Saya secara singkat menyebutkan bahwa data mode batch dinormalisasi di artikel terakhir saya Batch Mode Bitmaps di SQL Server. Semua data dalam kumpulan diwakili oleh nilai delapan byte dalam format normal khusus ini, terlepas dari tipe data yang mendasarinya.
Pernyataan itu tidak diragukan lagi menimbulkan beberapa pertanyaan, paling tidak tentang bagaimana data dengan panjang yang jauh lebih besar dari delapan byte mungkin dapat disimpan dengan cara itu. Artikel ini membahas representasi normalisasi data batch, menjelaskan mengapa tidak semua tipe data delapan byte dapat ditampung dalam 64 bit, dan menunjukkan contoh bagaimana semua ini memengaruhi kinerja mode batch.
Demo
Saya akan mulai dengan contoh yang menunjukkan format data batch membuat perbedaan penting pada rencana eksekusi. Anda memerlukan SQL Server 2016 (atau lebih baru) dan Edisi Pengembang (atau yang setara) untuk mereproduksi hasil yang ditampilkan di sini.
Hal pertama yang kita perlukan adalah tabel bigint angka dari 1 hingga 102.400 inklusif. Angka-angka ini akan segera digunakan untuk mengisi tabel penyimpanan kolom (jumlah baris adalah jumlah minimum yang diperlukan untuk mendapatkan satu segmen terkompresi).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Penurunan agregat berhasil
Skrip berikut menggunakan tabel angka untuk membuat tabel lain yang berisi angka yang sama diimbangi dengan nilai tertentu. Tabel ini menggunakan columnstore untuk penyimpanan utamanya untuk menghasilkan eksekusi mode batch nanti.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Jalankan kueri pengujian berikut terhadap tabel columnstore baru:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Penambahan di dalam SUM adalah untuk menghindari overflow. Anda dapat melewati WHERE klausa (untuk menghindari rencana sepele) jika Anda menjalankan SQL Server 2017.
Kueri tersebut semuanya mendapat manfaat dari pushdown agregat. Agregat dihitung pada Columnstore Index Scan daripada mode batch Hash Aggregate operator. Rencana pasca-eksekusi menunjukkan nol baris yang dipancarkan oleh pemindaian. Semua 102.400 baris 'diagregasi secara lokal'.
SUM rencana ditunjukkan di bawah ini sebagai contoh:

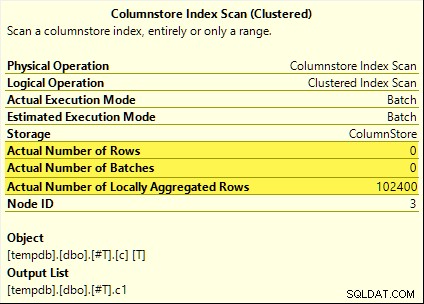
Penurunan agregat gagal
Sekarang jatuhkan lalu buat ulang tabel pengujian columnstore dengan offset dikurangi satu:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Jalankan kueri uji push-down agregat yang sama persis seperti sebelumnya:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Kali ini, hanya COUNT_BIG agregat mencapai pushdown agregat (hanya SQL Server 2017). MAX dan SUM agregat tidak. Ini SUM yang baru rencana untuk perbandingan dengan yang dari tes pertama:

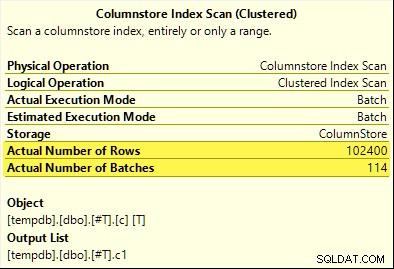
Semua 102.400 baris (dalam 114 batch) dipancarkan oleh Columnstore Index Scan , diproses oleh Compute Scalar , dan dikirim ke Hash Aggregate .
Mengapa perbedaan? Yang kami lakukan hanyalah mengimbangi rentang angka yang disimpan di tabel columnstore satu per satu!
Penjelasan
Saya sebutkan di pendahuluan bahwa tidak semua tipe data delapan byte dapat ditampung dalam 64 bit. Fakta ini penting karena banyak pengoptimalan kinerja mode kolom dan batch hanya berfungsi dengan data berukuran 64 bit. Pushdown agregat adalah salah satunya. Ada banyak lagi fitur kinerja (tidak semuanya didokumentasikan) yang berfungsi paling baik (atau tidak sama sekali) hanya jika datanya cocok dalam 64 bit.
Dalam contoh spesifik kami, pushdown agregat dinonaktifkan untuk segmen toko kolom bila berisi bahkan satu nilai data yang tidak sesuai dengan 64 bit. SQL Server dapat menentukan ini dari metadata nilai minimum dan maksimum yang terkait dengan setiap segmen tanpa memeriksa semua data. Setiap segmen dievaluasi secara terpisah.
Pushdown agregat masih berfungsi untuk COUNT_BIG agregat hanya di tes kedua. Ini adalah pengoptimalan yang ditambahkan di beberapa titik di SQL Server 2017 (pengujian saya dijalankan pada CU16). Adalah logis untuk tidak menonaktifkan pushdown agregat saat kita hanya menghitung baris, dan tidak melakukan apa pun dengan nilai data tertentu. Saya tidak dapat menemukan dokumentasi apa pun untuk peningkatan ini, tetapi hal itu tidak terlalu aneh akhir-akhir ini.
Sebagai catatan tambahan, saya perhatikan bahwa SQL Server 2017 CU16 mengaktifkan pushdown agregat untuk tipe data real yang sebelumnya tidak didukung , float , datetimeoffset , dan numeric dengan presisi lebih besar dari 18 — ketika data cocok dalam 64 bit. Ini juga tidak didokumentasikan pada saat penulisan.
Oke, tapi kenapa?
Anda mungkin mengajukan pertanyaan yang sangat masuk akal:Mengapa satu set bigint nilai pengujian tampaknya cocok dalam 64 bit tetapi yang lainnya tidak?
Jika Anda menebak alasannya terkait dengan NULL , beri tanda centang. Meskipun kolom tabel pengujian didefinisikan sebagai NOT NULL , SQL Server menggunakan tata letak data normal yang sama untuk bigint apakah data memungkinkan nol atau tidak. Ada beberapa alasan untuk ini, yang akan saya uraikan sedikit demi sedikit.
Mari saya mulai dengan beberapa pengamatan:
- Setiap nilai kolom dalam satu batch disimpan tepat dalam delapan byte (64 bit) terlepas dari tipe data yang mendasarinya. Tata letak ukuran tetap ini membuat segalanya lebih mudah dan lebih cepat. Eksekusi mode batch adalah tentang kecepatan.
- Satu batch berukuran 64KB dan berisi antara 64 dan 900 baris, bergantung pada jumlah kolom yang diproyeksikan. Ini masuk akal mengingat ukuran data kolom ditetapkan pada 64 bit. Lebih banyak kolom berarti lebih sedikit baris yang dapat ditampung dalam setiap batch 64KB.
- Tidak semua tipe data SQL Server dapat ditampung dalam 64 bit, bahkan pada prinsipnya. Sebuah string panjang (untuk mengambil satu contoh) bahkan mungkin tidak muat dalam satu batch 64KB (jika diizinkan), apalagi satu entri 64-bit.
SQL Server memecahkan masalah terakhir ini dengan menyimpan referensi 8-byte untuk data yang lebih besar dari 64 bit. Nilai data 'besar' disimpan di tempat lain di memori. Anda dapat menyebut pengaturan ini sebagai penyimpanan "off-row" atau "out-of-batch". Secara internal ini disebut sebagai data dalam .
Sekarang, tipe data delapan byte tidak dapat ditampung dalam 64 bit saat nullable. Ambil bigint NULL Misalnya . Rentang data non-null mungkin memerlukan 64 bit penuh, dan kita masih membutuhkan bit lain untuk menunjukkan nol atau tidak.
Memecahkan masalah
Solusi kreatif dan efisien untuk tantangan ini adalah memesan bagian terendah yang signifikan (LSB) dari nilai 64-bit sebagai flag. Bendera menunjukkan dalam-batch penyimpanan data saat LSB jelas (diatur ke nol). Saat LSB disetel (ke satu), itu bisa berarti salah satu dari dua hal:
- Nilainya nol; atau
- Nilai disimpan secara off-batch (ini adalah data yang dalam).
Kedua kasus ini dibedakan oleh keadaan 63 bit yang tersisa. Saat mereka semuanya nol , nilainya adalah NULL . Jika tidak, 'nilai' adalah penunjuk ke data dalam yang disimpan di tempat lain.
Jika dilihat sebagai bilangan bulat, menyetel LSB berarti penunjuk ke data dalam akan selalu ganjil angka. Null diwakili oleh angka (ganjil) 1 (semua bit lainnya adalah nol). Data dalam batch diwakili oleh genap angka karena LSB adalah nol.
Ini tidak berarti SQL Server hanya dapat menyimpan angka genap dalam satu batch! Itu hanya berarti representasi yang dinormalisasi dari nilai kolom yang mendasarinya akan selalu memiliki LSB nol saat disimpan "dalam-batch". Ini akan lebih masuk akal dalam beberapa saat.
Normalisasi Data Batch
Normalisasi dilakukan dengan cara yang berbeda, tergantung pada tipe data yang mendasarinya. Untuk bigint prosesnya adalah:
- Jika datanya null , simpan nilai 1 (hanya set LSB).
- Jika nilainya dapat direpresentasikan dalam 63 bit , geser semua bit satu tempat ke kiri dan nolkan LSB. Saat melihat nilai sebagai bilangan bulat, ini berarti menggandakan nilai. Misalnya
bigintnilai 1 dinormalisasi ke nilai 2. Dalam biner, yaitu tujuh byte semua-nol diikuti oleh00000010. LSB menjadi nol menunjukkan ini adalah data yang disimpan inline. Ketika SQL Server membutuhkan nilai asli, itu menggeser nilai 64-bit ke kanan satu posisi (membuang bendera LSB). - Jika nilainya tidak bisa direpresentasikan dalam 63 bit, nilainya disimpan secara off-batch sebagai data dalam . Pointer dalam-batch memiliki set LSB (menjadikannya bilangan ganjil).
Proses pengujian apakah bigint nilai yang dapat ditampung dalam 63 bit adalah:
- Simpan yang mentah*
bigintnilai dalam register prosesor 64-bitr8. - Menyimpan dua kali lipat nilai
r8di registerrax. - Geser bit
raxsatu tempat ke kanan. - Uji apakah nilai dalam
raxdanr8setara.
* Perhatikan bahwa nilai mentah tidak dapat ditentukan dengan andal untuk semua tipe data dengan konversi T-SQL ke tipe biner. Hasil T-SQL mungkin memiliki urutan byte yang berbeda dan mungkin juga berisi metadata mis. time presisi sepersekian detik.
Jika pengujian pada langkah 4 berhasil, kita tahu bahwa nilainya dapat digandakan dan kemudian dibagi dua dalam 64 bit — mempertahankan nilai aslinya.
Rentang yang dikurangi
Hasil dari semua ini adalah bahwa kisaran bigint nilai yang dapat disimpan dalam batch dikurangi satu bit (karena LSB tidak tersedia). Rentang inklusif berikut bigint nilai akan disimpan secara off-batch sebagai data dalam :
- -4.611.686.018.427.387.905 sampai -9.223.372.036.854.775.808
- +4.611.686.018.427.387.904 hingga +9.223.372.036.854.775.807
Sebagai imbalan untuk menerima bahwa bigint batasan jangkauan, normalisasi memungkinkan SQL Server untuk menyimpan (sebagian besar) bigint nilai, nol, dan referensi data dalam dalam kumpulan . Ini jauh lebih sederhana dan lebih hemat ruang daripada memiliki struktur terpisah untuk nullability dan referensi data yang dalam. Ini juga membuat pemrosesan data batch dengan instruksi prosesor SIMD menjadi jauh lebih mudah.
Normalisasi tipe data lain
SQL Server berisi normalisasi kode untuk setiap tipe data yang didukung oleh eksekusi mode batch. Setiap rutinitas dioptimalkan untuk menangani tata letak biner yang masuk secara efisien, dan hanya membuat data yang dalam bila diperlukan. Normalisasi selalu menghasilkan LSB yang dicadangkan untuk menunjukkan null atau data dalam, tetapi tata letak 63 bit yang tersisa bervariasi per tipe data.
Selalu dalam-batch
Data yang dinormalisasi untuk tipe data berikut selalu disimpan dalam kumpulan karena mereka tidak pernah membutuhkan lebih dari 63 bit:
datetime(n)– diskalakan ulang secara internal ketime(7)datetime2(n)– diskalakan ulang secara internal kedatetime2(7)integersmallinttinyintbit– menggunakantinyintimplementasi.smalldatetimedatetimerealfloatsmallmoney
Tergantung
Jenis data berikut dapat disimpan dalam kumpulan atau data dalam tergantung pada nilai datanya:
bigint– seperti yang dijelaskan sebelumnya.money– rentang in-batch yang sama denganbiginttapi dibagi 10.000.numeric/decimal– 18 digit desimal atau kurang dalam batch terlepas dari dari presisi yang dinyatakan. Misalnyadecimal(38,9)nilai -999999999.999999999 dapat direpresentasikan sebagai bilangan bulat 8 byte -999999999999999999 (f21f494c589c0001hex), yang dapat digandakan menjadi -1999999999999999998 (e43e9298b1380002hex) secara reversibel dalam 64 bit. SQL Server tahu di mana titik desimal pergi dari skala tipe data.datetimeoffset(n)– dalam-batch jika nilai runtime akan muat didatetimeoffset(2)terlepas dari presisi detik pecahan yang dideklarasikan.timestamp– format internal berbeda dari tampilan. Misalnyatimestampditampilkan dari T-SQL sebagai0x000000000099449Adirepresentasikan secara internal sebagai9a449900 00000000(dalam heksa). Nilai ini disimpan sebagai data dalam karena tidak muat dalam 64-bit saat digandakan (digeser kiri satu bit).
Selalu data yang dalam
Berikut ini selalu disimpan sebagai data dalam (kecuali nulls) :
uniqueidentifiervarbinary(n)– termasuk(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnametermasuk(max)– jenis ini juga dapat menggunakan kamus (bila tersedia).text/ntext/image/xml– menggunakanvarbinary(n)implementasi.
Agar jelas, nol untuk semua tipe data yang kompatibel dengan mode batch disimpan dalam batch sebagai nilai khusus 'satu'.
Pemikiran Terakhir
Anda mungkin berharap untuk memanfaatkan yang terbaik dari pengoptimalan penyimpanan kolom dan mode batch yang tersedia saat menggunakan tipe data dan nilai yang sesuai dengan 64 bit. Anda juga akan memiliki peluang terbaik untuk mendapatkan manfaat dari peningkatan produk tambahan dari waktu ke waktu, misalnya peningkatan terbaru untuk agregat pushdown yang disebutkan dalam teks utama. Tidak semua keuntungan kinerja akan begitu terlihat dalam rencana eksekusi, atau bahkan didokumentasikan. Namun demikian, perbedaannya bisa sangat signifikan.
Saya juga harus menyebutkan bahwa data dinormalisasi ketika operator rencana eksekusi mode baris menyediakan data ke mode induk batch, atau ketika pemindaian non-columnstore menghasilkan batch (mode batch pada rowstore). Ada adaptor baris-ke-batch yang tidak terlihat yang memanggil rutinitas normalisasi yang sesuai pada setiap nilai kolom sebelum menambahkannya ke batch. Menghindari tipe data dengan normalisasi yang rumit dan penyimpanan data yang dalam juga dapat menghasilkan manfaat kinerja di sini.