Sebagai konsultan yang bekerja dengan SQL Server, sering kali saya diminta untuk melihat server yang sepertinya mengalami masalah kinerja. Saat melakukan triase di server, saya mengajukan pertanyaan tertentu, seperti:berapa utilisasi CPU normal Anda, berapa rata-rata latensi disk Anda, berapa utilisasi memori normal Anda, dan seterusnya. Jawabannya biasanya, “kami tidak tahu” atau “kami tidak menangkap informasi itu secara teratur.” Tidak memiliki dasar baru-baru ini membuat sangat sulit untuk mengetahui seperti apa perilaku abnormal itu. Jika Anda tidak tahu apa itu perilaku normal, bagaimana Anda tahu pasti apakah keadaan menjadi lebih baik atau lebih buruk? Saya sering menggunakan ungkapan, "jika Anda tidak memantaunya, Anda tidak dapat mengukurnya," dan, "jika Anda tidak mengukurnya, Anda tidak dapat mengelolanya."
Dari perspektif pemantauan, minimal, organisasi harus memantau pekerjaan yang gagal seperti pencadangan, pemeliharaan indeks, DBCC CHECKDB, dan pekerjaan penting lainnya. Sangat mudah untuk mengatur pemberitahuan kegagalan untuk ini; namun Anda juga memerlukan proses untuk memastikan pekerjaan berjalan seperti yang diharapkan. Saya telah melihat pekerjaan yang macet dan tidak pernah selesai. Pemberitahuan kegagalan tidak akan memicu alarm karena pekerjaan tidak pernah berhasil atau gagal.
Dari baseline kinerja, ada beberapa metrik utama yang harus ditangkap. Saya telah membuat proses yang saya gunakan dengan klien yang menangkap metrik utama secara teratur dan menyimpan nilai-nilai itu dalam database pengguna. Proses saya sederhana:database khusus dengan prosedur tersimpan yang menggunakan skrip umum yang memasukkan kumpulan hasil ke dalam tabel. Saya memiliki pekerjaan Agen SQL untuk menjalankan prosedur tersimpan secara berkala dan skrip pembersihan untuk membersihkan data yang lebih lama dari X hari. Metrik yang selalu saya tangkap meliputi:
Harapan Hidup Halaman :PLE mungkin adalah salah satu cara terbaik untuk mengukur apakah sistem Anda berada di bawah tekanan memori internal. Sebagian besar sistem memiliki nilai PLE yang berfluktuasi selama beban kerja normal. Saya suka tren nilai-nilai ini untuk mengetahui apa nilai minimum, rata-rata, dan maksimum. Saya suka mencoba memahami apa yang menyebabkan PLE turun selama waktu-waktu tertentu dalam sehari untuk melihat apakah proses tersebut dapat disetel. Sering kali, seseorang melakukan pemindaian tabel dan membilas kumpulan buffer. Mampu mengindeks kueri tersebut dengan benar dapat membantu. Pastikan Anda memantau penghitung PLE yang tepat – lihat di sini .
Utilisasi CPU :Memiliki dasar untuk penggunaan CPU memungkinkan Anda mengetahui jika sistem Anda tiba-tiba berada di bawah tekanan CPU. Seringkali ketika pengguna mengeluh tentang masalah kinerja, mereka akan mengamati bahwa CPU terlihat tinggi. Misalnya, jika CPU berada di sekitar 80% mereka mungkin menemukan hal itu, namun jika CPU juga 80% selama waktu yang sama minggu-minggu sebelumnya ketika tidak ada masalah yang dilaporkan, kemungkinan bahwa CPU adalah masalah sangat rendah. CPU yang sedang tren tidak hanya untuk menangkap saat CPU melonjak dan tetap pada nilai tinggi yang konsisten. Saya memiliki banyak cerita ketika saya dibawa ke jembatan konferensi yang parah karena ada masalah dengan aplikasi. Sebagai DBA, saya memakai topi “Default Blame Acceptor.” Ketika tim aplikasi mengatakan ada masalah dengan database, saya harus membuktikan bahwa itu tidak, server database bersalah sampai terbukti tidak bersalah. Saya ingat dengan jelas sebuah insiden di mana tim aplikasi yakin bahwa server database mengalami masalah karena pengguna tidak dapat terhubung. Mereka telah membaca di internet bahwa SQL Server dapat mengalami kelaparan kumpulan utas jika menolak koneksi. Saya melompat ke server dan mulai melihat sumber daya, dan proses apa yang sedang berjalan. Dalam beberapa menit saya melaporkan kembali bahwa server yang bersangkutan sangat bosan. Berdasarkan metrik dasar kami, CPU biasanya 60% dan idle sekitar 20%, harapan hidup halaman terasa lebih tinggi dari biasanya, dan tidak terjadi penguncian atau pemblokiran, I/O tampak hebat, tidak ada kesalahan dalam log apa pun, dan jumlah sesi sekitar 1/3 dari jumlah normal mereka. Saya kemudian berkomentar, “Tampaknya pengguna bahkan tidak mencapai server database.” Itu menarik perhatian orang-orang jaringan dan mereka menyadari bahwa perubahan yang mereka buat pada penyeimbang beban tidak berfungsi dengan benar dan mereka menentukan bahwa lebih dari 50% koneksi dirutekan secara tidak benar dan tidak sampai ke server database. Jika saya tidak tahu apa dasarnya, kami akan membutuhkan waktu lebih lama untuk mencapai resolusi.
I/O Disk :Menangkap metrik disk sangat penting. Sys.dm_io_virtual_file_stats DMV bersifat kumulatif sejak server terakhir dihidupkan ulang. Menangkap latensi I/O Anda selama interval waktu akan memberi Anda dasar dari apa yang normal selama waktu itu. Mengandalkan nilai kumulatif dapat memberi Anda data miring dari aktivitas setelah jam kerja atau periode lama di mana sistem tidak digunakan. Paul membahasnya di sini .
Ukuran file basis data :Memiliki inventaris database Anda yang mencakup ukuran file, ukuran yang digunakan, ruang kosong, dan lainnya dapat membantu Anda memperkirakan pertumbuhan database. Seringkali saya diminta untuk memperkirakan berapa banyak penyimpanan yang dibutuhkan untuk server database selama tahun mendatang. Tanpa mengetahui tren pertumbuhan mingguan atau bulanan, saya tidak memiliki cara cerdas untuk menghasilkan angka. Setelah saya mulai melacak nilai-nilai ini, saya dapat membuat tren ini dengan benar. Selain trending, saya juga bisa menemukan ketika ada pertumbuhan database yang tidak terduga. Ketika saya melihat pertumbuhan dan penyelidikan yang tidak terduga, saya biasanya menemukan bahwa seseorang menggandakan tabel untuk melakukan beberapa pengujian (ya, dalam produksi!) Atau melakukan proses satu kali lainnya. Melacak jenis data ini, dan mampu merespons saat terjadi anomali, membantu menunjukkan bahwa Anda proaktif dan mengawasi sistem Anda.
Statistik tunggu :Memantau statistik tunggu dapat membantu Anda mulai mencari tahu penyebab masalah kinerja tertentu. Banyak DBA baru yang khawatir ketika mereka pertama kali mulai meneliti statistik menunggu dan gagal menyadari bahwa menunggu selalu terjadi, dan itulah cara kerja sistem penjadwalan SQL Server. Ada juga banyak menunggu yang dapat dianggap jinak, atau sebagian besar tidak berbahaya. Paul Randal mengecualikan penantian yang sebagian besar tidak berbahaya ini dalam skrip statistik menunggu yang populer. Paul juga telah membangun perpustakaan yang luas dari berbagai jenis tunggu dan kelas kait dengan deskripsi dan informasi lain tentang pemecahan masalah tunggu dan kait.
Saya telah mendokumentasikan proses pengumpulan data saya, dan Anda dapat menemukan kodenya di blog saya . Bergantung pada situasi dan jenis masalah yang mungkin dialami klien, saya mungkin juga ingin menangkap metrik tambahan. Glenn Berry membuat blog tentang proses yang dia kumpulkan yang menangkap Hitungan Tugas Rata-Rata, Hitungan Tugas Rata-Rata yang Dapat Dijalankan, Hitungan I/O Rata-rata yang Tertunda, pemanfaatan CPU proses SQL Server, dan Harapan Hidup Halaman Rata-rata di semua node NUMA. Pencarian internet cepat akan memunculkan beberapa proses pengumpulan data lain yang telah dibagikan orang, bahkan SQL Server Tiger Team memiliki proses yang menggunakan T-SQL dan PowerShell.
Menggunakan database kustom dan membangun paket pengumpulan data Anda sendiri adalah solusi yang valid untuk menangkap baseline, tetapi kebanyakan dari kita tidak berkecimpung dalam bisnis membangun solusi pemantauan SQL Server yang lengkap. Masih banyak lagi yang akan berguna untuk ditangkap, hal-hal seperti kueri yang berjalan lama, kueri teratas, dan prosedur tersimpan berdasarkan memori, I/O, dan CPU, kebuntuan, fragmentasi indeks, transaksi per detik, dan banyak lagi. Untuk itu, saya selalu menyarankan agar klien membeli alat pemantauan pihak ketiga. Vendor ini berspesialisasi dalam mengikuti tren dan fitur terbaru SQL Server sehingga Anda dapat memfokuskan waktu Anda untuk memastikan SQL Server stabil dan secepat mungkin.
Solusi seperti SQL Sentry (untuk SQL Server) dan DB Sentry (untuk Azure SQL Database) menangkap semua metrik ini untuk Anda, dan memungkinkan Anda membuat baseline yang berbeda dengan mudah. Anda dapat memiliki baseline normal, akhir bulan, akhir kuartal, dan banyak lagi. Anda kemudian dapat menerapkan garis dasar dan melihat secara visual perbedaannya. Lebih penting lagi, Anda dapat mengonfigurasi sejumlah lansiran untuk berbagai kondisi dan diberi tahu saat metrik melebihi ambang batas Anda.
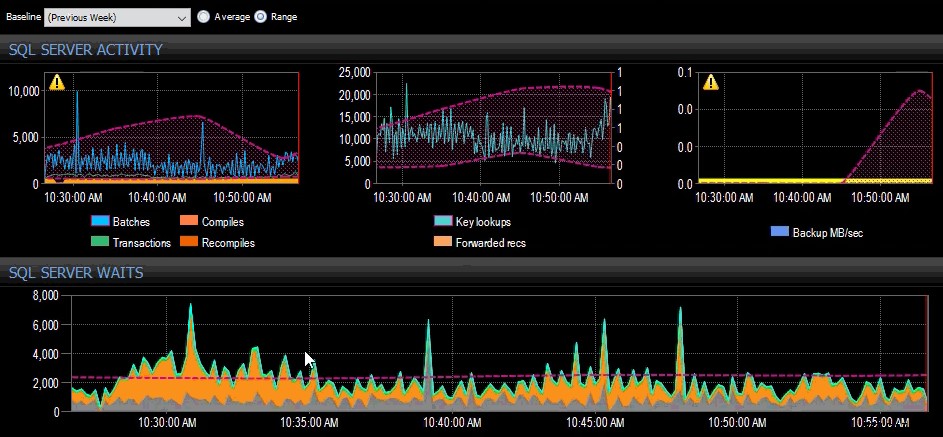 Dasar minggu lalu diterapkan ke beberapa metrik SQL Server di dasbor SQL Sentry.
Dasar minggu lalu diterapkan ke beberapa metrik SQL Server di dasbor SQL Sentry.
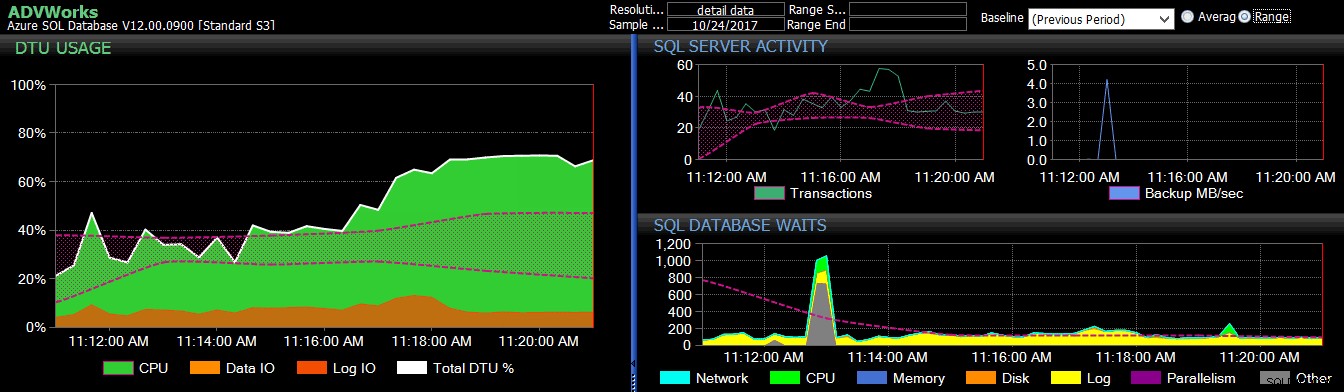 Dasar periode sebelumnya diterapkan ke beberapa metrik Azure SQL Database di dasbor DB Sentry.
Dasar periode sebelumnya diterapkan ke beberapa metrik Azure SQL Database di dasbor DB Sentry.
Untuk informasi lebih lanjut tentang baseline di SentryOne, lihat postingan ini di blog tim mereka, atau video Selasa 2 Menit ini . Tertarik untuk mengunduh percobaan? Mereka juga membantu Anda di sana .