Bulan lalu saya meliput tantangan Kepulauan Khusus. Tugasnya adalah mengidentifikasi periode aktivitas untuk setiap ID layanan, menoleransi jeda hingga beberapa detik masukan (@allowedgap ). Peringatannya adalah bahwa solusinya harus kompatibel dengan pra-2012, jadi Anda tidak dapat menggunakan fungsi seperti LAG dan LEAD, atau menggabungkan fungsi jendela dengan bingkai. Saya mendapat sejumlah solusi yang sangat menarik yang diposting di komentar oleh Toby Ovod-Everett, Peter Larsson, dan Kamil Kosno. Pastikan untuk membahas solusi mereka karena semuanya cukup kreatif.
Anehnya, sejumlah solusi berjalan lebih lambat dengan indeks yang direkomendasikan daripada tanpa indeks. Dalam artikel ini saya mengusulkan penjelasan untuk ini.
Meskipun semua solusi menarik, di sini saya ingin fokus pada solusi oleh Kamil Kosno, yang merupakan pengembang ETL dengan Zopa. Dalam solusinya, Kamil menggunakan teknik yang sangat kreatif untuk meniru LAG dan LEAD tanpa LAG dan LEAD. Anda mungkin akan menemukan teknik ini berguna jika Anda perlu melakukan perhitungan seperti LAG/LEAD menggunakan kode yang kompatibel dengan pra-2012.
Mengapa beberapa solusi lebih cepat tanpa indeks yang direkomendasikan?
Sebagai pengingat, saya menyarankan menggunakan indeks berikut untuk mendukung solusi tantangan:
BUAT INDEX idx_sid_ltm_lid PADA dbo.EventLog(serviceid, logtime, logid);
Solusi saya yang kompatibel dengan pra-2012 adalah sebagai berikut:
MENNYATAKAN @allowedgap SEBAGAI INT =66; -- dalam hitungan detik DENGAN C1 AS( SELECT logid, serviceid, logtime AS s, -- important, 's'> 'e', untuk pemesanan nanti DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION OLEH serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog), C2 AS ( SELECT logid, serviceid, logtime, eventtype, counteach, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countkeduanya DARI C1 UNPIVOT(logtime UNTUK eventtype IN (s, e)) AS U),C3 AS( SELECT serviceid, eventtype, logtime, (ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp FROM C2 CROSS APPLY ( VALUES( CASE WHEN eventtype ='s' THEN counteach - (countboth - counteach) WHEN eventtype ='e' THEN (countboth - counteach) - counteach END ) ) AS A(countactive) WHERE ( eventtype ='s' DAN countactive =1) OR (eventtype ='e' AND countactive =0))SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtimeFROM C3 PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P;
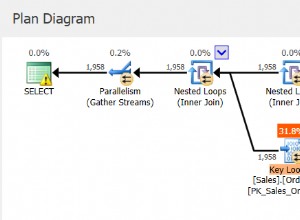
Gambar 1 memiliki rencana untuk solusi saya dengan indeks yang direkomendasikan.
 Gambar 1:Rencanakan solusi Itzik dengan indeks yang direkomendasikan
Gambar 1:Rencanakan solusi Itzik dengan indeks yang direkomendasikan
Perhatikan bahwa paket memindai indeks yang direkomendasikan dalam urutan kunci (Properti yang dipesan adalah Benar), mempartisi aliran dengan serviceid menggunakan pertukaran yang mempertahankan pesanan, dan kemudian menerapkan perhitungan awal nomor baris yang mengandalkan urutan indeks tanpa perlu menyortir. Berikut adalah statistik kinerja yang saya dapatkan untuk eksekusi kueri ini di laptop saya (waktu berlalu, waktu CPU, dan waktu tunggu teratas dinyatakan dalam detik):
berlalu:43, CPU:60, pembacaan logis:144.120 , tunggu atas:CXPACKET:166
Saya kemudian menjatuhkan indeks yang direkomendasikan dan menjalankan kembali solusinya:
JADIKAN INDEKS idx_sid_ltm_lid PADA dbo.EventLog;
Saya mendapatkan rencana yang ditunjukkan pada Gambar 2.
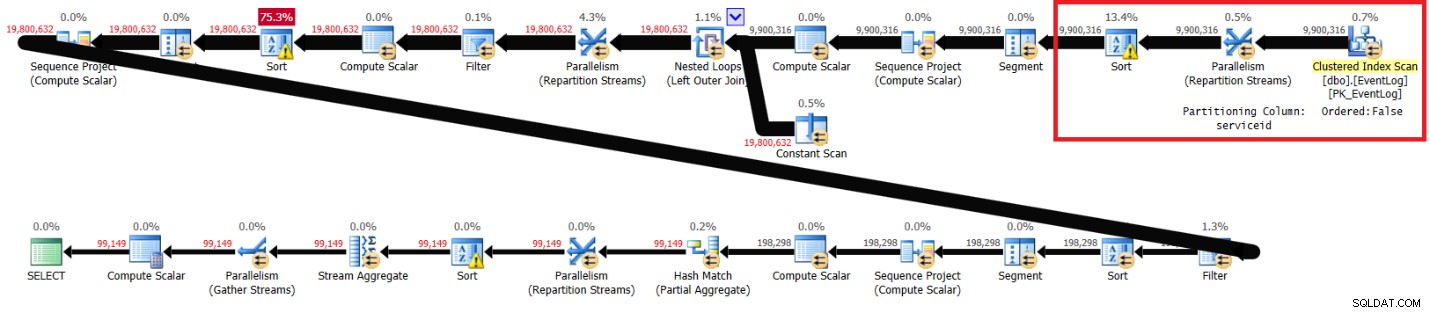 Gambar 2:Rencanakan solusi Itzik tanpa indeks yang direkomendasikan
Gambar 2:Rencanakan solusi Itzik tanpa indeks yang direkomendasikan
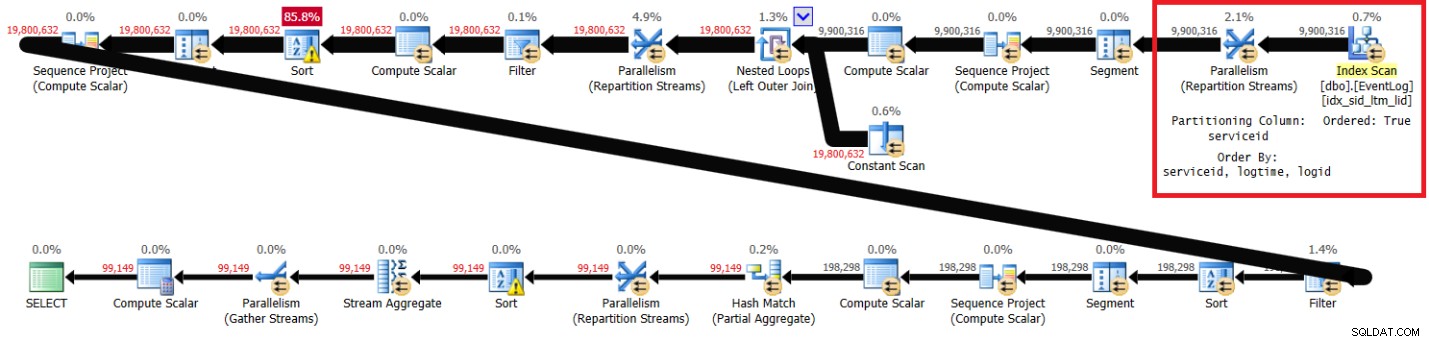
Bagian yang disorot dalam dua rencana menunjukkan perbedaannya. Paket tanpa indeks yang direkomendasikan melakukan pemindaian tidak berurutan dari indeks berkerumun, mempartisi aliran dengan serviceid menggunakan pertukaran nonorder-preserving, dan kemudian mengurutkan baris seperti yang dibutuhkan fungsi jendela (berdasarkan serviceid, logtime, logid). Sisa pekerjaan tampaknya sama di kedua rencana. Anda akan berpikir bahwa paket tanpa indeks yang direkomendasikan harus lebih lambat karena memiliki jenis ekstra yang tidak dimiliki paket lain. Tapi inilah statistik kinerja yang saya dapatkan untuk paket ini di laptop saya:
berlalu:31, CPU:89, pembacaan logis:172.598 , CXPACKET menunggu:84
Ada lebih banyak waktu CPU yang terlibat, yang sebagian disebabkan oleh pengurutan ekstra; ada lebih banyak I/O yang terlibat, mungkin karena tumpahan sortir tambahan; namun, waktu yang berlalu sekitar 30 persen lebih cepat. Apa yang bisa menjelaskan ini? Salah satu cara untuk mencoba dan mengetahuinya adalah dengan menjalankan kueri di SSMS dengan opsi Statistik Kueri Langsung diaktifkan. Ketika saya melakukan ini, operator Paralelisme (Aliran Ulang Partisi) paling kanan selesai dalam 6 detik tanpa indeks yang disarankan dan dalam 35 detik dengan indeks yang disarankan. Perbedaan utama adalah bahwa yang pertama mendapatkan data yang dipesan sebelumnya dari indeks, dan merupakan pertukaran yang mempertahankan pesanan. Yang terakhir mendapatkan data yang tidak diurutkan, dan bukan pertukaran yang mempertahankan pesanan. Pertukaran yang mempertahankan pesanan cenderung lebih mahal daripada yang tidak mempertahankan pesanan. Juga, setidaknya di bagian paling kanan dari rencana hingga pengurutan pertama, yang pertama mengirimkan baris dalam urutan yang sama seperti kolom partisi pertukaran, jadi Anda tidak mendapatkan semua utas untuk benar-benar memproses baris secara paralel. Nanti mengirimkan baris tidak berurutan, sehingga Anda mendapatkan semua utas untuk memproses baris benar-benar secara paralel. Anda dapat melihat bahwa tunggu teratas di kedua paket adalah CXPACKET, tetapi dalam kasus sebelumnya waktu tunggu dua kali lipat dari yang terakhir, memberi tahu Anda bahwa penanganan paralelisme dalam kasus terakhir lebih optimal. Mungkin ada beberapa faktor lain yang berperan yang tidak saya pikirkan. Jika Anda memiliki ide tambahan yang dapat menjelaskan perbedaan performa yang mengejutkan, silakan bagikan.
Di laptop saya ini mengakibatkan eksekusi tanpa indeks yang direkomendasikan menjadi lebih cepat daripada yang dengan indeks yang direkomendasikan. Namun, pada mesin uji lain, itu sebaliknya. Lagi pula, Anda memang memiliki jenis ekstra, dengan potensi tumpah.
Karena penasaran, saya menguji eksekusi serial (dengan opsi MAXDOP 1) dengan indeks yang direkomendasikan, dan mendapatkan statistik kinerja berikut di laptop saya:
berlalu:42, CPU:40, pembacaan logis:143.519
Seperti yang Anda lihat, run time mirip dengan run time dari eksekusi paralel dengan indeks yang direkomendasikan. Saya hanya memiliki 4 CPU logis di laptop saya. Tentu saja, jarak tempuh Anda mungkin berbeda dengan perangkat keras yang berbeda. Intinya adalah, ada baiknya menguji berbagai alternatif, termasuk dengan dan tanpa pengindeksan yang menurut Anda akan membantu. Hasilnya terkadang mengejutkan dan berlawanan dengan intuisi.
Solusi Kamil
Saya sangat tertarik dengan solusi Kamil dan terutama menyukai cara dia meniru LAG dan LEAD dengan teknik yang kompatibel sebelum tahun 2012.
Berikut kode yang mengimplementasikan langkah pertama dalam solusi:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_timeFROM dbo.EventLog;
Kode ini menghasilkan output berikut (hanya menampilkan data untuk serviceid 1):
serviceid logtime end_time start_time---------- -------------------- --------- ---- -------1 2018-09-12 08:00:00 1 01 2018-09-12 08:01:01 2 11 2018-09-12 08:01:59 3 21 2018-09-12 08 :03:00 4 31 2018-09-12 08:05:00 5 41 2018-09-12 08:06:02 6 5...
Langkah ini menghitung dua nomor baris yang terpisah satu untuk setiap baris, dipartisi oleh serviceid, dan diurutkan berdasarkan waktu log. Nomor baris saat ini mewakili waktu akhir (sebut saja end_time), dan nomor baris saat ini dikurangi satu mewakili waktu mulai (sebut saja start_time).
Kode berikut mengimplementasikan langkah kedua dari solusi:
DENGAN RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U;
Langkah ini menghasilkan output berikut:
serviceid logtime rownum time_type---------- -------------------- ------- ------ -----1 09-12-2018 08:00:00 0 start_time1 2018-09-12 08:00:00 1 end_time1 2018-09-12 08:01:01 1 start_time1 2018-09-12 08:01 :01 2 end_time1 2018-09-12 08:01:59 2 start_time1 2018-09-12 08:01:59 3 end_time1 2018-09-12 08:03:00 3 start_time1 2018-09-12 08:03:00 4 end_time1 2018-09-12 08:05:00 4 start_time1 2018-09-12 08:05:00 5 end_time1 2018-09-12 08:06:02 5 start_time1 2018-09-12 08:06:02 6 end_time ...
Langkah ini memisahkan setiap baris menjadi dua baris, menduplikasi setiap entri log—sekali untuk waktu ketik start_time dan satu lagi untuk end_time. Seperti yang Anda lihat, selain nomor baris minimum dan maksimum, setiap nomor baris muncul dua kali—satu kali dengan waktu log peristiwa saat ini (waktu_mulai) dan satu lagi dengan waktu log peristiwa sebelumnya (waktu_akhir).
Kode berikut mengimplementasikan langkah ketiga dalam solusi:
DENGAN RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P;
Kode ini menghasilkan output berikut:
serviceid rownum start_time end_time----------- -------------------- ------------ --------------- ---------------------------1 0 2018-09-12 08 :00:00 NULL1 1 2018-09-12 08:01:01 2018-09-12 08:00:001 2 2018-09-12 08:01:59 2018-09-12 08:01:011 3 2018- 09-12 08:03:00 2018-09-12 08:01:591 4 2018-09-12 08:05:00 2018-09-12 08:03:001 5 2018-09-12 08:06:02 12-09-2018 08:05:001 6 NULL 2018-09-12 08:06:02...
Langkah ini memutar data, mengelompokkan pasangan baris dengan nomor baris yang sama, dan mengembalikan satu kolom untuk waktu log peristiwa saat ini (waktu_mulai) dan satu lagi untuk waktu log peristiwa sebelumnya (waktu_akhir). Bagian ini secara efektif mengemulasi fungsi LAG.
Kode berikut mengimplementasikan langkah keempat dalam solusi:
MENNYATAKAN @allowedgap SEBAGAI INT =66; DENGAN RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grpFROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS PIVOT( MAX(logtime) FOR time_type IN(start_time, end_time)) AS PWHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap;
Kode ini menghasilkan output berikut:
serviceid rownum start_time end_time start_time_grp end_time_grp---------- ------- -------------------- ---- ---------------- --------------- -------------1 0 2018-09- 12 08:00:00 NULL 1 01 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 11 6 NULL 2018-09-12 08:06:02 3 2...Langkah ini memfilter pasangan di mana perbedaan antara waktu berakhir sebelumnya dan waktu mulai saat ini lebih besar dari celah yang diizinkan, dan baris dengan hanya satu peristiwa. Sekarang Anda perlu menghubungkan waktu mulai setiap baris saat ini dengan waktu akhir baris berikutnya. Ini membutuhkan perhitungan seperti LEAD. Untuk mencapai ini, kode tersebut, sekali lagi, membuat nomor baris yang terpisah satu sama lain, hanya saja kali ini nomor baris saat ini mewakili waktu mulai (start_time_grp ) dan nomor baris saat ini dikurangi satu menunjukkan waktu akhir (end_time_grp).
Seperti sebelumnya, langkah selanjutnya (nomor 5) adalah melepas pivot pada baris. Berikut kode yang mengimplementasikan langkah ini:
MENNYATAKAN @allowedgap SEBAGAI INT =66; DENGAN RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Berkisar sebagai ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT *FROM Ranges UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U;Keluaran:
serviceid rownum start_time end_time grp grp_type---------- ------- -------------------- ---- ---------------- ---- ---------------1 0 2018-09-12 08:00:00 NULL 0 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp1 0 2018-09-12 08:00:00 NULL 1 start_time_grp1 6 NULL 2018-09-12 08:06:02 2 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp1 6 NULL 2018-09-12 08:06:02 3 start_time_grp...Seperti yang Anda lihat, kolom grp unik untuk setiap pulau dalam ID layanan.
Langkah 6 adalah langkah terakhir dalam solusi. Berikut kode yang mengimplementasikan langkah ini, yang juga merupakan kode solusi lengkap:
MENNYATAKAN @allowedgap SEBAGAI INT =66; DENGAN RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Berkisar sebagai ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT serviceid, MIN(start_time) AS start_time , MAX(end_time) AS end_timeFROM Rentang UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS UGROUP BY serviceid, grpHAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) NOT NULL);Langkah ini menghasilkan output berikut:
serviceid start_time end_time----------- --------------------------- ------ -------1 2018-09-12 08:00:00 2018-09-12 08:03:001 2018-09-12 08:05 :00 2018-09-12 08:06:02...Langkah ini mengelompokkan baris menurut serviceid dan grp, memfilter hanya grup yang relevan, dan mengembalikan waktu_mulai minimum sebagai awal pulau, dan waktu akhir maksimum sebagai akhir pulau.
Gambar 3 memiliki rencana yang saya dapatkan untuk solusi ini dengan indeks yang direkomendasikan:
BUAT INDEX idx_sid_ltm_lid PADA dbo.EventLog(serviceid, logtime, logid);Rencanakan dengan indeks yang direkomendasikan pada Gambar 3.
Gambar 3:Rencanakan solusi Kamil dengan indeks yang direkomendasikan
Berikut adalah statistik kinerja yang saya dapatkan untuk eksekusi ini di laptop saya:
berlalu:44, CPU:66, pembacaan logis:72979, tunggu atas:CXPACKET:148Saya kemudian menjatuhkan indeks yang direkomendasikan dan menjalankan kembali solusinya:
JADIKAN INDEKS idx_sid_ltm_lid PADA dbo.EventLog;Saya mendapatkan rencana yang ditunjukkan pada Gambar 4 untuk eksekusi tanpa indeks yang direkomendasikan.
Gambar 4:Rencanakan solusi Kamil tanpa indeks yang direkomendasikan
Berikut adalah statistik kinerja yang saya dapatkan untuk eksekusi ini:
berlalu:30, CPU:85, pembacaan logis:94813, tunggu atas:CXPACKET:70Waktu berjalan, waktu CPU, dan waktu tunggu CXPACKET sangat mirip dengan solusi saya, meskipun pembacaan logisnya lebih rendah. Solusi Kamil juga berjalan lebih cepat di laptop saya tanpa indeks yang disarankan, dan sepertinya itu karena alasan yang sama.
Kesimpulan
Anomali adalah hal yang baik. Mereka membuat Anda penasaran dan menyebabkan Anda pergi dan meneliti akar penyebab masalah, dan sebagai hasilnya, mempelajari hal-hal baru. Sangat menarik untuk melihat bahwa beberapa kueri, pada mesin tertentu, berjalan lebih cepat tanpa pengindeksan yang disarankan.
Sekali lagi terima kasih kepada Toby, Peter dan Kamil atas solusi Anda. Dalam artikel ini saya membahas solusi Kamil, dengan teknik kreatifnya untuk meniru LAG dan LEAD dengan nomor baris, unpivoting dan pivoting. Anda akan menemukan teknik ini berguna saat membutuhkan perhitungan seperti LAG dan LEAD yang harus didukung pada lingkungan pra-2012.