Artikel ini adalah yang kedua dari seri tentang ambang pengoptimalan yang terkait dengan pengelompokan dan penggabungan data. Di Bagian 1, saya memberikan formula rekayasa terbalik untuk biaya operator Agregat Aliran. Saya menjelaskan bahwa operator ini perlu menggunakan baris yang diurutkan oleh kumpulan pengelompokan (urutan apa pun dari anggotanya), dan bahwa ketika data diperoleh diurutkan sebelumnya dari indeks, Anda mendapatkan penskalaan linier sehubungan dengan jumlah baris dan jumlah kelompok. Juga, tidak diperlukan pemberian memori dalam kasus seperti itu.
Dalam artikel ini, saya fokus pada penetapan biaya dan penskalaan operasi berbasis agregat aliran ketika data tidak diperoleh dari indeks, melainkan harus diurutkan terlebih dahulu.
Dalam contoh saya, saya akan menggunakan database sampel PerformanceV3, seperti di Bagian 1. Anda dapat mengunduh skrip yang membuat dan mengisi database ini dari sini. Sebelum Anda menjalankan contoh dari artikel ini, pastikan Anda menjalankan kode berikut terlebih dahulu untuk menghapus beberapa indeks yang tidak diperlukan:
JAUHKAN INDEKS idx_nc_sid_od_cid PADA dbo.Orders;TURUN INDEKS idx_unc_od_oid_i_cid_eid PADA dbo.Orders;
Hanya dua indeks yang harus ditinggalkan pada tabel ini adalah idx_cl_od (dikelompokkan dengan orderdate sebagai kunci) dan PK_Orders (tidak dikelompokkan dengan orderid sebagai kuncinya).
Urutkan + Agregat Aliran
Fokus artikel ini adalah untuk mencoba dan mencari tahu bagaimana skala operasi agregat aliran ketika data tidak diurutkan sebelumnya oleh kumpulan pengelompokan. Karena operator Stream Aggregate harus memproses baris yang diurutkan, jika tidak diurutkan sebelumnya dalam indeks, paket harus menyertakan operator Sortir eksplisit. Jadi, biaya operasi agregat yang harus Anda perhitungkan adalah jumlah biaya operator Sort + Stream Aggregate.
Saya akan menggunakan kueri berikut (kami akan menyebutnya Kueri 1) untuk mendemonstrasikan rencana yang melibatkan pengoptimalan seperti itu:
SELECT shipperid, MAX(orderdate) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
Rencana untuk kueri ini ditunjukkan pada Gambar 1.

Gambar 1:Rencana untuk Kueri 1
Alasan saya menggunakan ekspresi tabel dengan filter TOP adalah untuk mengontrol jumlah persis (perkiraan) baris yang terlibat dalam pengelompokan dan agregasi. Menerapkan perubahan terkontrol akan mempermudah untuk mencoba dan merekayasa balik rumus penetapan biaya.
Jika Anda bertanya-tanya mengapa memfilter sejumlah kecil baris dalam contoh ini, ini ada hubungannya dengan ambang pengoptimalan yang membuat strategi ini lebih disukai daripada algoritme Hash Aggregate. Di Bagian 3 saya akan menjelaskan penetapan biaya dan penskalaan alternatif hash. Dalam kasus di mana pengoptimal tidak memilih operasi agregat aliran dengan sendirinya, misalnya, ketika sejumlah besar baris terlibat, Anda selalu dapat memaksanya dengan petunjuk OPTION(ORDER GROUP) selama proses penelitian. Saat berfokus pada penetapan biaya paket serial, Anda jelas dapat menambahkan petunjuk MAXDOP 1 untuk menghilangkan paralelisme.
Seperti disebutkan, untuk mengevaluasi biaya dan penskalaan algoritme agregat aliran yang tidak dipesan sebelumnya, Anda perlu memperhitungkan jumlah operator Sort + Stream Aggregate. Anda sudah mengetahui rumus biaya untuk operator Stream Agregat dari Bagian 1:
@numrows * 0,0000006 + @numgroups * 0,0000005Dalam kueri kami, kami memiliki 100 perkiraan baris masukan dan 5 perkiraan grup keluaran (5 ID pengirim berbeda yang diperkirakan berdasarkan informasi kepadatan). Jadi biaya operator Stream Aggregate dalam paket kami adalah:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Mari kita coba mencari tahu rumus biaya untuk operator Sortir. Ingat, fokus kami adalah perkiraan biaya dan penskalaan karena tujuan akhir kami adalah mengetahui ambang pengoptimalan tempat pengoptimal mengubah pilihannya dari satu strategi ke strategi lainnya.
Perkiraan biaya I/O tampaknya tetap:0,0112613. Saya mendapatkan biaya I/O yang sama terlepas dari faktor-faktor seperti jumlah baris, jumlah kolom pengurutan, tipe data, dan sebagainya. Ini mungkin untuk menjelaskan beberapa pekerjaan I/O yang diantisipasi.
Adapun biaya CPU, sayangnya, Microsoft tidak secara terbuka mengekspos algoritma yang tepat yang mereka gunakan untuk menyortir. Namun, di antara algoritma umum yang digunakan untuk pengurutan oleh mesin basis data pada umumnya adalah implementasi yang berbeda dari merge sort dan quicksort. Berkat upaya yang dilakukan oleh Paul White, yang suka melihat jejak tumpukan debugger Windows (tidak semua dari kita memiliki keinginan untuk ini), kami memiliki sedikit lebih banyak wawasan tentang topik tersebut, yang diterbitkan dalam serinya “Internals of the Seven SQL Server Urutkan.” Menurut temuan Paul, kelas pengurutan umum (digunakan dalam rencana di atas) menggunakan pengurutan gabungan (pertama internal, lalu transisi ke eksternal). Rata-rata, algoritma ini membutuhkan n log n perbandingan untuk mengurutkan n item. Dengan mengingat hal ini, mungkin merupakan taruhan yang aman sebagai titik awal untuk mengasumsikan bahwa bagian CPU dari biaya operator didasarkan pada rumus seperti:
Biaya CPU operator =Tentu saja, ini bisa menjadi penyederhanaan yang berlebihan dari rumus penetapan biaya sebenarnya yang digunakan Microsoft, tetapi tanpa dokumentasi apa pun tentang masalah ini, ini adalah perkiraan awal yang terbaik.
Selanjutnya, Anda dapat memperoleh pengurutan biaya CPU dari dua rencana kueri yang dihasilkan untuk menyortir jumlah baris yang berbeda, katakanlah 1000 dan 2000, dan berdasarkan rumus tersebut dan di atas, rekayasa balik biaya perbandingan dan biaya awal. Untuk tujuan ini, Anda tidak perlu menggunakan kueri yang dikelompokkan; cukup dengan melakukan basic ORDER BY. Saya akan menggunakan dua kueri berikut (kami akan menyebutnya Kueri 2 dan Kueri 3):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; PILIH orderid % 1000000000 sebagai myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Inti dari pengurutan hasil komputasi adalah memaksa operator Sortir untuk digunakan dalam rencana.
Gambar 2 menunjukkan bagian yang relevan dari dua rencana:
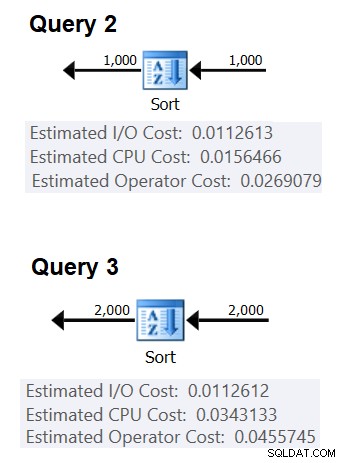
Gambar 2:Rencana untuk Kueri 2 dan Kueri 3
Untuk mencoba dan menyimpulkan biaya dari satu perbandingan, Anda akan menggunakan rumus berikut:
perbandingan biaya =
((
/ (
(0.0343133 – 0.0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2.25061348918698E-06
Untuk biaya awal, Anda dapat menyimpulkannya berdasarkan salah satu paket, misalnya, berdasarkan paket yang mengurutkan 2000 baris:
biaya awal =0,0343133 – 2000*LOG(2000) * 2.25061348918698E-06 =9.99127891201865E-05
Dan dengan demikian rumus biaya Sortir CPU kami menjadi:
Urutkan biaya CPU operator =9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06Dengan menggunakan teknik serupa, Anda akan menemukan bahwa faktor-faktor seperti ukuran baris rata-rata, jumlah kolom pemesanan, dan tipe datanya tidak memengaruhi perkiraan biaya CPU pengurutan. Satu-satunya faktor yang tampaknya relevan adalah perkiraan jumlah baris. Perhatikan bahwa pengurutan akan membutuhkan hibah memori, dan hibah sebanding dengan jumlah baris (bukan grup) dan ukuran baris rata-rata. Namun fokus kami saat ini adalah perkiraan biaya operator, dan tampaknya perkiraan ini hanya dipengaruhi oleh perkiraan jumlah baris.
Rumus ini tampaknya memprediksi biaya CPU dengan baik hingga ambang batas sekitar 5.000 baris. Cobalah dengan angka-angka berikut:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS predicatedcost FROM (VALUES(100), (200), (300), (400), (500), (1000) , (2000), (3000), (4000), (5000)) AS D(bilangan);
Bandingkan apa yang diprediksi rumus dan perkiraan biaya CPU yang ditampilkan paket untuk kueri berikut:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Saya mendapatkan hasil berikut:
numrowspredicatedbiaya perkiraan rasio ----------- --------------- -------------- --- ---- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0340.0034374 1.00000> 0.04500000,034375 1.000.000Kolom perkiraan biaya menunjukkan prediksi berdasarkan rumus rekayasa balik kami, kolom perkiraan biaya menunjukkan perkiraan biaya yang muncul dalam rencana, dan rasio kolom menunjukkan rasio antara yang terakhir dan yang pertama.
Predikasinya tampaknya cukup akurat hingga 5.000 baris. Namun, dengan angka yang lebih besar dari 5.000, formula rekayasa balik kami berhenti bekerja dengan baik. Kueri berikut memberi Anda predikat untuk baris 6K, 7K, 10K, 20K, 100K, dan 200K:
SELECT angka, 9.99127891201865E-05 + angka * LOG(angka) * 2.25061348918698E-06 SEBAGAI predicatedcost FROM (VALUES(6000), (7000), (10000), (20000), (100000), (200000) ) AS D(bilangan);Gunakan kueri berikut untuk mendapatkan perkiraan biaya CPU dari paket (perhatikan petunjuk untuk memaksa paket serial karena dengan jumlah baris yang lebih besar, kemungkinan besar Anda akan mendapatkan paket paralel di mana rumus penetapan biaya disesuaikan untuk paralelisme):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1);Saya mendapatkan hasil berikut:
numrowspredicatedbiaya perkiraan rasio ----------- --------------- -------------- --- --- 6000 0.117575 0.160970 1.3691 7000 0.139583 0.244848 1.7541 10000 0.207389 0.603420 2.9096 20000 0.445878 1.311710 2.9419 100000 2.591210 7.623920 2.9422 200000 5.494330 16.165700 2.9423Seperti yang Anda lihat, di luar 5.000 baris, rumus kami menjadi semakin tidak akurat, tetapi anehnya, rasio akurasi stabil pada sekitar 2,94 pada sekitar 20.000 baris. Ini menyiratkan bahwa dengan jumlah besar, rumus kami masih berlaku, hanya dengan biaya perbandingan yang lebih tinggi, dan bahwa kira-kira antara 5.000 dan 20.000 baris, ia bertransisi secara bertahap dari biaya perbandingan yang lebih rendah ke yang lebih tinggi. Tapi apa yang bisa menjelaskan perbedaan antara skala kecil dan skala besar? Kabar baiknya adalah bahwa jawabannya tidak serumit merekonsiliasi mekanika kuantum dan relativitas umum dengan teori string. Hanya saja pada skala yang lebih kecil Microsoft ingin memperhitungkan fakta bahwa cache CPU kemungkinan akan digunakan, dan untuk tujuan biaya, mereka mengasumsikan ukuran cache tetap.
Jadi, untuk mengetahui perbandingan biaya dalam skala besar, Anda ingin menggunakan pengurutan biaya CPU dari dua paket untuk angka di atas 20.000. Saya akan menggunakan 100.000 dan 200.000 baris (dua baris terakhir pada tabel di atas). Berikut rumus untuk menyimpulkan biaya perbandingan:
biaya perbandingan =
(16,1657 – 7,62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6.62193536908588E-06Selanjutnya, inilah rumus untuk menyimpulkan biaya awal berdasarkan paket untuk 200.000 baris:
biaya awal =
16,1657 – 200000*LOG(2000000) * 6.62193536908588E-06 =1.35166186417734E-04Bisa jadi biaya startup untuk skala kecil dan besar sama, dan perbedaan yang kami dapatkan adalah karena kesalahan pembulatan. Bagaimanapun, dengan jumlah baris yang besar, biaya awal menjadi dapat diabaikan dibandingkan dengan biaya perbandingan.
Ringkasnya, berikut rumus biaya CPU operator Sortir untuk jumlah besar (>=20000):
Biaya CPU operator =1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06Mari kita uji keakuratan rumus dengan baris 500K, 1M, dan 10M. Kode berikut memberi Anda prediksi rumus kami:
SELECT angka, 1.35166186417734E-04 + angka * LOG(angka) * 6.62193536908588E-06 AS predicatedcost FROM (VALUES(500000), (1000000), (10000000)) AS D(numrows);Gunakan kueri berikut untuk mendapatkan perkiraan biaya CPU:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT CHECKSUM(NEWID()) as myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);Saya mendapatkan hasil berikut:
numrowspredicatedbiaya perkiraan rasio ----------- --------------- -------------- --- --- 500000 43.4479 43.448 1.0000 1000000 91.4856 91.486 1.0000 10000000 1067.3300 1067.340 1.0000Sepertinya rumus kita untuk bilangan besar cukup berhasil.
Menggabungkan semuanya
Total biaya penerapan agregat aliran dengan penyortiran eksplisit untuk sejumlah kecil baris (<=5.000 baris) adalah:
+ + =
0.0112613
+ 9.99127891201865E-05 + @numrows * LOG(@ numrows) * 2.25061348918698E-06
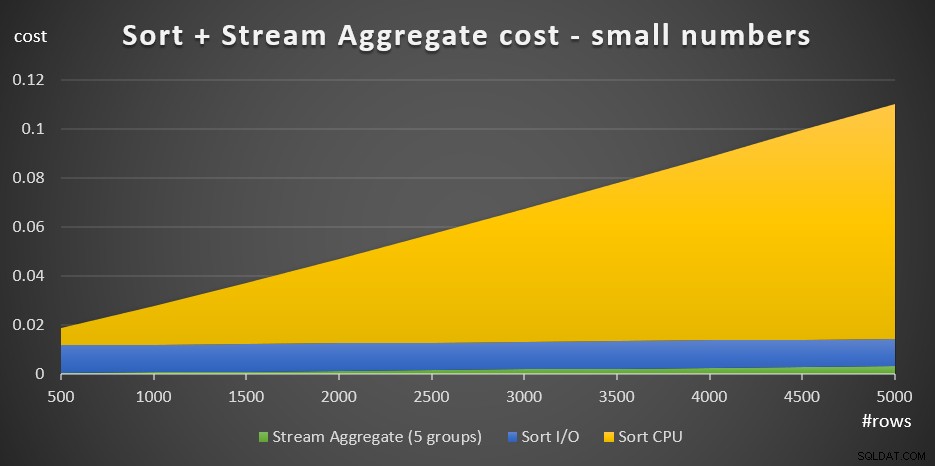
+ @numrows * 0,0000006 + @numgroups * 0,0000005Gambar 3 memiliki bagan area yang menunjukkan bagaimana skala biaya ini.
Gambar 3:Biaya Pengurutan + Agregat Aliran untuk sejumlah kecil barisBiaya CPU sortir adalah bagian paling substansial dari total biaya agregat Sort + Stream. Namun, dengan jumlah baris yang sedikit, biaya Agregat Aliran dan bagian I/O Urutkan dari biaya tidak sepenuhnya dapat diabaikan. Dalam istilah visual, Anda dapat dengan jelas melihat ketiga bagian dalam bagan.
Untuk jumlah baris yang banyak (>=20.000), rumus biayanya adalah:
0.0112613
+ 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+ @numrows * 0,0000006 + @numgroups * 0,0000005Saya tidak melihat banyak nilai dalam mengejar cara yang tepat untuk transisi biaya perbandingan dari skala kecil ke skala besar.
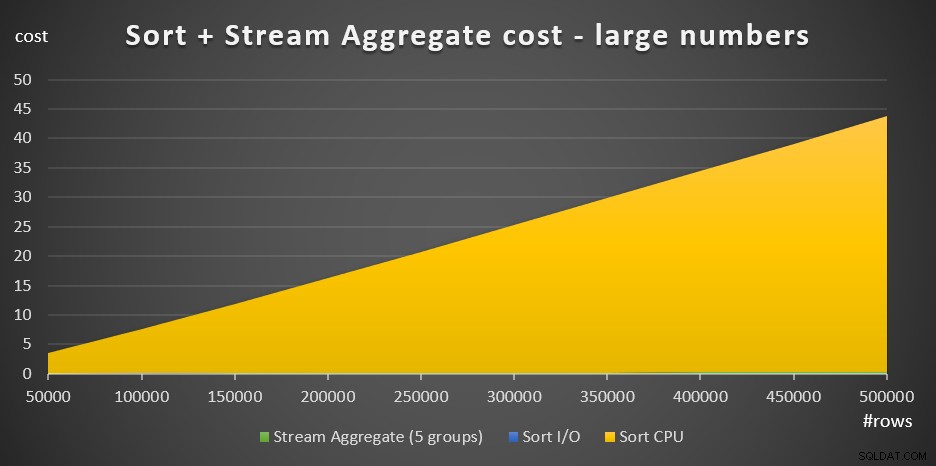
Gambar 4 memiliki bagan area yang menunjukkan bagaimana skala biaya untuk jumlah besar.
Gambar 4:Biaya Pengurutan + Agregat Aliran untuk sejumlah besar barisDengan jumlah baris yang banyak, biaya Stream Agregat dan Sort I/O cost sangat kecil dibandingkan dengan Sort CPU cost sehingga tidak terlihat dengan mata telanjang di grafik. Selain itu, bagian dari biaya Sort CPU yang dikaitkan dengan pekerjaan startup juga dapat diabaikan. Oleh karena itu, satu-satunya bagian dari perhitungan biaya yang benar-benar berarti adalah biaya perbandingan total:
@numrows * LOG(@numrows) *Ini berarti bahwa ketika Anda perlu mengevaluasi penskalaan strategi Sort + Stream Aggregate, Anda dapat menyederhanakannya ke bagian dominan ini saja. Misalnya, jika Anda perlu mengevaluasi bagaimana biaya akan diskalakan dari 100.000 baris menjadi 100.000.000 baris, Anda dapat menggunakan rumus (perhatikan bahwa biaya perbandingan tidak relevan):
(1000000000 * LOG(10000000)*) / (100000 * LOG(100000)*) =1600Ini memberitahu Anda bahwa ketika jumlah baris meningkat dari 100.000 dengan faktor 1.000, menjadi 100.000.000, perkiraan biaya meningkat dengan faktor 1.600.
Penskalaan dari 1.000.000 hingga 1.000.000.000 baris dihitung sebagai:
(1000000000 * LOG(1000000000)) / (1000000 * LOG(1000000)) =1500Artinya, ketika jumlah baris meningkat dari 1.000.000 dengan faktor 1.000, perkiraan biaya meningkat dengan faktor 1.500.
Ini adalah pengamatan menarik tentang cara skala strategi Sort + Stream Aggregate. Karena biaya awal yang sangat rendah, dan penskalaan linier ekstra, Anda akan mengharapkan strategi ini berhasil dengan jumlah baris yang sangat kecil, tetapi tidak begitu baik dengan jumlah baris yang besar. Juga, fakta bahwa operator Stream Aggregate saja mewakili sebagian kecil dari biaya dibandingkan dengan saat penyortiran juga diperlukan, memberi tahu Anda bahwa Anda bisa mendapatkan kinerja yang jauh lebih baik jika situasinya sedemikian rupa sehingga Anda dapat membuat indeks pendukung .
Di bagian selanjutnya dari seri ini, saya akan membahas penskalaan algoritma Hash Aggregate. Jika Anda menikmati latihan mencoba mencari rumus biaya ini, lihat apakah Anda dapat mengetahuinya untuk algoritme ini. Yang penting adalah mencari tahu faktor-faktor yang memengaruhinya, cara skalanya, dan kondisi yang membuatnya lebih baik daripada algoritme lainnya.