Cara tercepat untuk menghitung median menggunakan SQL Server 2012 OFFSET ekstensi ke ORDER BY ayat. Menjalankan hampir sedetik, solusi tercepat berikutnya menggunakan kursor dinamis (mungkin bersarang) yang berfungsi di semua versi. Artikel ini membahas ROW_NUMBER umum pra-2012 solusi untuk masalah perhitungan median untuk melihat mengapa kinerjanya kurang baik, dan apa yang dapat dilakukan untuk membuatnya lebih cepat.
Uji Median Tunggal
Data sampel untuk pengujian ini terdiri dari tabel sepuluh juta baris tunggal (direproduksi dari artikel asli Aaron Bertrand):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Solusi OFFSET
Untuk menetapkan tolok ukur, berikut adalah solusi OFFSET SQL Server 2012 (atau lebih baru) yang dibuat oleh Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
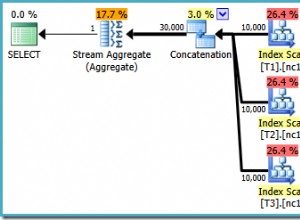
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Kueri untuk menghitung baris dalam tabel dikomentari dan diganti dengan nilai hard-code untuk berkonsentrasi pada kinerja kode inti. Dengan cache hangat dan kumpulan rencana eksekusi dimatikan, kueri ini berjalan selama 910 md rata-rata pada mesin uji saya. Rencana eksekusi ditunjukkan di bawah ini:

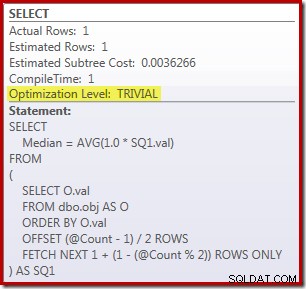
Sebagai catatan tambahan, menarik bahwa kueri yang cukup rumit ini memenuhi syarat untuk rencana sepele:
Solusi ROW_NUMBER
Untuk sistem yang menjalankan SQL Server 2008 R2 atau yang lebih lama, solusi alternatif dengan kinerja terbaik menggunakan kursor dinamis seperti yang disebutkan sebelumnya. Jika Anda tidak dapat (atau tidak mau) mempertimbangkannya sebagai opsi, wajar untuk berpikir untuk meniru OFFSET 2012 rencana eksekusi menggunakan ROW_NUMBER .
Ide dasarnya adalah memberi nomor baris dalam urutan yang sesuai, lalu memfilter hanya satu atau dua baris yang diperlukan untuk menghitung median. Ada beberapa cara untuk menulis ini di Transact SQL; versi ringkas yang menangkap semua elemen kunci adalah sebagai berikut:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
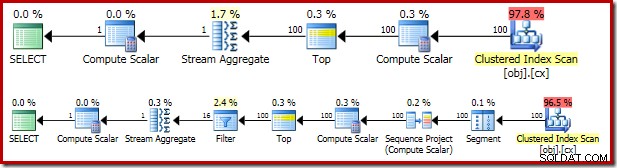
Rencana eksekusi yang dihasilkan sangat mirip dengan OFFSET versi:

Sebaiknya lihat masing-masing operator paket secara bergantian untuk memahaminya sepenuhnya:
- Operator Segmen berlebihan dalam rencana ini. Ini akan diperlukan jika
ROW_NUMBERfungsi peringkat memilikiPARTITION BYklausa, tetapi tidak. Meski begitu, itu tetap dalam rencana akhir. - Proyek Urutan menambahkan nomor baris terhitung ke aliran baris.
- Scalar Hitung mendefinisikan ekspresi yang terkait dengan kebutuhan untuk secara implisit mengonversi
valkolom ke numerik sehingga dapat dikalikan dengan konstanta literal1.0dalam kueri. Perhitungan ini ditangguhkan sampai dibutuhkan oleh operator selanjutnya (yang kebetulan adalah Stream Aggregate). Pengoptimalan waktu proses ini berarti konversi implisit hanya dilakukan untuk dua baris yang diproses oleh Agregat Aliran, bukan 5.000.001 baris yang ditunjukkan untuk Skalar Hitung. - Operator Top diperkenalkan oleh pengoptimal kueri. Ia mengakui bahwa paling banyak, hanya
(@Count + 2) / 2yang pertama baris dibutuhkan oleh kueri. Kita bisa menambahkanTOP ... ORDER BYdi subquery untuk membuat ini eksplisit, tetapi pengoptimalan ini membuat sebagian besar tidak perlu. - Filter mengimplementasikan kondisi di
WHEREklausa, memfilter semua kecuali dua baris 'tengah' yang diperlukan untuk menghitung median (Top yang diperkenalkan juga didasarkan pada kondisi ini). - Stream Aggregate menghitung
SUMdanCOUNTdari dua baris median. - Skalar Hitung akhir menghitung rata-rata dari jumlah dan hitungan.
Kinerja Mentah
Dibandingkan dengan OFFSET rencana, kita mungkin berharap bahwa Segmen tambahan, Sequence Project, dan operator Filter akan memiliki beberapa efek buruk pada kinerja. Sebaiknya luangkan waktu sejenak untuk membandingkan perkiraan biaya kedua paket:
OFFSET paket memiliki perkiraan biaya 0,0036266 unit, sedangkan ROW_NUMBER paket diperkirakan 0,0036744 unit. Ini adalah angka yang sangat kecil, dan ada sedikit perbedaan di antara keduanya.
Jadi, mungkin mengejutkan bahwa ROW_NUMBER kueri sebenarnya berjalan selama 4000 md rata-rata, dibandingkan dengan 910 md rata-rata untuk OFFSET larutan. Beberapa dari peningkatan ini pasti dapat dijelaskan oleh overhead operator rencana tambahan, tetapi faktor empat tampaknya berlebihan. Pasti ada lebih dari itu.
Anda mungkin juga memperhatikan bahwa perkiraan kardinalitas untuk kedua rencana perkiraan di atas sangat salah. Ini karena efek dari operator Top, yang memiliki ekspresi yang mereferensikan variabel sebagai batas jumlah barisnya. Pengoptimal kueri tidak dapat melihat konten variabel pada waktu kompilasi, sehingga menggunakan tebakan default 100 baris. Kedua paket benar-benar menemukan 5.000.001 baris saat runtime.
Ini semua sangat menarik, tetapi tidak secara langsung menjelaskan mengapa ROW_NUMBER kueri lebih dari empat kali lebih lambat daripada OFFSET Versi:kapan. Bagaimanapun, perkiraan kardinalitas 100 baris sama salahnya dalam kedua kasus.
Meningkatkan kinerja solusi ROW_NUMBER
Pada artikel saya sebelumnya, kita melihat bagaimana kinerja median OFFSET yang dikelompokkan tes bisa hampir dua kali lipat hanya dengan menambahkan PAGLOCK petunjuk. Petunjuk ini mengesampingkan keputusan normal mesin penyimpanan untuk memperoleh dan melepaskan kunci bersama pada perincian baris (karena kardinalitas yang diharapkan rendah).
Sebagai pengingat lebih lanjut, PAGLOCK petunjuk tidak diperlukan dalam median OFFSET pengujian karena pengoptimalan internal terpisah yang dapat melewati kunci bersama tingkat baris, yang mengakibatkan hanya sejumlah kecil kunci bersama maksud yang diambil di tingkat halaman.
Kami mungkin mengharapkan ROW_NUMBER solusi median tunggal untuk mendapatkan keuntungan dari optimasi internal yang sama, tetapi tidak. Memantau aktivitas penguncian saat ROW_NUMBER kueri dijalankan, kami melihat lebih dari setengah juta kunci bersama tingkat baris individu diambil dan dibebaskan.
Jadi, sekarang kami tahu apa masalahnya, kami dapat meningkatkan kinerja penguncian dengan cara yang sama seperti yang kami lakukan sebelumnya:baik dengan PAGLOCK mengunci petunjuk perincian, atau dengan meningkatkan perkiraan kardinalitas menggunakan tanda jejak terdokumentasi 4138.
Menonaktifkan "tujuan baris" menggunakan tanda jejak adalah solusi yang kurang memuaskan karena beberapa alasan. Pertama, ini hanya efektif di SQL Server 2008 R2 atau yang lebih baru. Kami kemungkinan besar akan memilih OFFSET solusi di SQL Server 2012, jadi ini secara efektif membatasi perbaikan bendera pelacakan ke SQL Server 2008 R2 saja. Kedua, menerapkan tanda pelacakan memerlukan izin tingkat administrator, kecuali diterapkan melalui panduan rencana. Alasan ketiga adalah bahwa menonaktifkan sasaran baris untuk keseluruhan kueri mungkin memiliki efek lain yang tidak diinginkan, terutama dalam rencana yang lebih kompleks.
Sebaliknya, PAGLOCK petunjuk efektif, tersedia di semua versi SQL Server tanpa izin khusus, dan tidak memiliki efek samping utama selain mengunci granularitas.
Menerapkan PAGLOCK petunjuk ke ROW_NUMBER kueri meningkatkan kinerja secara dramatis:dari 4000 md hingga 1500 md:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500 md hasilnya masih jauh lebih lambat dari 910 md untuk OFFSET solusi, tapi setidaknya sekarang di stadion baseball yang sama. Perbedaan kinerja yang tersisa hanya karena kerja ekstra dalam rencana eksekusi:

Dalam OFFSET rencana, lima juta baris diproses sejauh Top (dengan ekspresi yang didefinisikan pada Hitung Skalar ditangguhkan seperti yang dibahas sebelumnya). Dalam ROW_NUMBER plan, jumlah baris yang sama harus diproses oleh Segment, Sequence Project, Top, dan Filter.