Salah satu istilah paling umum yang muncul dalam diskusi tentang penyetelan kinerja SQL Server adalah statistik tunggu . Ini kembali jauh, bahkan sebelum dokumen Microsoft 2006 ini, "SQL Server 2005 Waits and Queues."
Menunggu sama sekali bukan segalanya, dan metodologi ini bukan satu-satunya cara untuk menyetel sebuah instance, apalagi kueri individu. Faktanya, menunggu seringkali tidak berguna ketika yang Anda miliki hanyalah kueri yang membuatnya menderita, dan tidak ada konteks di sekitarnya, terutama lama setelah fakta. Ini karena, cukup sering, hal yang menunggu kueri bukan kesalahan kueri itu . Seperti apa pun, ada pengecualian, tetapi jika Anda memilih alat atau skrip hanya karena ia menawarkan fungsi yang sangat spesifik ini, saya pikir Anda merugikan diri sendiri. Saya cenderung mengikuti nasihat yang diberikan Paul Randal kepada saya beberapa waktu lalu:
…umumnya saya sarankan memulai dengan seluruh instance menunggu. Saya tidak akan pernah memulai pemecahan masalah dengan melihat setiap permintaan menunggu.
Terkadang, ya, Anda mungkin ingin menggali lebih dalam kueri individual dan melihat apa yang menunggunya; sebenarnya Microsoft baru-baru ini menambahkan statistik tunggu tingkat kueri ke showplan untuk membantu analisis ini. Tetapi angka-angka ini biasanya tidak akan membantu Anda menyesuaikan kinerja instans Anda secara keseluruhan, kecuali jika angka-angka tersebut membantu menunjukkan sesuatu yang kebetulan juga memengaruhi seluruh beban kerja Anda. Jika Anda melihat satu kueri dari kemarin yang berjalan selama 5 menit, dan perhatikan bahwa jenis tunggunya adalah LCK_M_S , apa yang akan Anda lakukan sekarang? Bagaimana Anda akan melacak apa yang sebenarnya memblokir kueri dan menyebabkan jenis menunggu itu? Ini mungkin disebabkan oleh transaksi yang tidak dilakukan karena alasan lain, tetapi Anda tidak dapat melihatnya jika Anda tidak dapat melihat status keseluruhan sistem dan hanya berfokus pada kueri individual dan penantian yang mereka alami.
Jason Hall (@SQLSaurus) menyebutkan sesuatu yang menarik bagi saya juga. Dia mengatakan bahwa jika statistik tunggu tingkat kueri adalah bagian penting dari upaya penyetelan, metodologi ini akan dimasukkan ke dalam Query Store sejak awal. Itu telah ditambahkan baru-baru ini (dalam SQL Server 2017). Tetapi Anda masih belum mendapatkan statistik tunggu per eksekusi; Anda mendapatkan rata-rata dari waktu ke waktu, seperti statistik kueri dan statistik prosedur yang Anda lihat di DMV. Jadi anomali mendadak mungkin terlihat berdasarkan metrik lain yang ditangkap per eksekusi kueri, tetapi tidak berdasarkan rata-rata waktu tunggu yang diambil dari semua eksekusi. Anda dapat menyesuaikan rentang waktu tunggu yang dikumpulkan, tetapi pada sistem yang sibuk, ini mungkin masih belum cukup terperinci untuk melakukan apa yang menurut Anda akan dilakukan untuk Anda.
Inti dari posting ini adalah untuk membahas beberapa jenis menunggu yang lebih umum yang kami lihat di basis pelanggan kami, dan tindakan seperti apa yang dapat Anda (dan tidak boleh) lakukan ketika itu terjadi. Kami memiliki database statistik menunggu anonim yang telah kami kumpulkan dari pelanggan Cloud Sync kami selama beberapa waktu, dan sejak Mei 2017 kami telah menunjukkan kepada semua orang bagaimana tampilannya di Perpustakaan SQLskills Waits.
Paul berbicara tentang alasan di balik perpustakaan dan juga tentang integrasi kami dengan layanan gratis ini. Pada dasarnya, Anda mencari tipe menunggu yang Anda alami atau ingin tahu, dan dia menjelaskan apa artinya dan apa yang dapat Anda lakukan. Kami melengkapi info kualitatif ini dengan bagan yang menunjukkan seberapa lazim menunggu saat ini di antara basis pengguna kami, membandingkannya dengan semua jenis menunggu lain yang kami lihat, sehingga Anda dapat dengan cepat mengetahui apakah Anda berurusan dengan jenis menunggu umum atau sesuatu yang lebih sedikit eksotik. (Perlu diingat SQL Sentry tidak menyertakan antrian yang tidak berbahaya, latar belakang, dan antrian yang menimbulkan kebisingan dan bahwa sebagian besar skrip di luar sana menyaring, seperti WAITFOR atau LAZYWRITER_SLEEP – ini bukan sumber masalah kinerja.)
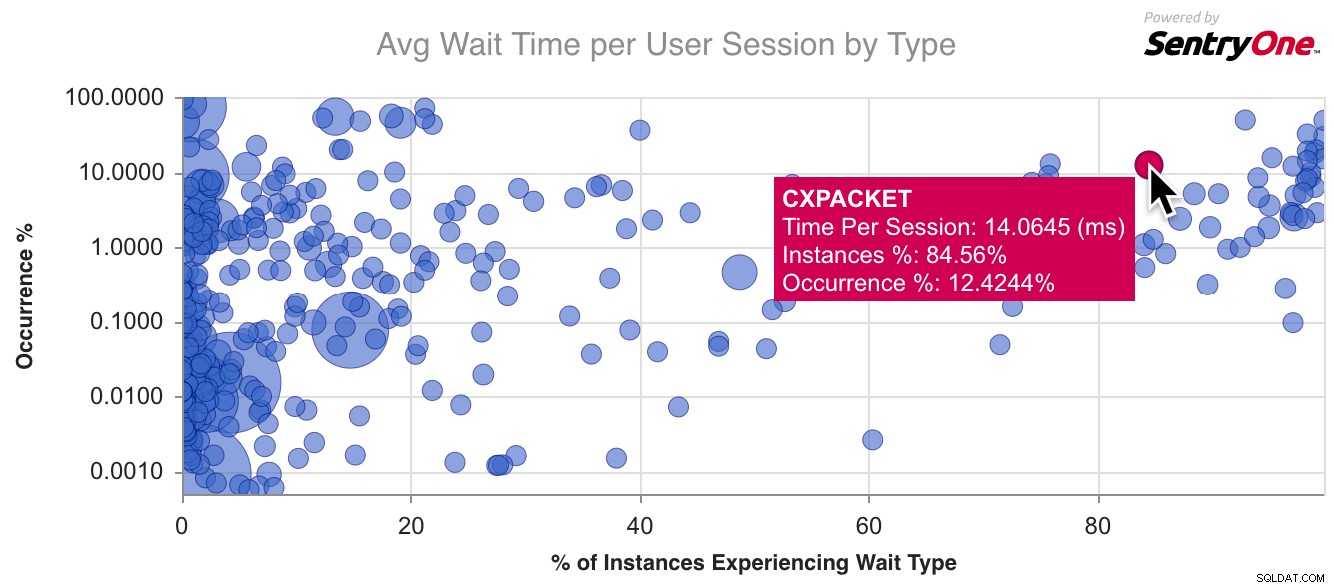
Berikut adalah contoh bagan untuk CXPACKET , jenis menunggu yang paling umum di luar sana:
Saya mulai melangkah lebih jauh dari ini, memetakan beberapa jenis tunggu yang lebih umum, dan mencatat beberapa properti yang mereka bagikan. Diterjemahkan ke dalam pertanyaan yang mungkin dimiliki tuner tentang jenis menunggu yang mereka alami:
- Dapatkah tipe menunggu diselesaikan di tingkat kueri?
- Apakah gejala inti dari menunggu kemungkinan akan memengaruhi kueri lain?
- Apakah Anda mungkin memerlukan lebih banyak informasi di luar konteks satu kueri dan jenis tunggu yang dialaminya untuk "menyelesaikan" masalah?
Ketika saya mulai menulis posting ini, tujuan saya hanya untuk mengelompokkan jenis menunggu yang paling umum bersama-sama, dan kemudian mulai membuat catatan tentang mereka yang berkaitan dengan pertanyaan di atas. Jason menarik yang paling umum dari perpustakaan, dan kemudian saya menggambar beberapa goresan ayam di papan tulis, yang kemudian saya rapikan sedikit. Penelitian awal ini mengarah pada pembicaraan yang diberikan Jason di TechOutbound SQL Cruise terbaru di Alaska. Saya agak malu bahwa dia mengadakan pembicaraan berbulan-bulan sebelum saya bisa menyelesaikan posting ini, jadi mari kita lanjutkan. Berikut adalah penantian teratas yang kami lihat (yang sebagian besar cocok dengan survei Paul dari tahun 2014), jawaban saya atas pertanyaan di atas, dan beberapa komentar untuk masing-masing:
Untuk berinteraksi dengan tautan dalam tabel di bawah, kunjungi halaman ini di layar yang lebih lebar.
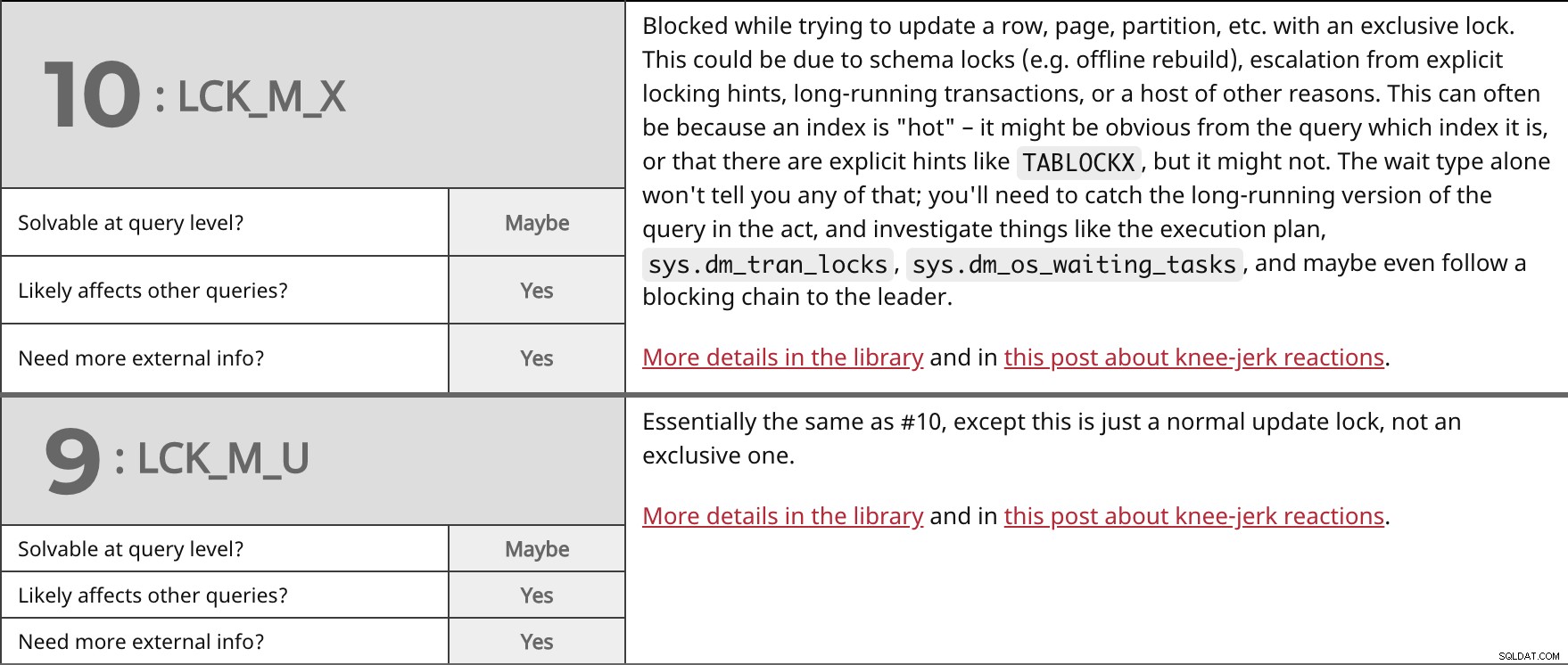
Diblokir saat mencoba memperbarui baris, halaman, partisi, dll. dengan kunci eksklusif. Ini mungkin karena penguncian skema (mis. pembuatan ulang offline), eskalasi dari petunjuk penguncian eksplisit, transaksi yang berjalan lama, atau sejumlah alasan lainnya. Ini sering kali karena indeks "panas" – mungkin terlihat jelas dari kueri yang mengindeksnya, atau ada petunjuk eksplisit seperti TABLOCKX , tapi mungkin tidak. Jenis menunggu saja tidak akan memberi tahu Anda semua itu; Anda harus menangkap versi lama kueri saat beraksi, dan menyelidiki hal-hal seperti rencana eksekusi, sys.dm_tran_locks , sys.dm_os_waiting_tasks , dan bahkan mungkin mengikuti rantai pemblokiran ke pemimpinnya. Lebih detail di perpustakaan dan di postingan ini tentang reaksi spontan. | ||
| Dapat dipecahkan pada tingkat kueri? | Mungkin | |
| Ya | ||
| Perlu info eksternal lainnya? | Ya | |
|
Pada dasarnya sama dengan #10, kecuali ini hanya kunci pembaruan normal, bukan kunci eksklusif. Lebih detail di perpustakaan dan di postingan ini tentang reaksi spontan. | ||
| Dapat dipecahkan pada tingkat kueri? | Mungkin | |
| Ya | ||
| Perlu info eksternal lainnya? | Ya | |
|
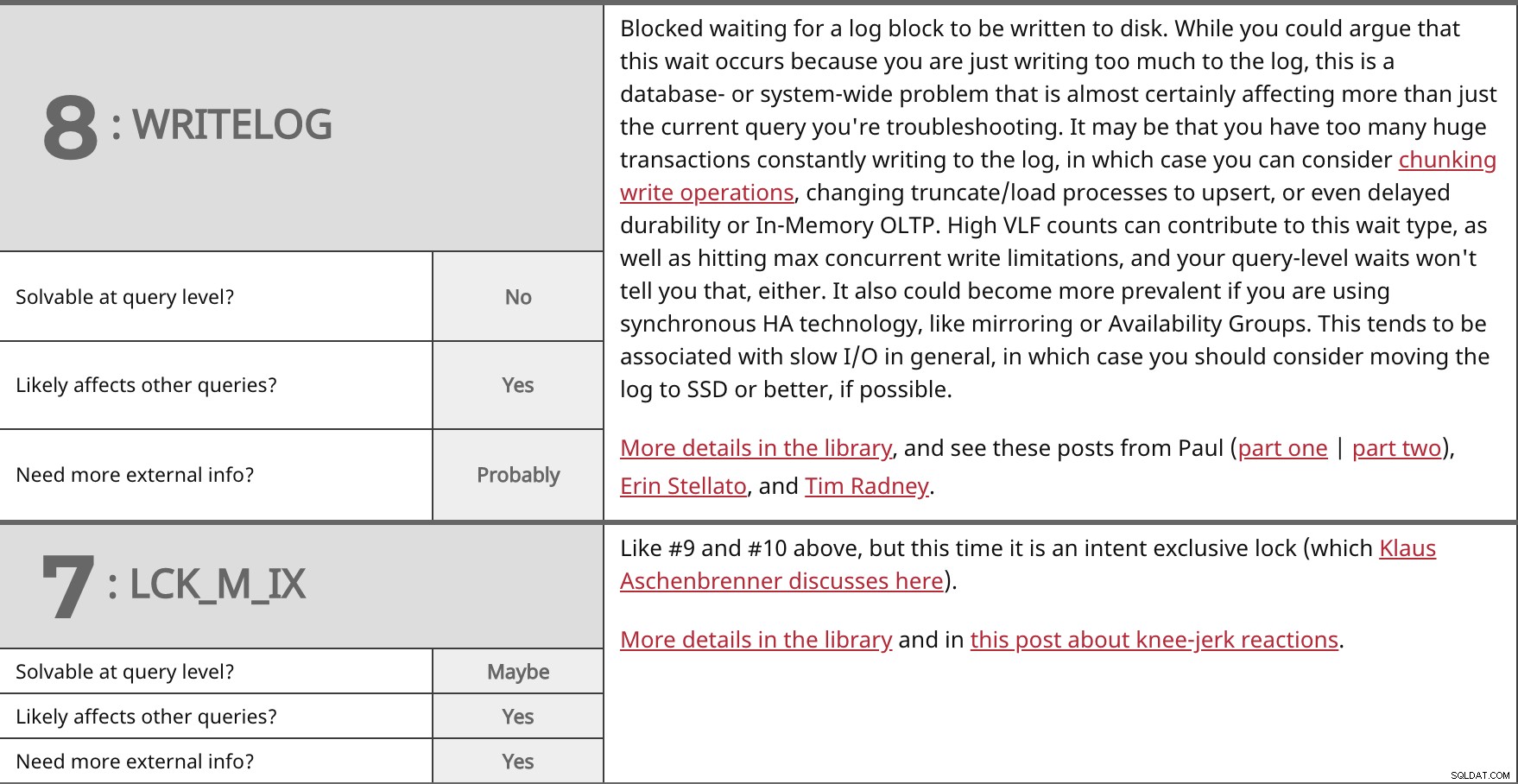
Diblokir menunggu blok log ditulis ke disk. Meskipun Anda dapat berargumen bahwa penantian ini terjadi karena Anda hanya menulis terlalu banyak ke log, ini adalah masalah basis data atau sistem yang hampir pasti memengaruhi lebih dari sekadar kueri saat ini yang sedang Anda pecahkan. Mungkin Anda memiliki terlalu banyak transaksi besar yang terus-menerus menulis ke log, dalam hal ini Anda dapat mempertimbangkan operasi penulisan chunking, mengubah proses truncate/load menjadi upsert, atau bahkan durabilitas yang tertunda atau OLTP Dalam Memori. Jumlah VLF yang tinggi dapat berkontribusi pada jenis menunggu ini, serta mencapai batasan maksimum penulisan bersamaan, dan menunggu tingkat kueri Anda juga tidak akan memberi tahu Anda. Ini juga bisa menjadi lebih umum jika Anda menggunakan teknologi HA sinkron, seperti mirroring atau Grup Ketersediaan. Ini cenderung dikaitkan dengan I/O lambat secara umum, dalam hal ini Anda harus mempertimbangkan untuk memindahkan log ke SSD atau yang lebih baik, jika memungkinkan. Lebih detail di perpustakaan, dan lihat posting ini dari Paul (bagian satu | bagian dua), Erin Stellato, dan Tim Radney. | ||
| Dapat dipecahkan pada tingkat kueri? | Tidak | |
| Ya | ||
| Perlu info eksternal lainnya? | Mungkin | |
|
Seperti #9 dan #10 di atas, tetapi kali ini adalah kunci eksklusif maksud (yang dibahas Klaus Aschenbrenner di sini). Lebih detail di perpustakaan dan di postingan ini tentang reaksi spontan. | ||
| Dapat dipecahkan pada tingkat kueri? | Mungkin | |
| Ya | ||
| Perlu info eksternal lainnya? | Ya | |
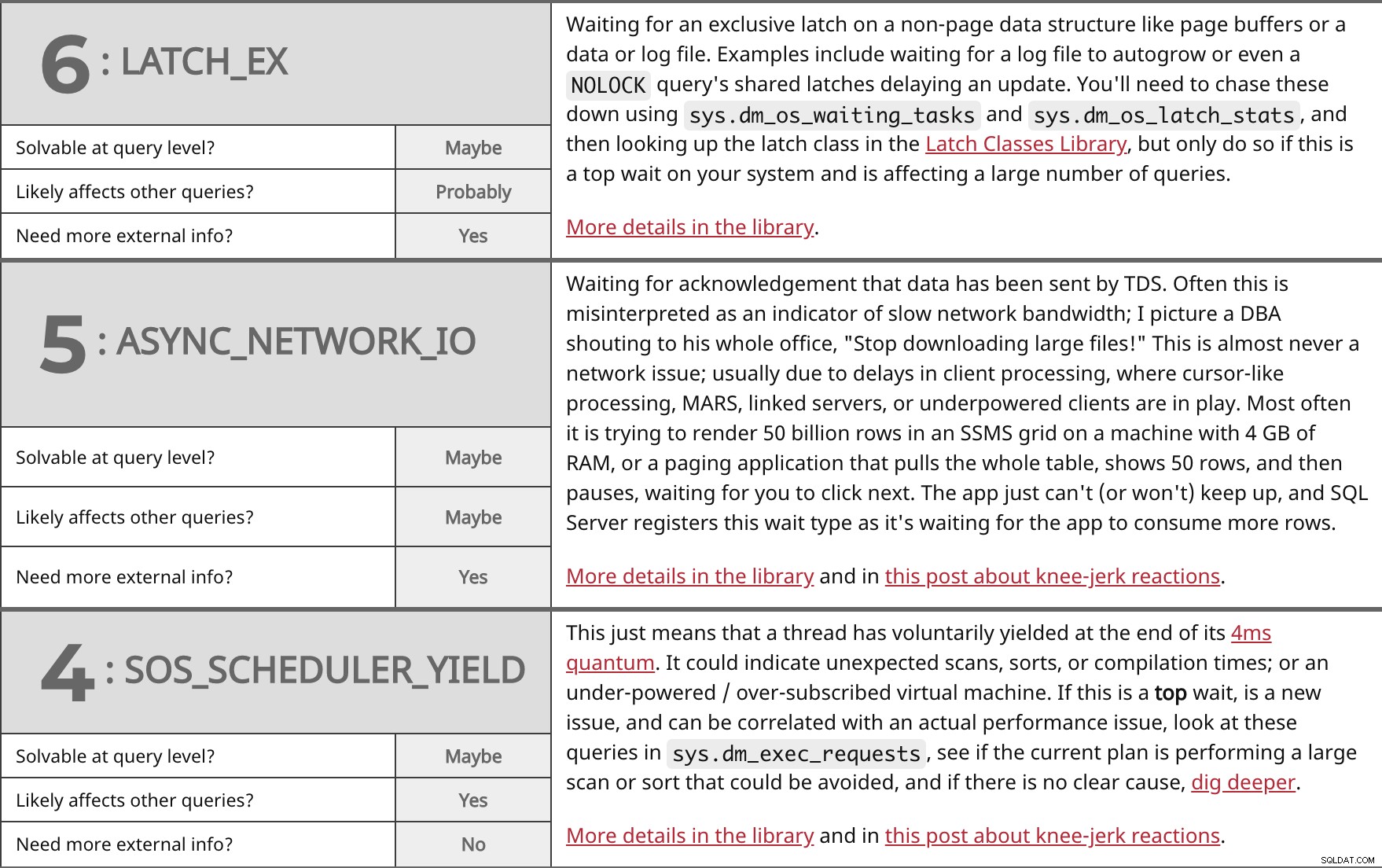
Menunggu kait eksklusif pada struktur data non-halaman seperti buffer halaman atau file data atau log. Contohnya termasuk menunggu file log tumbuh otomatis atau bahkan NOLOCK kait bersama kueri menunda pembaruan. Anda harus mengejar ini menggunakan sys.dm_os_waiting_tasks dan sys.dm_os_latch_stats , lalu mencari kelas latch di Pustaka Kelas Latch, tetapi hanya melakukannya jika ini adalah penantian teratas di sistem Anda dan memengaruhi sejumlah besar kueri. Lebih detail di perpustakaan. | ||
| Dapat dipecahkan pada tingkat kueri? | Mungkin | |
| Mungkin | ||
| Perlu info eksternal lainnya? | Ya | |
|
Menunggu konfirmasi bahwa data telah dikirim oleh TDS. Seringkali ini disalahartikan sebagai indikator bandwidth jaringan yang lambat; Saya membayangkan seorang DBA berteriak ke seluruh kantornya, "Berhenti mengunduh file besar!" Ini hampir tidak pernah menjadi masalah jaringan; biasanya karena penundaan dalam pemrosesan klien, di mana pemrosesan seperti kursor, MARS, server tertaut, atau klien yang kurang bertenaga sedang bermain. Paling sering itu mencoba untuk membuat 50 miliar baris dalam kotak SSMS pada mesin dengan 4 GB RAM, atau aplikasi paging yang menarik seluruh tabel, menunjukkan 50 baris, dan kemudian berhenti, menunggu Anda untuk mengklik berikutnya. Aplikasi tidak dapat (atau tidak mau) mengikuti, dan SQL Server mendaftarkan jenis tunggu ini saat menunggu aplikasi menggunakan lebih banyak baris. Lebih detail di perpustakaan dan di postingan ini tentang reaksi spontan. | ||
| Dapat dipecahkan pada tingkat kueri? | Mungkin | |
| Mungkin | ||
| Perlu info eksternal lainnya? | Ya | |
Ini hanya berarti bahwa sebuah utas telah secara sukarela menghasilkan di akhir kuantum 4 md. Ini dapat menunjukkan pemindaian, pengurutan, atau waktu kompilasi yang tidak terduga; atau mesin virtual yang kurang bertenaga/berlangganan berlebihan. Jika ini adalah atas tunggu, adalah masalah baru, dan dapat dikorelasikan dengan masalah kinerja aktual, lihat kueri ini di sys.dm_exec_requests , lihat apakah rencana saat ini melakukan pemindaian besar atau pengurutan yang dapat dihindari, dan jika tidak ada penyebab yang jelas, gali lebih dalam. Lebih detail di perpustakaan dan di postingan ini tentang reaksi spontan. | ||
| Dapat dipecahkan pada tingkat kueri? | Mungkin | |
| Ya | ||
| Perlu info eksternal lainnya? | Tidak | |
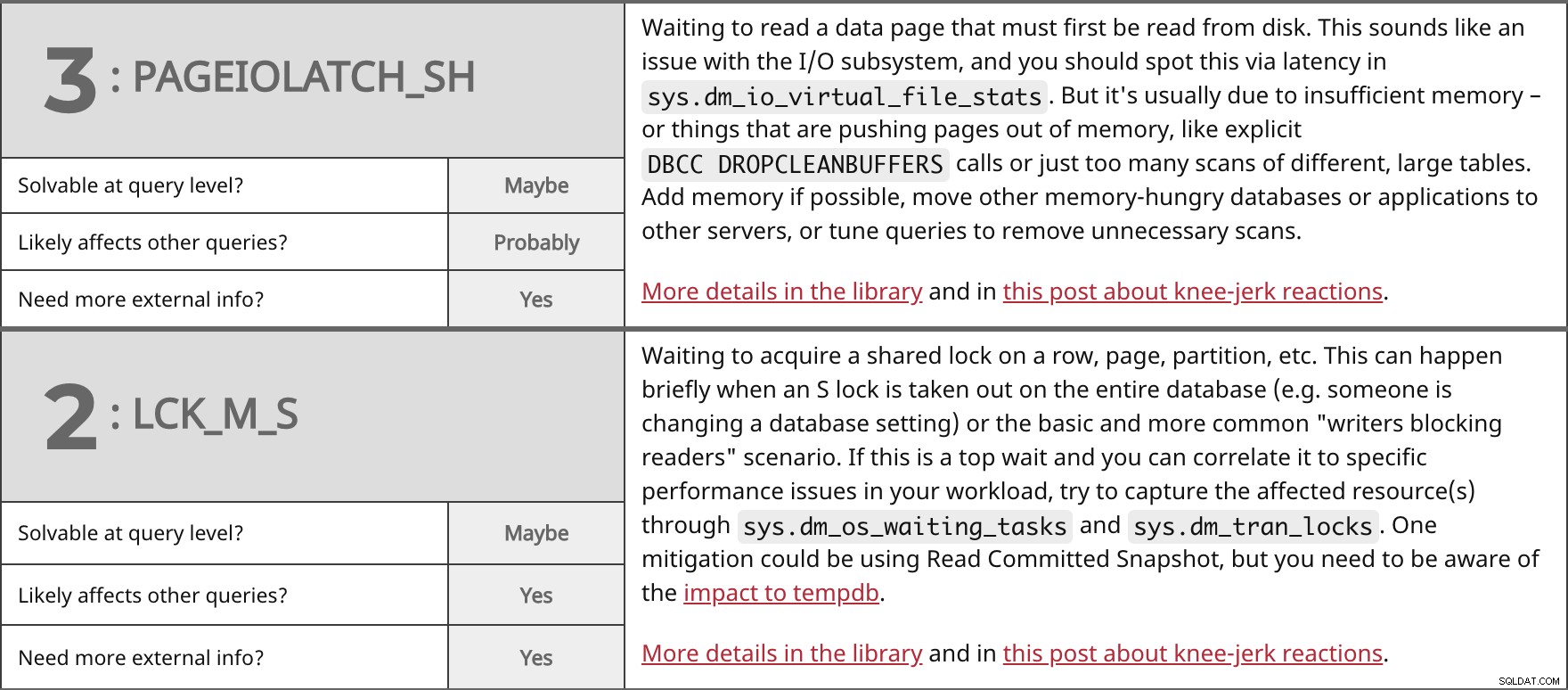
Menunggu untuk membaca halaman data yang harus dibaca terlebih dahulu dari disk. Ini terdengar seperti masalah dengan subsistem I/O, dan Anda harus melihat ini melalui latensi di sys.dm_io_virtual_file_stats . Tetapi biasanya karena memori yang tidak mencukupi – atau hal-hal yang mendorong halaman keluar dari memori, seperti DBCC DROPCLEANBUFFERS eksplisit panggilan atau terlalu banyak pemindaian tabel besar yang berbeda. Tambahkan memori jika memungkinkan, pindahkan database atau aplikasi lain yang membutuhkan memori ke server lain, atau sesuaikan kueri untuk menghapus pemindaian yang tidak perlu. Lebih detail di perpustakaan dan di postingan ini tentang reaksi spontan. | ||
| Dapat dipecahkan pada tingkat kueri? | Mungkin | |
| Mungkin | ||
| Perlu info eksternal lainnya? | Ya | |
Menunggu untuk mendapatkan kunci bersama pada baris, halaman, partisi, dll. Ini dapat terjadi sebentar ketika kunci S diambil di seluruh database (mis. pengaturan basis data) atau skenario "penulis memblokir pembaca" dasar dan lebih umum. Jika ini adalah penantian teratas dan Anda dapat menghubungkannya dengan masalah kinerja tertentu dalam beban kerja Anda, coba ambil sumber daya yang terpengaruh melalui sys.dm_os_waiting_tasks dan sys.dm_tran_locks . Salah satu mitigasinya bisa menggunakan Read Committed Snapshot, tetapi Anda harus menyadari dampaknya terhadap tempdb. Lebih detail di perpustakaan dan di postingan ini tentang reaksi spontan. | ||
| Dapat dipecahkan pada tingkat kueri? | Mungkin | |
| Ya | ||
| Perlu info eksternal lainnya? | Ya | |
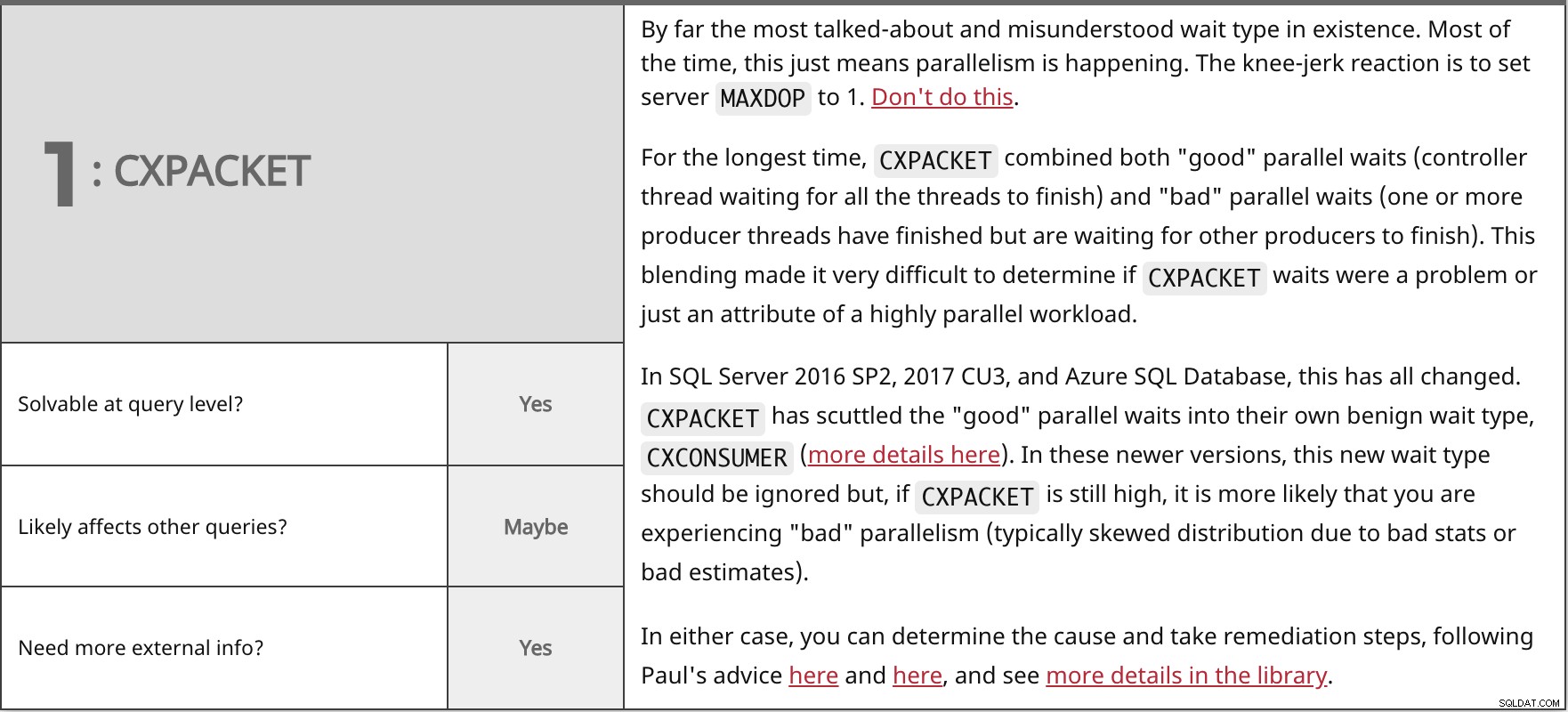
Sejauh ini tipe tunggu yang paling banyak dibicarakan dan disalahpahami yang ada. Sebagian besar waktu, ini hanya berarti paralelisme sedang terjadi. Reaksi spontan adalah untuk mengatur server MAXDOP ke 1. Jangan lakukan ini.
Untuk waktu yang lama,
Di SQL Server 2016 SP2, 2017 CU3, dan Azure SQL Database, semua ini telah berubah. Dalam kedua kasus tersebut, Anda dapat menentukan penyebabnya dan mengambil langkah-langkah perbaikan, mengikuti saran Paul di sini dan di sini, dan melihat detail lebih lanjut di perpustakaan. | ||
| Dapat dipecahkan pada tingkat kueri? | Ya | |
| Mungkin | ||
| Perlu info eksternal lainnya? | Ya | |
Ringkasan
Dalam sebagian besar kasus ini, lebih baik untuk melihat menunggu di tingkat instans, dan hanya fokus pada menunggu di tingkat kueri saat Anda memecahkan masalah kueri tertentu yang menunjukkan masalah kinerja terlepas dari jenis menunggu. Ini adalah hal-hal yang muncul karena alasan lain, seperti durasi lama, CPU tinggi, atau I/O tinggi, dan tidak dapat dijelaskan dengan hal-hal sederhana (seperti pemindaian indeks berkerumun saat Anda mengharapkan pencarian).
Bahkan pada tingkat instans, jangan mengejar setiap penantian yang menjadi penantian teratas di sistem Anda – Anda akan SELALU memiliki menunggu atas, dan Anda tidak akan pernah bisa berhenti mengejarnya. Pastikan Anda mengabaikan menunggu yang tidak berbahaya (Paul menyimpan daftar) dan hanya khawatir tentang menunggu yang dapat Anda kaitkan dengan masalah kinerja aktual yang Anda alami. Jika CXPACKET menunggu tinggi, jadi apa? Apakah ada gejala lain selain angka "tinggi" atau kebetulan berada di urutan teratas?
Semuanya bermuara pada mengapa Anda memecahkan masalah di tempat pertama. Apakah satu pengguna mengeluh tentang satu contoh kueri jahat? Apakah server Anda berlutut? Sesuatu di antara? Dalam kasus pertama, tentu saja, mengetahui mengapa kueri lambat dapat berguna, tetapi cukup mahal untuk melacak (apalagi tetap tanpa batas) semua menunggu yang terkait dengan setiap kueri, sepanjang hari, setiap hari, pada kesempatan aneh Anda ingin kembali dan meninjaunya nanti. Jika itu adalah masalah pervasif yang diisolasi dari kueri tersebut, Anda harus dapat menentukan apa yang membuat kueri tersebut lambat dengan menjalankannya lagi dan mengumpulkan rencana eksekusi, waktu kompilasi, dan metrik waktu proses lainnya. Jika itu adalah hal satu kali yang terjadi Selasa lalu, apakah Anda harus menunggu untuk satu contoh kueri itu atau tidak, Anda mungkin tidak dapat menyelesaikan masalah tanpa lebih banyak konteks. Mungkin ada pemblokiran, tetapi Anda tidak akan tahu apa, atau mungkin ada lonjakan I/O, tetapi Anda harus melacak masalah itu secara terpisah. Jenis wait itu sendiri biasanya tidak memberikan informasi yang cukup kecuali, paling banter, penunjuk ke sesuatu yang lain.
Tentu saja, saya juga harus mendapatkan penghasilan saya di sini. Produk unggulan kami, SQL Sentry, mengambil pendekatan holistik untuk pemantauan. Kami mengumpulkan statistik tunggu di seluruh instance, mengkategorikannya untuk Anda, dan membuat grafiknya di dasbor kami:
Anda dapat menyesuaikan bagaimana setiap tunggu dikategorikan dan apakah kategori itu muncul di dasbor atau tidak. Anda dapat membandingkan statistik tunggu saat ini dengan baseline bawaan atau kustom, dan bahkan mengatur peringatan atau tindakan saat melebihi beberapa penyimpangan yang ditentukan dari baseline. Dan, mungkin yang paling penting, Anda dapat melihat titik data dari masa lalu, dan menyinkronkan seluruh dasbor ke titik waktu tersebut, sehingga Anda dapat menangkap semua konteks di sekitarnya dan situasi lain apa pun yang mungkin memengaruhi masalah tersebut. Saat Anda menemukan hal-hal yang lebih terperinci untuk difokuskan, seperti pemblokiran, latensi disk tinggi, atau kueri dengan I/O tinggi atau durasi panjang, Anda dapat menelusuri metrik tersebut dan menyelesaikan akar masalahnya dengan lebih cepat.
Untuk info lebih lanjut tentang pendekatan statistik tunggu umum dan solusi kami secara khusus, Anda dapat melihat kertas putih Kevin Kline, Pemecahan Masalah Statistik Tunggu SQL Server, dan Anda dapat mengunduh webinar dua bagian yang disajikan oleh Paul Randal, Andy Yun (@SQLBek), dan Andy Mallon (@AMtwo):
- Bagian 1 :Pemecahan Masalah Performa Menggunakan Statistik Tunggu
- Bagian 2 :Analisis Cepat Statistik Tunggu dengan SentryOne
Dan jika Anda ingin mencoba Platform SentryOne, Anda dapat memulai di sini dengan penawaran waktu terbatas:
Unduh Uji Coba Gratis 15 Hari