Salah satu dari banyak fitur baru yang diperkenalkan kembali di SQL Server 2008 adalah Kompresi Data. Kompresi pada tingkat baris atau halaman memberikan kesempatan untuk menghemat ruang disk, dengan pengorbanan membutuhkan lebih banyak CPU untuk mengompresi dan mendekompresi data. Sering dikatakan bahwa sebagian besar sistem terikat IO, bukan terikat CPU, jadi pengorbanannya sepadan. menangkap? Anda harus menggunakan Edisi Perusahaan untuk menggunakan Kompresi Data. Dengan rilis SQL Server 2016 SP1, itu telah berubah! Jika Anda menjalankan Edisi Standar SQL Server 2016 SP1 dan lebih tinggi, Anda sekarang dapat menggunakan Kompresi Data. Ada juga fungsi bawaan baru untuk kompresi, COMPRESS (dan mitranya DECOMPRESS). Kompresi Data tidak berfungsi pada data di luar baris, jadi jika Anda memiliki kolom seperti NVARCHAR(MAX) di tabel Anda dengan nilai yang biasanya berukuran lebih dari 8000 byte, data tersebut tidak akan dikompresi (terima kasih Adam Machanic untuk pengingat itu) . Fungsi COMPRESS memecahkan masalah ini, dan mengompresi data hingga ukuran 2GB. Selain itu, sementara saya berpendapat bahwa fungsi tersebut hanya boleh digunakan untuk data besar di luar baris, saya pikir membandingkannya secara langsung dengan kompresi baris dan halaman adalah eksperimen yang bermanfaat.
PENYIAPAN
Untuk data pengujian, saya sedang mengerjakan skrip yang digunakan Aaron Bertrand sebelumnya, tetapi saya telah membuat beberapa penyesuaian. Saya membuat database terpisah untuk pengujian tetapi Anda dapat menggunakan tempdb atau database sampel lain, dan kemudian saya mulai dengan tabel Pelanggan yang memiliki tiga kolom NVARCHAR. Saya mempertimbangkan untuk membuat kolom yang lebih besar dan mengisinya dengan rangkaian huruf yang berulang, tetapi menggunakan teks yang dapat dibaca memberikan contoh yang lebih realistis dan dengan demikian memberikan akurasi yang lebih besar.
Catatan: Jika Anda tertarik untuk menerapkan kompresi dan ingin tahu bagaimana hal itu akan memengaruhi penyimpanan dan kinerja di lingkungan Anda, SAYA SANGAT MEREKOMENDASIKAN ANDA MENGUJINYA. Saya memberi Anda metodologi dengan data sampel; menerapkan ini di lingkungan Anda seharusnya tidak melibatkan pekerjaan tambahan.
Anda akan melihat di bawah bahwa setelah membuat database, kami mengaktifkan Query Store. Mengapa membuat tabel terpisah untuk mencoba dan melacak metrik kinerja kami ketika kami hanya dapat menggunakan fungsionalitas yang ada di dalam SQL Server?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Sekarang kita akan menyiapkan beberapa hal di dalam database:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Dengan tabel yang dibuat, kami akan menambahkan beberapa data, tetapi kami menambahkan 5 juta baris, bukan 1 juta. Ini membutuhkan waktu sekitar delapan menit untuk dijalankan di laptop saya.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Sekarang kita akan membuat tiga tabel lagi:satu untuk kompresi baris, satu untuk kompresi halaman, dan satu untuk fungsi KOMPRES. Perhatikan bahwa dengan fungsi KOMPRES, Anda harus membuat kolom sebagai tipe data VARBINARY. Akibatnya, tidak ada indeks nonclustered pada tabel (karena Anda tidak dapat membuat kunci indeks pada kolom varbinary).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Selanjutnya kita akan menyalin data dari [dbo].[Pelanggan] ke tiga tabel lainnya. Ini adalah INSERT langsung untuk tabel halaman dan baris kami dan membutuhkan waktu sekitar dua hingga tiga menit untuk setiap INSERT, tetapi ada masalah skalabilitas dengan fungsi COMPRESS:mencoba memasukkan 5 juta baris dalam satu gerakan saja tidak masuk akal. Skrip di bawah ini menyisipkan baris dalam kumpulan 50.000, dan hanya menyisipkan 1 juta baris, bukan 5 juta. Saya tahu, itu berarti kami tidak benar-benar apple-to-apple di sini untuk perbandingan, tapi saya setuju dengan itu. Memasukkan 1 juta baris membutuhkan waktu 10 menit di mesin saya; jangan ragu untuk mengubah skrip dan menyisipkan 5 juta baris untuk pengujian Anda sendiri.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Dengan semua tabel kami terisi, kami dapat melakukan pemeriksaan ukuran. Pada titik ini, kami belum mengimplementasikan kompresi ROW atau PAGE, tetapi fungsi COMPRESS telah digunakan:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
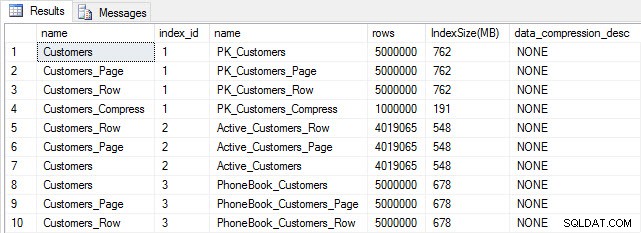 Ukuran tabel dan indeks setelah disisipkan
Ukuran tabel dan indeks setelah disisipkan
Seperti yang diharapkan, semua tabel kecuali Customers_Compress berukuran hampir sama. Sekarang kita akan membangun kembali indeks pada semua tabel, menerapkan kompresi baris dan halaman pada Customers_Row dan Customers_Page, masing-masing.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Jika kita memeriksa ukuran tabel setelah kompresi, sekarang kita dapat melihat penghematan ruang disk kita:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
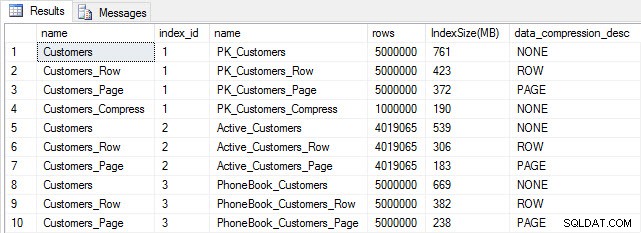
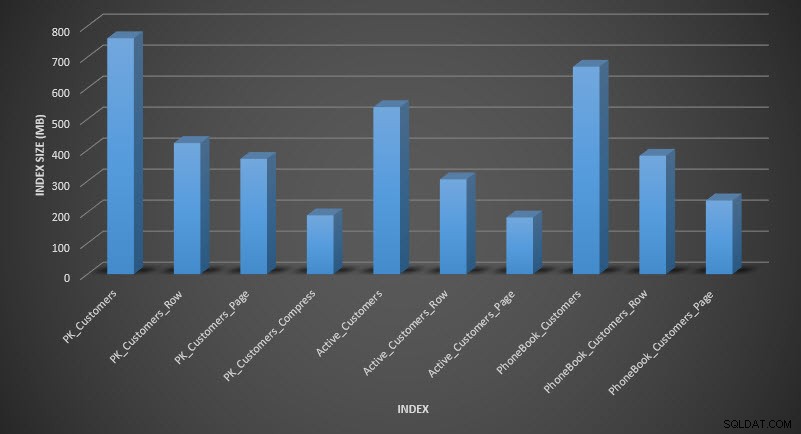 Ukuran indeks setelah kompresi
Ukuran indeks setelah kompresi
Seperti yang diharapkan, kompresi baris dan halaman secara signifikan mengurangi ukuran tabel dan indeksnya. Fungsi COMPRESS menghemat ruang paling banyak – indeks berkerumun berukuran seperempat dari tabel aslinya.
MEMERIKSA KINERJA QUERY
Sebelum kami menguji kinerja kueri, perhatikan bahwa kami dapat menggunakan Toko Kueri untuk melihat kinerja INSERT dan REBUILD:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
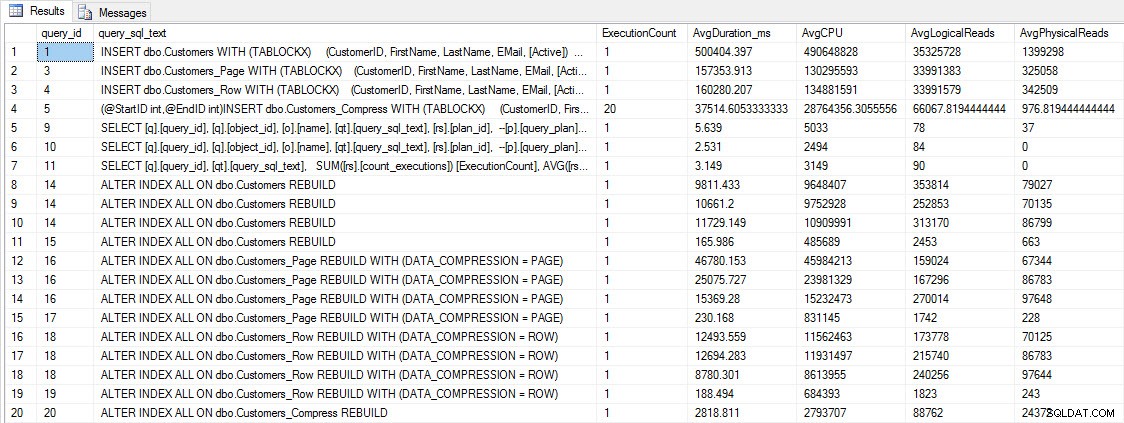 INSERT dan REBUILD metrik kinerja
INSERT dan REBUILD metrik kinerja
Meskipun data ini menarik, saya lebih ingin tahu tentang bagaimana kompresi memengaruhi kueri SELECT saya sehari-hari. Saya memiliki satu set tiga prosedur tersimpan yang masing-masing memiliki satu kueri SELECT, sehingga setiap indeks digunakan. Saya membuat prosedur ini untuk setiap tabel, dan kemudian menulis skrip untuk menarik nilai nama depan dan belakang yang akan digunakan untuk pengujian. Berikut script untuk membuat prosedurnya.
Setelah prosedur tersimpan dibuat, kita dapat menjalankan skrip di bawah ini untuk memanggilnya. Mulai ini, lalu tunggu beberapa menit…
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Setelah beberapa menit, intip apa yang ada di Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Anda akan melihat bahwa sebagian besar prosedur tersimpan hanya dijalankan 20 kali karena dua prosedur terhadap [dbo].[Customers_Compress] benar-benar lambat. Ini bukan kejutan; baik [FirstName] maupun [LastName] tidak diindeks, jadi setiap kueri harus memindai tabel. Saya tidak ingin kedua kueri tersebut memperlambat pengujian saya, jadi saya akan memodifikasi beban kerja dan mengomentari EXEC [dbo].[usp_FindActiveCustomer_CS] dan EXEC [dbo].[usp_FindAnyCustomer_CS] lalu memulainya lagi. Kali ini, saya akan membiarkannya berjalan selama sekitar 10 menit, dan ketika saya melihat output Query Store lagi, sekarang saya memiliki beberapa data yang bagus. Angka mentah ada di bawah, dengan grafik favorit manajer di bawah.
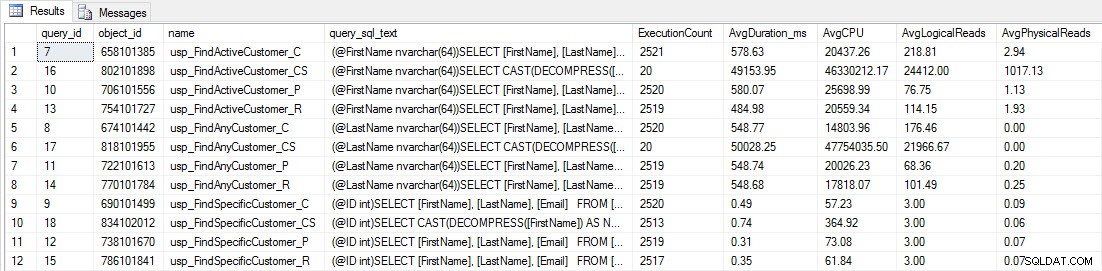 Data kinerja dari Toko Kueri
Data kinerja dari Toko Kueri
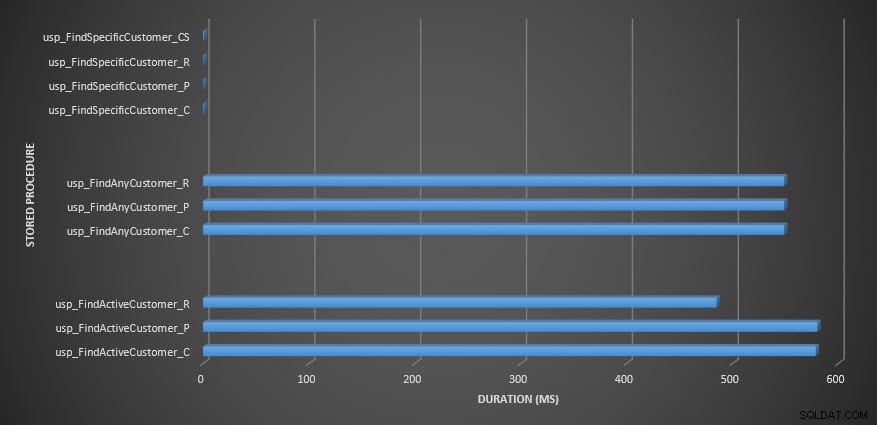 Durasi prosedur tersimpan
Durasi prosedur tersimpan
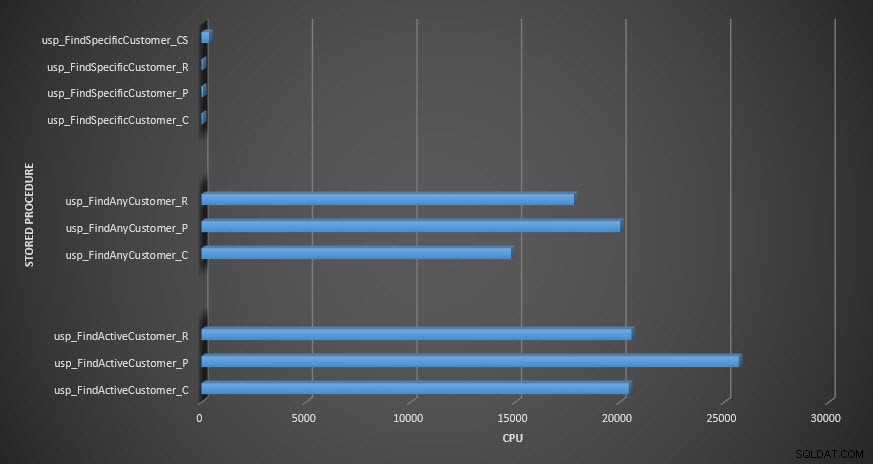 CPU prosedur tersimpan
CPU prosedur tersimpan
Pengingat:Semua prosedur tersimpan yang diakhiri dengan _C berasal dari tabel yang tidak dikompresi. Prosedur yang diakhiri dengan _R adalah tabel yang dikompresi baris, yang diakhiri dengan _P adalah halaman yang dikompresi, dan prosedur dengan _CS menggunakan fungsi COMPRESS (Saya menghapus hasil untuk tabel tersebut untuk usp_FindAnyCustomer_CS dan usp_FindActiveCustomer_CS karena mereka sangat mencondongkan grafik sehingga kami kehilangan perbedaan data lainnya). Prosedur usp_FindAnyCustomer_* dan usp_FindActiveCustomer_* menggunakan indeks nonclustered dan mengembalikan ribuan baris untuk setiap eksekusi.
Saya mengharapkan durasi lebih tinggi untuk prosedur usp_FindAnyCustomer_* dan usp_FindActiveCustomer_* terhadap tabel terkompresi baris dan halaman, dibandingkan dengan tabel yang tidak dikompresi, karena overhead dekompresi data. Data Penyimpanan Kueri tidak mendukung harapan saya – durasi untuk dua prosedur tersimpan tersebut kira-kira sama (atau kurang dalam satu kasus!) di ketiga tabel tersebut. IO logis untuk kueri hampir sama di seluruh tabel yang tidak dikompresi dan halaman dan baris yang dikompresi.
Dalam hal CPU, dalam prosedur tersimpan usp_FindActiveCustomer dan usp_FindAnyCustomer selalu lebih tinggi untuk tabel terkompresi. CPU sebanding untuk prosedur usp_FindSpecificCustomer, yang selalu merupakan pencarian tunggal terhadap indeks berkerumun. Perhatikan CPU yang tinggi (tetapi durasinya relatif rendah) untuk prosedur usp_FindSpecificCustomer terhadap tabel [dbo].[Customer_Compress], yang memerlukan fungsi DECOMPRESS untuk menampilkan data dalam format yang dapat dibaca.
RINGKASAN
CPU tambahan yang diperlukan untuk mengambil data terkompresi ada dan dapat diukur menggunakan Query Store atau metode dasar tradisional. Berdasarkan pengujian awal ini, CPU sebanding untuk pencarian tunggal, tetapi meningkat dengan lebih banyak data. Saya ingin memaksa SQL Server untuk mendekompres lebih dari hanya 10 halaman – saya ingin setidaknya 100. Saya menjalankan variasi skrip ini, di mana puluhan ribu baris dikembalikan, dan temuannya konsisten dengan apa yang Anda lihat di sini. Harapan saya adalah untuk melihat perbedaan durasi yang signifikan karena waktu untuk mendekompresi data, kueri perlu mengembalikan ratusan ribu, atau jutaan baris. Jika Anda menggunakan sistem OLTP, Anda tidak ingin mengembalikan banyak baris, jadi pengujian di sini akan memberi Anda gambaran tentang bagaimana kompresi dapat memengaruhi kinerja. Jika Anda berada di gudang data, maka Anda mungkin akan melihat durasi yang lebih tinggi bersama dengan CPU yang lebih tinggi saat mengembalikan kumpulan data besar. Sementara fungsi KOMPRES memberikan penghematan ruang yang signifikan dibandingkan dengan kompresi halaman dan baris, kinerja yang dicapai dalam hal CPU, dan ketidakmampuan untuk mengindeks kolom terkompresi karena tipe datanya, membuatnya layak hanya untuk volume data besar yang tidak akan dicari.