Minggu lalu, saya mempresentasikan sesi T-SQL :Kebiasaan Buruk dan Praktik Terbaik saya selama konferensi GroupBy. Video replay dan materi lainnya tersedia di sini:
- T-SQL :Kebiasaan Buruk dan Praktik Terbaik
Salah satu item yang selalu saya sebutkan di sesi itu adalah bahwa saya biasanya lebih suka GROUP BY daripada DISTINCT saat menghilangkan duplikat. Meskipun DISTINCT menjelaskan maksud dengan lebih baik, dan GROUP BY hanya diperlukan jika ada agregasi, mereka dapat dipertukarkan dalam banyak kasus.
Mari kita mulai dengan sesuatu yang sederhana menggunakan Wide World Importers. Kedua kueri ini menghasilkan hasil yang sama:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
Dan sebenarnya, dapatkan hasilnya menggunakan rencana eksekusi yang sama persis:

Operator yang sama, jumlah pembacaan yang sama, perbedaan CPU dan durasi total yang dapat diabaikan (mereka bergiliran "menang").
Jadi mengapa saya merekomendasikan menggunakan sintaks GROUP BY yang lebih banyak kata dan kurang intuitif daripada DISTINCT? Nah, dalam kasus sederhana ini, ini adalah lemparan koin. Namun, dalam kasus yang lebih kompleks, DISTINCT dapat melakukan lebih banyak pekerjaan. Pada dasarnya, DISTINCT mengumpulkan semua baris, termasuk ekspresi apa pun yang perlu dievaluasi, dan kemudian membuang duplikatnya. GROUP BY dapat (sekali lagi, dalam beberapa kasus) memfilter baris duplikat sebelum melakukan pekerjaan itu.
Mari kita bicara tentang agregasi string, misalnya. Sementara di SQL Server v.Next Anda akan dapat menggunakan STRING_AGG (lihat posting di sini dan di sini), kita semua harus melanjutkan FOR XML PATH (dan sebelum Anda memberi tahu saya tentang betapa menakjubkannya CTE rekursif untuk ini, tolong baca posting ini juga). Kami mungkin memiliki kueri seperti ini, yang mencoba mengembalikan semua Pesanan dari tabel Sales.OrderLines, bersama dengan deskripsi item sebagai daftar yang dipisahkan tanda pipa:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Ini adalah kueri khas untuk memecahkan masalah semacam ini, dengan rencana eksekusi berikut (peringatan di semua rencana hanya untuk konversi implisit yang keluar dari filter XPath):
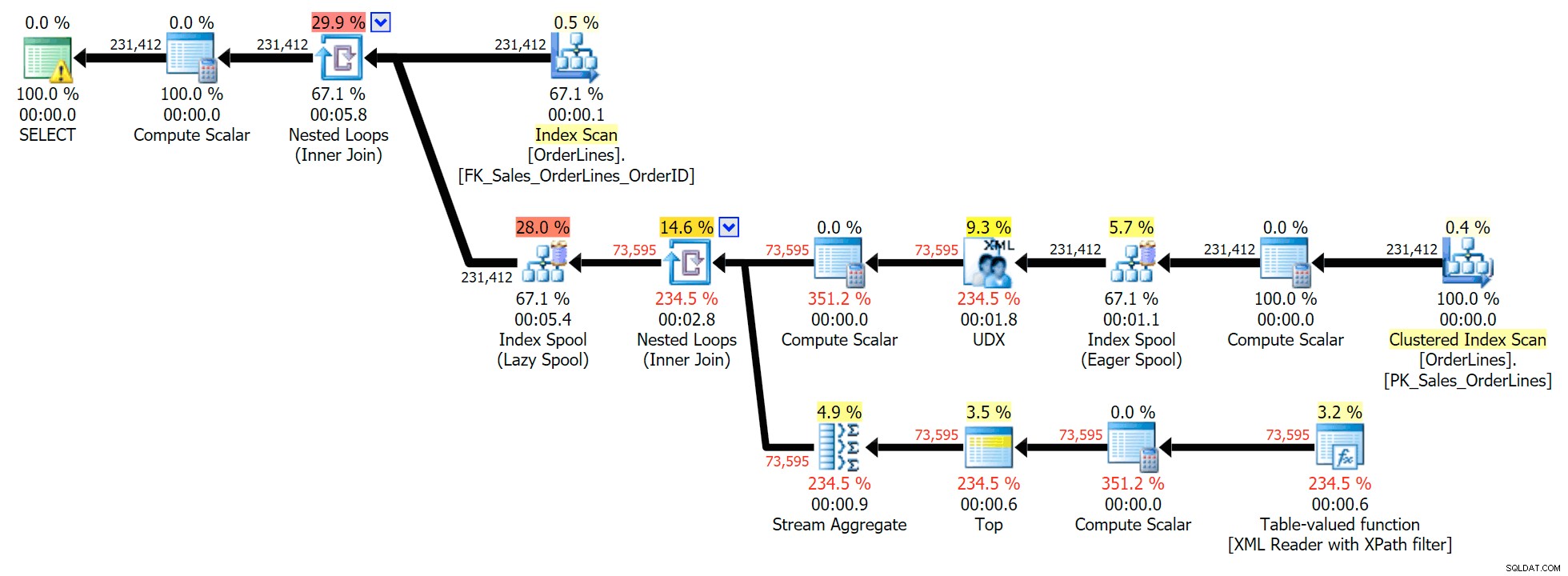
Namun, ini memiliki masalah yang mungkin Anda perhatikan dalam jumlah baris keluaran. Anda pasti dapat menemukannya saat memindai output dengan santai:

Untuk setiap pesanan, kami melihat daftar yang dibatasi pipa, tetapi kami melihat baris untuk setiap item di setiap pesanan. Reaksi spontan adalah melemparkan DISTINCT pada daftar kolom:
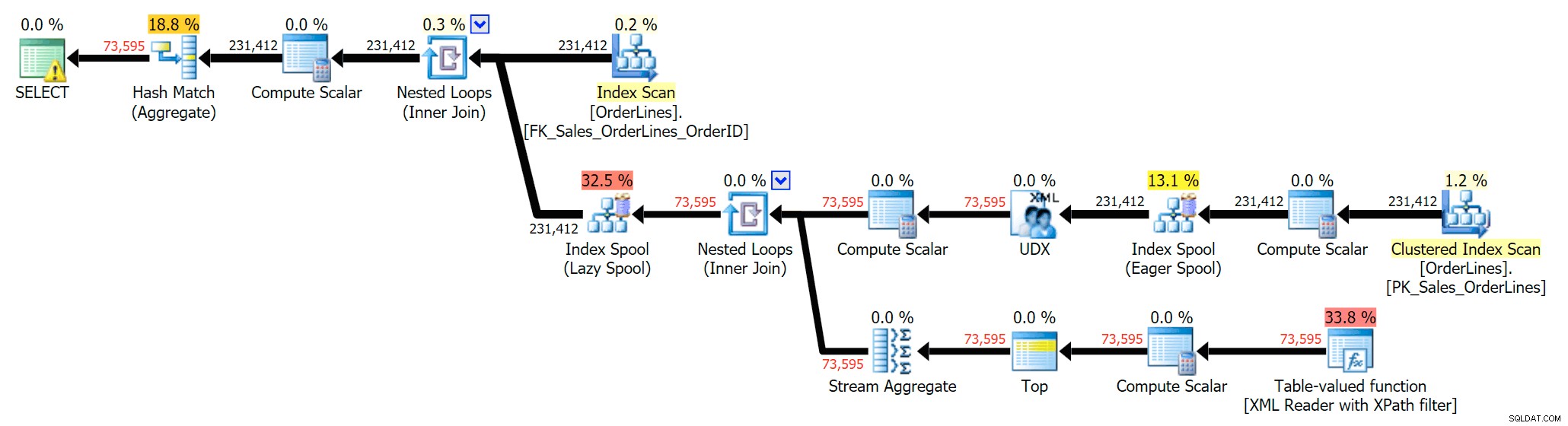
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Itu menghilangkan duplikat (dan mengubah properti pemesanan pada pemindaian, sehingga hasilnya tidak selalu muncul dalam urutan yang dapat diprediksi), dan menghasilkan rencana eksekusi berikut:
Cara lain untuk melakukannya adalah dengan menambahkan GROUP BY untuk OrderID (karena subquery tidak secara eksplisit membutuhkan untuk direferensikan lagi di GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Ini menghasilkan hasil yang sama (meskipun pesanan telah dikembalikan), dan rencana yang sedikit berbeda:
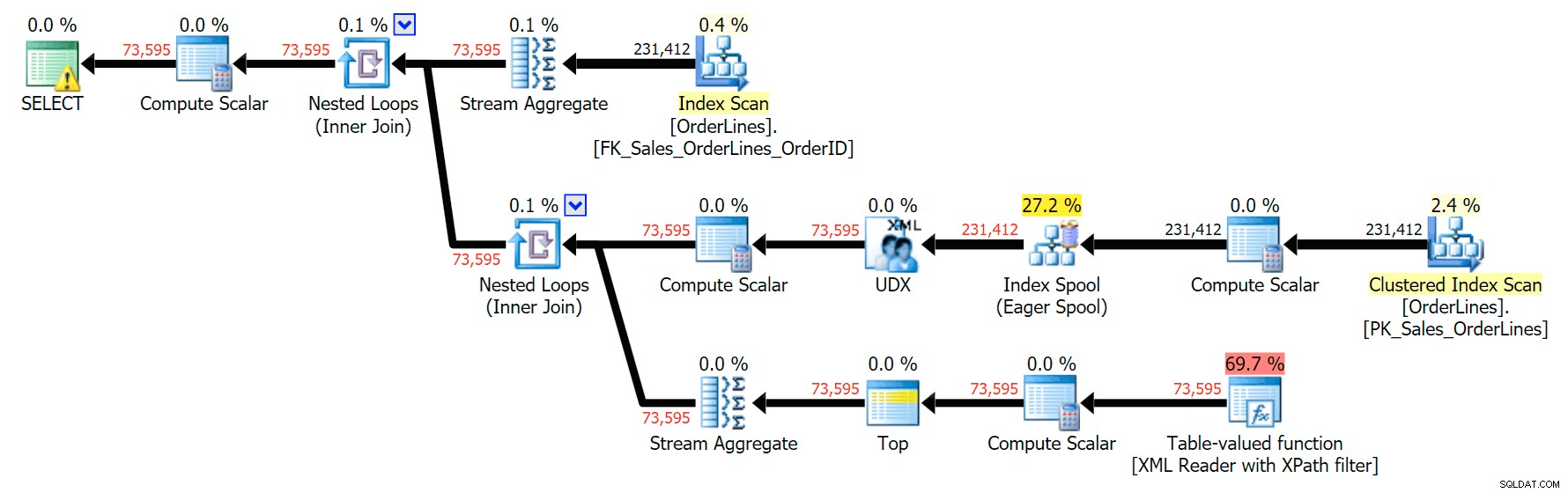
Namun, metrik kinerja menarik untuk dibandingkan.

Variasi DISTINCT membutuhkan waktu 4X lebih lama, menggunakan CPU 4X, dan hampir 6X pembacaan jika dibandingkan dengan variasi GROUP BY. (Ingat, kueri ini mengembalikan hasil yang sama persis.)
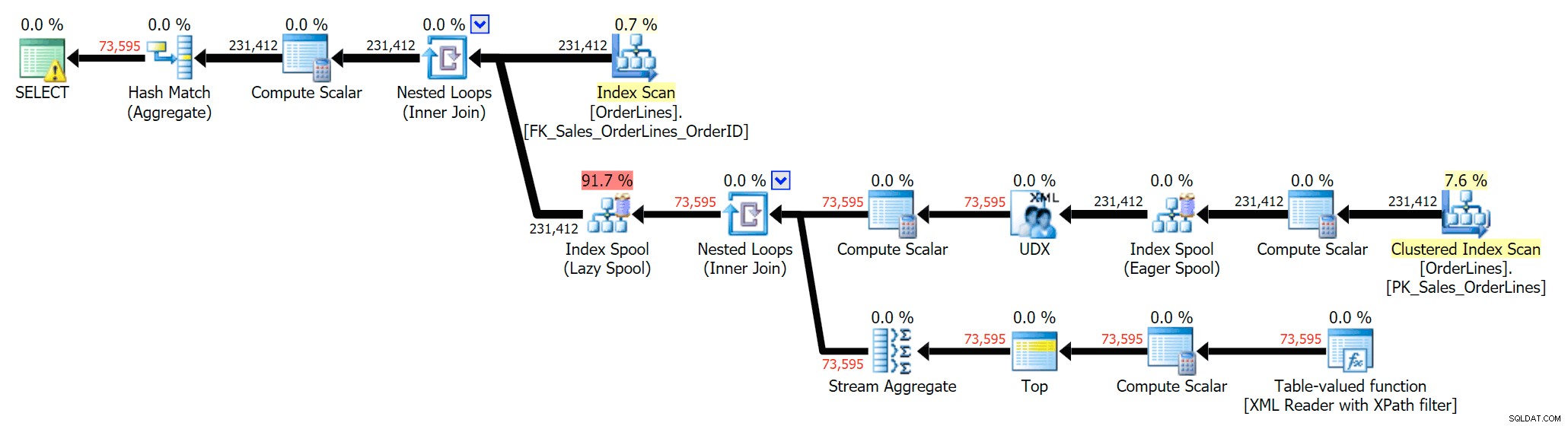
Kami juga dapat membandingkan rencana eksekusi saat kami mengubah biaya dari gabungan CPU + I/O menjadi I/O saja, fitur eksklusif untuk Plan Explorer. Kami juga menunjukkan nilai re-costed (yang didasarkan pada aktual biaya yang diamati selama eksekusi kueri, fitur yang juga hanya ditemukan di Plan Explorer). Berikut adalah paket DISTINCT:
Dan inilah rencana GROUP BY:
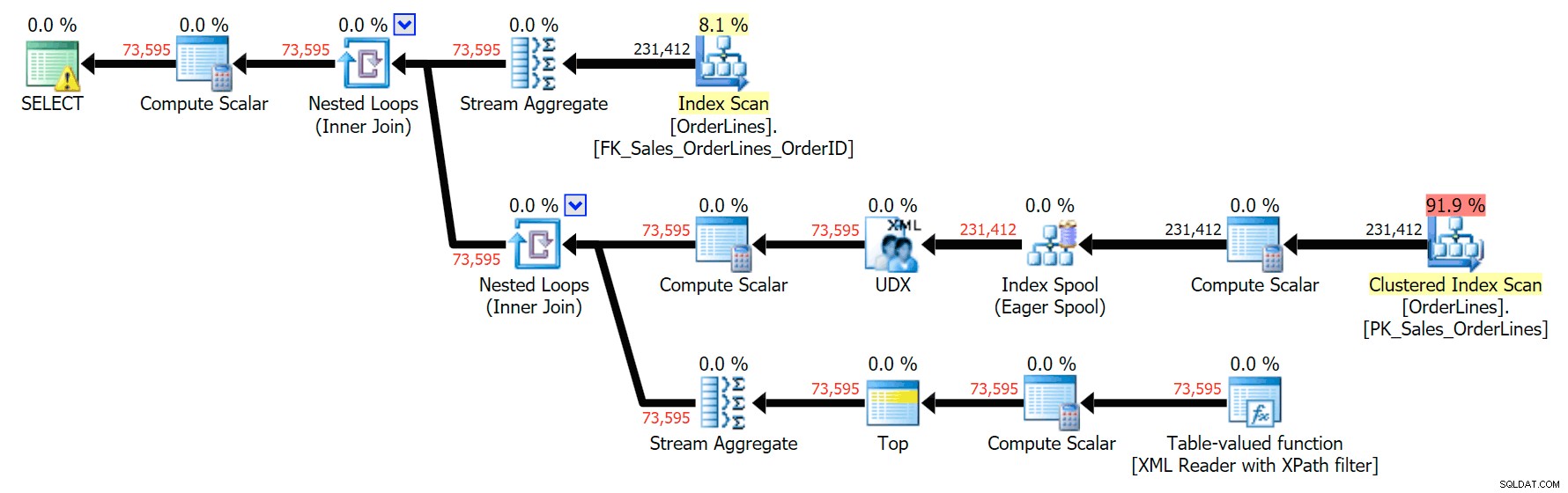
Anda dapat melihat bahwa, dalam paket GROUP BY, hampir semua biaya I/O ada dalam pemindaian (berikut tooltip untuk pemindaian CI, menunjukkan biaya I/O ~3,4 "uang kueri"). Namun dalam paket DISTINCT, sebagian besar biaya I/O ada di spool indeks (dan inilah tooltip itu; biaya I/O di sini adalah ~41,4 "query bucks"). Perhatikan bahwa CPU juga jauh lebih tinggi dengan spool indeks. Kami akan berbicara tentang "permintaan dolar" lain kali, tetapi intinya adalah bahwa gulungan indeks lebih dari 10X lebih mahal dari pemindaian – namun pemindaian masih sama 3.4 di kedua paket. Ini adalah salah satu alasan mengapa selalu mengganggu saya ketika orang mengatakan mereka perlu "memperbaiki" operator dalam paket dengan biaya tertinggi. Beberapa operator dalam paket akan selalu menjadi yang paling mahal; itu tidak berarti itu perlu diperbaiki.
@AaronBertrand kueri tersebut tidak benar-benar setara secara logis — DISTINCT adalah di kedua kolom, sedangkan GROUP BY Anda hanya di satu
— Adam Machanic (@AdamMachanic) 20 Januari 2017
Meskipun Adam Machanic benar ketika dia mengatakan bahwa kueri ini berbeda secara semantik, hasilnya sama – kami mendapatkan jumlah baris yang sama, berisi hasil yang persis sama, dan kami melakukannya dengan pembacaan dan CPU yang jauh lebih sedikit.
Jadi, meskipun DISTINCT dan GROUP BY identik dalam banyak skenario, berikut adalah satu kasus di mana pendekatan GROUP BY pasti mengarah pada kinerja yang lebih baik (dengan mengorbankan maksud deklaratif yang kurang jelas dalam kueri itu sendiri). Saya tertarik untuk mengetahui apakah menurut Anda ada skenario di mana DISTINCT lebih baik daripada GROUP BY, setidaknya dalam hal kinerja, yang jauh lebih subyektif daripada gaya atau apakah pernyataan perlu didokumentasikan sendiri.
Pos ini cocok dengan seri "kejutan dan asumsi" saya karena banyak hal yang kami pegang sebagai kebenaran berdasarkan pengamatan terbatas atau kasus penggunaan tertentu dapat diuji saat digunakan dalam skenario lain. Kami hanya perlu ingat untuk meluangkan waktu untuk melakukannya sebagai bagian dari pengoptimalan kueri SQL…
Referensi
- Penggabungan yang Dikelompokkan di SQL Server
- Penggabungan yang Dikelompokkan :Mengurutkan dan Menghapus Duplikat
- Empat Kasus Penggunaan Praktis untuk Penggabungan yang Dikelompokkan
- SQL Server v.Berikutnya :Performa STRING_AGG()
- SQL Server v.Berikutnya :Performa STRING_AGG, Bagian 2