya. Rencana eksekusi akhir dibangun dari opsi biaya terendah yang ditemukan untuk setiap grup operator. Anda dapat membaca detail selengkapnya tentang proses tersebut dalam seri Penyelaman Mendalam Pengoptimal Kueri.
Kondisi umum yang diperlukan agar spool kinerja muncul di rencana akhir pengoptimal adalah:
- Pengoptimal harus menjelajah alternatif logis yang menyertakan spool logis dalam pengganti yang dihasilkan. Ini lebih kompleks daripada kedengarannya, jadi saya akan membongkar detailnya di bagian utama berikutnya.
- Spool logis harus dapat diterapkan sebagai gulungan fisik operator di mesin eksekusi. Untuk versi SQL Server modern, ini pada dasarnya berarti bahwa semua kolom kunci dalam spool indeks harus sebanding ketik, total tidak lebih dari 900 byte*, dengan 64 kolom kunci atau kurang.
- Yang terbaik rencana lengkap setelah optimasi berbasis biaya harus mencakup salah satu alternatif spool. Dengan kata lain, setiap pilihan berbasis biaya yang dibuat antara opsi spool dan non-spool harus menguntungkan spool.
* Nilai ini di-hard-code ke SQL Server dan tidak diubah setelah peningkatan menjadi 1700 byte untuk nonclustered kunci indeks dari SQL Server 2016 dan seterusnya. Ini karena indeks spool adalah berkelompok indeks, bukan indeks nonclustered.
Aturan Pengoptimal
Kami tidak dapat menentukan spool menggunakan T-SQL, jadi memasukkannya ke dalam rencana eksekusi berarti pengoptimal harus memilih untuk menambahkannya. Sebagai langkah pertama, ini berarti pengoptimal harus menyertakan spool logis di salah satu alternatif yang dipilih untuk dijelajahi.
Pengoptimal tidak secara menyeluruh menerapkan semua aturan ekivalensi logis yang diketahuinya ke setiap pohon kueri. Ini akan sia-sia, mengingat tujuan pengoptimal untuk menghasilkan rencana yang masuk akal dengan cepat. Ada beberapa aspek untuk ini. Pertama, pengoptimal berjalan secara bertahap, dengan aturan yang lebih murah dan lebih sering diterapkan dicoba terlebih dahulu. Jika rencana yang masuk akal ditemukan pada tahap awal, atau kueri tidak memenuhi syarat untuk tahap selanjutnya, upaya pengoptimalan dapat dihentikan lebih awal dengan rencana biaya terendah yang ditemukan sejauh ini. Strategi ini membantu mencegah menghabiskan lebih banyak waktu untuk pengoptimalan daripada yang dihemat oleh peningkatan biaya tambahan.
Pencocokan Aturan
Setiap operator logika di pohon kueri dengan cepat diperiksa untuk kecocokan pola dengan aturan yang tersedia di tahap pengoptimalan saat ini. Misalnya, setiap aturan hanya akan cocok dengan subset operator logika, dan mungkin juga memerlukan properti tertentu untuk ditempatkan, seperti input terurut yang dijamin. Aturan mungkin cocok dengan operasi logika individu (satu grup) atau beberapa grup yang berdekatan (subbagian dari rencana).
Setelah cocok, aturan kandidat diminta untuk menghasilkan nilai janji . Ini adalah angka yang menunjukkan seberapa besar kemungkinan aturan saat ini untuk menghasilkan hasil yang berguna, mengingat konteks lokal. Misalnya, aturan mungkin menghasilkan nilai janji yang lebih tinggi saat target memiliki banyak duplikat pada inputnya, perkiraan jumlah baris yang besar, input terurut yang dijamin, atau properti lain yang diinginkan.
Setelah aturan eksplorasi yang menjanjikan telah diidentifikasi, pengoptimal mengurutkannya ke dalam urutan nilai yang dijanjikan, dan mulai memintanya untuk menghasilkan pengganti logis yang baru. Setiap aturan dapat menghasilkan satu atau lebih pengganti yang nantinya akan diimplementasikan menggunakan operator fisik. Sebagai bagian dari proses itu, perkiraan biaya dihitung.
Maksud dari semua ini yang berlaku untuk spool kinerja adalah bahwa bentuk dan properti rencana logis harus kondusif untuk mencocokkan aturan berkemampuan spool, dan konteks lokal harus menghasilkan nilai janji yang cukup tinggi sehingga pengoptimal memilih untuk menghasilkan pengganti menggunakan aturan .
Aturan Spool
Ada sejumlah aturan yang mengeksplorasi penggabungan loop bersarang logis atau lamar alternatif. Beberapa aturan ini dapat menghasilkan satu atau lebih pengganti dengan jenis spool kinerja tertentu. Aturan lain yang cocok dengan loop bersarang bergabung atau berlaku tidak pernah menghasilkan alternatif spool.
Misalnya, aturan ApplyToNL mengimplementasikan logika menerapkan sebagai loop fisik bergabung dengan referensi luar. Aturan ini dapat menghasilkan beberapa alternatif setiap kali berjalan. Selain operator gabungan fisik, setiap pengganti mungkin berisi spool tabel malas, spul indeks malas, atau tidak ada spul sama sekali. Pengganti spool logis kemudian diimplementasikan secara individual dan dihitung biayanya sebagai spool fisik yang diketik dengan tepat, dengan aturan lain yang disebut BuildSpool .
Sebagai contoh kedua, aturan JNtoIdxLookup mengimplementasikan gabungan logis sebagai berlaku physical fisik , dengan pencarian indeks langsung di sisi dalam. Aturan ini tidak pernah menghasilkan alternatif dengan komponen spool. JNtoIdxLookup dievaluasi lebih awal dan mengembalikan nilai janji yang tinggi saat cocok, sehingga rencana pencarian indeks sederhana ditemukan dengan cepat.
Ketika pengoptimal menemukan alternatif berbiaya rendah seperti ini sejak awal, alternatif yang lebih kompleks mungkin secara agresif dipangkas atau dilewati seluruhnya. Alasannya adalah bahwa tidak masuk akal untuk mengejar opsi yang tidak mungkin memperbaiki alternatif berbiaya rendah yang sudah ditemukan. Demikian pula, tidak ada gunanya mengeksplorasi lebih jauh jika paket lengkap terbaik saat ini sudah memiliki total biaya yang cukup rendah.
Contoh aturan ketiga:Aturan JNtoNL mirip dengan ApplyToNL , tetapi hanya mengimplementasikan gabungan loop bersarang fisik , dengan gulungan meja malas, atau tanpa gulungan sama sekali. Aturan ini tidak pernah menghasilkan spool indeks karena jenis spool tersebut memerlukan penerapan.
Pembuatan dan Penetapan Biaya Spool
Aturan yang mampu menghasilkan spool logis tidak akan selalu melakukannya setiap kali dipanggil. Akan sia-sia untuk menghasilkan alternatif logis yang hampir tidak memiliki peluang untuk dipilih sebagai yang termurah. Ada juga biaya untuk menghasilkan alternatif baru, yang pada gilirannya dapat menghasilkan lebih banyak alternatif — yang masing-masing mungkin memerlukan implementasi dan penetapan biaya.
Untuk mengelola ini, pengoptimal menerapkan logika umum untuk semua aturan berkemampuan spool untuk menentukan jenis alternatif spool mana yang akan dihasilkan berdasarkan kondisi rencana lokal.
Loop Bersarang Bergabung
Untuk perulangan bersarang bergabung , peluang mendapatkan gulungan meja malas meningkat sejalan dengan:
- Perkiraan jumlah baris pada input luar gabungan.
- Perkiraan biaya operator rencana sisi dalam.
Biaya spool dilunasi dengan penghematan yang dilakukan dengan menghindari eksekusi operator sisi dalam. Penghematan meningkat dengan lebih banyak iterasi dalam, dan biaya sisi dalam yang lebih tinggi. Hal ini terutama benar karena model biaya menetapkan I/O dan nomor biaya CPU yang relatif rendah ke spool rewinds tabel (cache hits). Ingat bahwa spool tabel pada loop bersarang bergabung hanya pernah mengalami rewinds, karena kurangnya parameter berarti kumpulan data sisi dalam statis.
Spool dapat menyimpan data lebih padat daripada operator yang memberinya makan. Misalnya, indeks berkerumun tabel dasar mungkin menyimpan rata-rata 100 baris per halaman. Katakanlah kueri hanya membutuhkan nilai kolom bilangan bulat tunggal dari setiap baris indeks berkerumun lebar. Menyimpan hanya nilai integer di meja kerja spool berarti lebih dari 800 baris seperti itu dapat disimpan per halaman. Ini penting karena pengoptimal menilai sebagian biaya spool tabel menggunakan perkiraan jumlah halaman meja kerja diperlukan. Faktor biaya lainnya termasuk biaya CPU per baris yang terlibat dalam penulisan dan pembacaan spool, di atas perkiraan jumlah iterasi loop.
Pengoptimal bisa dibilang sedikit terlalu tertarik untuk menambahkan gulungan tabel malas ke sisi dalam dari gabungan loop bersarang. Namun demikian, keputusan pengoptimal selalu masuk akal dalam hal perkiraan biaya. Saya pribadi menganggap penggabungan loop bersarang sebagai berisiko tinggi , karena mereka dapat dengan cepat menjadi lambat jika salah satu dari perkiraan kardinalitas input terlalu rendah.
Sebuah gulungan meja mungkin membantu mengurangi biaya, tetapi tidak dapat sepenuhnya menyembunyikan kinerja terburuk dari gabungan loop bersarang naif. Penggabungan penerapan yang diindeks biasanya lebih disukai, dan lebih tahan terhadap kesalahan estimasi. Ini juga merupakan ide yang baik untuk menulis kueri yang dapat diterapkan oleh pengoptimal dengan hash atau gabungan gabungan bila perlu.
Terapkan Lazy Table Spool
Untuk lamar , peluang mendapatkan gulungan meja malas meningkat dengan perkiraan jumlah duplikat gabungkan nilai kunci pada input luar dari apply. Dengan lebih banyak duplikat, ada secara statistik peluang yang lebih tinggi dari spool untuk memutar ulang hasil yang saat ini disimpan pada setiap iterasi. Spool meja malas yang diterapkan dengan perkiraan biaya yang lebih rendah memiliki peluang yang lebih baik untuk ditampilkan dalam rencana eksekusi akhir.
Saat baris yang tiba di input luar yang berlaku tidak memiliki urutan tertentu, pengoptimal membuat penilaian statistik seberapa besar kemungkinan setiap iterasi menghasilkan rewind murah atau rebind mahal. Penilaian ini menggunakan data dari langkah-langkah histogram jika tersedia, tetapi bahkan skenario kasus terbaik ini lebih merupakan tebakan yang terdidik. Tanpa jaminan, urutan baris yang tiba di input luar yang berlaku tidak dapat diprediksi.
Aturan pengoptimal yang sama yang menghasilkan alternatif spool logis mungkin juga tentukan bahwa operator apply memerlukan baris yang diurutkan pada input luarnya. Ini memaksimalkan spool malas mundur karena semua duplikat dijamin akan ditemui dalam satu blok. Ketika urutan pengurutan input luar dijamin, baik dengan pemesanan yang dipertahankan atau Urutkan . eksplisit , biaya spool jauh berkurang. Faktor pengoptimal dalam dampak urutan pengurutan pada jumlah spool rewind dan rebind.
Paket dengan Urut pada input luar yang berlaku, dan Lazy Table Spool pada input batin cukup umum. Optimalisasi penyortiran sisi luar mungkin masih berakhir menjadi kontra-produktif. Misalnya, ini dapat terjadi ketika perkiraan kardinalitas sisi luar sangat rendah sehingga pengurutan berakhir dengan tempdb .
Terapkan Lazy Index Spool
Untuk lamar , mendapatkan gulungan indeks malas alternatif tergantung pada bentuk rencana serta biaya.
Pengoptimal membutuhkan:
- Beberapa duplikat gabungkan nilai pada input luar.
- Sebuah kesetaraan bergabung dengan predikat (atau setara logis yang dipahami pengoptimal, seperti
x <= y AND x >= y). - Sebuah jaminan bahwa referensi luarnya unik di bawah spool indeks malas yang diusulkan.
Dalam rencana eksekusi, keunikan yang diperlukan sering disediakan oleh pengelompokan agregat oleh referensi luar, atau agregat skalar (satu tanpa grup oleh). Keunikan juga dapat diberikan dengan cara lain, misalnya dengan adanya indeks atau batasan unik.
Contoh mainan yang menunjukkan bentuk denah di bawah ini:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
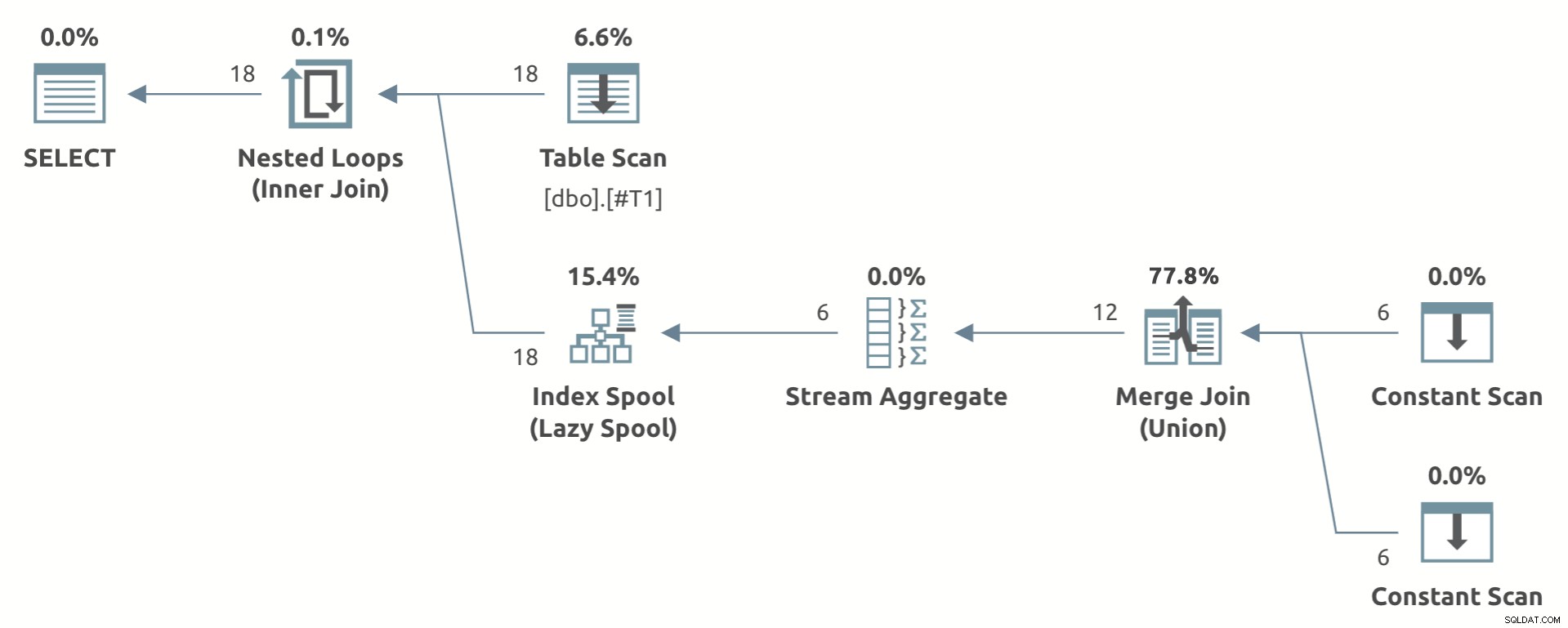
Perhatikan Stream Aggregate di bawah Spool Indeks Malas .
Jika persyaratan bentuk rencana terpenuhi, pengoptimal akan sering menghasilkan alternatif indeks malas (tunduk pada peringatan yang disebutkan sebelumnya). Apakah paket akhir menyertakan spool indeks malas atau tidak bergantung pada biaya.
Spool Indeks versus Spool Tabel
Jumlah perkiraan mundur dan mengembalikan untuk spool indeks malas adalah sama untuk spool meja malas tanpa diurutkan terapkan input luar.
Ini mungkin tampak seperti keadaan yang agak disayangkan. Keuntungan utama dari spool indeks adalah bahwa ia menyimpan semua hasil yang terlihat sebelumnya. Ini seharusnya membuat spool indeks mundur lebih mungkin daripada untuk spool tabel (tanpa penyortiran input luar) dalam keadaan yang sama. Pemahaman saya adalah bahwa quirk ini ada karena tanpanya, pengoptimal akan terlalu sering memilih spool indeks.
Terlepas dari itu, model biaya menyesuaikan hal di atas sampai batas tertentu dengan menggunakan nomor biaya I/O dan CPU baris awal dan selanjutnya yang berbeda untuk spool indeks dan tabel. Efek bersihnya adalah spool indeks biasanya diberi biaya lebih rendah daripada spool tabel tanpa input luar yang diurutkan, tetapi ingat persyaratan bentuk rencana yang membatasi, yang membuat spool indeks malas relatif langka.
Namun, pesaing biaya utama untuk indeks lazy spool adalah table spool dengan input luar yang diurutkan. Intuisi untuk ini cukup mudah:Input luar yang diurutkan berarti spool tabel dijamin untuk melihat semua referensi luar duplikat secara berurutan. Ini berarti akan rebind hanya sekali per nilai yang berbeda, dan mundur untuk semua duplikat. Ini sama dengan perilaku yang diharapkan dari spool indeks (setidaknya secara logika).
Dalam praktiknya, spool indeks lebih cenderung lebih disukai daripada spool tabel yang dioptimalkan untuk pengurutan karena lebih sedikit duplikat menerapkan nilai kunci. Memiliki lebih sedikit kunci duplikat akan mengurangi mundur keuntungan dari spool tabel pengurutan yang dioptimalkan, dibandingkan dengan perkiraan spool indeks “sayang” yang disebutkan sebelumnya.
Opsi spool indeks juga diuntungkan karena perkiraan biaya spool tabel sisi luar Urutkan meningkat. Ini paling sering dikaitkan dengan lebih banyak (atau lebih lebar) baris pada titik tersebut dalam rencana.
Melacak Bendera dan Petunjuk
-
Kumparan kinerja dapat dinonaktifkan dengan tanda jejak yang didokumentasikan dengan ringan 8690 , atau petunjuk kueri yang didokumentasikan
NO_PERFORMANCE_SPOOLdi SQL Server 2016 atau yang lebih baru. -
Bendera jejak tidak berdokumen 8691 dapat digunakan (pada sistem pengujian) untuk selalu menambahkan spool kinerja bila memungkinkan. jenis spool malas yang Anda dapatkan (jumlah baris, tabel, atau indeks) tidak dapat dipaksakan; masih tergantung estimasi biaya.
-
Bendera jejak tidak berdokumen 2363 dapat digunakan dengan model estimasi kardinalitas baru untuk melihat turunan dari estimasi berbeda pada input luar untuk aplikasi, dan estimasi kardinalitas secara umum.
-
Bendera jejak tidak berdokumen 9198 dapat digunakan untuk menonaktifkan spool kinerja indeks malas secara khusus. Anda mungkin masih mendapatkan tabel malas atau gulungan jumlah baris sebagai gantinya (dengan atau tanpa pengoptimalan pengurutan), bergantung pada biaya.
-
Bendera jejak tidak berdokumen 2387 dapat digunakan untuk mengurangi biaya CPU membaca baris dari gulungan indeks malas . Bendera ini memengaruhi perkiraan biaya CPU umum untuk membaca rentang baris dari b-tree. Bendera ini cenderung membuat pemilihan spool indeks lebih mungkin, karena alasan biaya.
Tanda pelacakan dan metode lain untuk menentukan aturan pengoptimal mana yang diaktifkan selama kompilasi kueri dapat ditemukan di seri Penyelaman Mendalam Pengoptimal Kueri.
Pemikiran Terakhir
Ada banyak sekali detail internal yang mempengaruhi apakah rencana eksekusi akhir menggunakan spool kinerja atau tidak. Saya telah mencoba untuk membahas pertimbangan utama dalam artikel ini, tanpa terlalu jauh ke detail yang sangat rumit dari rumus biaya operator spool. Semoga ada cukup saran umum di sini untuk membantu Anda menentukan kemungkinan alasan untuk jenis spool kinerja tertentu dalam rencana eksekusi (atau ketiadaannya).
Kumparan kinerja sering mendapatkan rap yang buruk, saya pikir itu adil untuk dikatakan. Beberapa di antaranya tidak diragukan lagi layak. Banyak dari Anda akan melihat demo di mana sebuah rencana dijalankan lebih cepat tanpa "spool kinerja" daripada dengan. Sampai batas tertentu itu tidak terduga. Kasus tepi ada, model penetapan biayanya tidak sempurna, dan tidak diragukan lagi, demo sering kali menampilkan paket dengan perkiraan kardinalitas yang buruk, atau masalah pembatas pengoptimal lainnya.
Yang mengatakan, saya kadang-kadang berharap SQL Server akan memberikan semacam peringatan atau umpan balik lain ketika resor untuk menambahkan spool tabel malas ke loop bersarang bergabung (atau aplikasi tanpa indeks sisi dalam pendukung yang digunakan). Seperti disebutkan di bagian utama, ini adalah situasi yang paling sering saya temukan salah, ketika perkiraan kardinalitas ternyata sangat rendah.
Mungkin suatu hari pengoptimal kueri akan mempertimbangkan beberapa konsep risiko untuk merencanakan pilihan, atau memberikan lebih banyak kemampuan "adaptif". Sementara itu, ada baiknya untuk mendukung penggabungan loop bersarang Anda dengan indeks yang berguna, dan untuk menghindari penulisan kueri yang hanya dapat diimplementasikan menggunakan loop bersarang jika memungkinkan. Saya menggeneralisasi tentu saja, tetapi pengoptimal cenderung bekerja lebih baik ketika memiliki lebih banyak pilihan, skema yang masuk akal, metadata yang baik, dan pernyataan T-SQL yang dapat dikelola untuk digunakan. Seperti saya, kalau dipikir-pikir.
Artikel spool lainnya
Spool non-kinerja digunakan untuk banyak tujuan dalam SQL Server, termasuk:
- Perlindungan Halloween
- Beberapa fungsi jendela mode baris
- Menghitung banyak agregat
- Mengoptimalkan pernyataan yang mengubah data



