Jenis dan jumlah kunci yang diperoleh dan dilepaskan selama eksekusi kueri dapat memiliki efek mengejutkan pada kinerja (saat menggunakan tingkat isolasi penguncian seperti komitmen baca default) bahkan saat tidak ada menunggu atau pemblokiran terjadi. Tidak ada informasi dalam rencana eksekusi untuk menunjukkan jumlah aktivitas penguncian selama eksekusi, yang membuatnya lebih sulit dikenali ketika penguncian berlebihan menyebabkan masalah kinerja.
Untuk menjelajahi beberapa perilaku penguncian yang kurang terkenal di SQL Server, saya akan menggunakan kembali kueri dan data sampel dari posting terakhir saya tentang menghitung median. Dalam posting itu, saya menyebutkan bahwa OFFSET solusi median yang dikelompokkan membutuhkan PAGLOCK yang eksplisit petunjuk penguncian untuk menghindari kehilangan kursor bersarang solusi, jadi mari kita mulai dengan melihat alasannya secara detail.
Solusi Median yang Dikelompokkan OFFSET
Tes median yang dikelompokkan menggunakan kembali data sampel dari artikel sebelumnya Aaron Bertrand. Skrip di bawah ini membuat ulang pengaturan sejuta baris ini, yang terdiri dari sepuluh ribu catatan untuk masing-masing dari seratus tenaga penjualan imajiner:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL Server 2012 (dan yang lebih baru) OFFSET solusi yang dibuat oleh Peter Larsson adalah sebagai berikut (tanpa petunjuk penguncian):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
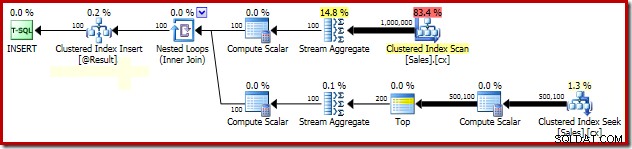
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Bagian penting dari rencana pasca-eksekusi ditunjukkan di bawah ini:

Dengan semua data yang diperlukan dalam memori, kueri ini dijalankan dalam 580 md rata-rata di laptop saya (menjalankan SQL Server 2014 Service Pack 1). Performa kueri ini dapat ditingkatkan menjadi 320 md cukup dengan menambahkan petunjuk penguncian perincian halaman ke tabel Penjualan di subkueri yang berlaku:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Rencana eksekusi tidak berubah (tentu saja, selain dari teks petunjuk penguncian di showplan XML):
Analisis Penguncian Median yang Dikelompokkan
Penjelasan untuk peningkatan dramatis dalam kinerja karena PAGLOCK petunjuknya cukup sederhana, setidaknya pada awalnya.
Jika kami memantau aktivitas penguncian secara manual saat kueri ini dijalankan, kami melihat bahwa tanpa petunjuk perincian penguncian halaman, SQL Server memperoleh dan melepaskan lebih dari setengah juta kunci tingkat baris sambil mencari indeks berkerumun. Tidak ada halangan untuk disalahkan; hanya memperoleh dan melepaskan banyak kunci ini menambahkan overhead yang cukup besar untuk eksekusi kueri ini. Meminta kunci tingkat halaman sangat mengurangi aktivitas penguncian, sehingga menghasilkan kinerja yang jauh lebih baik.
Masalah kinerja penguncian paket khusus ini terbatas pada pencarian indeks berkerumun dalam paket di atas. Pemindaian penuh indeks berkerumun (digunakan untuk menghitung jumlah baris yang ada untuk setiap staf penjualan) menggunakan kunci tingkat halaman secara otomatis. Ini adalah hal yang menarik. Perilaku penguncian terperinci dari mesin SQL Server tidak didokumentasikan dalam Buku Online untuk sebagian besar, tetapi berbagai anggota tim SQL Server telah membuat beberapa komentar umum selama bertahun-tahun, termasuk fakta pemindaian tidak terbatas cenderung mulai mengambil halaman kunci, sedangkan operasi yang lebih kecil cenderung dimulai dengan kunci baris.
Pengoptimal kueri memang membuat beberapa informasi tersedia untuk mesin penyimpanan, termasuk perkiraan kardinalitas, petunjuk internal untuk tingkat isolasi dan perincian penguncian, pengoptimalan internal mana yang dapat diterapkan dengan aman, dan seterusnya. Sekali lagi, rincian ini tidak didokumentasikan dalam Buku Daring. Pada akhirnya, mesin penyimpanan menggunakan berbagai informasi untuk memutuskan penguncian mana yang diperlukan pada waktu berjalan, dan pada perincian mana kunci tersebut harus diambil.
Sebagai catatan tambahan, dan mengingat bahwa kita berbicara tentang kueri yang dieksekusi di bawah penguncian default, baca tingkat isolasi transaksi berkomitmen, perhatikan bahwa kunci baris yang diambil tanpa petunjuk granularitas tidak akan meningkat menjadi kunci tabel dalam kasus ini. Ini karena perilaku normal dalam komitmen baca adalah melepaskan kunci sebelumnya tepat sebelum memperoleh kunci berikutnya, yang berarti bahwa hanya satu kunci baris bersama (dengan kunci bersama maksud tingkat yang lebih tinggi terkait) yang akan ditahan pada saat tertentu. Karena jumlah kunci baris yang dipegang secara bersamaan tidak pernah mencapai ambang batas, tidak ada eskalasi kunci yang dicoba.
Solusi Median Tunggal OFFSET
Tes kinerja untuk perhitungan median tunggal menggunakan kumpulan data sampel yang berbeda, sekali lagi direproduksi dari artikel Aaron sebelumnya. Skrip di bawah ini membuat tabel dengan sepuluh juta baris data pseudo-acak:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
OFFSET solusinya adalah:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Rencana pasca-eksekusi adalah:

Kueri ini dijalankan dalam 910 md rata-rata pada mesin uji saya. Performa tidak berubah jika PAGLOCK petunjuk ditambahkan, tetapi alasannya bukan itu yang mungkin Anda pikirkan…
Analisis Penguncian Median Tunggal
Anda mungkin mengharapkan mesin penyimpanan untuk memilih kunci bersama tingkat halaman, karena pemindaian indeks berkerumun, menjelaskan mengapa PAGLOCK petunjuk tidak berpengaruh. Faktanya, memantau kunci yang diambil saat kueri ini dijalankan mengungkapkan bahwa tidak ada kunci bersama (S) yang diambil sama sekali, pada perincian apa pun . Satu-satunya kunci yang diambil adalah intent-shared (IS) di tingkat objek dan halaman.
Penjelasan untuk perilaku ini datang dalam dua bagian. Hal pertama yang harus diperhatikan adalah bahwa Clustered Index Scan berada di bawah operator Top dalam rencana eksekusi. Ini memiliki efek penting pada perkiraan kardinalitas, seperti yang ditunjukkan dalam rencana pra-eksekusi (perkiraan):

OFFSET dan FETCH klausa dalam kueri merujuk ekspresi dan variabel, sehingga pengoptimal kueri menebak jumlah baris yang akan dibutuhkan saat runtime. Tebakan standar untuk Top adalah seratus baris. Ini tentu saja merupakan tebakan yang buruk, tetapi cukup untuk meyakinkan mesin penyimpanan untuk mengunci perincian baris, bukan pada tingkat halaman.
Jika kami menonaktifkan efek "tujuan baris" dari operator Top menggunakan tanda jejak terdokumentasi 4138, perkiraan jumlah baris pada pemindaian berubah menjadi sepuluh juta (yang masih salah, tetapi ke arah lain). Ini cukup untuk mengubah keputusan perincian penguncian mesin penyimpanan, sehingga kunci bersama tingkat halaman (catatan, bukan kunci bersama maksud) diambil:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Perkiraan rencana eksekusi yang dihasilkan di bawah bendera jejak 4138 adalah:

Kembali ke contoh utama, perkiraan seratus baris karena target baris yang ditebak berarti bahwa mesin penyimpanan memilih untuk mengunci pada tingkat baris. Namun, kami hanya mengamati penguncian intent-shared (IS) di tingkat tabel dan halaman. Kunci tingkat yang lebih tinggi ini akan cukup normal jika kita melihat kunci bersama (S) tingkat baris, jadi ke mana mereka pergi?
Jawabannya adalah bahwa mesin penyimpanan berisi pengoptimalan lain yang dapat melewati kunci bersama tingkat baris dalam keadaan tertentu. Saat pengoptimalan ini diterapkan, kunci bersama maksud tingkat yang lebih tinggi masih diperoleh.
Untuk meringkas, untuk kueri median tunggal:
- Penggunaan variabel dan ekspresi dalam
OFFSETklausa berarti pengoptimal menebak kardinalitas. - Perkiraan rendah berarti mesin penyimpanan memutuskan strategi penguncian tingkat baris.
- Pengoptimalan internal berarti kunci S tingkat baris dilewati saat waktu proses, hanya menyisakan kunci IS di tingkat halaman dan objek.
Kueri median tunggal akan memiliki masalah kinerja penguncian baris yang sama dengan median yang dikelompokkan (karena perkiraan pengoptimal kueri yang tidak akurat) tetapi disimpan oleh pengoptimalan mesin penyimpanan terpisah yang mengakibatkan hanya kunci halaman dan tabel yang dibagikan dengan maksud yang diambil saat runtime.
Tes Median Terkelompok Ditinjau Kembali
Anda mungkin bertanya-tanya mengapa Clustered Index Seek dalam pengujian median yang dikelompokkan tidak memanfaatkan pengoptimalan mesin penyimpanan yang sama untuk melewati kunci bersama tingkat baris. Mengapa begitu banyak kunci baris bersama digunakan, menjadikan PAGLOCK petunjuk yang diperlukan?
Jawaban singkatnya adalah pengoptimalan ini tidak tersedia untuk INSERT...SELECT pertanyaan. Jika kita menjalankan SELECT sendiri (yaitu tanpa menulis hasil ke tabel), dan tanpa PAGLOCK petunjuk, pengoptimalan melewatkan kunci baris adalah diterapkan:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Hanya kunci bersama (IS) tingkat tabel dan halaman yang digunakan, dan kinerja meningkat ke tingkat yang sama seperti saat kita menggunakan PAGLOCK petunjuk. Anda tentu tidak akan menemukan perilaku ini dalam dokumentasi, dan itu dapat berubah sewaktu-waktu. Namun, ada baiknya untuk diperhatikan.
Juga, jika Anda bertanya-tanya, trace flag 4138 tidak berpengaruh pada pilihan granularitas penguncian mesin penyimpanan dalam kasus ini karena perkiraan jumlah baris pada pencarian terlalu rendah (per iterasi penerapan) bahkan dengan tujuan baris dinonaktifkan.
Sebelum menarik kesimpulan tentang kinerja kueri, pastikan untuk memeriksa jumlah dan jenis kunci yang digunakan selama eksekusi. Meskipun SQL Server biasanya memilih perincian yang 'benar', ada kalanya hal itu bisa salah, terkadang dengan efek dramatis pada kinerja.