SQL Server 2005 menambahkan kemampuan untuk memasukkan kolom nonkey dalam indeks nonclustered. Di SQL Server 2000 dan sebelumnya, untuk indeks nonclustered, semua kolom yang ditentukan untuk indeks adalah kolom kunci, yang berarti mereka adalah bagian dari setiap level indeks, dari akar hingga level daun. Ketika sebuah kolom didefinisikan sebagai kolom yang disertakan, itu adalah bagian dari tingkat daun saja. Books Online mencatat manfaat berikut dari kolom yang disertakan:
- Mereka dapat berupa tipe data yang tidak diizinkan sebagai kolom kunci indeks.
- Mereka tidak dipertimbangkan oleh Mesin Basis Data saat menghitung jumlah kolom kunci indeks atau ukuran kunci indeks.
Misalnya, kolom varchar(max) tidak dapat menjadi bagian dari kunci indeks, tetapi dapat berupa kolom yang disertakan. Selanjutnya, kolom varchar(max) itu tidak dihitung terhadap batas 900-byte (atau 16-kolom) yang dikenakan untuk kunci indeks.
Dokumentasi juga mencatat manfaat kinerja berikut:
Indeks dengan kolom bukan kunci dapat secara signifikan meningkatkan kinerja kueri saat semua kolom dalam kueri disertakan dalam indeks baik sebagai kolom kunci atau bukan kunci. Peningkatan kinerja dicapai karena pengoptimal kueri dapat menemukan semua nilai kolom dalam indeks; tabel atau data indeks berkerumun tidak diakses sehingga lebih sedikit operasi I/O disk.Kita dapat menyimpulkan bahwa apakah kolom indeks adalah kolom kunci atau kolom bukan kunci, kita mendapatkan peningkatan kinerja dibandingkan ketika semua kolom bukan bagian dari indeks. Namun, apakah ada perbedaan performa antara kedua variasi tersebut?
Penyiapan
Saya memasang salinan database AdventuresWork2012 dan memverifikasi indeks untuk tabel Sales.SalesOrderHeader menggunakan sp_helpindex versi Kimberly Tripp:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Indeks default untuk Penjualan.SalesOrderHeader
Kami akan mulai dengan kueri langsung untuk pengujian yang mengambil data dari beberapa kolom:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Jika kita menjalankan ini terhadap database AdventureWorks2012 menggunakan SQL Sentry Plan Explorer dan memeriksa rencana dan output Tabel I/O, kita melihat bahwa kita mendapatkan pemindaian indeks berkerumun dengan 689 pembacaan logis:
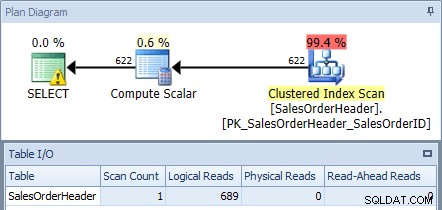
Rencana eksekusi dari kueri asli
(Di Management Studio, Anda dapat melihat metrik I/O menggunakan SET STATISTICS IO ON; .)
SELECT memiliki ikon peringatan, karena pengoptimal merekomendasikan indeks untuk kueri ini:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Uji 1
Pertama-tama kita akan membuat indeks yang direkomendasikan pengoptimal (bernama NCI1_included), serta variasi dengan semua kolom sebagai kolom kunci (bernama NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Jika kita menjalankan kembali kueri asli, setelah mengisyaratkannya dengan NCI1, dan sekali mengisyaratkannya dengan NCI1_included, kita melihat rencana yang mirip dengan aslinya, tapi kali ini ada pencarian indeks dari setiap indeks nonclustered, dengan nilai yang setara untuk Tabel I/ O, dan biaya serupa (keduanya sekitar 0,006):
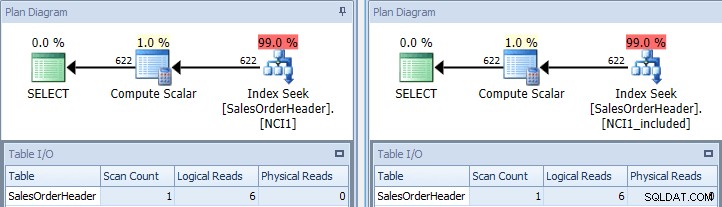
Kueri asli dengan pencarian indeks – tombol di sebelah kiri, sertakan di kanan
(Jumlah pemindaian masih 1 karena pencarian indeks sebenarnya adalah pemindaian rentang yang menyamar.)
Sekarang, database AdventureWorks2012 tidak mewakili database produksi dalam hal ukuran, dan jika kita melihat jumlah halaman di setiap indeks, kita melihat mereka persis sama:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
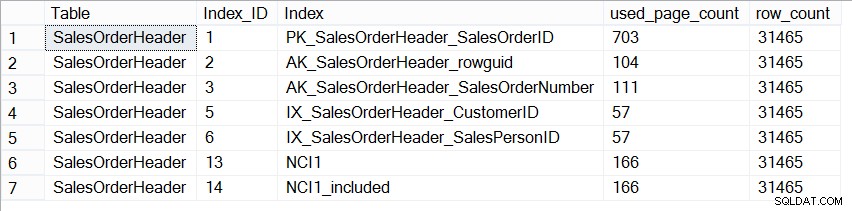
Ukuran indeks pada Sales.SalesOrderHeader
Jika kita melihat kinerja, itu ideal (dan lebih menyenangkan) untuk menguji dengan kumpulan data yang lebih besar.
Uji 2
Saya memiliki salinan database AdventureWorks2012 yang memiliki tabel SalesOrderHeader dengan lebih dari 200 juta baris (skrip DI SINI), jadi mari buat indeks nonclustered yang sama di database itu dan jalankan kembali kueri:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
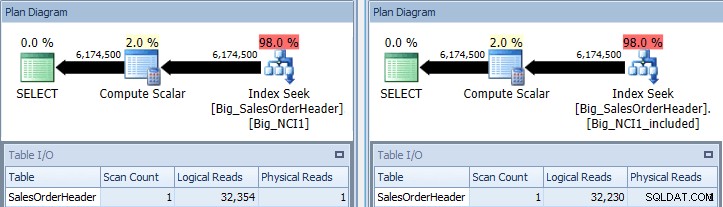
Kueri asli dengan pencarian indeks terhadap Big_NCI1 (l) dan Big_NCI1_Included ( r)
Sekarang kita mendapatkan beberapa data. Kueri menghasilkan lebih dari 6 juta baris, dan mencari setiap indeks membutuhkan lebih dari 32.000 pembacaan, dan perkiraan biayanya sama untuk kedua kueri (31.233). Belum ada perbedaan kinerja, dan jika kami memeriksa ukuran indeks, kami melihat bahwa indeks dengan kolom yang disertakan memiliki 5.578 halaman lebih sedikit:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Ukuran indeks pada Penjualan.Big_SalesOrderHeader
Jika kita menggali lebih jauh dan memeriksa dm_dm_index_physical_stats, kita dapat melihat bahwa perbedaan ada di tingkat menengah indeks:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
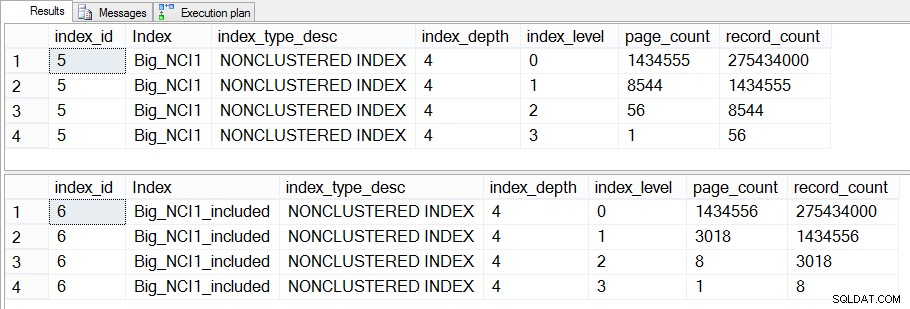
Ukuran indeks (khusus level) pada Penjualan.Big_SalesOrderHeader
Perbedaan antara tingkat menengah kedua indeks adalah 43 MB, yang mungkin tidak signifikan, tetapi saya mungkin masih cenderung membuat indeks dengan kolom yang disertakan untuk menghemat ruang – baik di disk maupun di memori. Dari perspektif kueri, kami masih belum melihat perubahan besar dalam kinerja antara indeks dengan semua kolom di kunci dan indeks dengan kolom yang disertakan.
Uji 3
Untuk pengujian ini, mari ubah kueri dan tambahkan filter untuk [SubTotal] >= 100 ke klausa WHERE:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
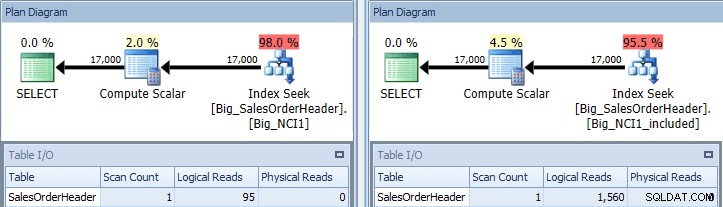
Rencana eksekusi kueri dengan predikat SubTotal terhadap kedua indeks
Sekarang kita melihat perbedaan dalam I/O (95 pembacaan versus 1.560), biaya (0,848 vs 1,55), dan perbedaan halus namun patut diperhatikan dalam rencana kueri. Saat menggunakan indeks dengan semua kolom di kunci, predikat pencarian adalah ID Pelanggan dan SubTotal:
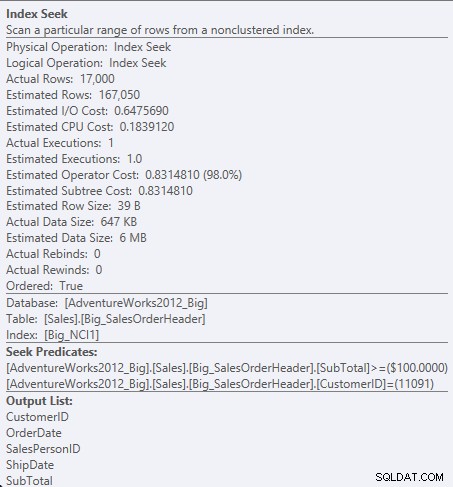
Cari predikat terhadap NCI1
Karena SubTotal adalah kolom kedua dalam kunci indeks, data diurutkan dan SubTotal ada di tingkat menengah indeks. Mesin dapat mencari langsung ke catatan pertama dengan ID Pelanggan 11091 dan SubTotal lebih besar dari atau sama dengan 100, dan kemudian membaca indeks sampai tidak ada lagi catatan untuk ID Pelanggan 11091.
Untuk indeks dengan kolom yang disertakan, SubTotal hanya ada di tingkat daun indeks, jadi CustomerID adalah predikat pencarian, dan SubTotal adalah predikat residual (hanya terdaftar sebagai Predikat di tangkapan layar):
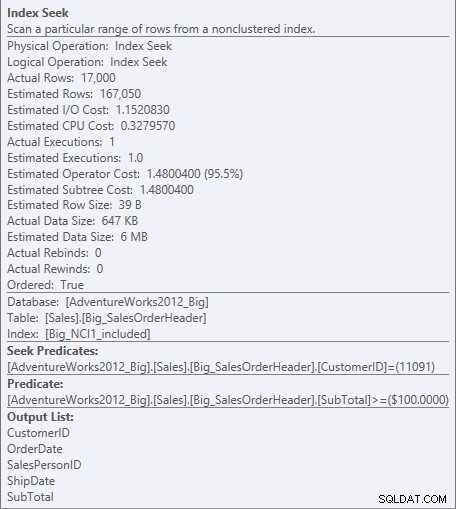
Cari predikat dan sisa predikat terhadap NCI1_included
Mesin dapat mencari langsung ke catatan pertama di mana ID Pelanggan adalah 11091, tetapi kemudian harus melihat setiap record untuk CustomerID 11091 untuk melihat apakah SubTotal 100 atau lebih tinggi, karena data diurutkan oleh CustomerID dan SalesOrderID (kunci pengelompokan).
Uji 4
Kami akan mencoba satu variasi lagi dari kueri kami, dan kali ini kami akan menambahkan ORDER BY:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
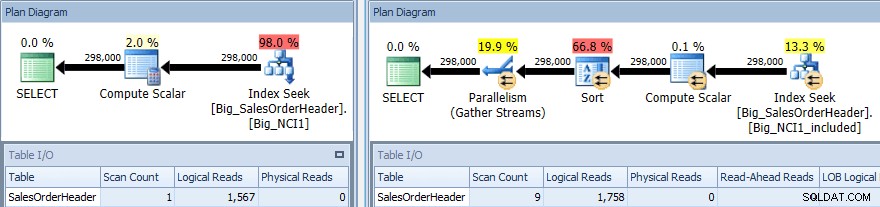
Rencana eksekusi kueri dengan SORT terhadap kedua indeks
Sekali lagi kami memiliki perubahan I/O (meskipun sangat sedikit), perubahan biaya (1,5 vs 9,3), dan perubahan yang jauh lebih besar dalam bentuk rencana; kami juga melihat jumlah pemindaian yang lebih besar (1 vs 9). Kueri mengharuskan data diurutkan berdasarkan SubTotal; ketika SubTotal adalah bagian dari kunci indeks, itu diurutkan, jadi ketika catatan untuk CustomerID 11091 diambil, mereka sudah dalam urutan yang diminta.
Ketika SubTotal ada sebagai kolom yang disertakan, catatan untuk CustomerID 11091 harus diurutkan sebelum dapat dikembalikan ke pengguna, oleh karena itu pengoptimal menyela operator Sortir dalam kueri. Akibatnya, kueri yang menggunakan indeks Big_NCI1_included juga meminta (dan diberikan) hibah memori sebesar 29.312 KB, yang penting (dan ditemukan di properti paket).
Ringkasan
Pertanyaan awal yang ingin kami jawab adalah apakah kami akan melihat perbedaan kinerja saat kueri menggunakan indeks dengan semua kolom di kunci, versus indeks dengan sebagian besar kolom termasuk dalam tingkat daun. Dalam rangkaian pengujian pertama kami tidak ada perbedaan, tetapi pada pengujian ketiga dan keempat kami ada perbedaan. Itu pada akhirnya tergantung pada permintaan. Kami hanya melihat dua variasi – satu memiliki predikat tambahan, yang lain memiliki ORDER BY – banyak lagi yang ada.
Apa yang perlu dipahami oleh pengembang dan DBA adalah bahwa ada beberapa manfaat besar untuk menyertakan kolom dalam indeks, tetapi mereka tidak akan selalu berkinerja sama seperti indeks yang memiliki semua kolom di kunci. Mungkin tergoda untuk memindahkan kolom yang bukan bagian dari predikat dan bergabung keluar dari kunci, dan hanya menyertakannya, untuk mengurangi ukuran indeks secara keseluruhan. Namun, dalam beberapa kasus ini memerlukan lebih banyak sumber daya untuk eksekusi kueri dan dapat menurunkan kinerja. Degradasi mungkin tidak signifikan; mungkin tidak… Anda tidak akan tahu sampai Anda mengujinya. Oleh karena itu, saat mendesain indeks, penting untuk memikirkan kolom setelah kolom utama – dan memahami apakah kolom tersebut perlu menjadi bagian dari kunci (misalnya karena menyimpan data yang diurutkan akan memberikan manfaat) atau jika kolom tersebut dapat memenuhi tujuannya sebagaimana disertakan kolom.
Seperti biasa dengan pengindeksan di SQL Server, Anda harus menguji kueri Anda dengan indeks Anda untuk menentukan strategi terbaik. Ini tetap merupakan seni dan sains – mencoba menemukan jumlah indeks minimum untuk memenuhi sebanyak mungkin kueri.



