Kevin Kline (@kekline) dan saya baru-baru ini mengadakan webinar penyetelan kueri (yah, sebenarnya satu seri), dan salah satu hal yang muncul adalah kecenderungan orang untuk membuat indeks yang hilang yang menurut SQL Server akan menjadi hal yang bagus™ . Mereka dapat mempelajari indeks yang hilang ini dari Database Engine Tuning Advisor (DTA), DMV indeks yang hilang, atau rencana eksekusi yang ditampilkan di Management Studio atau Plan Explorer (semuanya hanya menyampaikan informasi dari tempat yang sama persis):
Masalah dengan hanya membabi buta membuat indeks ini adalah bahwa SQL Server telah memutuskan bahwa itu berguna untuk kueri tertentu (atau beberapa kueri), tetapi sepenuhnya dan secara sepihak mengabaikan sisa beban kerja. Seperti yang kita semua tahu, indeks tidak "gratis" – Anda membayar indeks baik dalam penyimpanan mentah maupun pemeliharaan yang diperlukan pada operasi DML. Tidak masuk akal, dalam beban kerja tulis-berat, untuk menambahkan indeks yang membantu membuat satu kueri sedikit lebih efisien, terutama jika kueri itu tidak sering dijalankan. Dalam kasus ini, memahami beban kerja Anda secara keseluruhan dan mencapai keseimbangan yang baik antara membuat kueri Anda menjadi efisien dan tidak membayar terlalu banyak untuk itu dalam hal pemeliharaan indeks dapat menjadi sangat penting.
Jadi ide yang saya miliki adalah untuk "menumbuhkan" informasi dari DMV indeks yang hilang, DMV statistik penggunaan indeks, dan informasi tentang rencana kueri, untuk menentukan jenis saldo apa yang saat ini ada dan bagaimana penambahan indeks dapat berjalan secara keseluruhan.
Indeks tidak ada
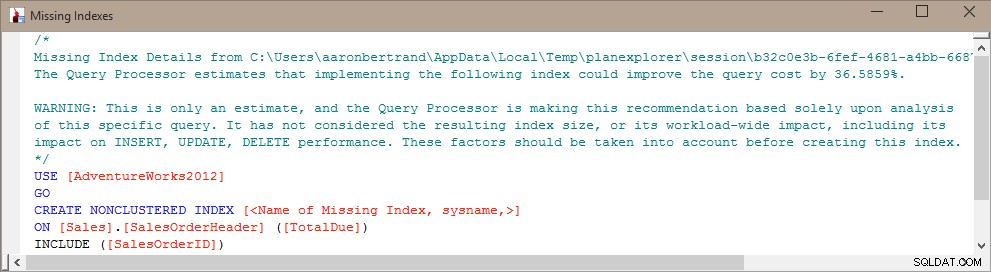
Pertama, kita dapat melihat indeks yang hilang yang saat ini disarankan oleh SQL Server:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Ini menunjukkan tabel dan kolom yang akan berguna dalam indeks, berapa banyak kompilasi/pencarian/pemindaian yang akan digunakan, dan kapan peristiwa terakhir terjadi untuk setiap indeks potensial. Anda juga dapat menyertakan kolom seperti s.avg_total_user_cost dan s.avg_user_impact jika Anda ingin menggunakan angka-angka itu untuk diprioritaskan.
Rencanakan operasi
Selanjutnya, mari kita lihat operasi yang digunakan di semua rencana yang telah kita cache terhadap objek yang telah diidentifikasi oleh indeks yang hilang.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Seorang teman di dba.SE, Mikael Eriksson, menyarankan dua kueri berikut yang, pada sistem yang lebih besar, akan berkinerja jauh lebih baik daripada kueri XML / UNION yang saya buat bersama di atas, sehingga Anda dapat bereksperimen dengan yang pertama. Komentar penutupnya adalah bahwa dia "tidak mengherankan mengetahui bahwa lebih sedikit XML adalah hal yang baik untuk kinerja. :)" Memang.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Sekarang di #planops tabel Anda memiliki banyak nilai untuk plan_handle sehingga Anda dapat pergi dan menyelidiki masing-masing rencana individu dalam permainan melawan objek yang telah diidentifikasi tidak memiliki indeks yang berguna. Kami tidak akan menggunakannya untuk itu sekarang, tetapi Anda dapat dengan mudah melakukan referensi silang dengan:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Sekarang Anda dapat mengklik salah satu rencana keluaran untuk melihat apa yang sedang mereka lakukan terhadap objek Anda. Perhatikan bahwa beberapa paket akan diulang, karena sebuah paket dapat memiliki beberapa operator yang mereferensikan indeks berbeda pada tabel yang sama.
Statistik penggunaan indeks
Selanjutnya, mari kita lihat statistik penggunaan indeks, sehingga kita dapat melihat seberapa banyak aktivitas aktual yang saat ini berjalan terhadap tabel kandidat kita (dan, khususnya, pembaruan).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Jangan khawatir jika sangat sedikit atau tidak ada rencana dalam cache yang menunjukkan pembaruan untuk indeks tertentu, meskipun statistik penggunaan indeks menunjukkan bahwa indeks tersebut telah diperbarui. Ini hanya berarti bahwa paket pembaruan saat ini tidak ada dalam cache, yang mungkin karena berbagai alasan – misalnya, itu bisa menjadi beban kerja yang sangat berat untuk dibaca dan sudah usang, atau semuanya tunggal. gunakan dan optimize for ad hoc workloads diaktifkan.
Menggabungkan semuanya
Kueri berikut akan menunjukkan kepada Anda, untuk setiap indeks yang hilang yang disarankan, jumlah pembacaan yang mungkin dibantu oleh indeks, jumlah penulisan dan pembacaan yang saat ini telah ditangkap terhadap indeks yang ada, rasionya, jumlah paket yang terkait dengan objek itu, dan jumlah total penggunaan untuk paket tersebut:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Jika rasio tulis:baca Anda untuk indeks ini sudah> 1 (atau> 10!), saya pikir itu memberi alasan untuk jeda sebelum membuat indeks secara membabi buta yang hanya dapat meningkatkan rasio ini. Jumlah potential_read_ops ditampilkan, bagaimanapun, dapat mengimbangi itu karena jumlahnya menjadi lebih besar. Jika potential_read_ops Jumlahnya sangat kecil, Anda mungkin ingin mengabaikan rekomendasi sepenuhnya bahkan sebelum repot menyelidiki metrik lainnya – sehingga Anda dapat menambahkan WHERE klausa untuk menyaring beberapa rekomendasi tersebut.
Beberapa catatan:
- Ini adalah operasi baca dan tulis, bukan baca dan tulis yang diukur secara individual dari 8K halaman.
- Rasio dan perbandingannya sebagian besar bersifat mendidik; sangat mungkin terjadi bahwa 10.000.000 operasi tulis semuanya memengaruhi satu baris, sementara 10 operasi baca dapat memiliki dampak yang jauh lebih besar. Ini hanya dimaksudkan sebagai pedoman kasar dan mengasumsikan bahwa operasi baca dan tulis berbobot kira-kira sama.
- Anda juga dapat menggunakan sedikit variasi pada beberapa kueri ini untuk mencari tahu – di luar indeks yang hilang yang direkomendasikan SQL Server – berapa banyak indeks Anda saat ini yang boros. Ada banyak ide tentang ini secara online, termasuk posting ini oleh Paul Randal (@PaulRandal).
Saya harap itu memberikan beberapa ide untuk mendapatkan lebih banyak wawasan tentang perilaku sistem Anda sebelum Anda memutuskan untuk menambahkan indeks yang diminta oleh beberapa alat untuk Anda buat. Saya bisa saja membuat ini sebagai satu permintaan besar, tetapi saya pikir bagian-bagian individual akan memberi Anda beberapa lubang kelinci untuk diselidiki, jika Anda mau.
Catatan lainnya
Anda mungkin juga ingin memperluas ini untuk menangkap metrik ukuran saat ini, lebar tabel, dan jumlah baris saat ini (serta prediksi apa pun tentang pertumbuhan di masa mendatang); ini dapat memberi Anda ide bagus tentang berapa banyak ruang yang akan digunakan oleh indeks baru, yang dapat menjadi perhatian tergantung pada lingkungan Anda. Saya mungkin akan membahas ini di postingan mendatang.
Tentu saja, Anda harus ingat bahwa metrik ini hanya berguna seperti yang ditentukan waktu aktif Anda. DMV dihapus setelah dimulai ulang (dan terkadang dalam skenario lain yang tidak terlalu mengganggu), jadi jika menurut Anda informasi ini akan berguna dalam jangka waktu yang lebih lama, mengambil snapshot secara berkala mungkin merupakan sesuatu yang ingin Anda pertimbangkan.